






一、MMOCR是什么?
MMOCR 是一个基于 PyTorch 和 MMDetection 的开源工具箱,支持众多 OCR 相关的模型,涵盖了文本检测、文本识别以及关键信息提取等多个主要方向。
MMOCR 具有以下特点:
-
全流程:支持文字检测、文字识别以及其下游任务,比如关键信息提取等。
-
多模型:我们实现了 10 余种优秀算法。文字检测算法包括单阶段检测算法和双阶段检测算法;文字识别包含规则文字识别和非规则文字识别算法;关键信息提取包含基于图模型的关键信息提取算法。
模块设计:我们使用统一框架和模块化设计实现了各个算法模块。一方面可以尽量实现代码复用,另外一方面,方便大家基于此框架实现新的算法。我们把文字检测,基于分割的文字识别以及关键信息识别网络结构,抽象成 backbone,neck,head 以及 loss 模块,把 seq2seq 文字识别网络抽象成 backbone,encoder,decoder 以及 loss 模块 -
公平对比:现有文字检测识别方法,往往使用不同的训练数据,预训练模型,数据增强方法,网络 backbone,优化器以及学习率策略。比如文字检测常见的数据增强方式有随机缩放,随机旋转变换,以及随机 crop,不同的方法使用不同的数据增强方法的实现,组合以及参数配置,导致分析关键作用模块较为困难。统一的代码框架,模块化的设计,使得不同的模块可以轻松进行组合,实现公平的对比。
-
快速入门:我们统一了常见的学术数据集合的标注文件格式,并提供了已经处理好的标注文件。 同时我们提供了丰富的预训练模型,benchmark 和详细的文档,帮助大家快速上手。
二、安装
1.准备环境
第一步 下载并安装 Miniconda.
第二步 创建并激活一个 conda 环境:
打开命令提示符,win+R
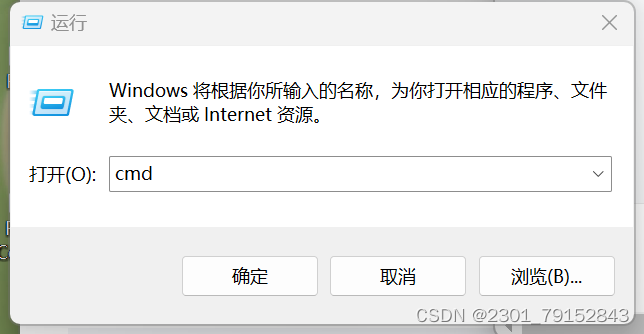
#创建mmocr环境(name后是环境的名字) conda create --name mmocr python=3.8 -y #卸载虚拟环境 conda remove -n mmocr --all #激活环境命令 conda mmocr
第三步 依照官方指南,安装 PyTorch。
GPU
conda install pytorch torchvision -c pytorch
CPU
conda install pytorch torchvision cpuonly -c pytorch
如果版本不匹配就查看自己下载的conda的版本
输入如下命令,即可查看到电脑已经安装的cuda版本
nvcc --version
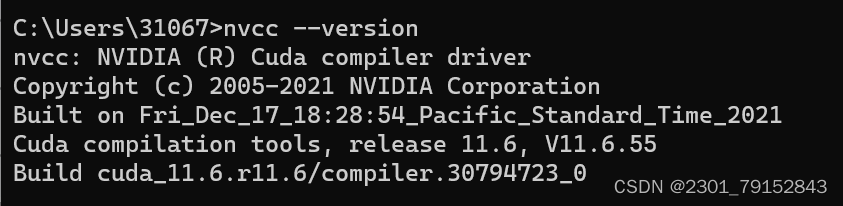
在这里我的cuda是11.6版本的
# CUDA 11.6
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia
# CUDA 11.7
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
# CPU Only
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 cpuonly -c pytorch
2.安装步骤
第一步 使用 MIM 安装 MMEngine, MMCV 和 MMDetection。
pip install -U openmim
mim install mmengine
mim install mmcv
mim install mmdet
第二步 安装 MMOCR.
