






目录
摘要
在本周中,通过阅读文献,进一步了解了域分解PINN分类及原理和优劣性,具体做法为:每个子域使用单独的PINN来计算局部解,通过在接口处施加额外的连续性条件来无缝连接。且可以通过研究各界面上的各种连续条件用于提高性能。在Fluent中,选用入口排气和质量流出口的边界条件应用分析,进行几何划分和设置求解。理论学习方面,对有限体积法中的离散过程进行了学习。
Abstract
This week, I read the literature to learn more about domain decomposition PINN classification, how it works, and its pros and cons by using a separate PIN for each subdomain to compute the local solution, and seamlessly connecting them by imposing additional continuity conditions at the interface. It can also be used to improve performance by studying various continuous conditions on various surfaces. In Fluent, I applied the analysis using boundary conditions for the inlet, exhaust, and mass flow outlets, and solved the geometry and setup. In terms of theoretical study, I studied discrete processes in the finite volume method.
文献阅读:通过领域分解的并行物理信息神经网络
文献摘要
本文介绍了一种分布式的物理信息神经网络(PINNs)框架,这两种扩展分别在空间和时空上采用域分解。这种领域分解使cpinn和xpinn比普通的pinn具有并行化能力、大表示能力、高效的超参数调优等优点,对多尺度和多物理场问题特别有效。
提出了一个应用并行XPINN方法,将十个区域作为子域在美国地图上求解具有可变电导率的逆扩散问题。展示了cpu和gpu的弱伸缩和cpu的强伸缩,展示了两种方法在cpu上的良好加速和效率,介绍了XPINN在cPINN上的性能,用于各种正演问题,如非线性守恒定律和不可压缩的Navier-Stokes方程。还实现了XPINN方法来解决一个逆问题,该问题涉及具有非琐碎空间相关电导率的复杂非凸几何,由一个单独的神经网络表示。
讨论|结论
该框架为一种基于MPI + X的混合规划模型的cpinn和xpinn并行算法,其中X∈{cpu, gpu}。与经典的数据和模型并行方法相比,cPINN和XPINN的主要优点是可以灵活地在每个子域中分别优化每个神经网络的所有超参数。
使用弱、强缩放比较了分布式cpinn和xpinn在各种正问题上的性能,研究结果表明:对于空间域分解,cpinn在通信成本方面更有效,而xpinn提供了更大的灵活性,因为它们还可以处理任何微分方程的时域分解,并且可以处理任何任意形状的复杂子域。
文章首先从并行方法的原理介入,引出CPINN和XPINN的概念,前者为基于守恒律来进行域分解的PINN方法,其中状态的连续性及其在子域接口上的通量用于将子域拼接在一起。
后者为extend PINN ,将域分解应用于一般偏微分方程的方式,与提供空间分解的cPINN不同,XPINN为任何不规则、非凸几何提供了时空域分解,从而有效地降低了计算成本。利用cPINN/XPINN方法的分解过程及其在现代异构计算平台上的隐式映射,可以在很大程度上减少网络的训练时间。
用于数据并行方法的编程模型属于MPI+X系统,其中X可选为CPU(s)或GPU(s)(基于输入数据的大小),利用相同的数据在不同的损失函数上得出不同的数据块,实现了标准的基于pup的多物理场仿真框架。
