







本人认为主要思想是这里也不是对视图数据进行填充,而相当于特征填充,就是直接对能产生聚类结果的自表示进行填充和优化。正交投影到潜在空间获得自表示,利用融合矩阵进行自表示填充。聚类结果由自表示Z给出。
摘要:
提出了一种不完全多视图聚类方法(MISS),该方法可以同时学习潜在空间中的缺失实例和自表示。我们不是在原始数据空间中填充缺失实例,而是在潜在空间中学习缺失实例和自表示,从而在保留数据原始潜在空间结构的同时掌握缺失实例的特征。此外,还提出了一种新的融合矩阵。缺失的实例由潜在空间中已知实例的线性组合表示。根据多视图聚类中潜在空间的自表示学习,同时学习融合矩阵。还提出了完备性约束,以保证缺失实例的学习方向尽可能接近原始数据。由于关注缺失实例的特征和保持原始数据结构,MISS既可以处理随机数据缺失,即从每个视图中随机删除一些实例,也可以处理连续数据缺失,即某些集群的所有实例完全缺失。
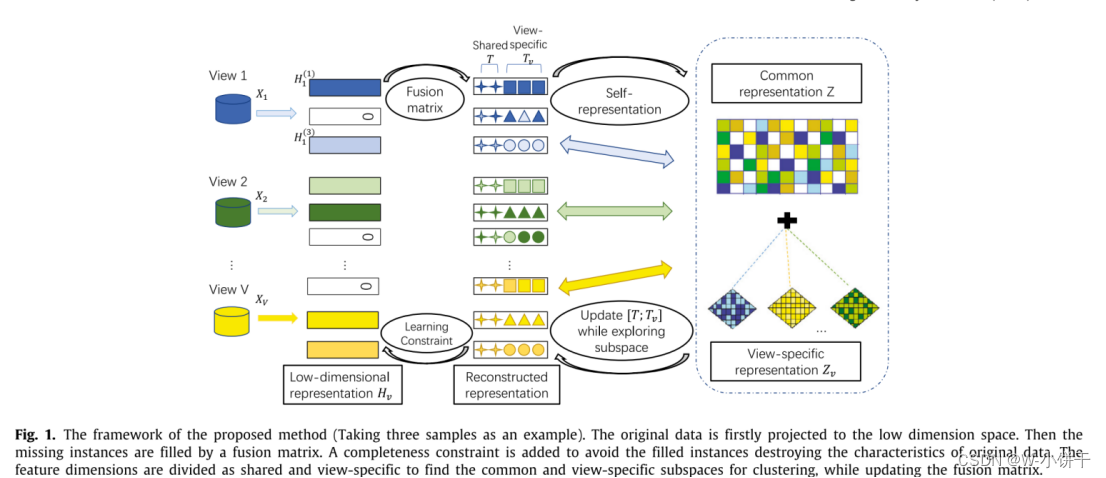
Method
假设给定一个具有部分实例的多视图数据集,并且已知对象在视图中是否有表示。数据集包含V个视图X = {X1,…, XV},每个视图可以描述为XV = {xv^1,…, xv^N}包含N个样本。如果缺少实例,我们将所有维度的特征值设置为0.
投影学习
我们首先将原始数据投影到一个低维潜在空间中,如下所示:
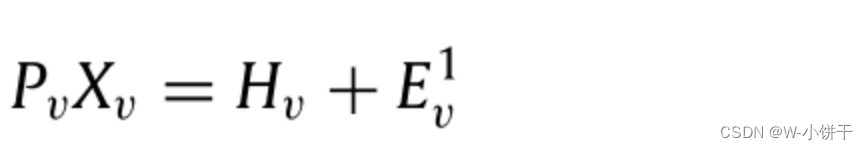
Xv为第v-th视图的原始数据矩阵,Pv为第v-th视图的投影矩阵,Hv为第v-th视图的不完整低维特征矩阵,Ev^1为投影误差项。
融合矩阵
接下来我们将低维特征矩阵Hv与融合矩阵Mv相乘,使得数据完整,得到的第v个视图的低维特征矩阵为

