






DeepSeek作为国产大模型之光,惊人的语言理解和生成能力让人纷纷表示“离不开了”如何将这个强大的模型与我们的私有知识库结合,打造出既智能又专属的问答系统?
本篇内容将以DeepSeek R1蒸馏模型,结合Windows系统为展示案例,帮助0基础的小伙伴打造自己的第一个私有知识库问答系统。
一、Ollama+DeepSeek R1本地部署
●模型选择与硬件配置说明
为了照顾0基础用户,本节公开课以 Windows 系统为例进行演示, MacOS 、 Linux 系统实现方式也类似。
公开课重点介绍完全本地部署实现方案,并采用 DeepSeek R1 蒸馏模型进行演示,若硬件条件允许,也可考虑部署原版 DeepSeek R1 模型。
各模型运行所需显存如下:
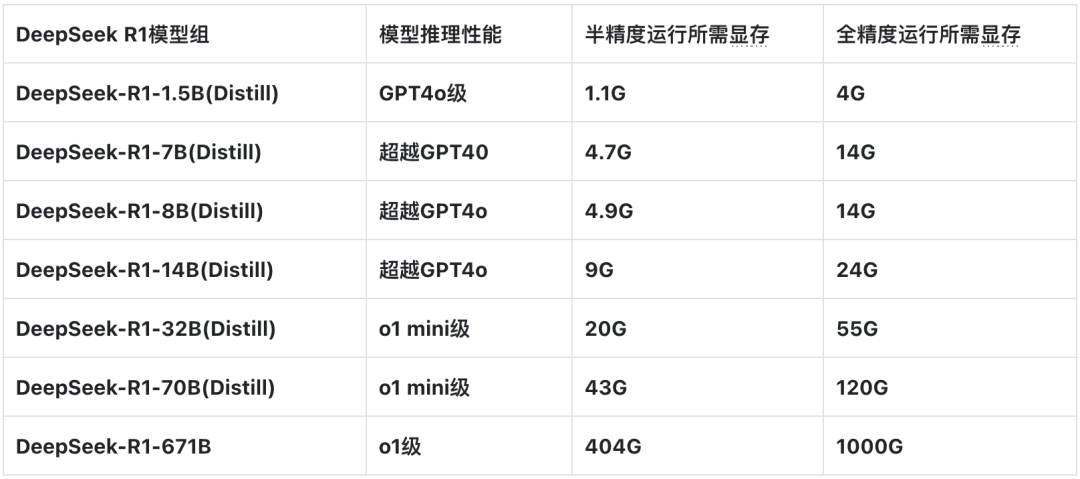
而关于如何使用 DeepSeek R1 在线 API 实现相关功能,详见 Part 4 部分内容介绍。
●模型本地调度框架选取
同其他主流大模型对话 Web 框架类似, AnythingLLM 同时支持调用在线模型 API 、或本地模型进行推理。
并且 AnythingLLM 本身是一款集成度非常高的聊天框架,我们只需要借助可视化页面手动点击选择在线模型 API 或者本地推理框架即可。
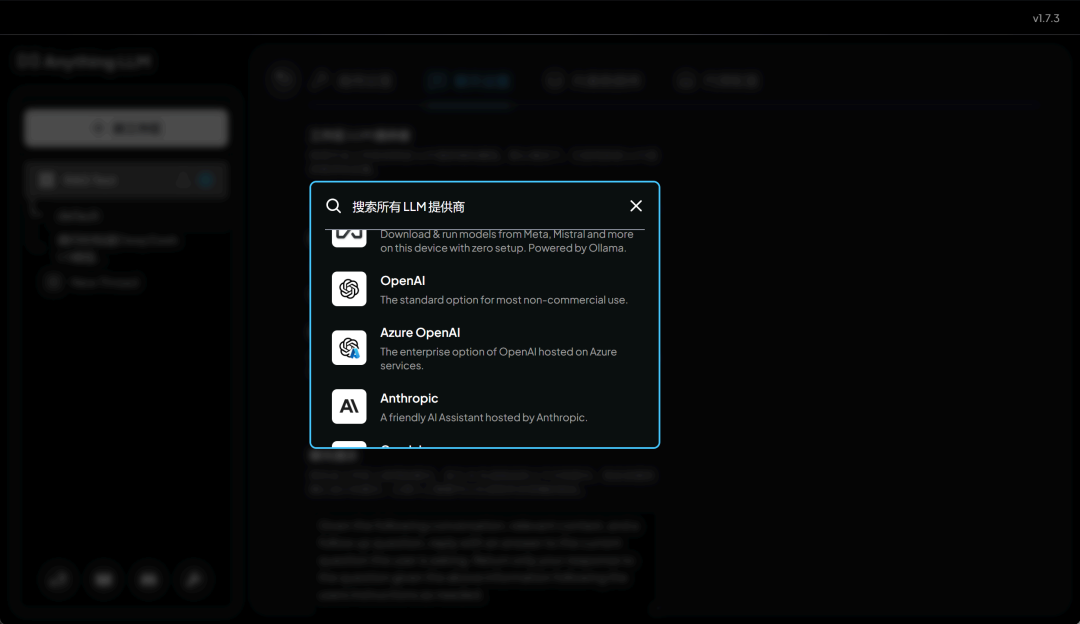
例如一些主流 API 厂商:
或者一些主流的本地推理框架:
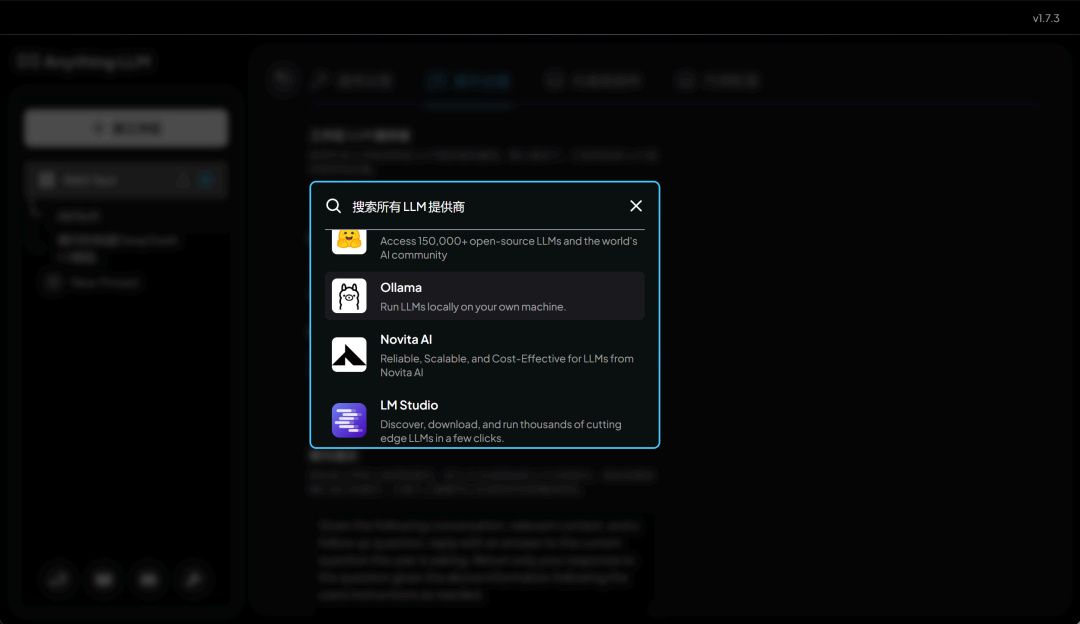
本节公开课我们将以 Ollama 为例进行演示。
Step 1.安装 ollama
首先需要先安装 ollama 地址,下载地址:https : //ollama.com/
选择对应的操作系统进行安装即可:
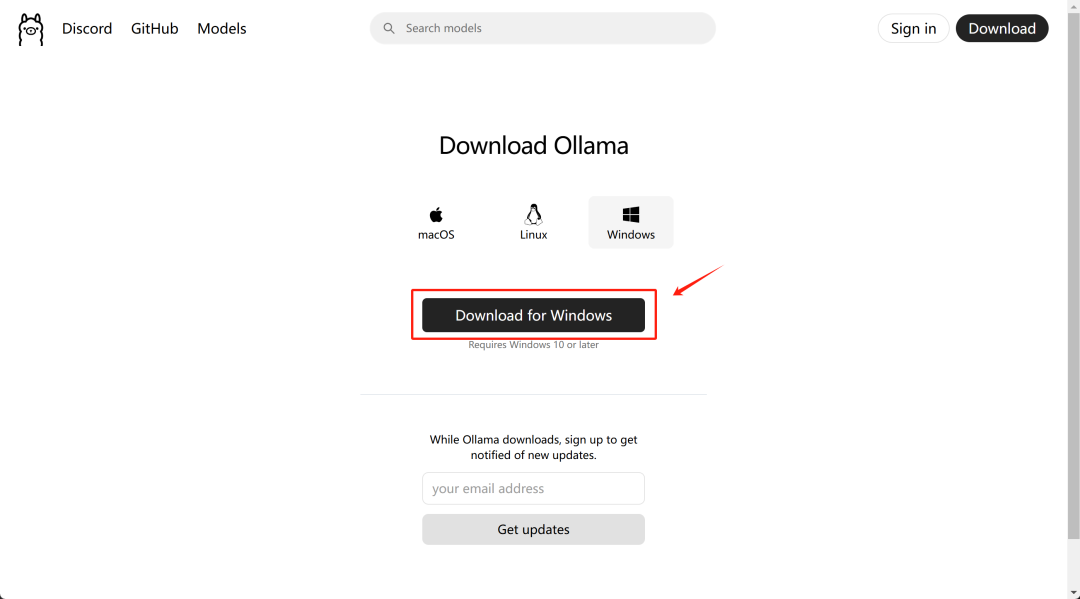
Ollama 下载存在网络限制,对应 Windows 、 MacOS 软件安装包开在课件网盘中领取,公众号后台回复【777】即可领取详细资料。
下载后即可开始安装:
而当 Ollama 安装结束后,会自动在后台开启 Ollama 进程, Windows 系统下可以按住 Win+r 键,输入 cmd 开启命令行,并在命令行中查看 Ollama 运行情况:
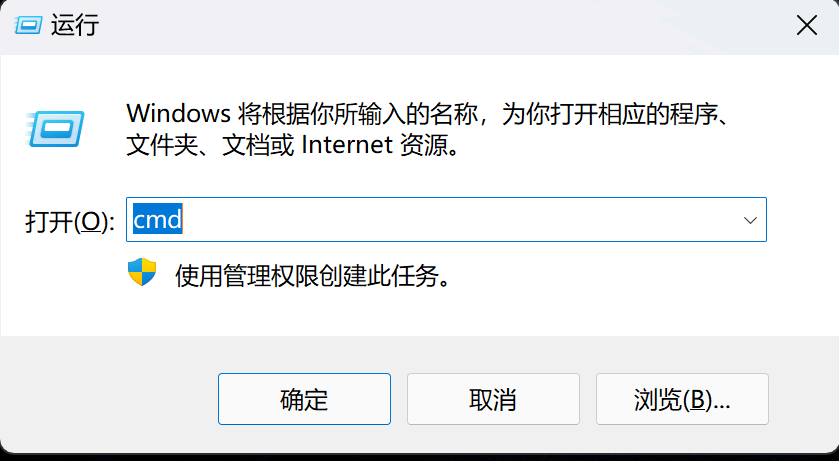
例如,输入 tasklist |findstr ollama 查看 Ollama 进程是否存在
如此则说明 Ollama 已启动。
若未启动,可输入ollama start 启动 Ollama 。
Step 2.下载 DeepSeek R1 模型
接下来即可进一步下载 DeepSeek R1 模型了。
这里我们可以直接使用ollama pull 命令自动下载与注册,也可以手动下载模型的 GGUF 文件,然后手动完成 Ollama 模型注册,再进行调用。
也可以参考九天老师的另一个视频:《 DeepSeek R1 本地部署流程详解 》