与数据和模型并行方法相比,cPINN和XPINN的主要优点是它们对每个子域中神经网络的所有超参数的自适应性。在普通的数据并行方法中,通过平均损失函数的梯度并随后broadcast算法来同步跨处理器的训练,从而在每个处理器上强制使用相同的网络架构。
基于单域的解的收敛性受到全局逼近的限制,收敛速度相对较慢。利用局部逼近的解可以获得较快的收敛速度。在计算方面,基于域分解的方法需要一个点对点通信协议,并且缓冲区非常小。
关于分布式系统的优化,文献作者的实验表明:只要给定的PDE是适定的并且具有唯一解,只要使用足够表达的网络和足够数量的残差点,cPINN/XPINN公式就能够获得准确的解。
一般采用基于梯度的优化方法进行参数的训练:随机梯度下降法(SGD)是一种应用广泛的优化方法。在SGD中,每次迭代都随机抽取一小组点来确定梯度方向。SGD算法可以很好地避免DNN在单点凸性下训练时出现不良的局部极小值。
与传统的数据和模型并行方法相比,并行cPINN和XPINN的主要优点是它们对神经网络在每个子域中的所有超参数具有自适应性。
与cPINN相比,XPINN方法的空间分解导致了更大的通信开销,但我们也表明,XPINN方法可以通过沿时间轴分解域来提高效率。在接口条件的实现方面,XPINN可以很容易地应用于更复杂的子域。
其中存在的缺点:
- 需要一个all reduce操作和一个broadcast算法,每个操作的缓冲区大小等于神经网络的参数数量,这使得跨处理器的通信变慢。
- 对于涉及异构物理的问题,数据/模型并行方法是不够的。故需要CPINN/XPINN的加入来更容易的处理这些物理问题。
原理简介
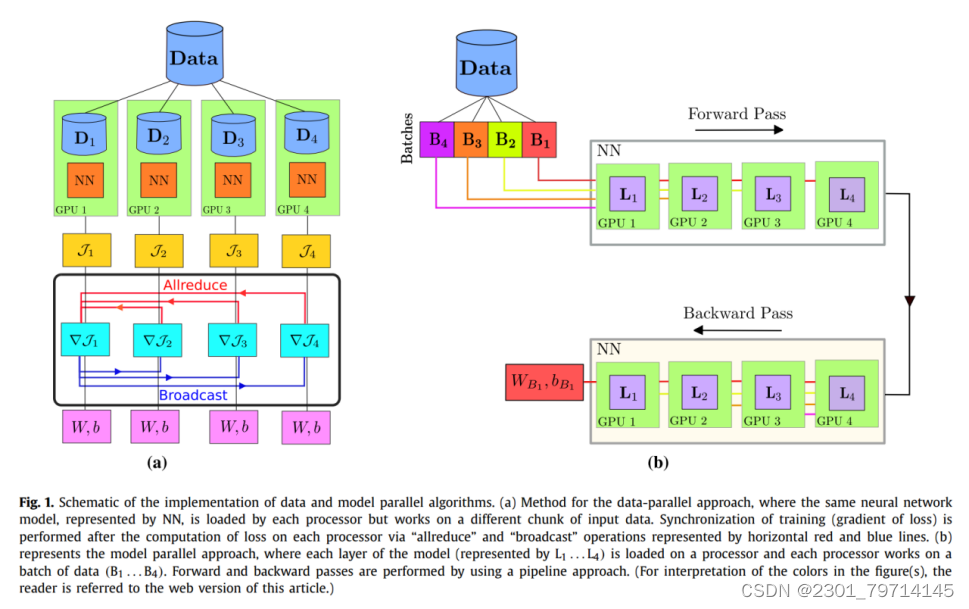
数据和模型并行算法
在模型并行方法中,首先将数据分成小批(B1,…,B4)和每个隐藏层(L1,…,L4)分配给处理器(或GPU)。在正向传递过程中,一旦B1被L1处理,L1的输出作为输入传递给L2, L1开始处理B2,以此类推。一旦L4完成工作,B1将开始向后传递(优化过程),从而以流水线模式完成训练的时代。