融合矩阵Mv将通过学习潜在空间中的自我表征来更新。如图2所示,我们初始化融合矩阵如下(i i i = j):
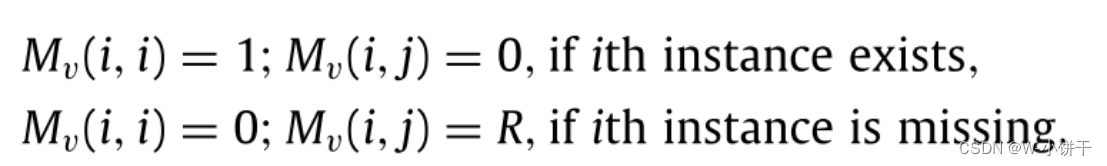
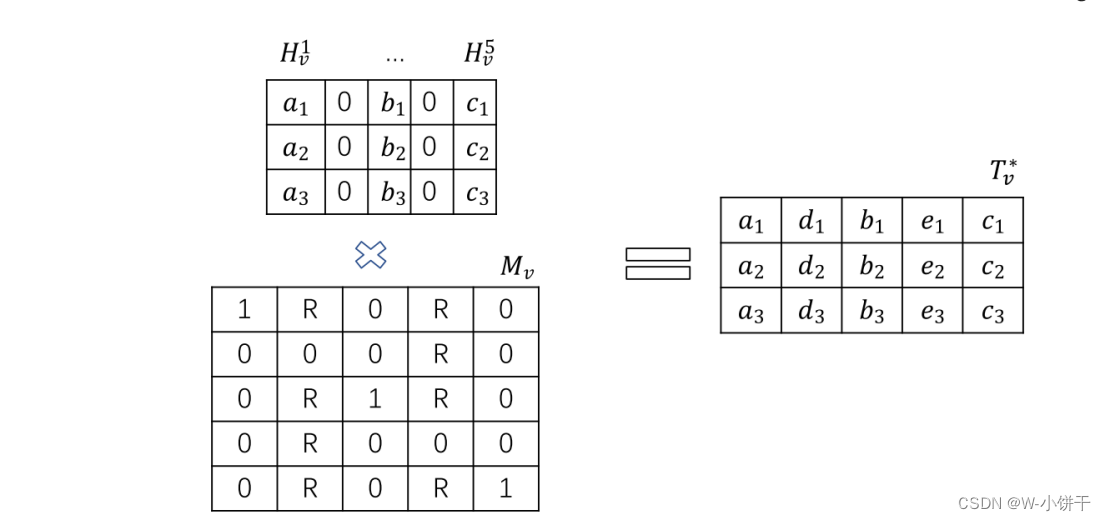
其中,R表示在不完全低维特征矩阵Hv的最小值和最大值之间产生的随机值。
子空间聚类的自表示
将低秩表示T*进行划分,其中T为所有视图共享特征维的低维特征矩阵,Tv为第v个视图唯一特征维的低维特征矩阵。即T*=[T;Tv]。

则自表示如下,Ev^2为自表示误差项,Z和Zv分别为常见的自表示系数矩阵和第v视图唯一的自表示系数矩阵。自表示学习是通过最小化Ev^2来获得[Z, Zv]。

完备性约束
当我们在填充缺失的实例时,不可避免地会对数据的原有特征产生影响。特别是,随着缺失实例的比例逐渐增加,甚至可能导致子空间学习方向错误,最终导致错误的聚类结果,对此我们引入实例填充误差项EH,通过最小化误差项EH,我们学习缺失的实例,同时使它们接近原始的低维特征矩阵。误差项可以避免填充后的低维特征矩阵与原始低维特征矩阵相差太大,从而不破坏原始数据的特征。
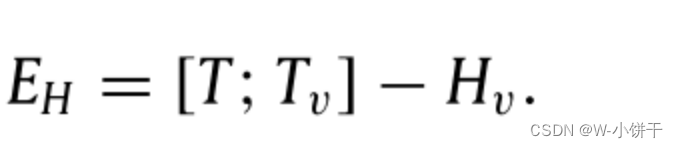
最终的目标函数
通过将潜在空间中填充实例的学习和自我表征学习统一到同一个框架中,我们得到MISS的总目标函数为:
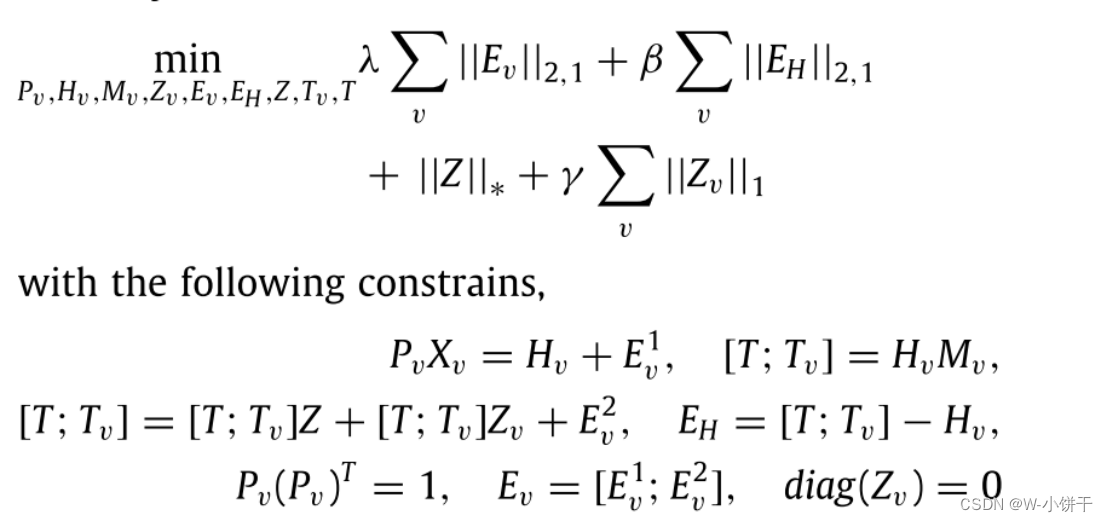
总结:
本文提出了一种在潜在空间(MISS)中同时进行缺失实例融合和子空间学习的方法来解决不完整多视图数据的聚类问题。我们首先通过融合现有数据来填充不完整的数据,然后利用视图之间的共同信息和每个视图特有的信息来学习良好的自表示,最后我们添加约束项来指导填充实例的学习方向。
前景:
由于线性组合在实验中被证明是有效的,期待在方法中加入非线性组合,以进一步改善结果。















 8568
8568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