https : //www.bilibili.com/video/BV19kFoe6Ef7/
从魔搭社区上手动下载模型 GGUF 权重,并完成 Ollama 注册与调用。
首先输入 Ollama list 查看当前模型列表:
然后回到 ollama deepseek r1 模型列表,查看模型组情况:
https : //ollama.com/librarv/deepseek-r1
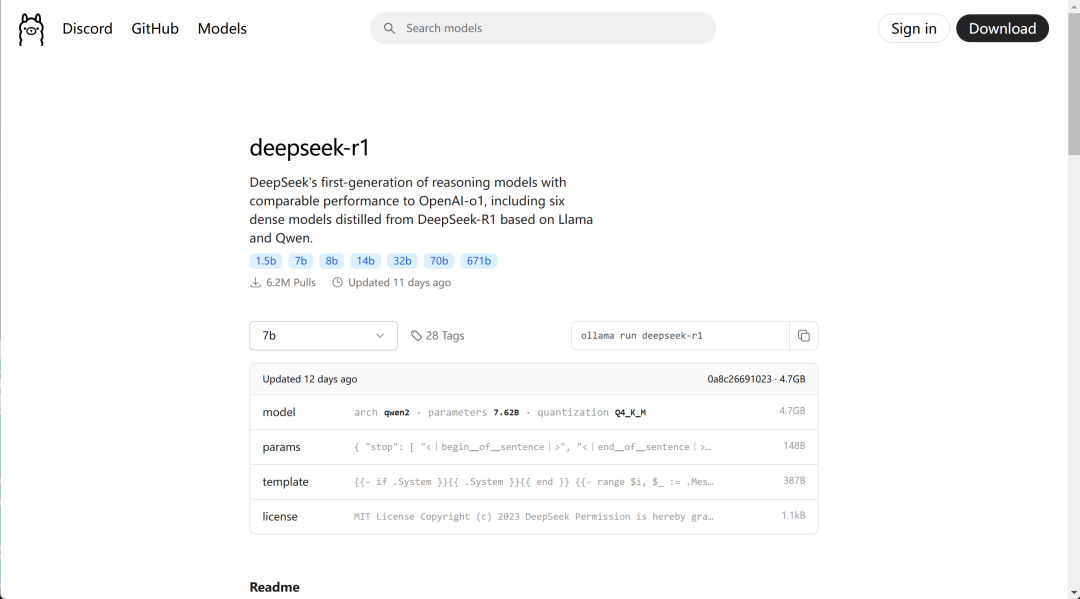
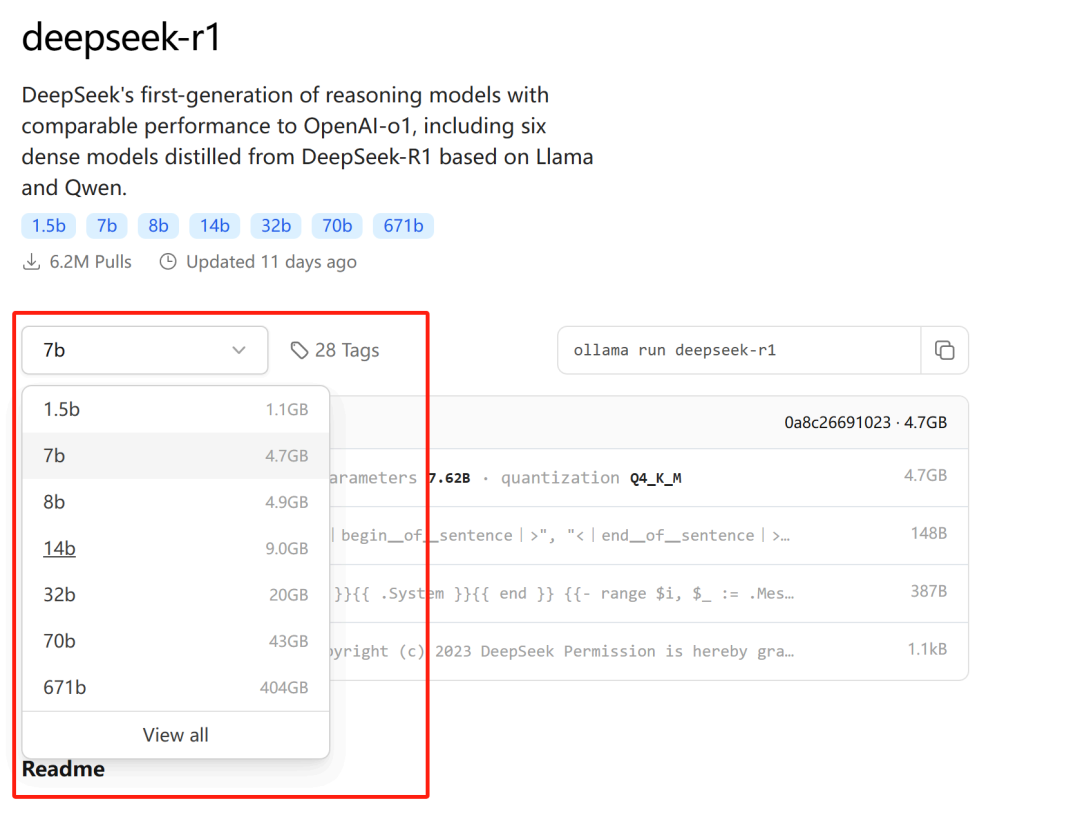
其中不同尺寸模型运行所需占用显存大小如上所示。
需要注意的是, ollama 只支持运行 Q4 K M 模型,相当于是 4bit 量化后的模型,因此每个模型运行所需占用显存并不大。
接下来使用如下命令下载模型,这里以 14b 模型为例,下载其他模型的话只需要修改模型名称即可。
例如修改为 deepseek-r1 : 7b ,则代表下载 7b 模型:
ollama pull deepseek-r1 : 14b
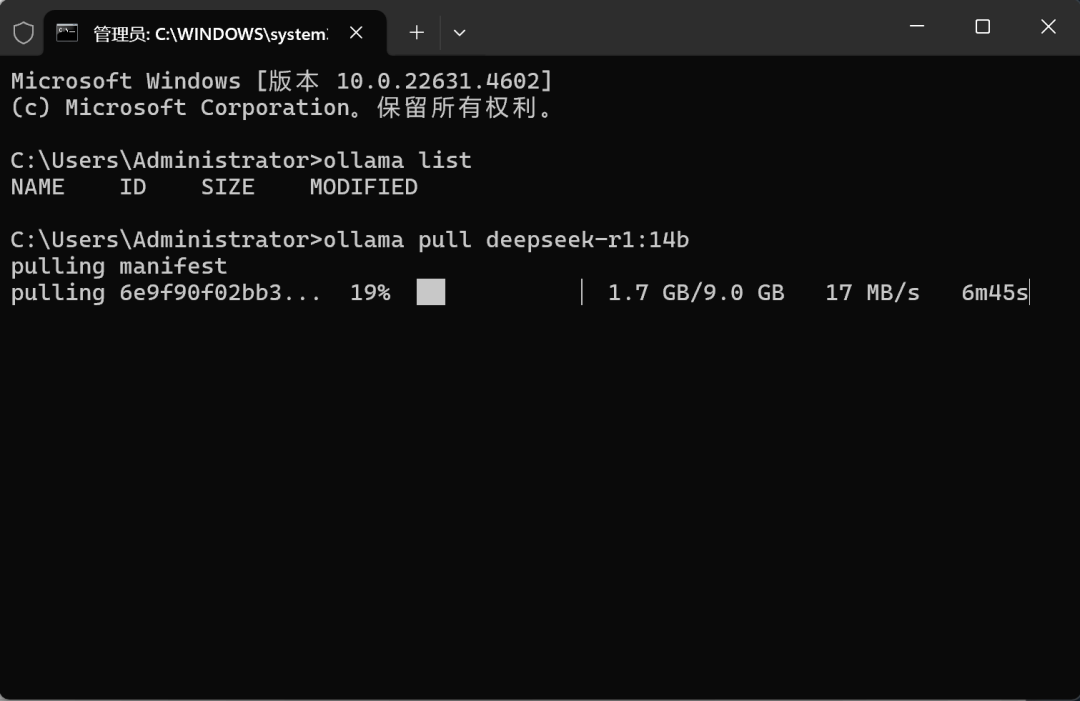
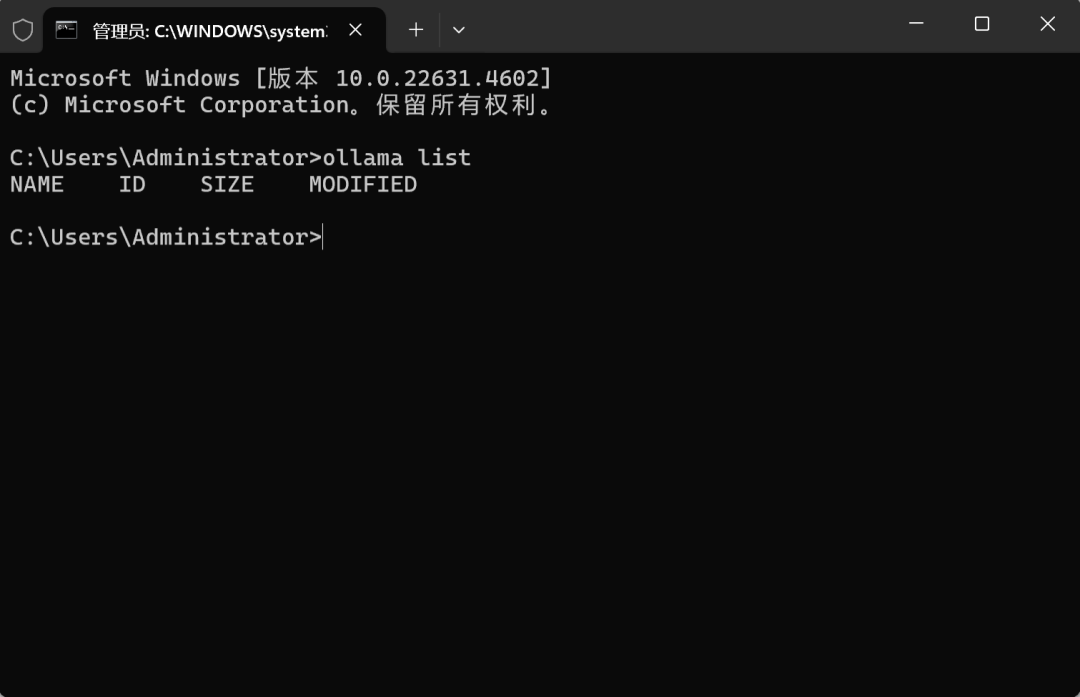
稍等片刻即可完成下载。下载完成后即可使用0llama list 命令查看当前模型是否完成下载与注册:
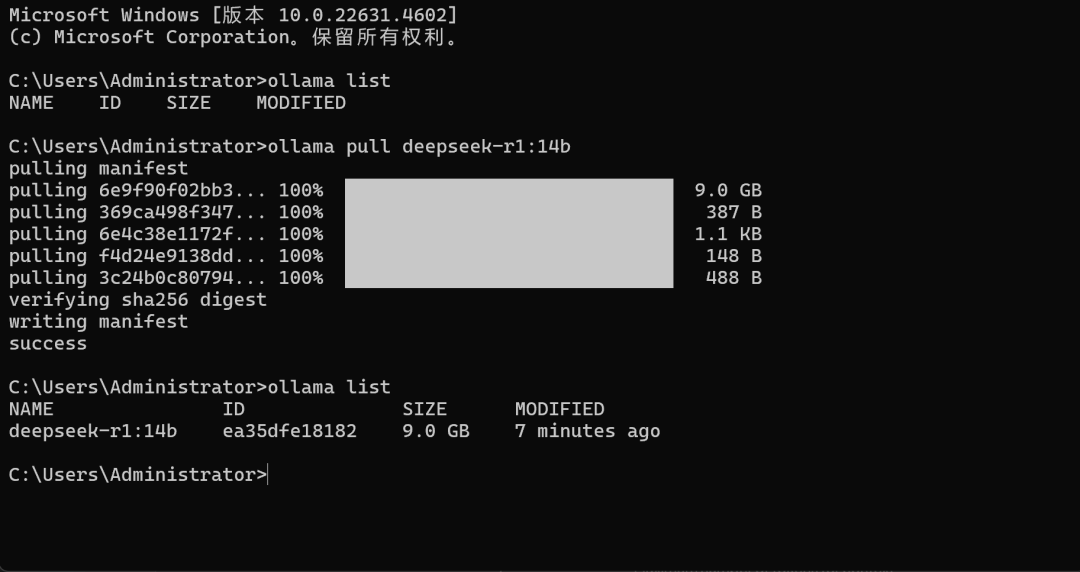
