






文章目录
计算机的随机数生成方法
计算机程序的随机数生成并不能实现真正的“随机”,而是通过伪随机数生成算法来模拟随机性。最常用的伪随机数生成方法是梅森旋转算法(Mersenne Twister),它生成的是一个周期非常长、分布均匀的伪随机数序列。尽管如此,由于计算机的有限性,生成的随机数并不是真正的随机,仍然具有一定的规律性。为了尽量消除这些规律性的影响,在实际应用中,我们使用了多种随机数生成方法。
在R语言中,内置了多种生成随机数的函数。例如:
runif(n):生成一个包含n个介于0到1之间的伪随机数的向量rbeta(n, shape1, shape2):生成n个遵循Beta分布的随机数rgeom(n, prob):生成n个遵循几何分布的随机数rchisq(n, df):生成n个遵循卡方分布的随机数
本章节将讨论几种常用的基于R自带函数的随机数生成方法,包括逆变换法、接受拒绝法以及其他常见的变换方法,以尽量消除计算机带来的伪随机影响。
1.逆变换法 (Inverse Transform Method)
逆变换法是一种常用的生成随机变量的方法,适用于可以通过其累积分布函数(CDF)求得反函数的分布。该方法的基本思路是通过将均匀分布的随机数映射到目标分布来生成随机数。
原理
假设目标分布的累积分布函数为 F ( x ) F(x) F(x),则:
- 生成一个均匀分布的随机数 U ∼ Uniform ( 0 , 1 ) U \sim \text{Uniform}(0, 1) U∼Uniform(0,1)。
- 利用目标分布的累积分布函数的反函数 F − 1 ( U ) F^{-1}(U) F−1(U) 来映射 U U U,得到服从目标分布的随机数。
示例 1:生成符合指数分布的随机数
对于指数分布,其累积分布函数为:
F
(
x
)
=
1
−
e
−
λ
x
,
x
≥
0
F(x) = 1 - e^{-\lambda x}, \quad x \geq 0
F(x)=1−e−λx,x≥0
逆函数为:
F
−
1
(
U
)
=
−
ln
(
1
−
U
)
λ
F^{-1}(U) = -\frac{\ln(1-U)}{\lambda}
F−1(U)=−λln(1−U)
通过该逆函数,可以将均匀分布的随机数 U U U 转换为服从指数分布的随机数。
示例 2(连续场景):模拟密度函数 f X ( x ) = 4 x 3 f_X(x) = 4x^3 fX(x)=4x3 的随机样本
理论推导
给定密度函数:
f
X
(
x
)
=
4
x
3
,
0
<
x
<
1
f_X(x) = 4x^3, \quad 0 < x < 1
fX(x)=4x3,0<x<1
-
累积分布函数为:
F X ( x ) = ∫ 0 x 4 t 3 d t = x 4 F_X(x) = \int_0^x 4t^3 \, dt = x^4 FX(x)=∫0x4t3dt=x4 -
累积分布函数的反函数为:
F X − 1 ( u ) = u 1 / 4 , u ∈ [ 0 , 1 ] F_X^{-1}(u) = u^{1/4}, \quad u \in [0, 1] FX−1(u)=u1/4,u∈[0,1] -
根据逆变换法,通过均匀分布 U ∼ Uniform ( 0 , 1 ) U \sim \text{Uniform}(0, 1) U∼Uniform(0,1) 的随机数 u u u,利用 F X − 1 ( u ) = u 1 / 4 F_X^{-1}(u) = u^{1/4} FX−1(u)=u1/4 映射即可生成目标分布的随机数。
R代码实现
以下是 R 代码实现:
# 生成随机样本的数量
n <- 1000
# 逆变换法生成随机样本
set.seed(123) # 设置随机种子以保证结果可复现
u <- runif(n) # 从 U(0,1) 中生成 n 个随机数
x <- u^(1/4) # 通过逆累积分布函数 F^-1(u) = u^(1/4) 映射
# 绘制结果
# 直方图展示生成的随机样本的分布
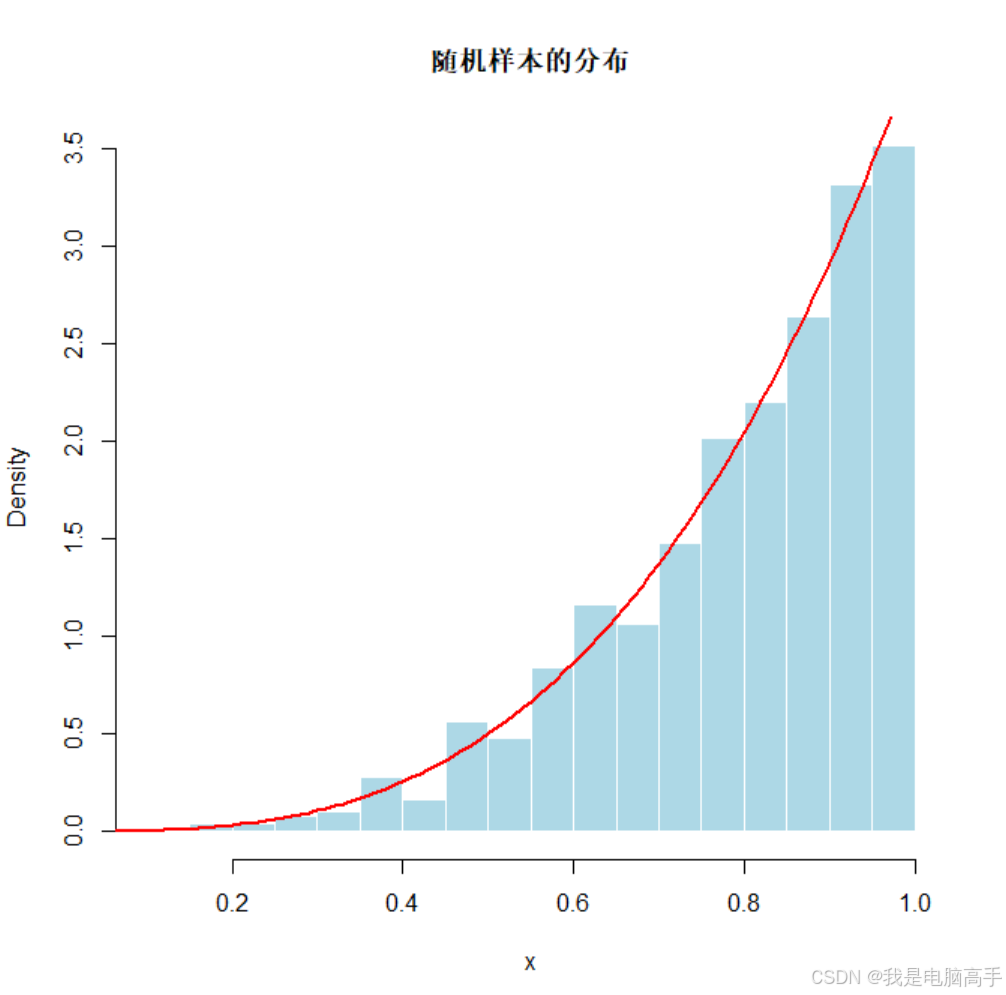
hist(x, breaks = 30, probability = TRUE, main = "随机样本的分布",
xlab = "x", col = "lightblue", border = "white")
# 添加理论密度函数的曲线
curve(4 * x^3, col = "red", lwd = 2, add = TRUE, from = 0, to = 1)
# 输出前 10 个随机样本
head(x, 10)
运行结果如下
示例 3(离散场景):模拟两点分布的随机样本
理论推导
假设我们有一个离散分布 ( X ),其概率质量函数(PMF)定义如下:
P ( X = 0 ) = p , P ( X = 1 ) = 1 − p , 0 ≤ p ≤ 1 P(X = 0) = p, \quad P(X = 1) = 1 - p, \quad 0 \leq p \leq 1 P(X=0)=p,P(X=1)=1−p,0≤p≤1
-
累积分布函数(CDF)为:
F X ( x ) = { 0 , x < 0 p , 0 ≤ x < 1 1 , x ≥ 1 F_X(x) = \begin{cases} 0, & x < 0 \\ p, & 0 \leq x < 1 \\ 1, & x \geq 1 \end{cases} FX(x)=⎩ ⎨ ⎧0,p,1,x<00≤x<1x≥1 -
累积分布函数的反函数为:
F X − 1 ( u ) = { 0 , 0 ≤ u < p 1 , p ≤ u ≤ 1 , u ∈ [ 0 , 1 ] F_X^{-1}(u) = \begin{cases} 0, & 0 \leq u < p \\ 1, & p \leq u \leq 1 \end{cases}, \quad u \in [0, 1] FX−1(u)={0,1,0≤u<pp≤u≤1,u∈[0,1] -
