






在Stable Diffusion 3(SD3)等生成模型中,CLIP-G、CLIP-L和T5-XXL是三种核心文本编码器,其功能定位和适用场景各有侧重。以下是详细解析:
可通过ComfyUI的多编码器并联节点实现组合调用,具体工作流示例可参考6。
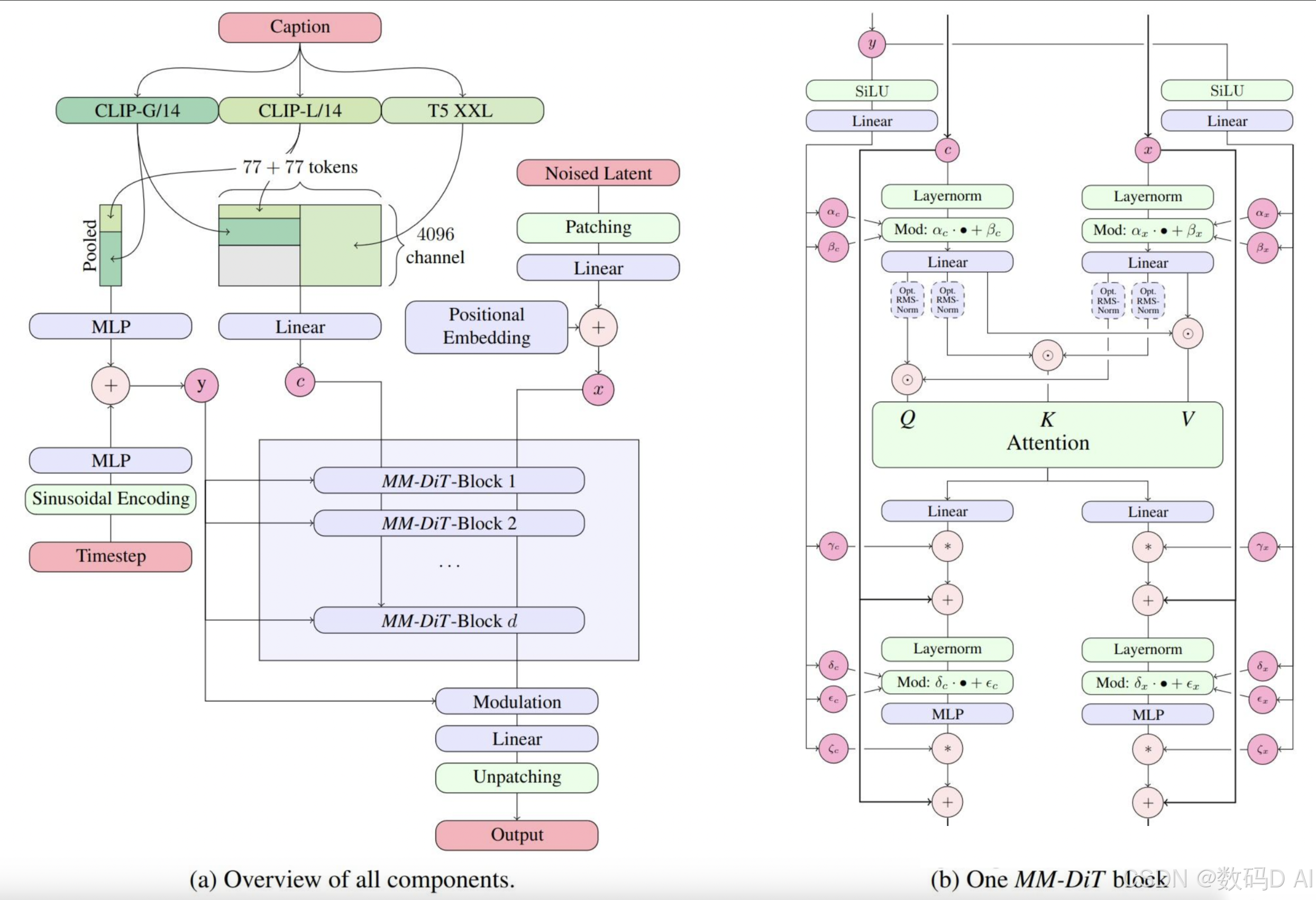
一、CLIP-G(通用型语义编码器)
含义
- 全称:CLIP-G/14(基于CLIP ViT-G/14架构)36
- 设计目的:处理基础语义理解,将用户输入的短文本转换为图像生成所需的向量表示。
- 结构特点:参数量为695M,使用Vision Transformer架构,训练数据覆盖广泛的通用语义关联3。
用法
- 适用场景:短文本提示(如“夏日海滩”),快速提取核心语义。
- 加载方式:SD3模型中默认集成,需搭配其他编码器使用。
- 输入限制:支持77个token以内的文本,超过部分会被截断6。
二、CLIP-L(长文本优化编码器)
含义
- 全称:CLIP-L/14(基于CLIP ViT-L/14架构)36
- 设计目的:优化对复杂长文本的解析能力,捕捉上下文关联和细节描述。
- 结构特点:参数量124M,相比CLIP-G更轻量,但通过训练策略强化长文本处理3。
用法
- 适用场景:包含多条件、多细节的提示词(如“黄昏时分的城市天际线,霓虹灯闪烁,潮湿的街道反射着车灯”)。
- 协同工作:与CLIP-G共同生成77x2048维特征向量,拼接后扩展至77x4096维6。
- 输入优化:支持分段处理,避免关键信息丢失。
三、T5-XXL(增强型多模态编码器)
含义
- 全称:Text-To-Text Transfer Transformer XXL35
- 设计目的:增强对超长文本、专业术语和复杂逻辑的捕捉能力。
- 结构特点:参数量高达4762M,远超CLIP系列,采用序列到序列架构,支持跨模态理解310。
用法
- 适用场景:超过200 token的详细描述,或需要结合外部知识(如科学术语、文学引用)的生成任务。
- 加载要求:需单独下载模型权重(约4.89GB),显存占用较高5。
- 输出特征:生成77x4096维向量,与CLIP特征拼接后形成最终引导信号6。
四、三者的核心区别