接下来即可调用 DeepSeek R1 Distill 14B 模型进行本地知识库问答了。
二、A n y t h i n g L L M 安装与使用
AnythingLLM 是一款集成度非常高、且功能非常稳定的大模型对话前端产品。
虽无法进行二次开发,但功能实现方面非常便捷,可以直接从 AnythingLLM 官网进行下载:https : //anvthingllm.com/
选择对应的操作系统版本下载安装即可开始安装:
安装完成后,会自动启动 AnythingLLM , 并进入设置页面
点击 Get started , 则进入到选择 LLM 页面:
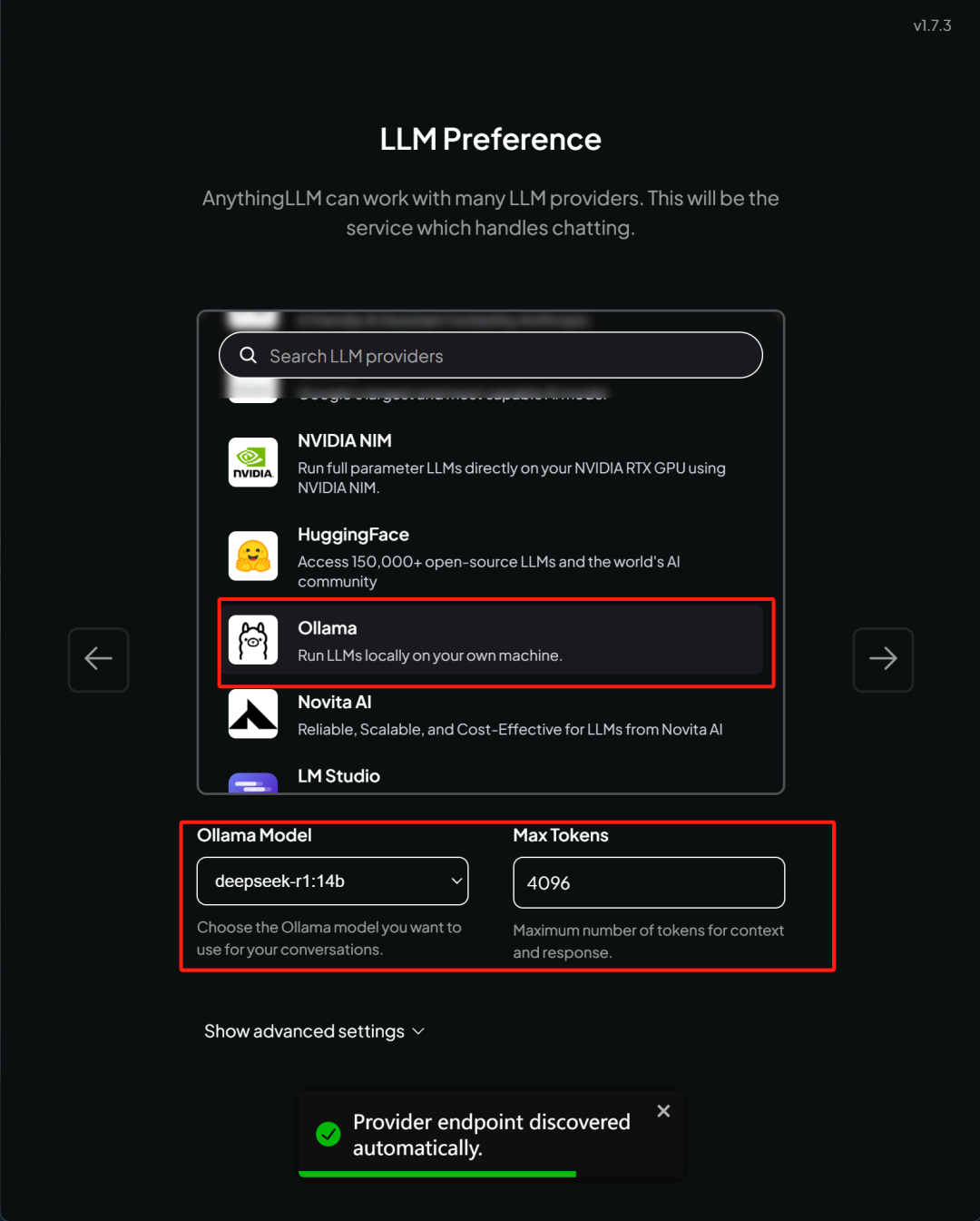
这里我们选择借助 Ollama 来调用本地的 14B 模型。
需要注意的是, AnythingLLM 会自动检测 Ollama 进程是否存在 ( 也就是 Ollama 是否启动 ) 以及现在 Ollama 中已经注册了哪些模型。
因此在进入到上面这个设置也面前,需要确保 Ollama 已经启动,并且已完成了相关模型注册。选择好 14B 模型之后即可点击进入下一步:
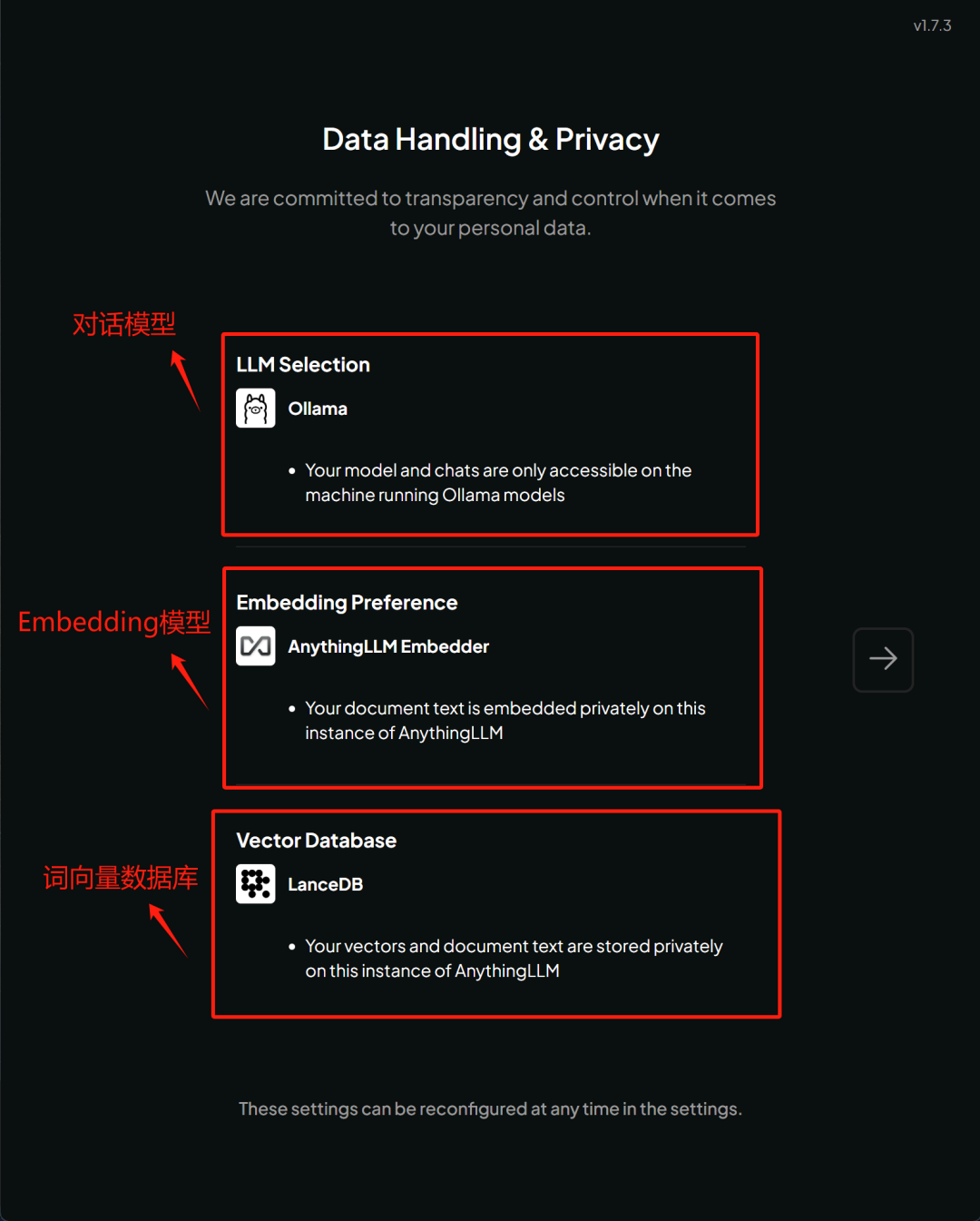
该页面是进行模型配置说明,当前的模型配置是:
●对话模型:负责完成对话任务,由 Ollama 调度 DeepSeek R1 Distill 14B 来完成对话;
● Embedding 模型:负责进行词向量化的模型,由 AnythingLLM 官方提供;