根据逆变换法,通过均匀分布 ( U \sim \text{Uniform}(0, 1) ) 的随机数 ( u ),我们可以根据以下规则生成 ( X ) 的随机数:
- 如果 u < p ,则 X = 0 u < p ,则 X = 0 u<p,则X=0;
- 如果 u ≥ p ,则 X = 1 u \geq p ,则 X = 1 u≥p,则X=1。
R代码实现
以下是 R 代码实现:
# 生成随机样本的数量
n <- 1000
p <- 0.7 # 假设 P(X = 0) = p = 0.7
# 逆变换法生成随机样本
set.seed(123) # 设置随机种子以保证结果可复现
u <- runif(n) # 从 U(0,1) 中生成 n 个随机数
x <- ifelse(u < p, 0, 1) # 根据逆变换法生成离散随机样本
# 绘制结果
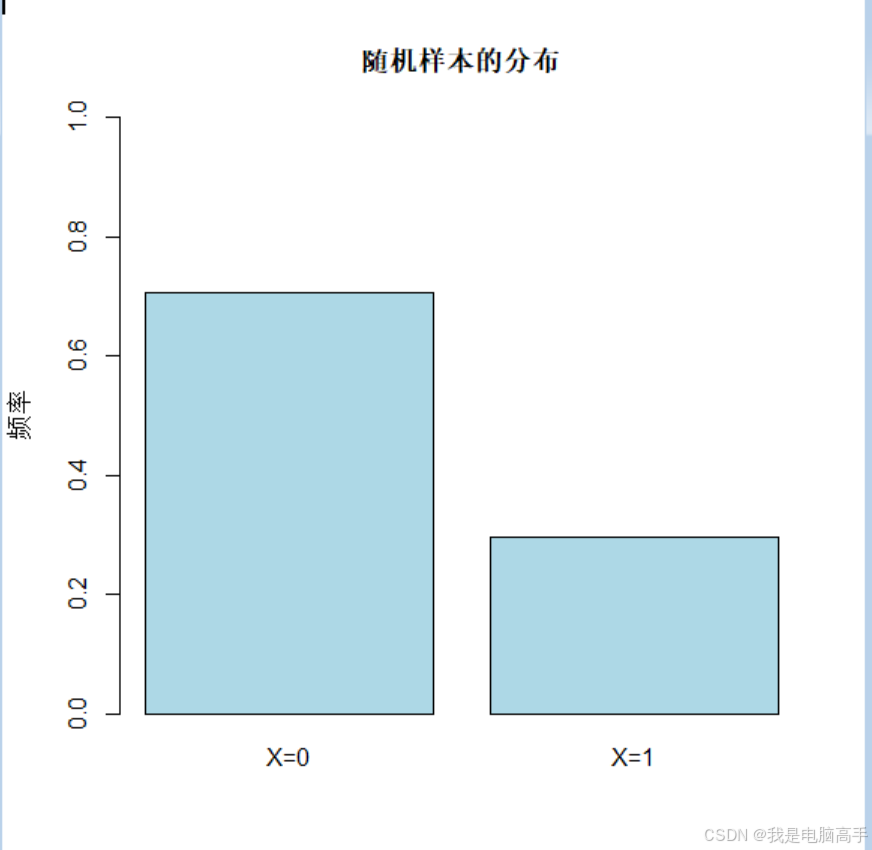
# 绘制频数图展示生成的随机样本的分布
barplot(table(x) / n, names.arg = c("X=0", "X=1"), col = "lightblue",
main = "随机样本的分布", ylab = "频率", ylim = c(0, 1))
# 输出前 10 个随机样本
head(x, 10)
2. 接受拒绝法 (Rejection Sampling)
接受拒绝法是一种通用的随机数生成方法,适用于无法直接求得目标分布的逆函数的情况。该方法的基本思想是从一个容易采样的“提议分布”(proposal distribution)中生成样本,然后通过某种规则来决定是否接受这些样本。
具体步骤如下:
选择一个容易采样的提议分布
g
(
x
)
g(x)
g(x),并计算其概率密度函数
g
(
x
)
g(x)
g(x)。
选择一个常数
M
M
M,使得目标分布的概率密度 ( f(x) ) 可以通过
M
⋅
g
(
x
)
M \cdot g(x)
M⋅g(x) 上界化。
从提议分布中生成一个样本
x
′
x'
x′。
生成一个均匀分布的随机数
U
∼
Uniform
(
0
,
1
)
U \sim \text{Uniform}(0, 1)
U∼Uniform(0,1)。
如果
U
≤
f
(
x
′
)
M
⋅
g
(
x
′
)
U \leq \frac{f(x')}{M \cdot g(x')}
U≤M⋅g(x′)f(x′),则接受 ( x’ ) 作为目标分布的样本;否则,拒绝 ( x’ ) 并重新采样。
R语言的 rnorm 和 rbeta 等函数可以通过接受拒绝法实现复杂分布的生成。
例如:
假设我们希望从正态分布中采样,但不直接使用R的 rnorm 函数,而是通过接受拒绝法。选择标准正态分布作为提议分布,接着在每次采样时比较目标分布和提议分布的比例,决定是否接受该样本。
