






TensorRT 是 NVIDIA 开发的高性能深度学习推理引擎,旨在优化神经网络模型并加速其在 NVIDIA GPU 上的推理性能。它支持多种深度学习框架,并提供一系列优化技术,以实现更高的吞吐量和更低的延迟。
理论上可以对每一代的yolo模型加速推理
YOLOv12 模型简介:
YOLO(You Only Look Once)系列模型以其高效的目标检测能力广受欢迎。YOLOv12 是该系列的最新版本,具有更高的精度。虽然引入FlashAttention,但基于官方对比,yolov12相较于之前的yolo版本,推理速度下降。
环境准备:
在开始之前,确保已安装以下软件:
- CUDA:用于 GPU 加速。
- cuDNN:NVIDIA 的深度神经网络库。
安装TensorRT
TensorRT Download | NVIDIA Developer

选择自己要下载的版本,我以TensorRT10为例。
点开后,勾上选项
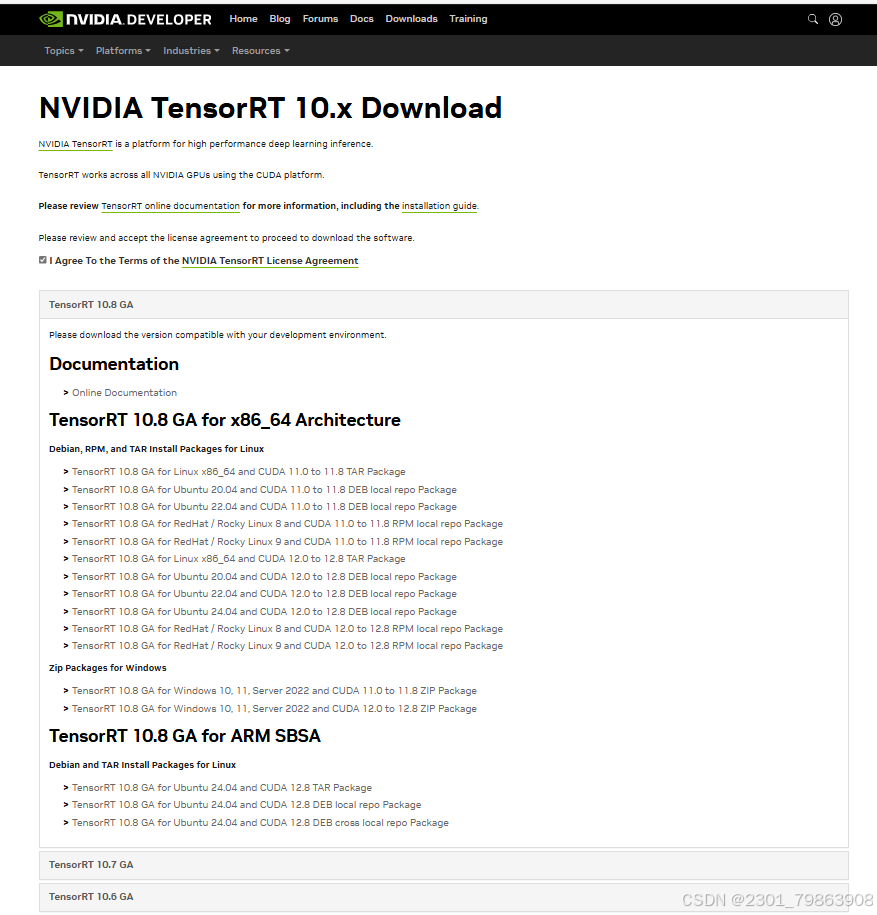
下载和自己cuda和系统对应的版本,以windows11,cuda12.8安装为例,下面这个安装包:
TensorRT 10.8 GA for Windows 10, 11, Server 2022 and CUDA 12.0 to 12.8 ZIP Package
TensorRT 10.8:TensorRT 的版本
for Windows 10, 11, Server 2022:适用于Windows 10和Windows 11和Server 2022
and CUDA 12.0 to 12. 8:表示该版本的 TensorRT 支持 CUDA 12.0 到 CUDA 12.8 的版本范围。
下载得到zip压缩包解压后,将bin和include和lib里的内容移到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2对应的文件夹内然后去设置环境变量(安装过cuda和cudnn可以跳过设置环境变量)。
Releases · kingbri1/flash-attention
使用 FlashAttention 尽量减少内存访问开销也可以加速推理,下载对应的包进行离线安装。(已安装可跳过)
使用 TensorRT 加速 YOLOv12 推理:
将yolov12模型转换为 TensorRT 可以直接运行的模型.engine。
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.export(format="engine", half=True) # 或者 format="onnx"以下是使用 Python 和 TensorRT 加速 YOLOv12 推理的示例代码:
from ultralytics import YOLO
trt_model_path = "yolov12n.engine"
img_path = "ultralytics/assets/bus.jpg"
trt_model = YOLO(trt_model_path, task="detect")
results_tensorrt = trt_model(img_path)
FlashAttention + TensorRT 加速:

仅FlashAttention :

未使用 TensorRT 的推理结果:
- 每张图像的处理时间:
- 预处理:1.0 毫秒
- 推理:59.7 毫秒
- 后处理:67.1 毫秒
- 总计:127.8 毫秒
使用 TensorRT 的推理结果:
- 每张图像的处理时间:
- 预处理:24.7 毫秒
- 推理:4.0 毫秒
- 后处理:74.2 毫秒
- 总计:102.9 毫秒
性能对比与优势:
- 推理时间:使用 TensorRT 后,推理时间从 59.7 毫秒减少到 4.0 毫秒,提升了约 14.9 倍。
- 每张图像的处理时间:总处理时间从 127.8 毫秒减少到 102.9 毫秒,提升了约 1.24 倍。
使用 TensorRT 对 YOLOv12 进行推理加速,不仅显著提高了推理速度,还在精度上保持了模型的有效性,适用于对实时性要求较高的应用场景。

















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