若你需要直接运行 MMOCR 或在其基础上进行开发,则通过源码安装(推荐)。
如果你将 MMOCR 作为一个外置依赖库使用,则可以通过 MIM 安装。
MIM安装 mim install mmocr
第三步(可选) 如果你需要使用与 albumentations 有关的变换(如 ABINet 数据流水线中 的 Albu),或需要构建文档、运行单元测试的依赖,请使用以下命令安装依赖:
MIM安装:pip install albumentations>=1.1.0 --no-binary qudida,albumentations
3.测试
在 Python 中运行以下代码:
from mmocr.apis import MMOCRInferencer
ocr = MMOCRInferencer(det='DBNet', rec='CRNN')
ocr('demo/demo_text_ocr.jpg', show=True, print_result=True)
如果你是通过源码安装的 MMOCR,你可以在 MMOCR 的根目录下运行以下命令:
python tools/infer.py demo/demo_text_ocr.jpg --det DBNet --rec CRNN --show --print-result
若 MMOCR 的安装无误,你在这一节完成后应当能看到以图片和文字形式表示的识别结果:
使用命令
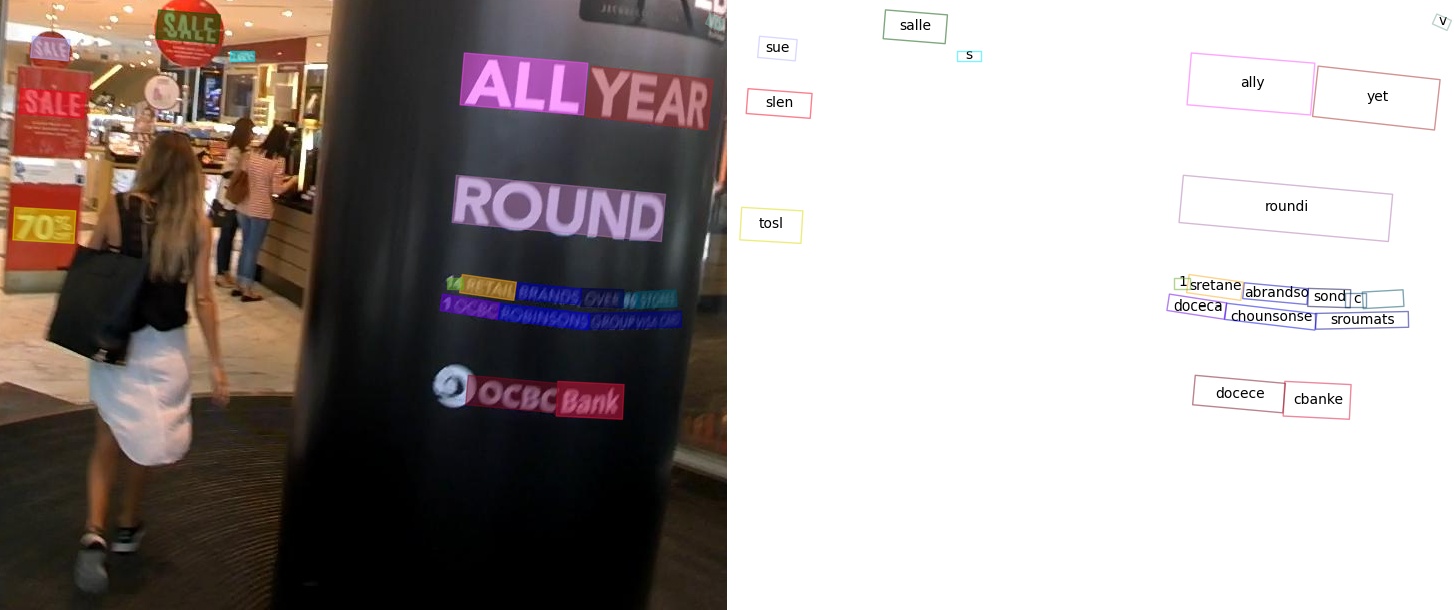
# 识别结果
{'predictions': [{'rec_texts': ['cbanks', 'docecea', 'grouf', 'pwate', 'chobnsonsg', 'soxee', 'oeioh', 'c', 'sones', 'lbrandec', 'sretalg', '11', 'to8', 'round', 'sale', 'year',
'ally', 'sie', 'sall'], 'rec_scores': [...], 'det_polygons': [...], 'det_scores':
[...]}]}
使用代码的运行结果:

4.准备数据集
由于 OCR 任务的数据集种类多样,格式不一,不利于多数据集的切换和联合训练,因此 MMOCR 约定了一种统一的数据格式,并针对常用的 OCR 数据集提供了一键式数据准备脚本。通常,要在 MMOCR 中使用数据集,你只需要按照对应步骤运行指令即可。
注解
但我们亦深知,效率就是生命——尤其对想要快速上手 MMOCR 的你来说。
在这里,我们准备了一个用于演示的精简版 ICDAR 2015 数据集。下载我们预先准备好的压缩包 https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz,解压到 mmocr 的
https://download.openmmlab.com/mmocr/data/icdar2015/mini_icdar2015.tar.gz,解压到 mmocr 的 data(需要新建data目录)/icdar2015 目录下,就能得到我们准备好的图片和标注文件。
5.修改配置
准备好数据集后,我们接下来就需要通过修改配置的方式指定训练集的位置和训练参数。
在这个例子中,我们将会训练一个以 resnet18 作为骨干网络(backbone)的 DBNet。由于 MMOCR 已经有针对完整 ICDAR 2015 数据集的配置 (configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py),我们只需要在它的基础上作出一点修改。
我们首先需要修改数据集的路径。在这个配置中,大部分关键的配置文件都在 _base_ 中被导入,如数据库的配置就来自 configs/textdet/_base_/datasets/icdar2015.py。打开该文件,把第一行 icdar2015_textdet_data_root 指向的路径替换:
icdar2015_textdet_data_root = 'data/mini_icdar2015'
icdar2015_textdet_data_root = 'data/mini_icdar2015'' icdar2015_textdet_train = dict( type='OCRDataset', data_root=icdar2015_textdet_data_root, ann_file='textdet_train.json', filter_cfg=dict(filter_empty_gt=True, min_size=32), pipeline=None) icdar2015_textdet_test = dict( type='OCRDataset', data_root=icdar2015_textdet_data_root, ann_file='textdet_test.json', test_mode=True, pipeline=None)
另外,因为数据集尺寸缩小了,我们也要相应地减少训练的轮次到 400,缩短验证和储存权重的间隔到10轮,并放弃学习率衰减策略。直接把以下几行配置放入 configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py即可生效:
# 每 10 个 epoch 储存一次权重,且只保留最后一个权重
default_hooks = dict(
checkpoint=dict(
type='CheckpointHook',
interval=10,
max_keep_ckpts=1,
))
# 设置最大 epoch 数为 400,每 10 个 epoch 运行一次验证
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=400, val_interval=10)