# 示例:接受拒绝法生成符合正态分布的随机数
# 假设我们想要从均值为0、方差为1的正态分布中生成样本
n <- 10000
samples <- numeric(n)
accepted <- 0
while (accepted < n) {
# 从标准正态分布生成一个样本
x_star <- rnorm(1)
u <- runif(1)
# 接受样本的概率
if (u <= dnorm(x_star) / (1 / sqrt(2 * pi))) {
accepted <- accepted + 1
samples[accepted] <- x_star
}
}
3. 其他变换方法
1. 从标准正态分布到卡方分布
如果 Z ∼ N ( 0 , 1 ) Z \sim N(0, 1) Z∼N(0,1),那么 V = Z 2 ∼ χ 2 ( 1 ) V = Z^2 \sim \chi^2(1) V=Z2∼χ2(1)。
2. 从卡方分布到F分布
如果
U
∼
χ
2
(
m
)
U \sim \chi^2(m)
U∼χ2(m) 和
V
∼
χ
2
(
n
)
V \sim \chi^2(n)
V∼χ2(n) 相互独立,那么
T
=
U
/
m
V
/
n
∼
F
(
m
,
n
)
T = \frac{U/m}{V/n} \sim F(m, n)
T=V/nU/m∼F(m,n)
即
T
T
T 服从自由度为
m
m
m 和
n
n
n 的 F 分布。
3. 从标准正态分布和卡方分布到t分布
如果
Z
∼
N
(
0
,
1
)
Z \sim N(0, 1)
Z∼N(0,1) 和
V
∼
χ
2
(
n
)
V \sim \chi^2(n)
V∼χ2(n) 相互独立,那么
T
=
Z
V
/
n
∼
t
(
n
)
T = \frac{Z}{\sqrt{V/n}} \sim t(n)
T=V/nZ∼t(n)
即
T
T
T 服从自由度为
n
n
n 的 t 分布。
4. 使用独立的均匀分布生成标准正态分布
如果 U , V ∼ U ( 0 , 1 ) U, V \sim U(0, 1) U,V∼U(0,1) 相互独立,那么可以通过以下变换生成两个相互独立的标准正态随机变量 Z 1 Z_1 Z1 和 Z 2 Z_2 Z2:
Z
1
=
−
2
log
U
cos
(
2
π
V
)
Z_1 = \sqrt{-2 \log U} \cos(2 \pi V)
Z1=−2logUcos(2πV)
Z
2
=
−
2
log
U
sin
(
2
π
V
)
Z_2 = \sqrt{-2 \log U} \sin(2 \pi V)
Z2=−2logUsin(2πV)
其中, Z 1 Z_1 Z1 和 Z 2 Z_2 Z2 都服从 N ( 0 , 1 ) N(0, 1) N(0,1),并且相互独立。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