这两种算法的实现都是问题不可知的,并且不使用待逼近解的先验信息,这使得这些算法的性能依赖于数据大小和模型参数。在文献中,数据和模型并行方法的实现主要用于基于大量训练数据的分类和自然语言处理问题。
原理图如下所示:
域分解原理
即CPINN和XPINN,原理为将计算域划分为Nsd个不重叠的规则/不规则子域,并在每个子域中部署独立的神经网络,这些神经网络通过公共接口相互连接起来。
神经网络在第qth子域的输出由u φ(z)=N l(z;θ)∈Ωq;最终解为:

其中指向函数ΩZ定义为:

其中S表示沿公共接口相交的子域总数。
与PINN类似,cPINN和XPINN方法的目的是学习一个代理函数,用于使用式(4)预测给定PDE在整个计算域上的解。cPINN/XPINN的损失函数是按子域定义的,它在每个子域上具有与PINN相似的损失函数结构,但它被赋予了将子域拼接在一起的接口条件。
CPINN
基于域分解的守恒律PINN,即保守PINN (cPINN),其中状态的连续性及其在子域接口上的通量用于将子域拼接在一起。为提供空间分解的模式。接口条件确保来自一个子域的信息可以在相邻的子域中传播。这些条件在没有训练数据可用的子域的收敛中也起着重要作用
在cPINN方法中,第q子域的损失函数定义为:
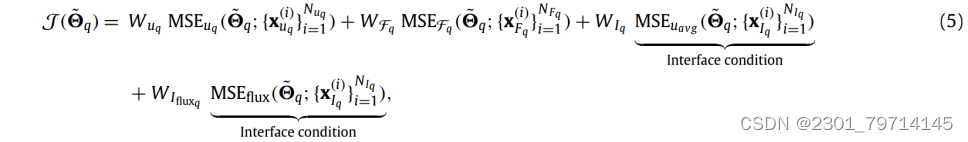
每一项的均方误差如下:
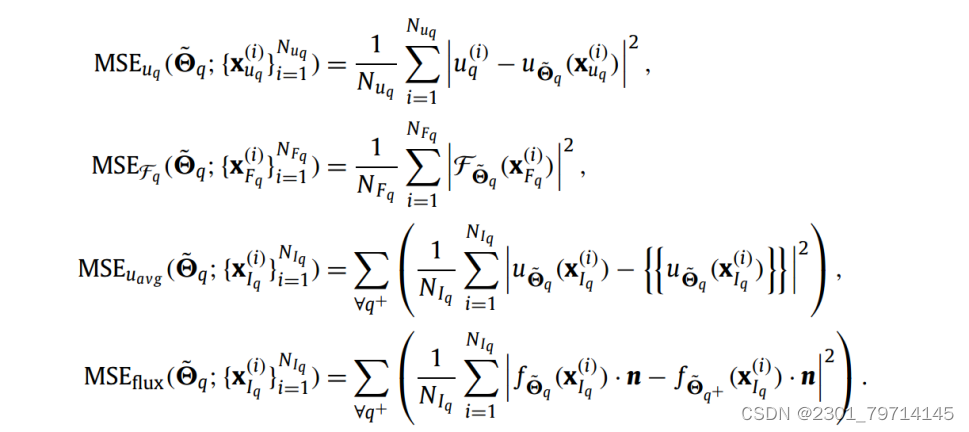
其中,沿公共界面的u的平均值由以下公式给出:
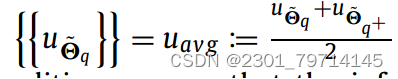
XPINN
与提供空间分解的cPINN不同,XPINN为任何不规则、非凸几何提供了时空域分解,从而有效地降低了计算成本。在XPINN方法中,除了平均解连续条件外,还沿界面施加了更一般的剩余连续条件,从而可以求解任何具有时空分解的微分方程。