| 维度 | CLIP-G | CLIP-L | T5-XXL |
|---|---|---|---|
| 参数量 | 695M3 | 124M3 | 4762M3 |
| 输入长度 | ≤77 token | ≤77 token(分段优化) | 支持超长文本(理论无上限)6 |
| 功能侧重 | 基础语义提取 | 上下文关联与细节解析 | 复杂逻辑与跨模态理解 |
| 显存占用 | 低 | 低 | 高(需8GB以上显存)5 |
| 典型应用 | 快速生成、简单提示 | 艺术创作、多条件控制 | 科研插图、长篇故事板生成 |
五、组合使用建议
- 基础生成:CLIP-G + CLIP-L,兼顾效率与质量1。
- 高精度需求:三者全加载(CLIP-G + CLIP-L + T5-XXL),适合商业级作品5。
- 资源不足时:仅用CLIP-G + CLIP-L,关闭T5-XXL以减少显存消耗3。
在Stable Diffusion 3(SD3)等生成模型中,“反向引导参数”与CLIP-G、CLIP-L、T5-XXL文本编码器的关系体现在语义控制的协同机制上,具体可分为以下四个层面:
反向引导参数与三类编码器构成了语义控制的金字塔结构:CLIP-G提供基础抑制,CLIP-L实现上下文修正,T5-XXL完成逻辑级对抗。这种协同机制使得SD3模型既能快速响应简单排除需求,也能处理专业级创作中的复杂否定逻辑35。
一、参数作用域的互补性
二、权重调整的协同机制
| 编码器类型 | 反向参数作用方式 | 典型案例 |
|---|---|---|
| CLIP-G | 调节全局语义抑制强度(如(water:0.2)降低水体存在感) | 抑制常见元素时效率高3 |
| CLIP-L | 控制上下文关联否定(如(cloudy sky:-1.5)不影响其他天气描述) | 多条件反向控制必备5 |
| T5-XXL | 实现逻辑否定(如no {A, but B}结构) | 复杂概念排除的核心依赖3 |
三、向量空间的对抗优化

四、实践中的协同策略
- 参数组合建议
- 典型工作流示例


















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