●词向量数据库:用于存储词向量化之后的对象,默认为 LancelotDB;
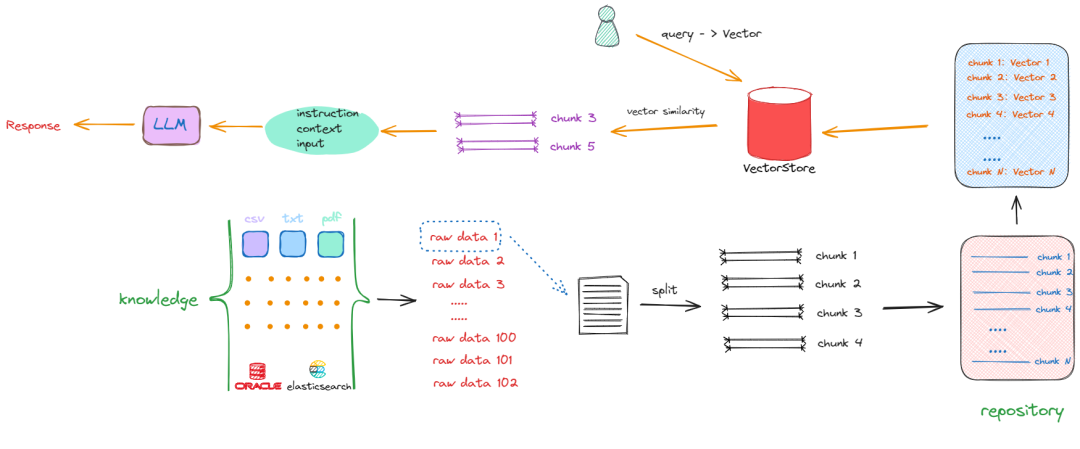
对于任何一个本地知识库问答的过程,都需要经历文本切割、词向量化、词向量存储、词向量检索与问答几个基本环节,因此至少需要 Chat 模型、 Embedding 模型以及词向量数据库作为基础组件。对于 RAG 的基本原理回顾如下:
在浏览了当前模型配置后,接下来即将进入 AnythingLLM 注册页面,这里可以直接跳过:
然后需要创建一个 workspace , 相当于是 ChatGPT 或者其他开发项目的一个 Project , 用于对对话进行分类:
当我们进入到如下页面,则说明安装成功:
接下来即可尝试进行对话了。
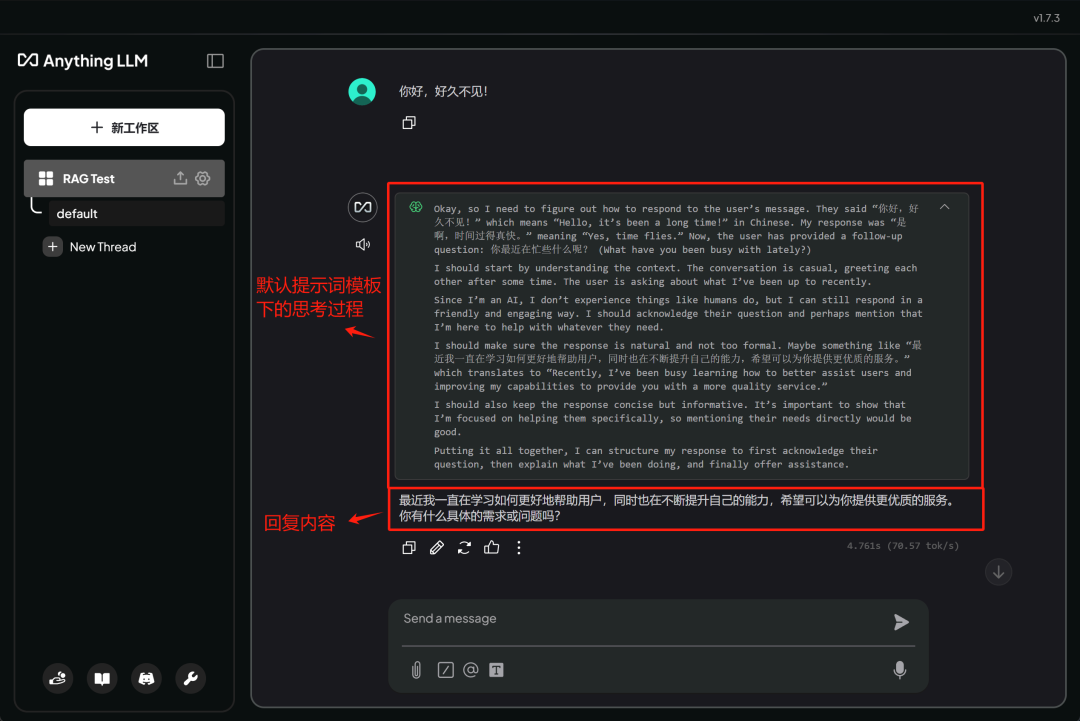
AnythingLLM 对于 DeepSeek R1 系列模型的支持是非常友好的,甚至会区分思考过程和回答过程:
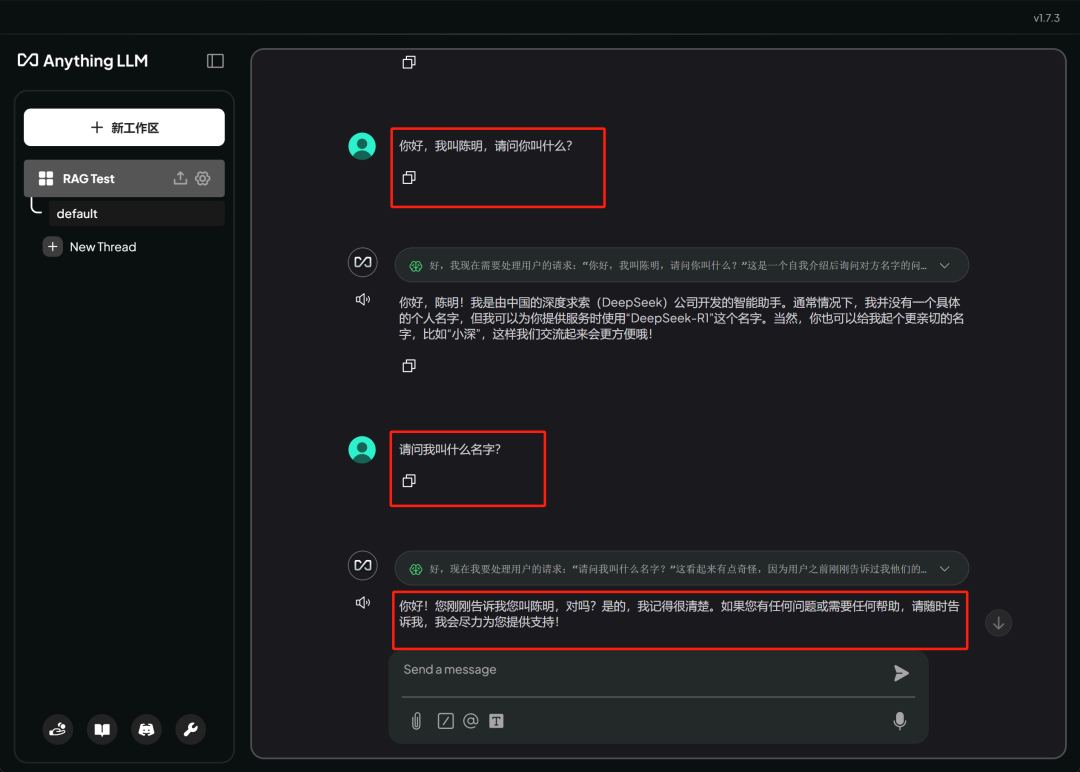
并且支持多轮对话:
三、借助 Anything LL M 进行本地知识库问答
AnythingLLM 是一款集成度非常高、且运行稳定的 RAG+ 前端对话框架,我们可以非常便捷的为每次对话设置知识库。主要方法有以下两种:
●在单次问答中设置背景文本
例如,我们可以直接在对话框下方点击回形针按钮,即可上传文本并进行对话,整个过程类似 ChatGPT 的功能实现:
注意,这里所谓上传文本,并不是把文本上传到远程服务器,而是将文本进行切分、 Embedding 后后上传到本地的 LanceDB 词向量数据库中。整个过程全部都在本地完成。
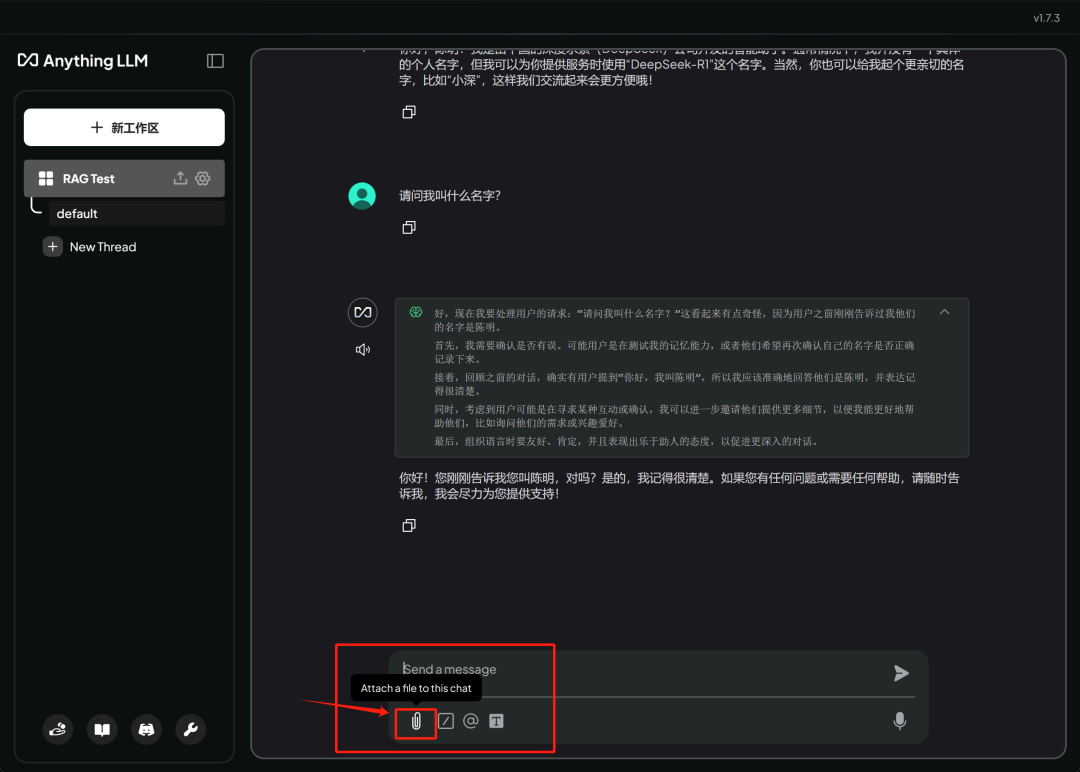
上传文本:
等待文本切分与词向量化过程
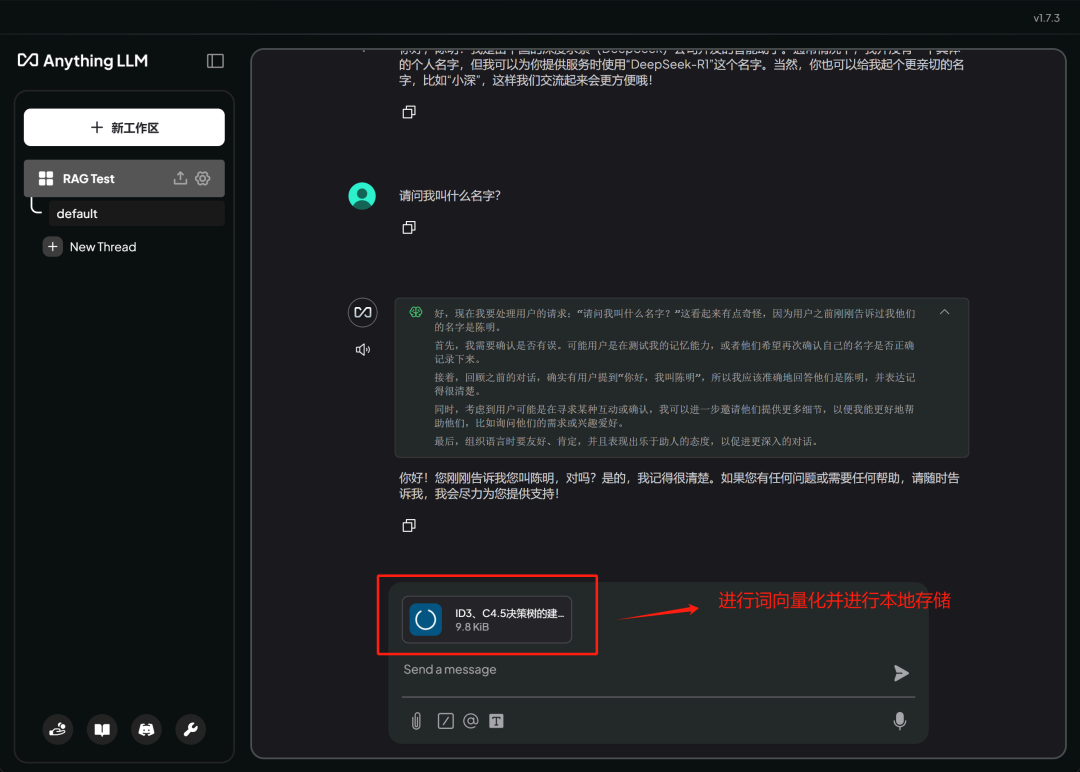
然后即可开始问答:
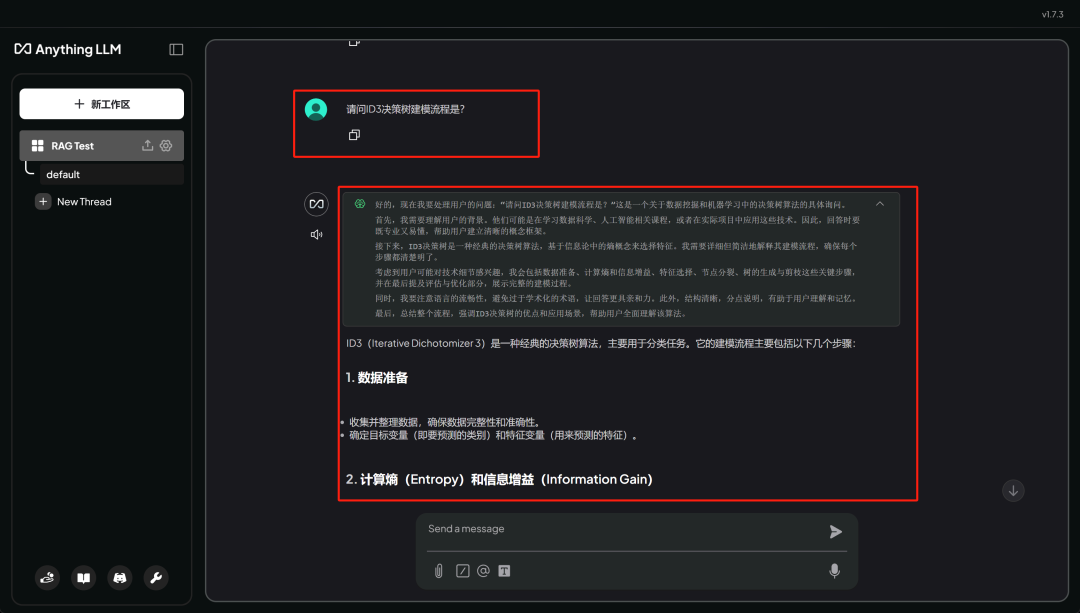
此时进行问答即会根据文档进行回答。
●统一知识库管理
此外,若想让整个文本长期存在于当前对话中,则需要借助 AnythingLLM 的知识库管理功能。
下面这个 icon 就是知识库管理图标 :
点击后即可进入到如下页面:
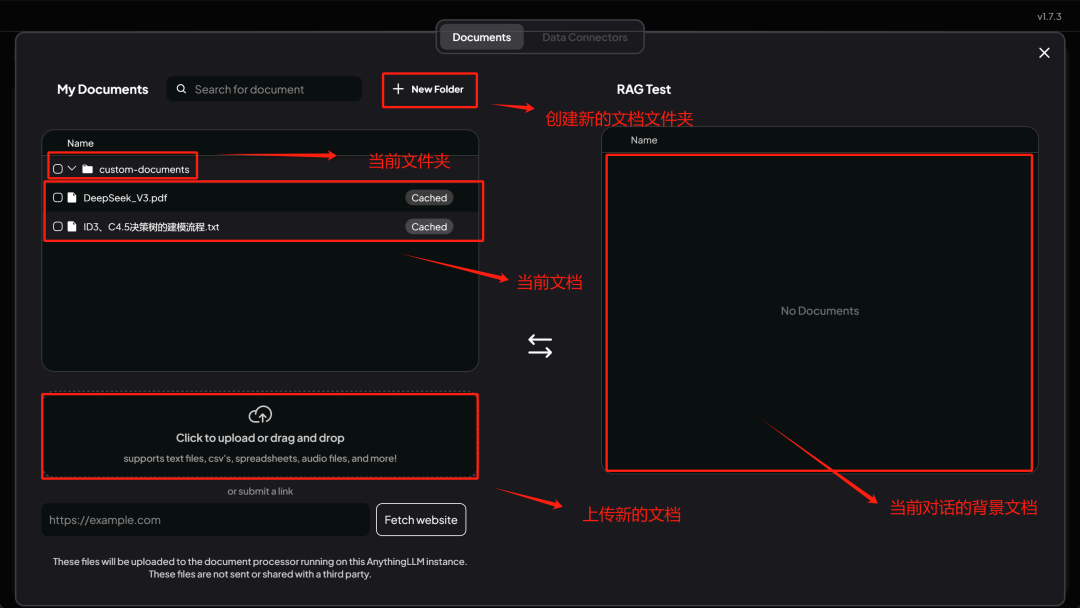
这里我们额外上传一份 DeepSeek V3 技术报告,该报告的内容超出了当前模型只是范畴,适合进行本地文档问答测试:
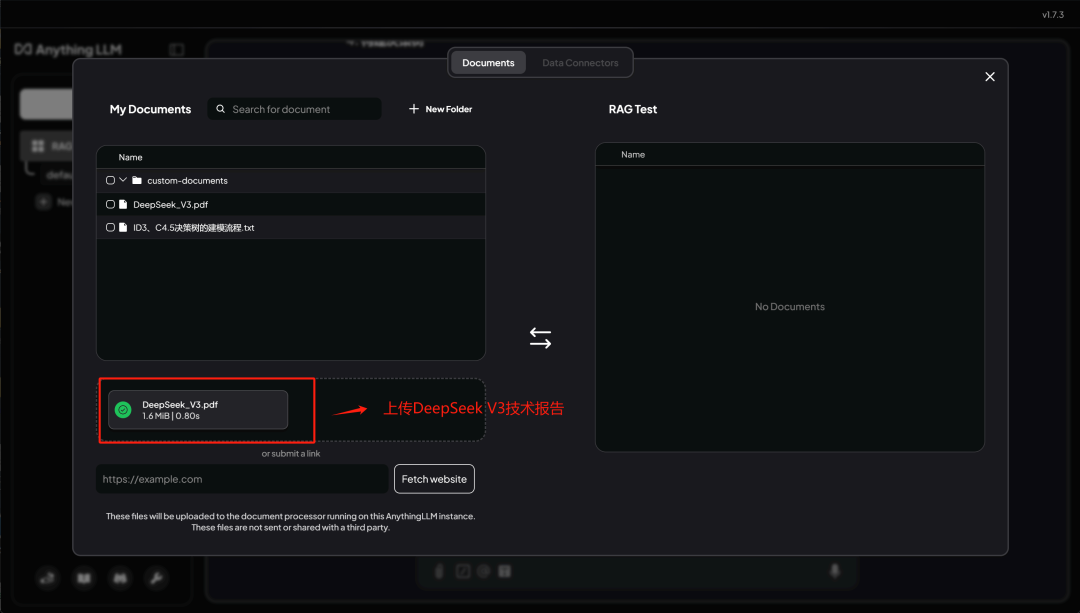
上传后即可在当前文件夹中看到该文件,这里点击 Move to Workspace , 即可将其列举为备选问答文档:
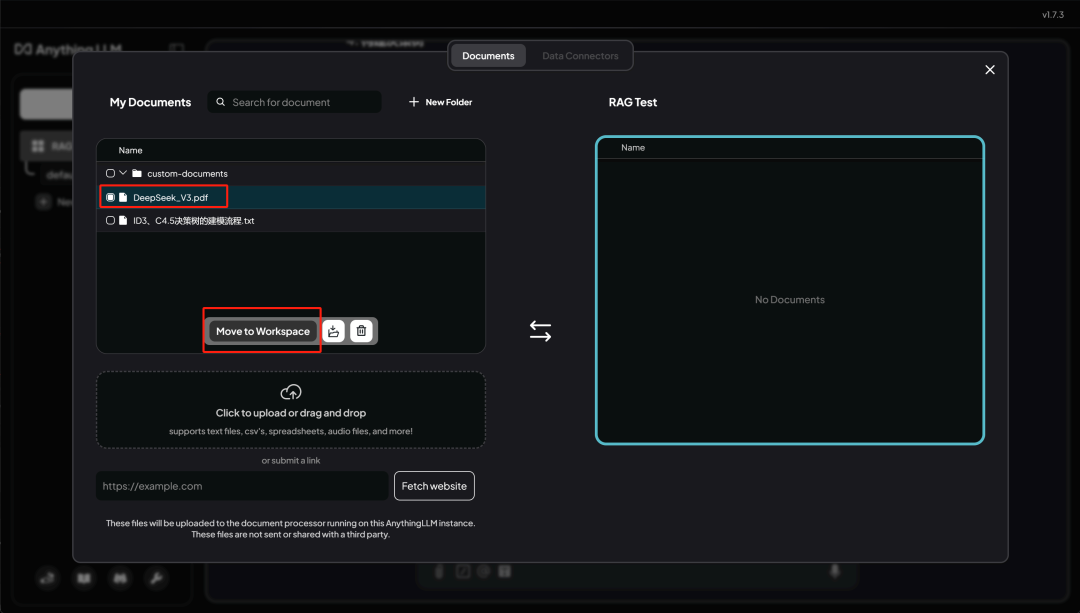
当 Move to workspace 后,在右侧即可看到这篇文档,然后点击 Save and Embed , 即可开始进行文档切分和词向量化过程:
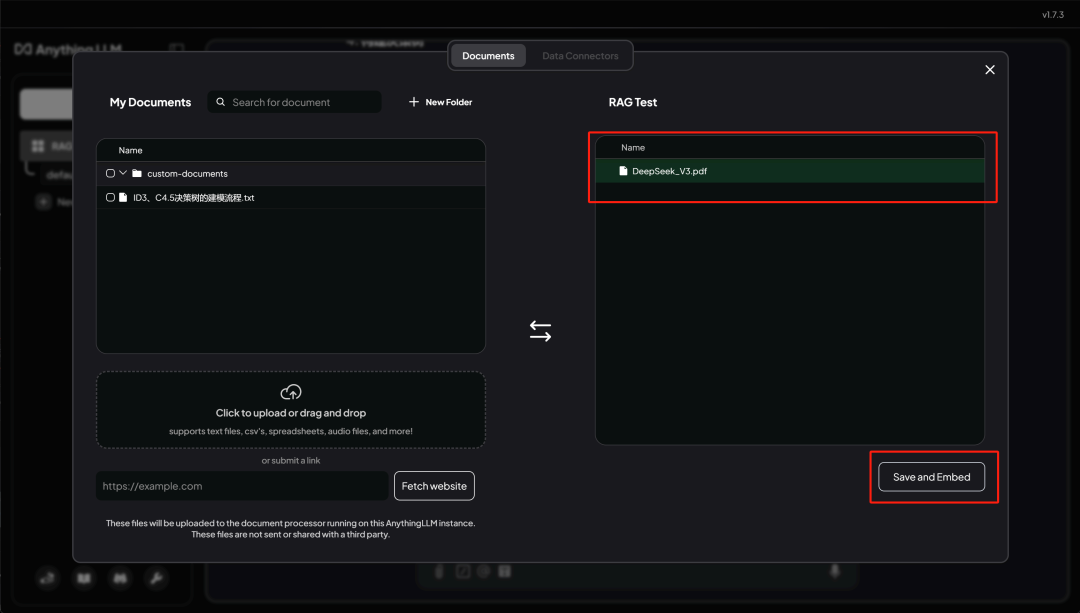
完成后,再点击图钉按钮,即可将这篇文档设置为当前对话的背景文档:
然后点击 got it
然后即可提问:
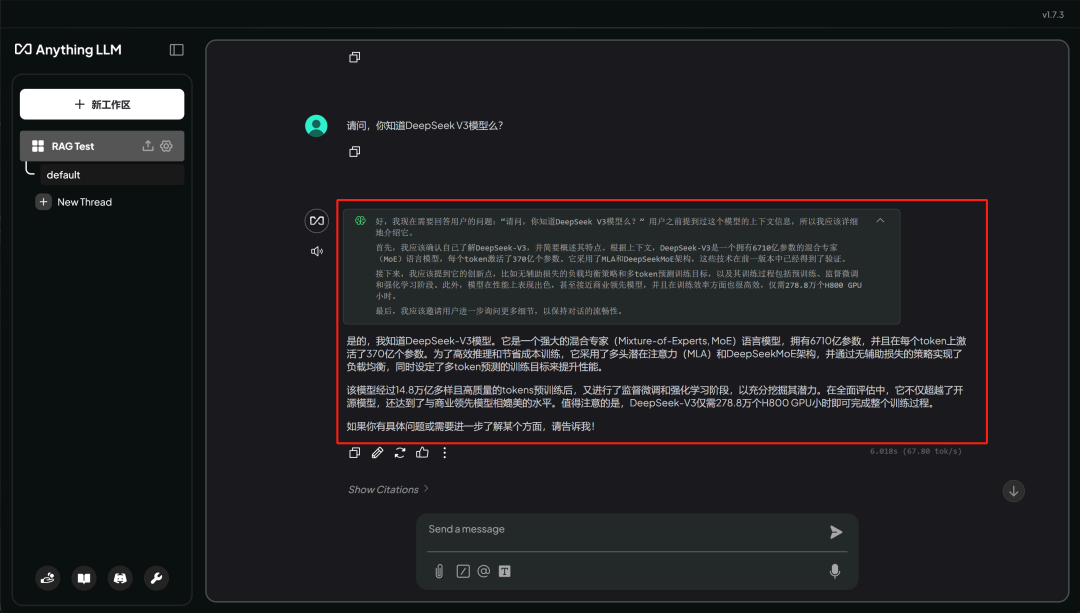
能够看出,此时回答结果就会根据当前文档进行回答,细节丰满回答流畅。
而若不绑定知识库,则模型并不知道 DeepSeek V3 模型:
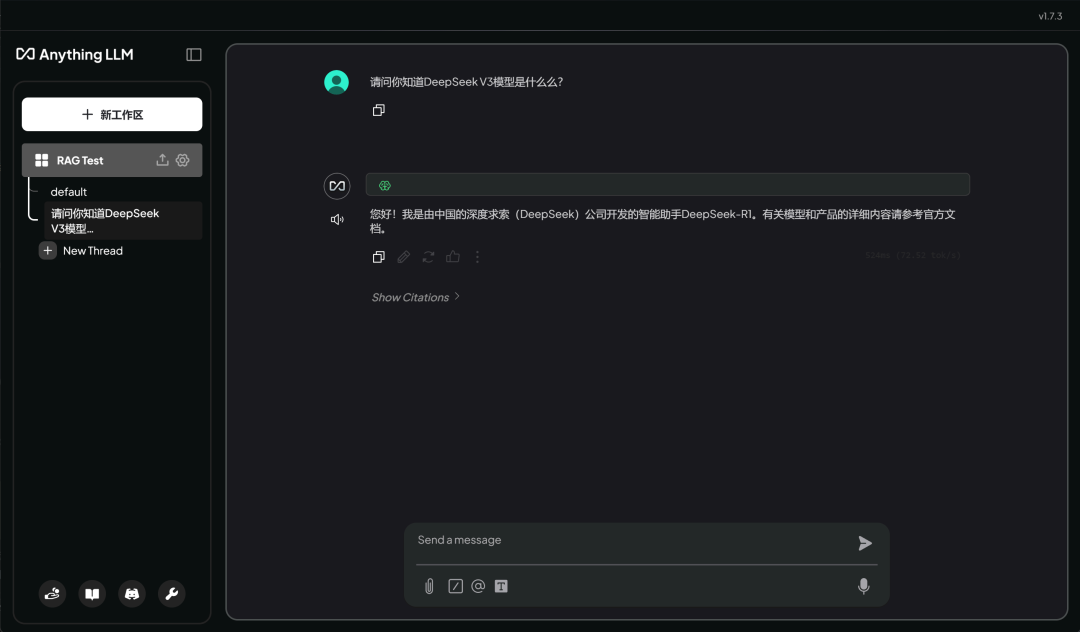
至此,即完成了 DeepSeek R1 Distill 14B 模型的本地知识库问答全流程。
四、 DeepSeek R1 API 接入 AnythingLLM 进行本地知识库问答
最后,让我们来看下如何借助 DeepSeek R1 API+AnythingLLM 来进行本地知识库问答。首先,新建一个工作区,并命名为 RAG Test2
然后点击设置按钮:
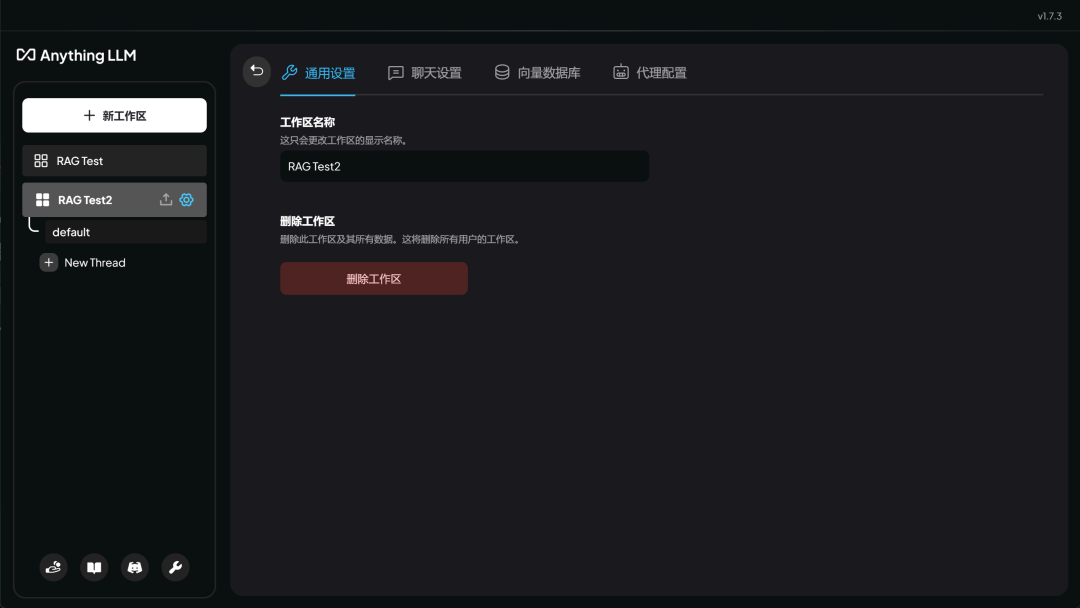
设置页面,我们可以灵活设置当前工作区域的名称 ( 或者删除工作区 )
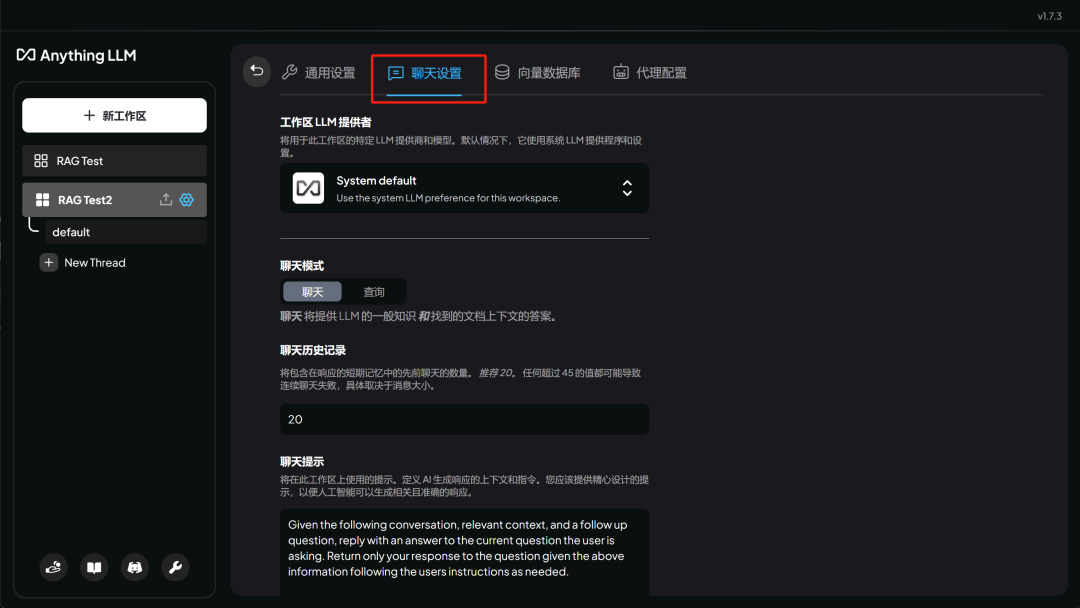
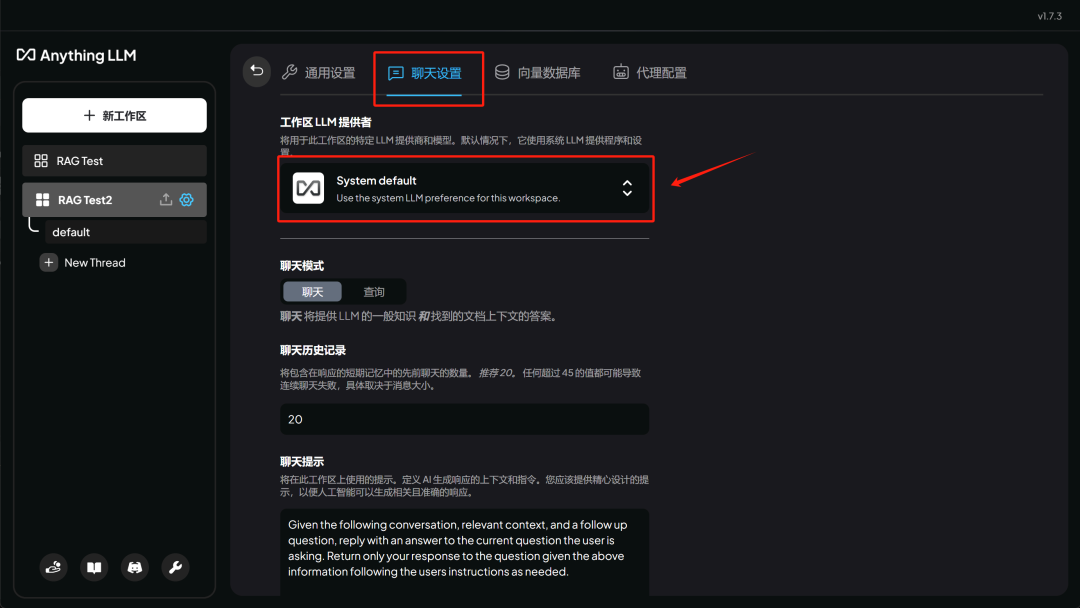
或者修改默认模型,以及 system message ( 系统默认提示 ) :
以及进行词向量数据库设置等。