除了这些连续性条件外,根据界面的方向和控制微分方程的性质,还可以施加附加的连续性条件,如正常通量连续性、高阶解导数连续性、积分约束(不变量)连续性条件等。
第qth子域的损失函数定义为:

同样,MSE给出为:
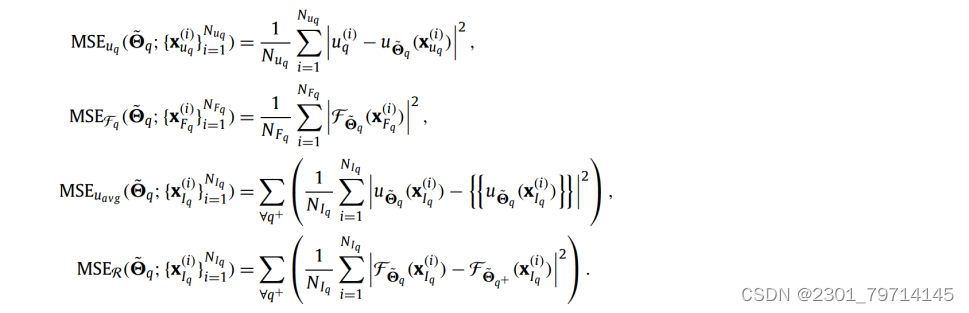
MSE R是两个不同的神经网络分别在子域q和子域q+上给出的公共接口上的残差连续性条件;上标+ / q表示相邻子域(s),MSER和MSEuavg项都是为所有相邻的子域q+定义的,这在它们各自的表达式中通过对所有q+的求和符号表示。
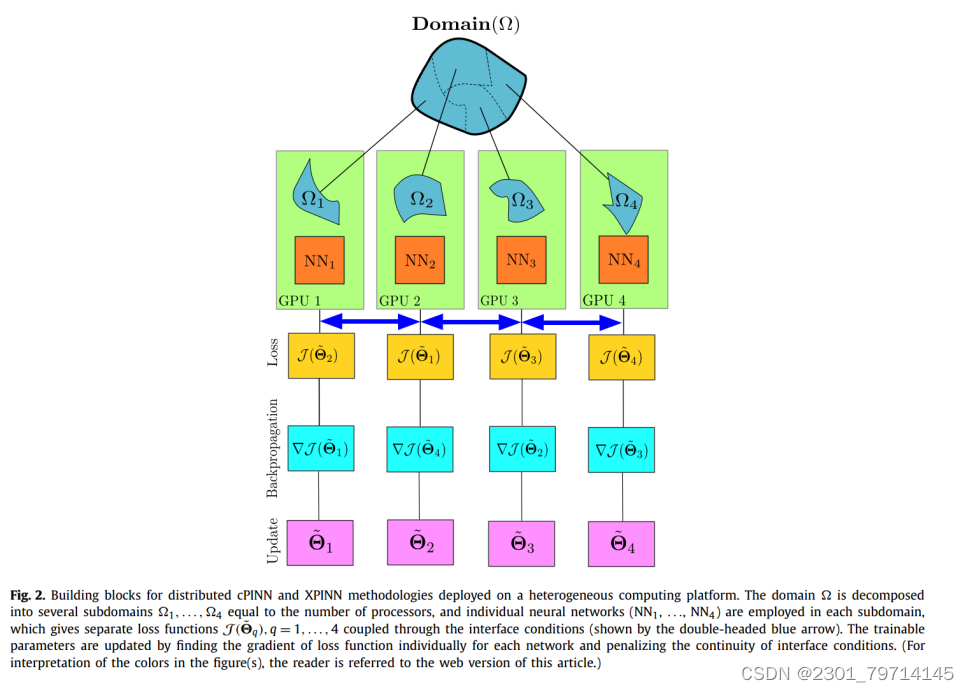
cPINN和XPINN的并行实现
首先,整个域Ω如图所示)被分解为几个子域(Ω1,…,Ω4),每个子域等于处理器或协处理器(GPU)的数量,每个子域将分配给一个单独的神经网络模型。每个处理器将在各自的子域中计算其局部解,并在计算损失之前使用相应的接口条件沿非重叠接口缝合(如图中双头蓝色箭头所示)。因此,cPINN和XPINN继承了数据和模型并行方法的优点,并在解上施加了先验信息,最终确定了每个子域中神经网络的参数。
预处理阶段
预处理阶段主要处理计算域的分解,具体算法详情可见原文,如下图所示;

首先将域划分为不重叠的子域,并约束Nsd的总数等于用于计算的处理器或加速器的数量,如图所示。例如,在图中,将域划分为12个子域:
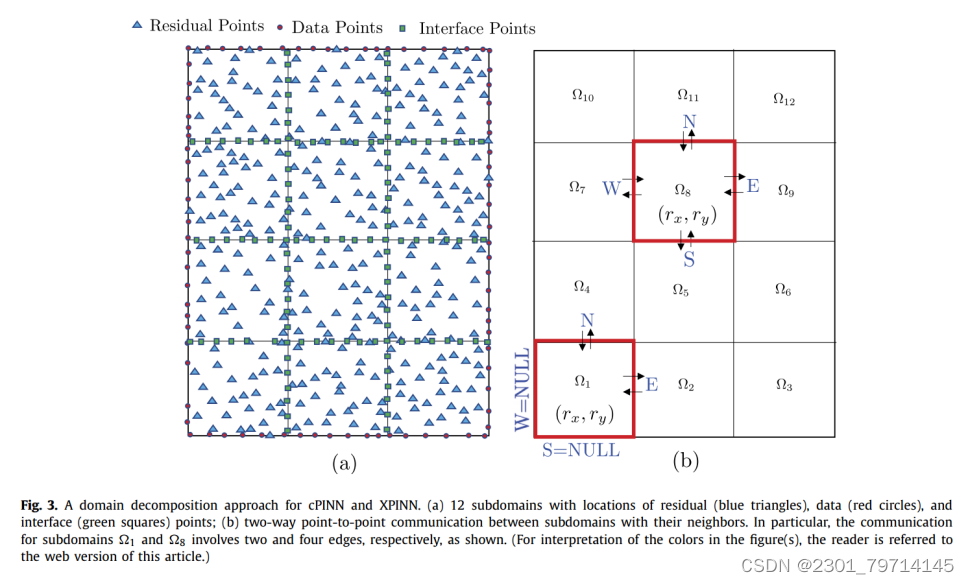
(1)在每个子域中,使用从N(0,σ 2)中抽取的i.i.d方法对训练点、残差点和接口点进行采样。为了同时存储和访问训练数据,我们使用字典型数据结构,其中键值对为子域编号,包含子域边界的子域边的索引列表,并用EToV表示。
(2)准备了另一个字典数据结构,其中包含子域的索引和残差点的(x, y)坐标的二维数组,分别作为键值对。
(3)准备了另一个字典数据结构来存储沿子域边缘的残差点。通过减去全局边数与边界符合的边的集合(EToV)来提取内部子域对应的边。
