







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的坐姿监测算法系统
设计思路
一、课题背景与意义
随着科技的进步和人们对健康的日益关注,坐姿监测逐渐成为一个重要的研究领域。长时间的不良坐姿不仅会导致脊椎和肌肉的损伤,还可能引发一系列健康问题,如颈椎病、腰椎间盘突出等。因此,开发一个能够实时监测和纠正坐姿的系统,具有广泛的应用前景。传统的坐姿监测方法往往依赖于人工检查或简单的传感器,缺乏智能化和实时性,而基于深度学习的坐姿监测算法则能够通过计算机视觉和人工智能技术,自动识别和分析坐姿,从而提供更为精准和高效的解决方案。
二、算法理论原理
2.1 YOLOv5算法
YOLO(You Only Look Once)是一种高效的端到端目标监测算法,其核心思想是通过神经网络直接预测目标的边界框和类别,从而实现快速的目标检测。YOLO算法的结构主要由四个部分组成:输入端负责接收和预处理图像数据,主干网络(Backbone)用于提取特征,网络的颈部(Neck)则用于融合不同层次的特征,最后在预测输出端生成最终的检测结果。相较于之前的版本,YOLOv5在这四个部分都进行了显著改进,尤其在特征提取和特征融合上,采用了更先进的结构,如Focus模块和CSP结构,从而提升了模型的精度和实时性。此外,YOLOv5在小目标检测方面表现尤为出色,能够在复杂场景中有效识别小尺寸目标,使其在实际应用中具有更强的适应性和实用性。这些改进使得YOLOv5成为现代目标检测任务中一种极具竞争力的选择,广泛应用于安防监控、自动驾驶和智能分析等领域。