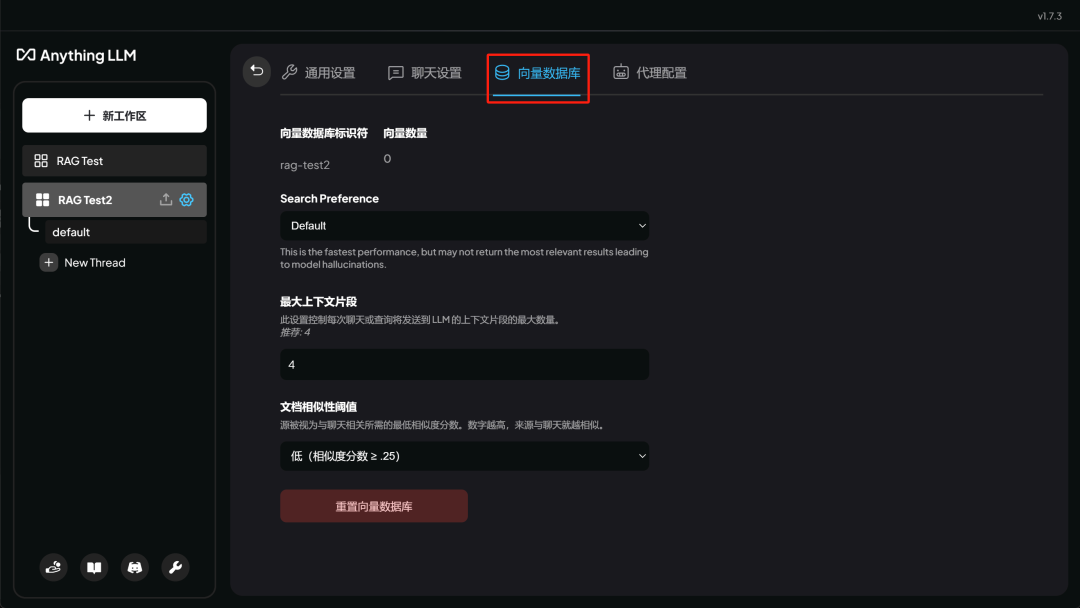
这里我们需要在聊天设置中修改模型为 DeepSeek R1 API , 先点击聊天设置,然后选择模型:
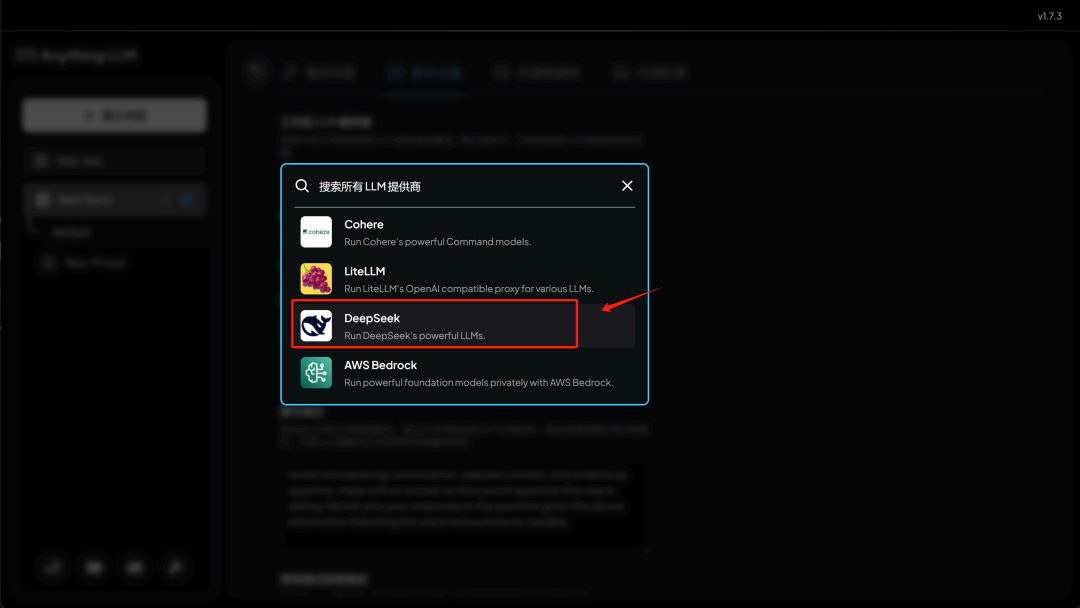
然后在模型提供商中选择 DeepSeek :
然后在弹出的页面输入 API-KEY
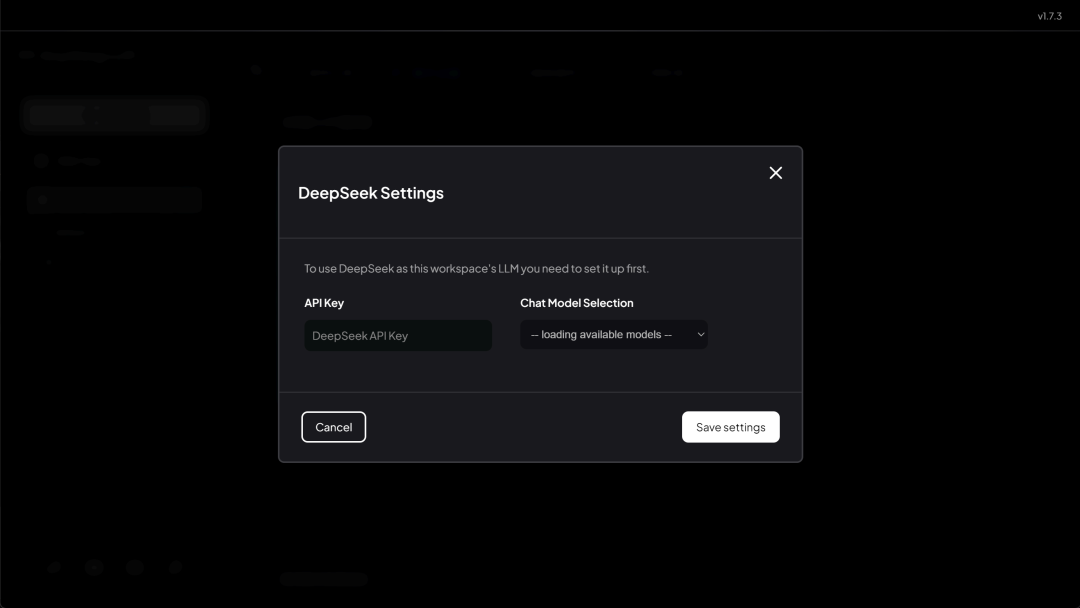
输入完 API-Key 后,即可选择对话模型。
deepseek-chat 就是 DeepSeek V3 , 而 deepseek-reasoner 则是 DeepSeek R1 。
这里我们选择 deepseek-reasoner :
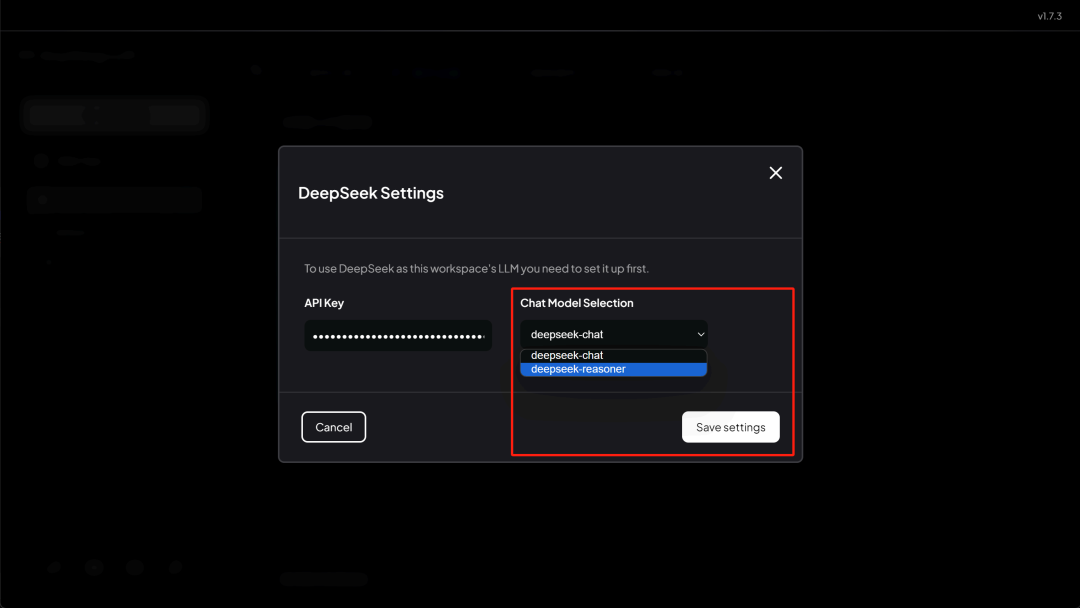
然后点击 Save , 即可返回设置页面:
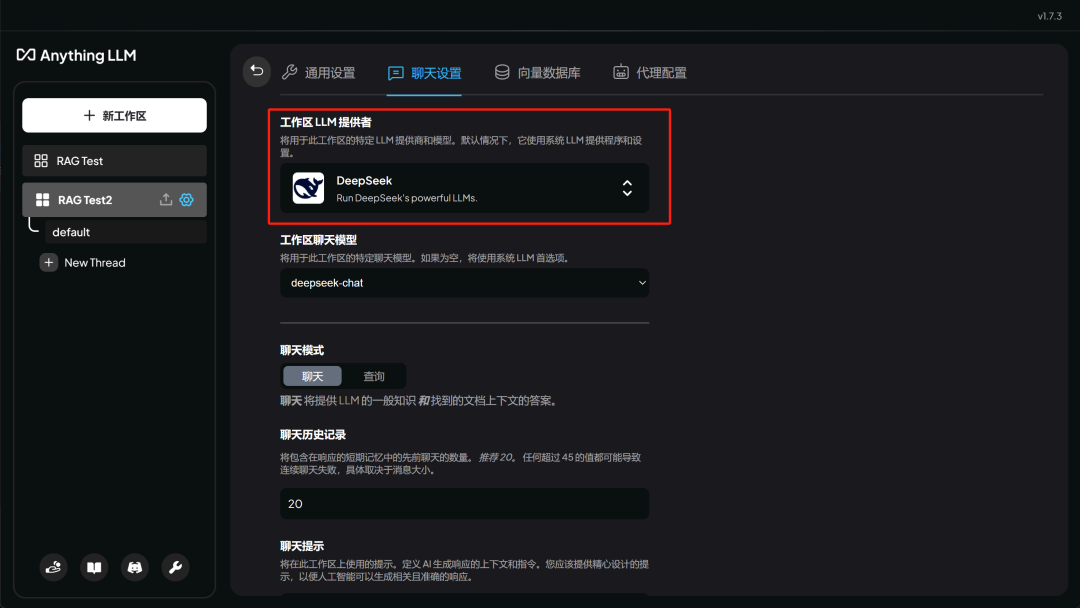
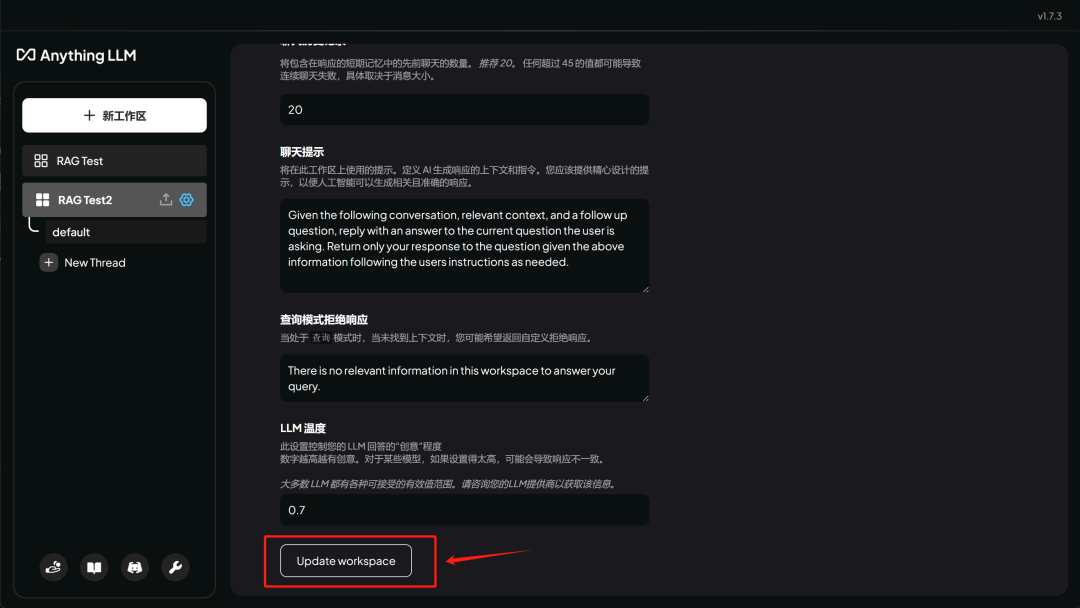
然后翻到最下面点击 Update workspace , 即可完成设置:
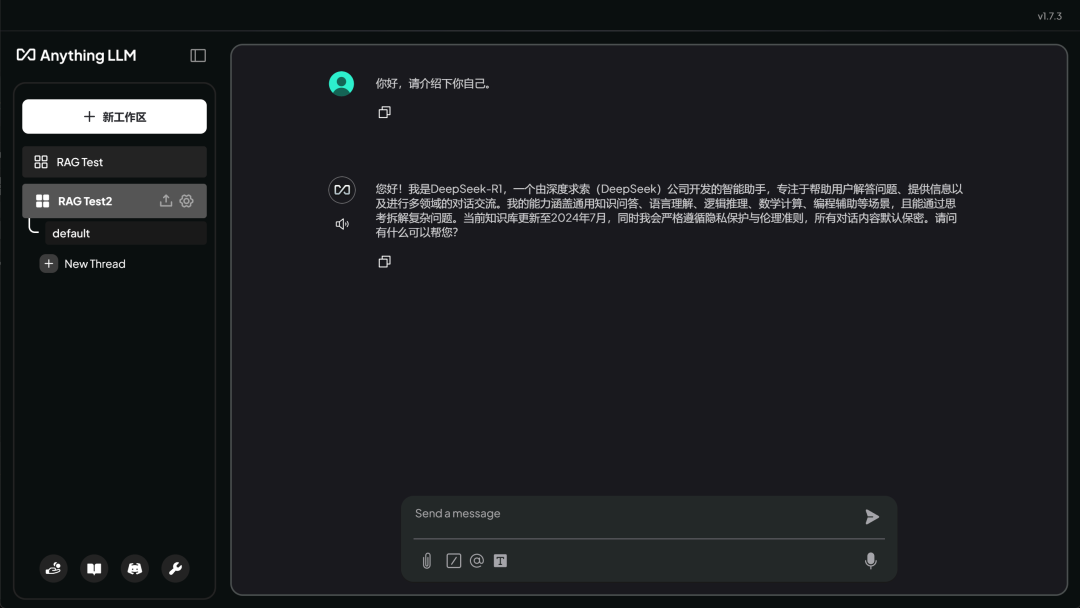
然后点击左侧聊天栏,选择 default 会话即可开始聊天了:
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