(4)将以一对一的方式赋予每个子域对应的每个处理器各自子域内残差点(图3a中蓝色三角形)的物理坐标(x, y),子域边缘的接口点(图3a中绿色方形),以及映射到各自子域的训练数据(图3a中红色圆圈)。
并行算法
在通信阶段,用绿色字体表示:

首先将处理器按二维逻辑布局,如图3b所示,每个处理器用x-和y-rank表示为:

在MPI实现中,通信是通过使用全局秩来进行的,全局秩是通过使用r = rx * Nx + ry将局部秩映射到全局秩来获得的。其余不存在的子域使用MPI构造MPI. proc_null初始化为NULL。
现在,随着通信的消息信封准备就绪,每个处理器通过使用点对点发送-接收协议以非阻塞方式发送和接收uφ ~ q (xIq)和f φ~ q (xIq)。
为了接收来自相邻子域的数据,初始化一个对应于子域每条边的缓冲区。一旦通信完成且处理器同步,则使用式(5)或式(6)计算子域损失,对每个子域对应的损失函数进行优化,同时检索每个神经网络的参数。
实验设置
以具有可变电导率的稳态热传导的逆问题为例,在这个反问题中,假设区域内的温度是已知的,但可变导热系数是未知的。目的是从沿边界线可用的K和域内可用的温度值的几个数据点推断材料的未知导热系数。
首先,稳态热传导问题的控制方程为:
![]()
用温度T和导热系数K的狄利克雷边界条件,由精确解得到。强迫项f (x, y)由变导热系数和变温度的精确解得到,假设为:

材质域选择为美国地图,划分为10个子域,如图所示。这些子域之间的接口用蓝色虚线表示,而域边界用绿色实线表示。每个子域的边界和训练数据都是可用的:
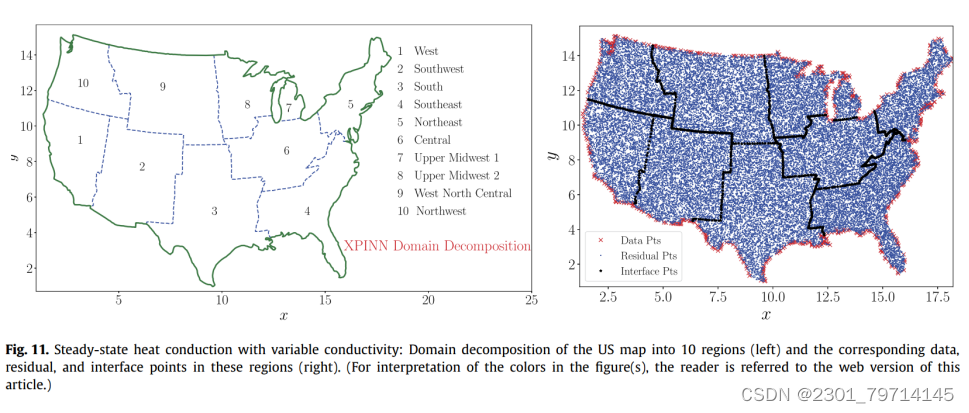
与cPINN不同,XPINN可以用任意形状的接口轻松处理这种复杂的子域,因此,在域细分方面提供了更大的灵活性。图11(右)分别以蓝点、红叉和黑色星号表示整个域的残差、训练数据和接口点。
在每个子域中使用单个PINN,表4给出了关于网络体系结构的详细信息。在每个子域中,我们使用了3个隐藏层,每层有80个神经元,学习率为6e-3,对于所有网络都是固定的。