2.2 图像分类
深度学习中的图像分类是一个关键的任务,它通过神经网络模型对输入图像进行特征提取和分类,从而实现自动识别和理解图像内容的目标。在这一过程中,神经网络,尤其是卷积神经网络(CNN),通过多层结构逐步提取图像的高级特征,能够有效捕捉图像中的边缘、纹理和形状等信息。网络的每一层都学习到不同层次的特征,从而使得整体模型能够对复杂的视觉模式进行更深层次的分析。训练过程中,模型通过大量标注的数据进行优化,调整参数以提高分类精度。
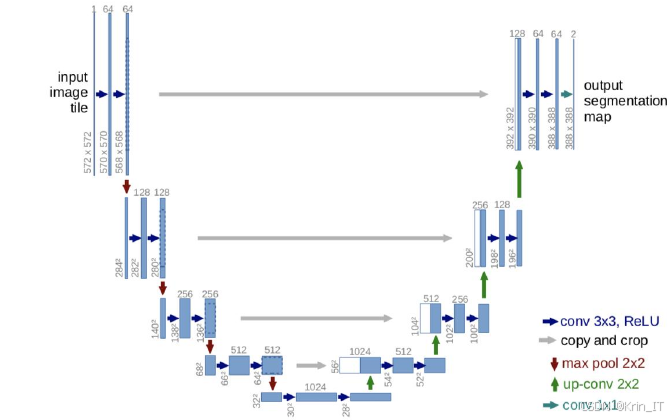
VGG是一个经典的卷积神经网络(CNN)模型,其创新性地采用了多个连续的小卷积核来替代传统的较大卷积核,从而成功增加了网络的深度,提升了模型的表达能力。传统CNN模型常使用大卷积核提取图像特征,这不仅增加了计算复杂度,还可能导致参数数量的迅速膨胀。VGG通过堆叠多个3x3的小卷积核,既实现了与大卷积核相同的特征提取效果,又显著减少了参数数量,从而提高了模型的效率和可训练性。VGG中最具代表性的两个版本是VGG16和VGG19,它们的主要区别在于卷积层的数量,前者有16个卷积层,后者则有19个。这种设计使得VGG能够在浅层捕捉更多局部特征,同时在深层获取更丰富的全局信息,使其在图像分类和特征提取等任务中表现出色,成为深度学习领域的重要基准模型。
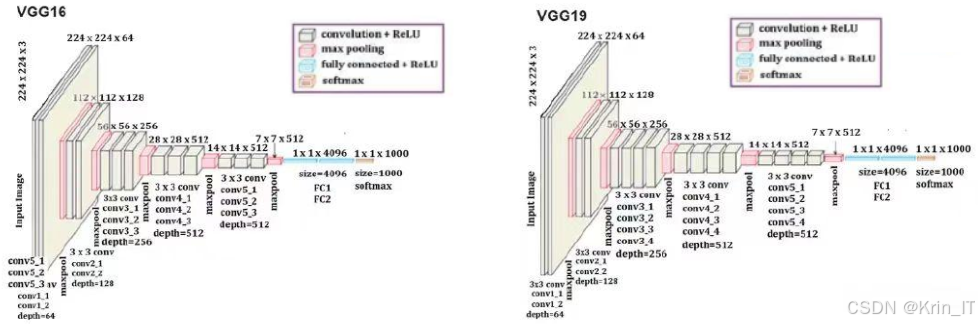
MobileNet是一种轻量级卷积神经网络(CNN),专为移动设备的图像识别任务设计,其主要目标是减少模型的计算量和参数量,同时保持良好的分类性能。MobileNet的核心创新在于引入了深度可分离卷积,这种卷积方法将标准卷积操作拆分为两部分:深度卷积和逐点卷积。深度卷积在每个输入通道上独立进行特征提取,而逐点卷积则用于将提取到的特征组合到一起。这种分离的卷积策略显著降低了模型的复杂度,理论上可以将计算量缩减至普通卷积的八分之一,使得MobileNet非常适合在资源有限的移动设备上运行,依然能够实现高效的图像分类和特征识别。
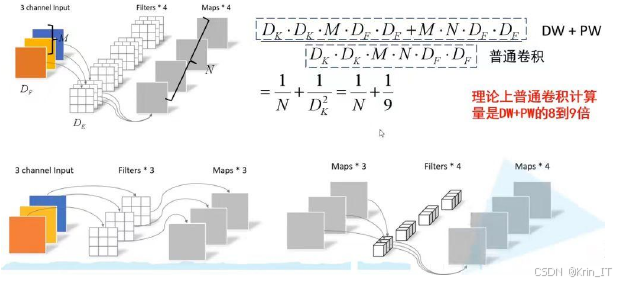
残差网络(ResNet)是一种深度神经网络架构,通过引入残差块显著提高了网络的深度和性能。由微软研究院提出的ResNet,解决了传统卷积网络在增加深度时面临的梯度消失和爆炸问题,提升了模型的训练效果。ResNet的核心思想是残差学习,即通过跳跃连接将输入直接传递到后续层,以保留前面层的输出,从而减轻网络训练中的信息丢失。这种设计允许网络在训练过程中更灵活地适应数据特征,提高了其对不同视觉任务的适应能力。跳跃连接不仅加速了训练过程,还促进了更深层网络的构建,使得ResNet在多个视觉任务中取得了突破性成果,成为深度学习领域的重要基准模型。
相关代码:
# 定义ResNet模型
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x三、检测的实现
3.1 数据集
鉴于缺乏公开且适用于坐姿识别的数据集,进行了坐姿数据的采集工作,以使数据更贴近实际应用场景。采集过程中,拍摄了多人图像,并针对教室和办公室中常见的坐姿类型,如端坐、趴卧、托头和站立,进行了重点关注。尽管“站立”不属于坐姿,但考虑到其对坐姿识别的影响,仍将其纳入分类范围。此外,面部朝向也被作为分类目标,分为面向左、前和右三类,以帮助识别不当坐姿带来的潜在健康问题。数据采集步骤包括拍摄多人坐姿图像,特别关注在有无桌椅遮挡的情况下进行拍摄,随后利用目标检测模型对图像进行处理,将其裁剪为单人图像,为后续的分割和图像分类做好准备。
数据扩展在深度学习模型训练中至关重要,它通过生成多样化的训练样本,提升模型的泛化能力和鲁棒性,有效减少过拟合现象。常用的数据扩展技术包括几何变换(如旋转、翻转、缩放)、颜色变换(如亮度、对比度调整)、噪声添加(如高斯噪声)、裁剪与填充(如随机裁剪)以及混合技术(如Mixup和CutMix)。这些技术不仅增加了数据集的规模,还帮助模型适应不同的输入条件,从而在面对现实世界的变化时表现更加稳定,最终提高分类准确性和其他性能指标。
3.2 实验环境搭建
深度学习框架为构建、训练、优化和推理深度神经网络提供了必要的基础工具,使开发者能够更高效地进行相关工作。这些框架不仅简化了复杂的计算过程,还提供了丰富的功能和灵活的接口,帮助开发者快速实现各种深度学习算法。在众多深度学习框架中,PyTorch因其高度的扩展性和可移植性而受到广泛欢迎,尤其在学术研究和工业应用中表现出色。它的动态计算图特性使得模型的调试和修改变得更加直观和方便,同时,PyTorch拥有一个活跃的开发者社区,提供了大量的资源和支持,极大地推动了深度学习的研究和应用。

3.3 效果图
在模型训练过程中,定义合适的损失函数和优化器是至关重要的步骤。损失函数用于量化模型预测值与真实标签之间的差距,通过最小化损失来指导模型的更新。在坐姿监测任务中,通常使用交叉熵损失(Cross Entropy Loss),特别适合多分类问题,它能够有效地衡量分类结果的准确性。同时,选择合适的优化器,如Adam或SGD(随机梯度下降),可以加速收敛过程并提高模型的训练效率。优化器通过调整学习率和其他超参数,帮助模型在训练过程中逐步优化。
监控训练过程中的损失和准确率是评估模型性能的重要手段。在每个训练轮次结束时,记录并分析训练损失和验证损失,以判断模型是否存在过拟合或欠拟合的情况。同时,通过计算准确率,可以直观地了解模型在训练集和验证集上的表现。根据这些指标,可以进行相应的调整,例如修改学习率、增减训练轮次或应用早停策略,从而确保模型在实际应用中的有效性和稳定性。通过这种动态监控和调整,能够显著提升模型的整体性能,最终实现高效准确的坐姿监测。
def load_model():
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
return model
def train_model(model, train_loader, num_epochs=10):
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for images, labels in train_loader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {running_loss / len(train_loader):.4f}')
if __name__ == "__main__":
image_dir = 'path/to/images' # 替换为实际图像目录
labels = [{'filename': 'image1.jpg', 'label': 0}, {'filename': 'image2.jpg', 'label': 1}] # 示例标签
dataset = PoseDataset(image_dir, labels)
train_loader = torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)
model = load_model()
train_model(model, train_loader, num_epochs=10)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

















 6855
6855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









