







建模
建模,也被称为训练(Training)模型。包括了两个主要部分,一是数据科学家进行试验,找到解决问题的最佳方案,本节称之为模型试验;二是计算机训练模型的过程,本节在平台支持中介绍。
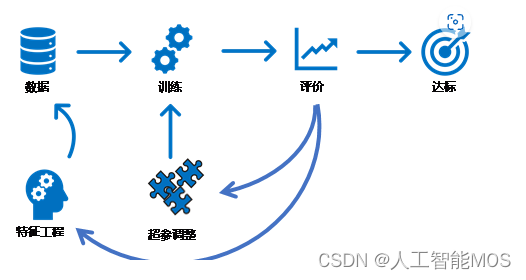
建模是数据科学家的核心工作之一。建模过程涉及到很多数据工作,称为特征工程,主要是调整、转换数据。数据科学家的主要任务是要让数据发挥出最大的价值,解决业务需求,或发现未知的问题,从而提升业务。建设机器学习平台时,要对数据科学家的工作有一定理解,才能建设出真正能帮助数据科学家的平台。
模型试验
特征工程与超参调整是建模过程中的核心工作。
特征工程是指对数据进行预处理,使处理后输入模型的数据能更好的表达信息,并提升输出结果的质量。特征工程是机器学习中非常重要的一环。数据和特征工程决定了模型质量的上限,而算法和超参只是逼近了这个上限。
超参调整包括选择算法、网络结构、初始参数等工作。这些工作不仅需要丰富的经验,也需要不断地试验来测试效果。
特征工程与超参调整不是独立的过程。做完特征工程后,即要开始通过超参的组合来试验模型的效果。如果结果不够理想,就要从特征工程、超参两方面来思索、改进,经过一次次迭代,才能达到理想的效果。
特征工程
特征工程的内涵非常丰富,在输入模型前的所有数据处理过程都可以归到特征工程的范畴。通过特征工程,将人的知识(通常称为先验知识)加入到数据中,并降维来减小计算规模,从而提高模型性能和计算效率。
特征工程的数据处理过程大部分都可以在数据转换阶段进行。可以将常见的特征工程的处理函数抽象为数据转换组件,方便重用。
特征工程的主要内容有:
-
数据清洗。在数据部分已介绍过,即处理异常数据,或对数据进行修正。
-
纠正数据偏离(bias)。
在一些应用中,虽然有大量的数据,但数据分布并不均衡。如,在流水线检测缺陷产品的场景下,如果缺陷率为千分之一,那么原始数据里99.9%都是正常产品的图片,只有0.1%是缺陷数据。这种情况下,训练出来的模型质量不会太高。
还有些情况下,数据偏离很难被发现。比如,互联网新闻图片下训练的分类模型,在用于手机摄像头照片分类时,效果会差很多。原因是新闻图片通常选择了颜色饱满丰富,构图优美的图片,和用户自己拍摄照片的色彩构图上有不小的差异。
这种情况下,一旦发现了数据偏离就要从数据和算法两方面来调整。有的机器学习算法能够自动将小量数据的作用放大。但大部分情况下,需要人工对数据比重进行调整,并引入接近真实情况的数据集。
-
数值变换。机器学习需要的数据都是数值,如果是浮点数,一般要调整到0~1之间。枚举值要拆成一组布尔值。不同来源的数据还要做计量单位的统一。
-
输入先验知识。即根据人的判断,将一些数据中难以直接学习到的信息抽取成特征,从而减小学习难度。如,自然语言的评价分类问题中,可以建词表,将正面词语和负面词语总结出来,对每句话的正负面词计数,并作为单独的特征列。这样对正面负面的分类判断会有较大的帮助。虽然数据维度会增加,但模型有了更多的人类先验知识,会判断得更准确。
-
数据降维。是在尽量不丢失信息的情况下,减小单条数据的大小,从而减小计算量。比较直观的降维方式就是把图片缩小到一定的尺寸,减小像素数量。深度学习是在多层网络里,保留信息的同时,逐步给数据降维。机器学习算法中的主成分分析(Primary Component Analysis, PCA)和线性判别分析(Linear Discriminant Analysis,LDA)是经典的降维方法,用线代的矩阵特征分解的算法,找出数据中区分度最大的特征,然后省略一些作用不大的特征。
超参调整
在机器学习中,模型能够自己学习改变的权重等数据,叫做参数。而不能通过机器学习改变,需要提前人为指定的参数叫做超参数(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