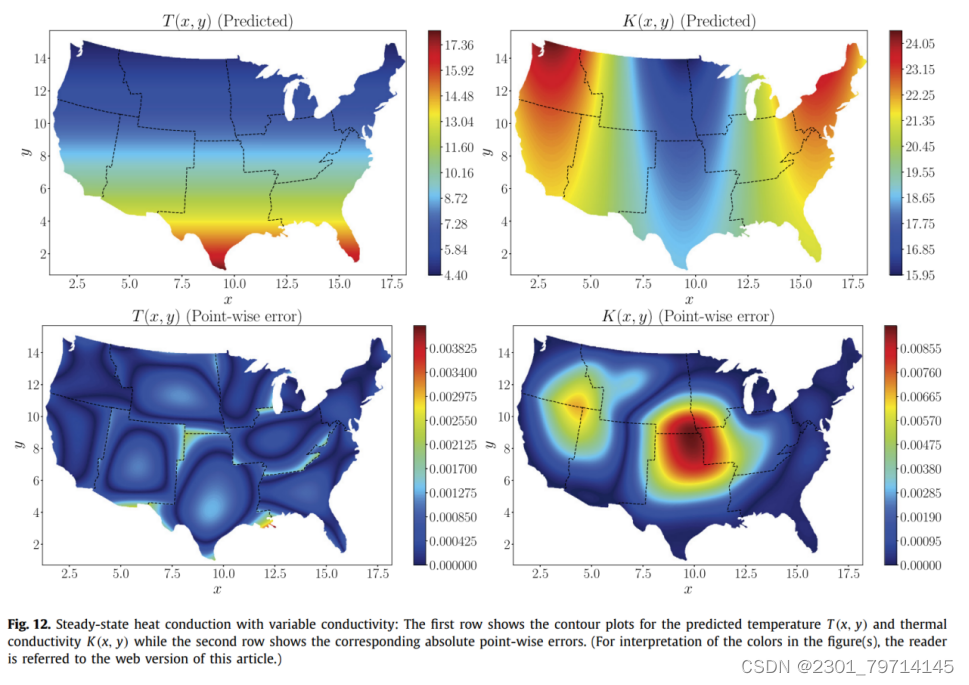
图12(上排)为温度和导热系数预测值。绝对逐点误差在最下面一行给出。XPINN方法可以准确地推断出热导率,这表明XPINN可以很容易地处理高度不规则和非凸的界面。
图13是用于求解逆热传导问题的并行XPINN算法的性能。性能是根据表4中给出的数据点进行测量的。
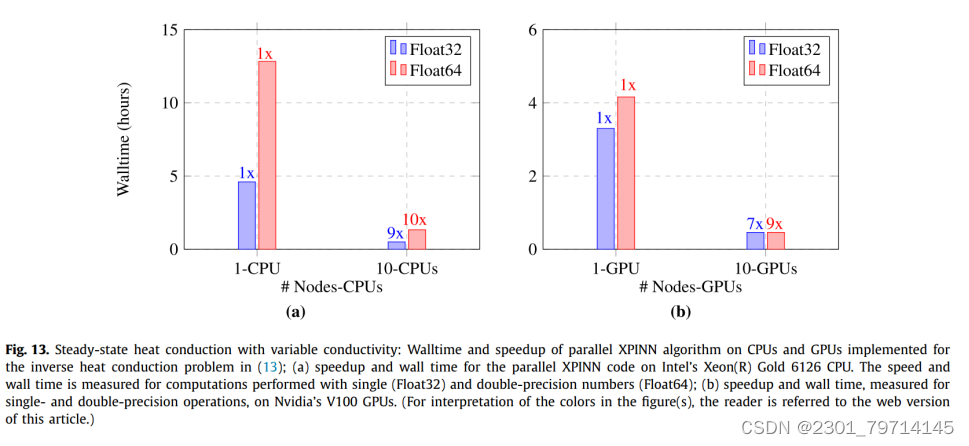

图13a表示了并行XPINN算法在cpu上的壁时间和缩放情况,通过使用一个cpu计算每个域的解。通过MPI协议将每个域边界上的解传递给相邻的子域,实现了子域共享边界上解的连续性。由于通信过程受到计算时间的影响,双精度的缩放效果相对较好。然而,对于基于单个和多个cpu的实现,基于双精度的计算会使隔离时间增加2.5倍。
在这个测试用例中,通过手动选择接口点来执行域的划分。这样做是为了显示XPINN算法对非凸或不规则子域的有效性。在这些复杂的子域中,配电系统经常面临负载不平衡的问题,这将严重降低系统的性能,可以使用一种更有效的方法来分解域,以便对子域进行最佳打包,以便进行节点间或进程间通信。
从计算实验中可以看出:
- cPINN比XPINN具有更低的通信开销,但它只能应用于守恒定律等物理问题。
- 与cPINN不同的是,XPINN可以用于具有普遍适用性的时空分解,而不考虑物理定律的性质。在实践中,两者可以同时使用,例如对于时间相关的守恒律,可以在空间上使用cPINN,而XPINN可以在时间方向上进行分解。
这样的组合可以大大降低与科学问题的神经网络训练相关的计算能力,此外,这种组合方法有效地平衡了所有网络的通信开销。
Fluent实例:入口排气和质量流出口的边界条件应用
几何建模部分
单位转换为mm后,绘制一个1000mm高,半径40mm的圆柱体,可使用创建中的原画命令,直接创建一个出来。如下图所示:
网格划分部分
