










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的的地铁场景行人目标检测系统

设计思路
一、课题背景与意义
面对危险事故,人员疏散和救援相对困难,这就要求地铁内部视频监控分析系统和安检系统必须满足高实时性和高准确性。近年来,深度学习领域得到突破性发展,目标检测技术愈发成熟,将其应用于地铁安检和视频监控分析领域有着重要的现实意义。
二、算法理论原理
2.1 深度残差收缩网络
为加强模型从含噪信号中提取有用特征的能力,模型引入软阈值化函数;软阈值化函数在图像信号降噪中起着重要作用,将图像特征绝对值低于某个阈值的特征删除,同时将高于某个阈值的特征绝对值向坐标原点“收缩”。3D-SE注意力模块。卷积神经网络中的卷积操作主要是提高局部感受野,以获得多尺度的空间信息。常规卷积操作基本是对输入特征图的全部通道进行融合,网络无法聚焦重要特征通道。
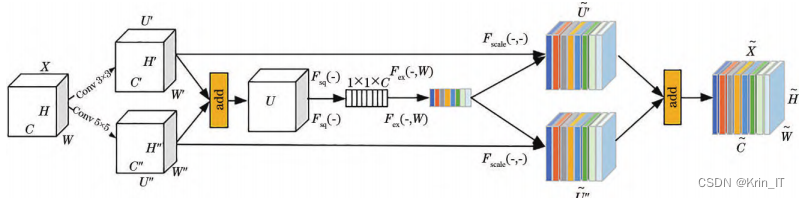
引入D-SE注意力模块,特征图经过一系列卷积操作后将会预测一组权重值,然后对各个通道特征进行加权,模型能够自动提取包含目标特征信息量最大的通道。D-SE注意力模块具有高度对称性,上下分支共用squeeze和excitation操作。特征图U通过聚合不同感受野特征信息引导通道注意力,有助于网络筛选辨别度最高的特征。

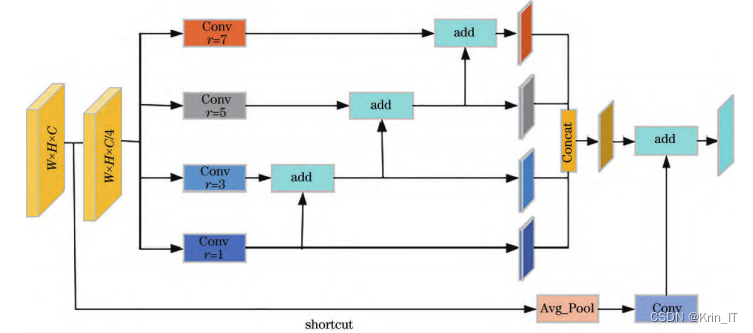
2.2 空洞空间金字塔池化模块
目标检测中,模型对输入图像进行推理检测会对同一目标产生多个预测框,实际应用中模型对单个目标只需保留一个最优预测框。NMS算法是常用的目标预测框后处理算法,用于消除同一目标冗余的预测框。NMS算法原理:设A为模型预测的N个预测框。设计了一种SDIOU-NMS算法,该算法利用一种衰减机制对预测框得分进行优化,通过降低预测框得分而非直接置零,使得一些高分预测框可能作为正确预测框被保留。
相关代码:
import torch
import torch.nn as nn
# 定义空洞卷积模块
class DilatedConvModule(nn.Module):
def __init__(self, in_channels, out_channels, dilation_rate):
super(DilatedConvModule, self).__init__()
self.dilated_conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=dilation_rate, dilation=dilation_rate)
self.relu = nn.ReLU()
def forward(self, x):
out = self.dilated_conv(x)
out = self.relu(out)
return out
# 创建输入张量
batch_size = 32
channels = 3
height = 256
width = 256
input_tensor = torch.randn(batch_size, channels, height, width)
# 定义空洞卷积模块的参数
in_channels = 3
out_channels = 64
dilation_rates = [1, 2, 4] # 使用不同的感受野
# 创建空洞卷积模块实例
dilated_conv_module = DilatedConvModule(in_channels, out_channels, dilation_rates[0])
# 计算特征图
output = dilated_conv_module(input_tensor)
# 打印特征图的形状
print("Output shape:", output.shape)三、检测的实现
3.1 数据集
实验数据集一部分为地铁监控视频抽帧图片,另一部分为公开的数据集。数据采集地铁大多数场景环境的行人目标,如密集行人目标、不同程度遮挡行人目标等。对地铁监控视频抽帧采样的图片用Labelimg软件进行手动标注,标注后的标签是一系列可扩展标记语言(XML)格式。标注过程中对于遮挡严重的行人目标按照“人头”标注“person”类。实验按照6∶2∶2比例,训练集4800张,验证集和测试集各1600张,一共选取8000张图片,共有41935条标签,平均每张图片包含大约5个行人标签。

3.2 实验环境搭建
使用TensorFlow深度学习框架进行网络模型部署,代码基于Windows 10操作系统使用Python语言编写,所用CPU为Intel Core i7 9700K处理器,显卡类型为NVIDIA GeForce RTX2080Ti(11 G)。
3.3 实验及结果分析
为验证改进模块的性能,本研究以YOLOv5s原始模型为基准方法,设计一系列消融实验进行对比验证,使用fAP、FPS两种定量评价指标。
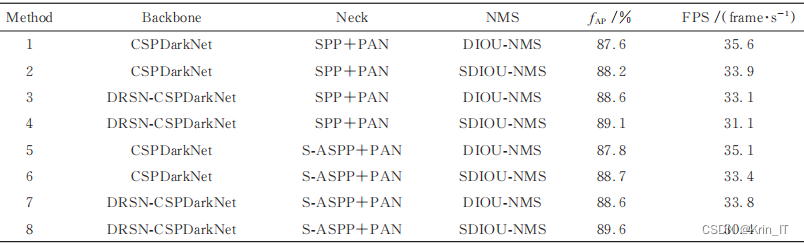
网络模型收敛时,改进YOLOv5s算法对本研究所使用的数据集有更好的泛化性。

相关代码如下:
# 将图像转移到GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_tensor = image_tensor.to(device)
# 运行图像通过模型
outputs = model([image_tensor])
# 解析输出
boxes = outputs[0]['boxes']
scores = outputs[0]['scores']
labels = outputs[0]['labels']
# 设置阈值来筛选行人目标
threshold = 0.5
person_boxes = []
for box, score, label in zip(boxes, scores, labels):
if score > threshold and label == 1:
person_boxes.append(box)
# 打印检测结果
for box in person_boxes:
print('Person box coordinates:', box.tolist())实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!














 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