# 令学习率为常量,即不进行学习率衰减
param_scheduler = [dict(type='ConstantLR', factor=1.0),]
6.使用命令完成数据集准备
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet
命令执行完成后,数据集将被下载并转换至 MMOCR 格式,文件目录结构如下:
data/icdar2015 ├── textdet_imgs │ ├── test │ └── train ├── textdet_test.json └── textdet_train.json
7.可视化数据集
在正式开始训练前,我们还可以可视化一下经过训练过程中数据变换(transforms)后的图像。方法也很简单,把我们需要可视化的配置传入 browse_dataset.py 脚本即可:
mmocr-main\tools\visualizations\browse_dataset.py是用来可视化的py文件
python tools/analysis_tools/browse_dataset.py configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py
三.运行
1.训练
tools/train.py实现了基础的训练服务。MMOCR 推荐用户使用 GPU 进行模型训练和测试,但是,用户也可以通过指定CUDA_VISIBLE_DEVICES=-1来使用 CPU 设备进行模型训练及测试。例如,以下命令演示了如何使用 CPU 或单卡 GPU 来训练 DBNet 文本检测器。# 通过调用 tools/train.py 来训练指定的 MMOCR 模型 CUDA_VISIBLE_DEVICES= python tools/train.py ${CONFIG_FILE} [PY_ARGS] # 训练 # 示例 1:使用 CPU 训练 DBNet CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py # 示例 2:指定使用 gpu:0 训练 DBNet,指定工作目录为 dbnet/,并打开混合精度(amp)训练 CUDA_VISIBLE_DEVICES=0 python tools/train.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py --work-dir dbnet/ --amp
根据系统情况,MMOCR 会自动使用最佳的设备进行训练。如果有 GPU,则会默认在第一张卡启动单卡训练。当开始看到 loss 的输出,就说明你已经成功启动了训练。
2022/08/22 18:42:22 - mmengine - INFO - Epoch(train) [1][5/7] lr: 7.0000e-03 memory: 7730 data_time: 0.4496 loss_prob: 14.6061 loss_thr: 2.2904 loss_db: 0.9879 loss: 17.8843 time: 1.8666 2022/08/22 18:42:24 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015 2022/08/22 18:42:28 - mmengine - INFO - Epoch(train) [2][5/7] lr: 7.0000e-03 memory: 6695 data_time: 0.2052 loss_prob: 6.7840 loss_thr: 1.4114 loss_db: 0.9855 loss: 9.1809 time: 0.7506 2022/08/22 18:42:29 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015 2022/08/22 18:42:33 - mmengine - INFO - Epoch(train) [3][5/7] lr: 7.0000e-03 memory: 6690 data_time: 0.2101 loss_prob: 3.0700 loss_thr: 1.1800 loss_db: 0.9967 loss: 5.2468 time: 0.6244 2022/08/22 18:42:33 - mmengine - INFO - Exp name: dbnet_resnet18_fpnc_1200e_icdar2015
2.测试
tools/test.py提供了基础的测试服务,其使用原理和训练脚本类似。例如,以下命令演示了 CPU 或 GPU 单卡测试 DBNet 模型。# 通过调用 tools/test.py 来测试指定的 MMOCR 模型 CUDA_VISIBLE_DEVICES= python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [PY_ARGS] # 测试 # 示例 1:使用 CPU 测试 DBNet CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth # 示例 2:使用 gpu:0 测试 DBNet CUDA_VISIBLE_DEVICES=0 python tools/test.py configs/textdet/dbnet/dbnet_resnet50-dcnv2_fpnc_1200e_icdar2015.py dbnet_r50.pth


















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