检查完模型绘制情况后,插入“扫掠(Sweep)”命令,使用轴对称算法,以六面体图形为中心网格,将网格单元阶改为“二次项”,O型网格分区改为设置为10,在中心产生更多的均匀网格:

O型网格如下所示:
将单个网格尺寸改为5mm,网格质量如下所示:
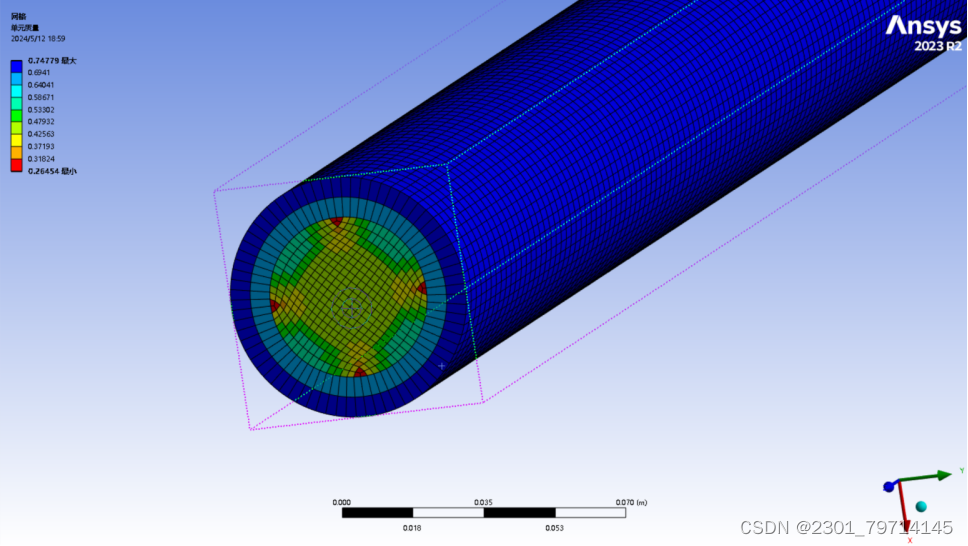
求解器设置
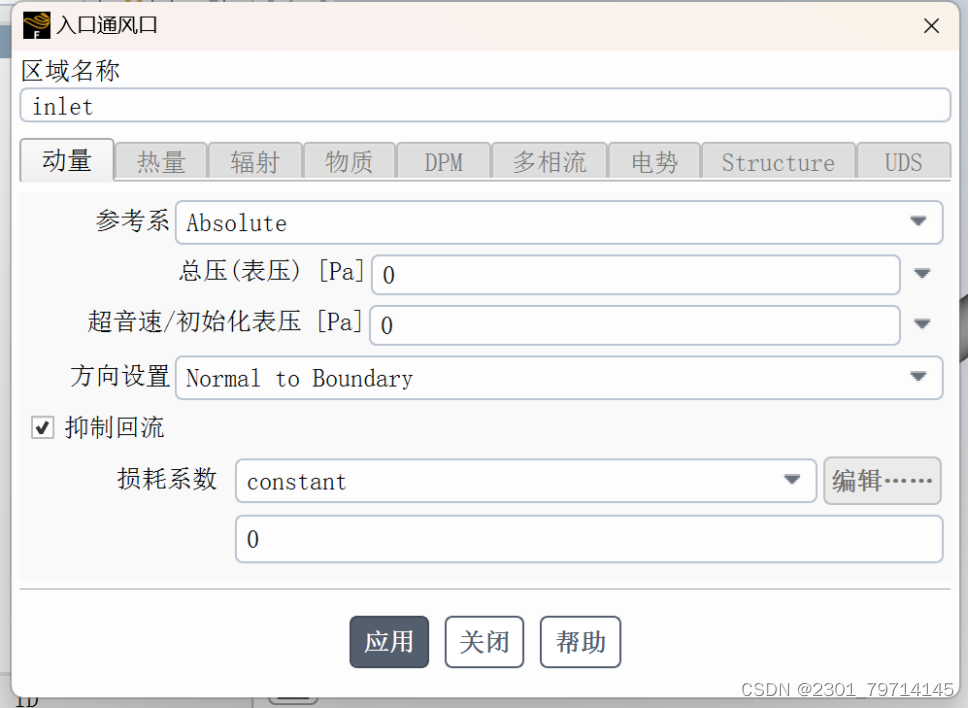
粘性模型使用层流,在数据库中选用液体水作为流体材料,将流体区域条件改为液体水,在边界条件中,将入口条件改为inlet- vent,损耗系数改为常数,并点出抑制回流:
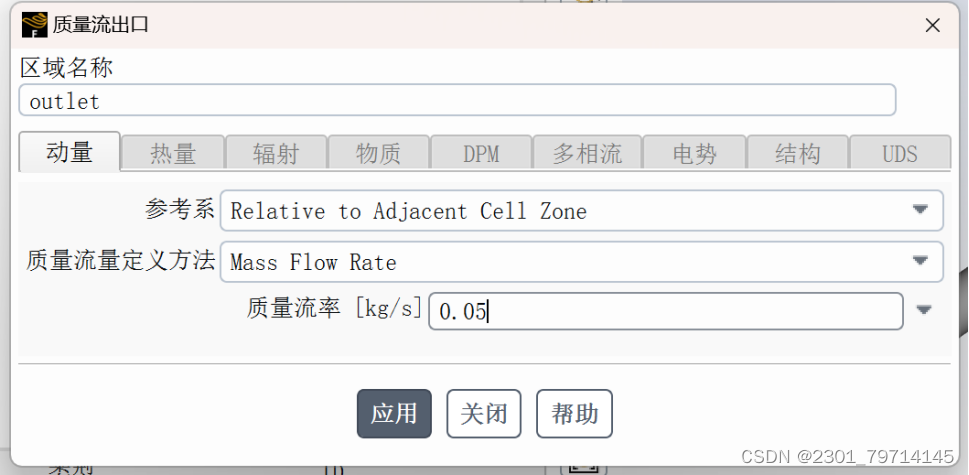
将出口条件改为质量流出口,流出率改为0.05,其余边界条件保持默认:
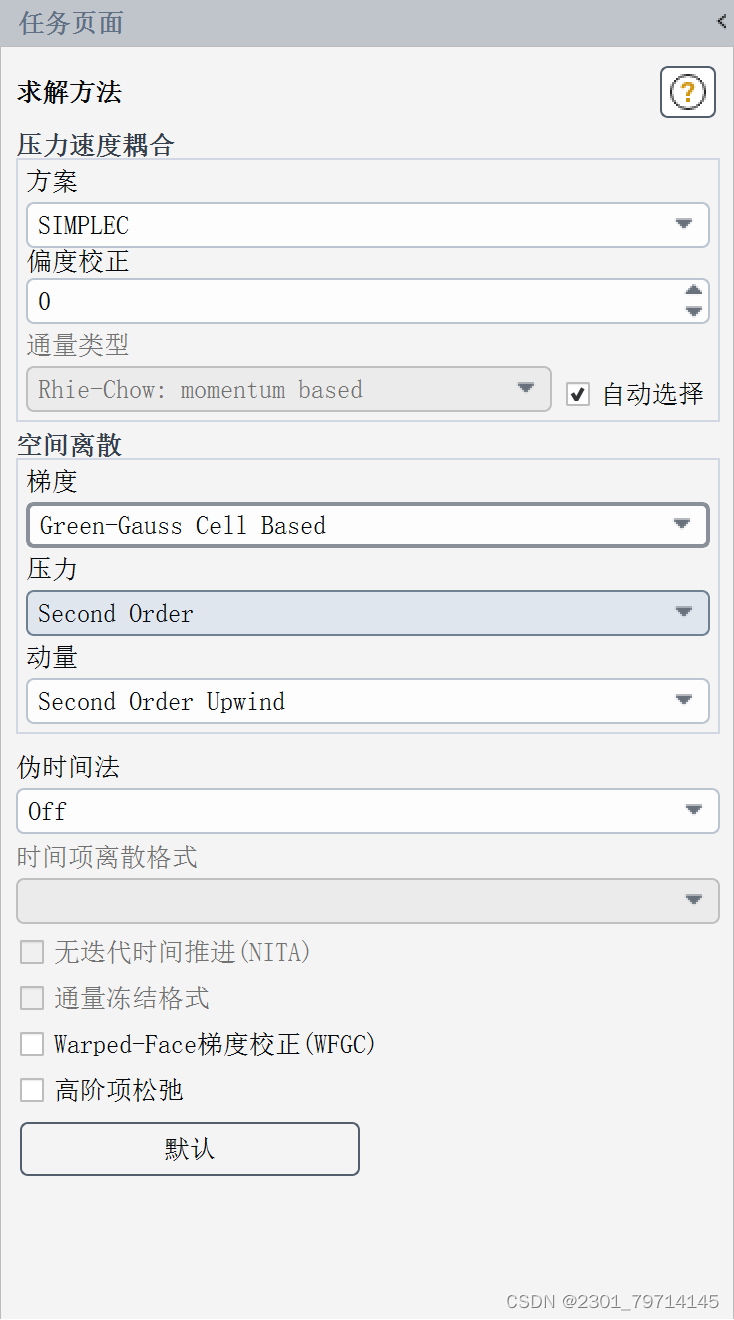
求解方法采用SIMPEC,残差改为1e-6,以获得更好的结果,使用标准初始化,参考区域为all zone具体如下所示:
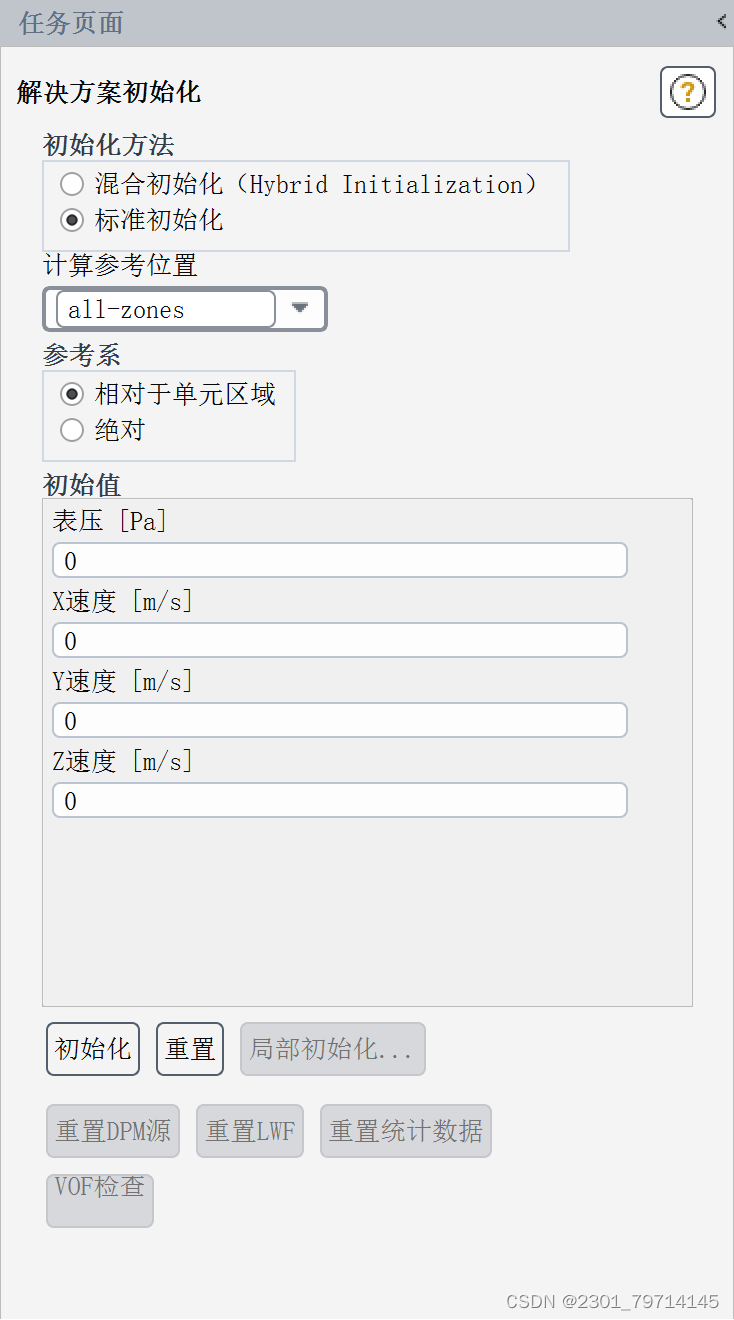
结果展示
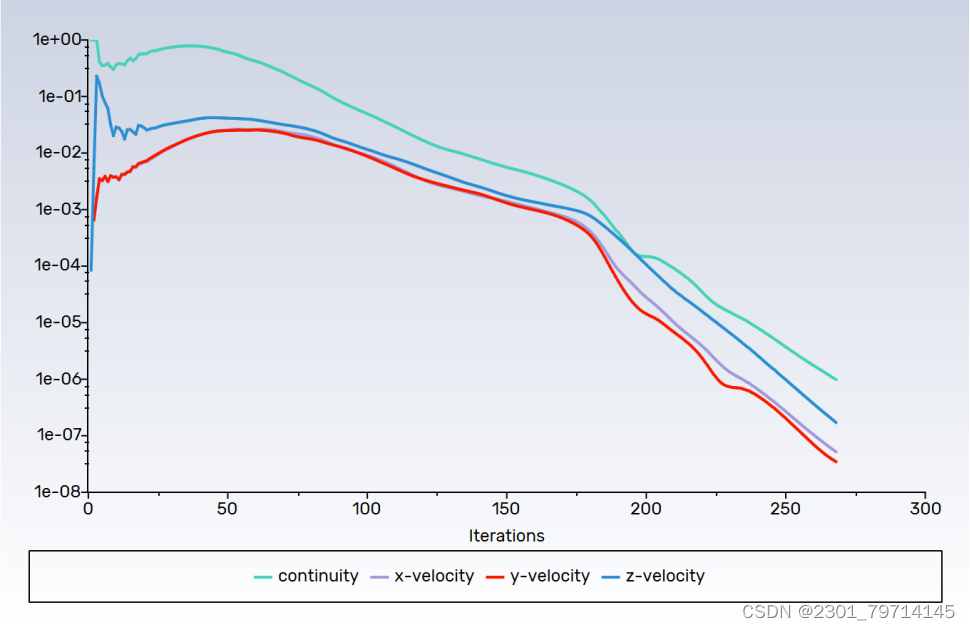
迭代268次后,结果如下:
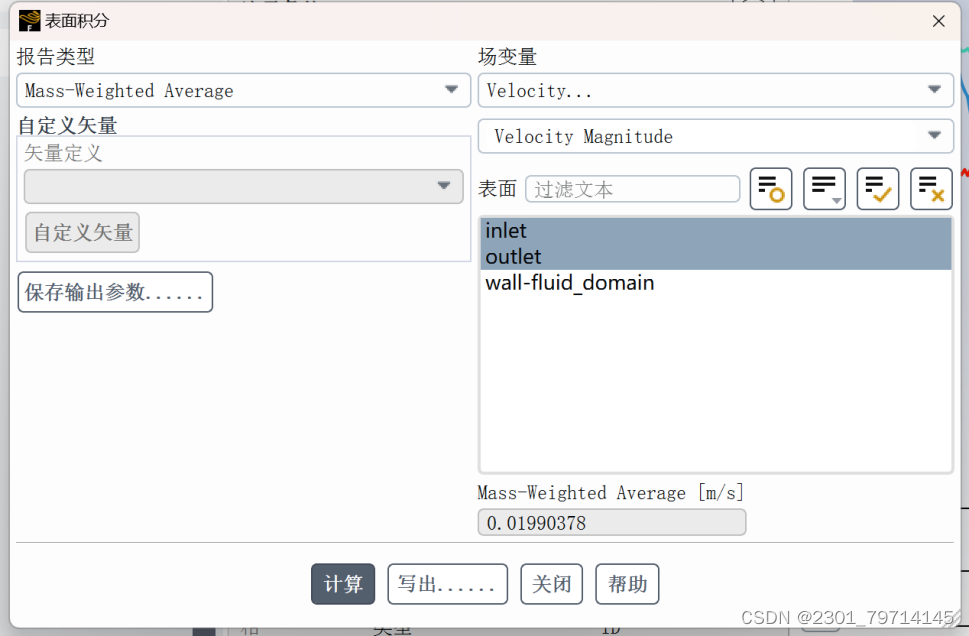
平均质量流率:
速度流线图:

速度云图:

压力云图:
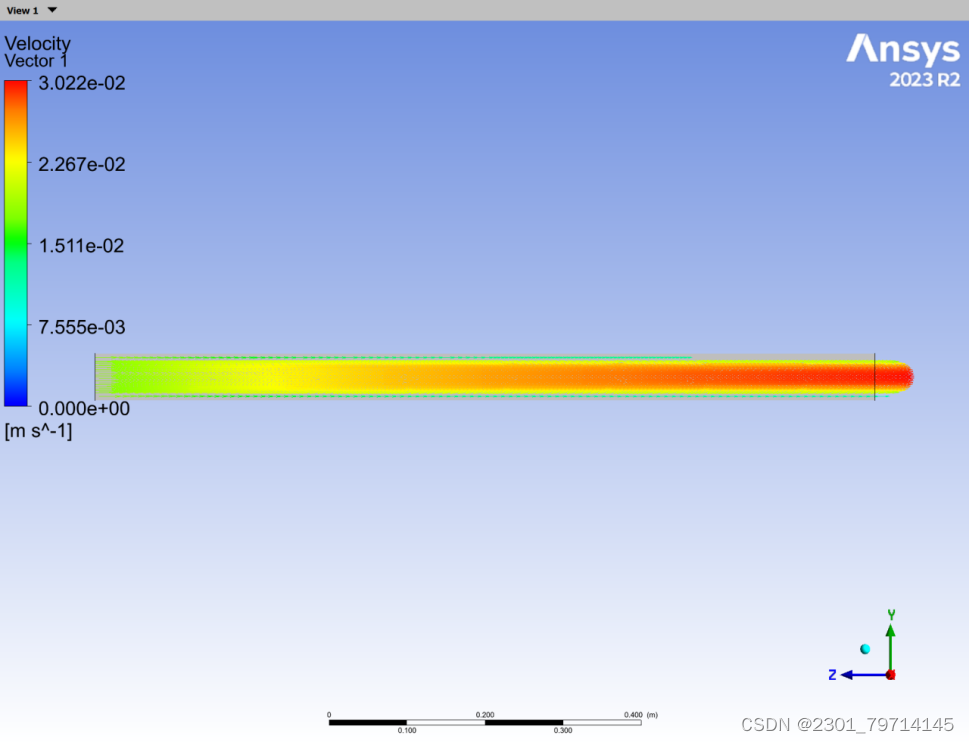
速度矢量图:
理论学习部分





总结
这一周看了域分解的出处文章,对这个方法有了更深刻的理解,并且通过学习有限体积法,对于方程中的扩散项、强迫项、瞬态项等的理解也比以前有进步,不再像以前一样看着方程一脸懵,有更明确的方向感去学习,下一周会继续努力。















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









