






 本文详细介绍了拉格朗日乘数法在求解约束优化问题中的应用,包括矩阵求导法则,以及矩阵2-范数的概念。重点讨论了MDS、PCA和LLE三种降维算法的原理、证明过程和优化方法,展示了这些在数据处理中的实际应用。
本文详细介绍了拉格朗日乘数法在求解约束优化问题中的应用,包括矩阵求导法则,以及矩阵2-范数的概念。重点讨论了MDS、PCA和LLE三种降维算法的原理、证明过程和优化方法,展示了这些在数据处理中的实际应用。
预备知识:
1.拉格朗日乘数法:对于前面定义中所设的一般目标函数和约束条件组, 应引入辅助函数
称此函数为拉格朗日函数, 其中
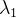
....
称为拉格朗乘数。
设上述条件极值问题中的函数
与
在在区域
上有连续一阶偏导数.。若
是该条件极值问题的极值点, 且
则对于m 个常数
使得
为拉格朗日函数的稳定点即它是如下
个方程的解。


2.矩阵求导法则:
矩阵求导法则:设存在矩阵
矩阵
及
维向量
,我们有
补充:(1)
(2)
(3)
3.矩阵的2-范数:又名欧几里得范数,即向量元素绝对值的平方和再开方,
,
可以表示矩阵之间的距离。
公式推导:
1.MDS算法:假定m个属性在原始空间的距离矩阵为:
,其
行
列的元素
为样本
到
的距离。我们假设样本在
维空间的表示
,且任意两个样本在
。

证明:我们令为降维后的内积矩阵,
,我们有:
我们假设降维后样本Z被中心化:。我们有:
那么我们有:
同理,我们有:
其中。
我们令:
我们有:
我们对进行特征值分解,
,其中
,我们取其非零的特征向量,我们有:
,对应特征向量为
。
在降维过程中,距离可不必完全相等,于是我们可以取前几个最大特征值来构成对角矩阵:,
为对应特征向量,
。
2.主成分分析(PCA)算法:

证明:假设数据样本进行了中心化,,假设投影变换后的新坐标系为
,
为标准向量基,将
降低维度到
,其中
是
在低维坐标系下的第j维的坐标。基于
重构
我们有
我们设,计算原样本点
与重构的样本点
距离:

我们由最近重构性,将最小化,由于
为标准正交基,我们有
。我们有以下目标优化:
我们使用拉格朗日数乘法构造拉格朗日函数,其中
。我们将其对
求导有:
我们有使之为0,有,由此我们有
。我们对协方差矩阵
进行特征值分解,将求得的特征值进行排序:
。我们取前
个特征向量对应特征向量构成
即为主成分分析的解。
3.LLE算法:

证明:假定样本点的坐标能通过它的邻域样本点
,
,
。我们为每个
找出近邻下标集
,计算出基于
中的样本点进行线性重构系数
:
我们有:

其中,
。
我们有约束条件为:。
我们可以得到最终的优化方程:
我们对其使用拉格朗日乘数法构造拉格朗日函数有:。
我们将其对求导并使之等于0有:
我们对其乘以有:
将代入到
有:
。我们设
,那么我们有:
。
相应的低维空间中保持不变,则我们可以通过以下式求得对应的低维坐标
:
。
我们设,则有:

最终得到我们的优化方程:
参考文献:
西瓜书:PCA数学推导_pca西瓜书-CSDN博客 https://blog.csdn.net/weixin_45963617/article/details/107426075
https://blog.csdn.net/weixin_45963617/article/details/107426075
















 1875
1875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











