






全连接
-
前馈全连接神经网络
1. 导包:
- 导入本次所要使用的所有库—pandas、numpy、matplotlib...
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt2. 导入所需数据:
- 在网上获取所需要的“.csv”数据集,进行数据导入
import pandas as pd
path1 = "D:\MNIST\mnist_train.csv"
path2 = "D:\MNIST\mnist_test.csv"
train_Data = pd.read_csv(path1, header = None) # 训练数据
test_Data = pd.read_csv(path2, header = None) # 测试数据3. 观察导入的数据:
- 分别输出训练数据和测试数据的信息,包括数据的维度、数据类型
# 观察数据
print("Train data:")
train_Data.info()
print("\nTest data:")
test_Data.info()输出结果:
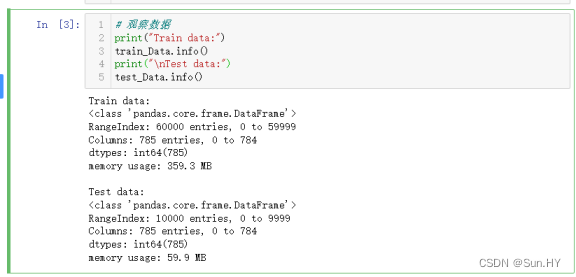
- 训练数据集有 60000 个样本,每个样本有 785 个特征(包括标签)、10000 个样本,每个样本也有 785 个特征(包括标签)、所有特征的数据类型都是 int64、占用内存 359.3 MB,测试数据集占用内存 59.9 MB。
4. 观察数据集的前五行:
train_Data.head(5)输出结果:
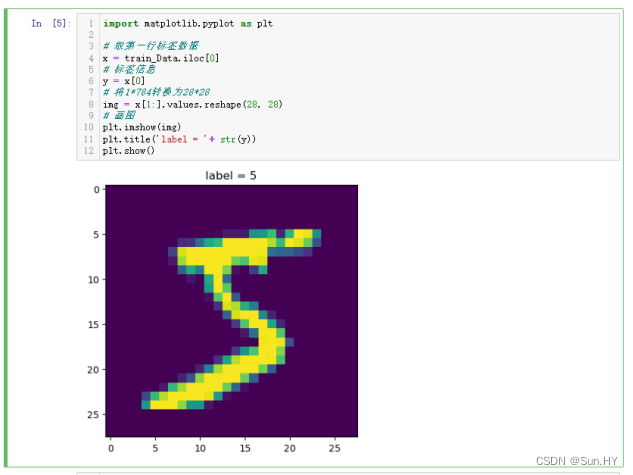
5. 显示 MNIST 数据集中的一个手写数字样本:
- 从 MNIST 训练数据集中取出一个样本,提取出它的图像数据和标签信息,然后使用 Matplotlib 将其可视化显示出来。
import matplotlib.pyplot as plt
# 取第一行标签数据
x = train_Data.iloc[0]
# 标签信息
y = x[0]
# 将1*784转换为28*28
img = x[1:].values.reshape(28, 28)
# 画图
plt.imshow(img)
plt.title('label = '+ str(y))
plt.show()输出结果:
6. 从sklearn中导入数据并观察数据
# 从sklearn中导入数据
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version = 1)
# 观察数据
mnist.keys()输出结果:
7. 从 MNIST 数据集中提取图像数据和标签数据:
data, label = mnist["data"], mnist["target"]
print("标签维度:", data.shape)
print("标签维度:", label.shape)输出结果:

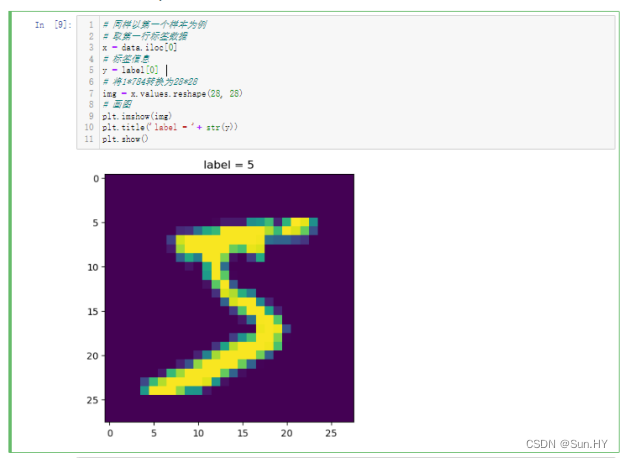
8. 从 MNIST 数据集中获取第一个图像,将其转换为可视化的格式:
- 在数据集中获取第一个图像的数据和标签,然后将其转换为 28x28 的图像格式,最后使用 Matplotlib 库将其显示出来,并在图像上添加标签信息。
# 同样以第一个样本为例
# 取第一行标签数据
x = data.iloc[0]
# 标签信息
y = label[0]
# 将1*784转换为28*28
img = x.values.reshape(28, 28)
# 画图
plt.imshow(img)
plt.title('label = '+ str(y))
plt.show()输出结果:
9. 数据预处理:
9.1 导入数据:
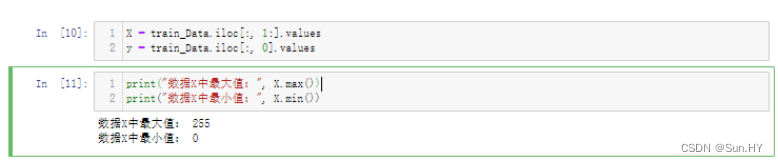
- 从 train_Data 数据集中分离出特征数据 X 和标签数据 y、打印出 X 中数据的最大值和最小值。(最大值是255,最小值是0)
X = train_Data.iloc[:, 1:].values
y = train_Data.iloc[:, 0].values
print("数据X中最大值:", X.max())
print("数据X中最小值:", X.min())输出结果:
9.2 对9.1中的X进行归一化:
# 归一化(直接÷255)
X = X/255
# 此时将数值大小缩小在[0,1]范围内,重新观察数据中最大、最小值
print("数据X中最大值:", X.max())
print("数据X中最小值:", X.min())输出结果:

9.3 评估的数据集:
- 将所有训练样本分为55000个样本的训练集(X_train, y_train)与5000个样本的验证集(X_valid, y_valid)
X_valid,X_train= X[:5000], X[5000:]
y_valid, y_train = y[:5000], y[5000:]
X_test,y_test = test_Data.iloc[:,1:].values/255, test_Data.iloc[:,0].values输出结果:

10. 前馈全连接神经网络(Sequential模型):
10.1 导包:
- 导入所需要的库
import tensorflow as tf
from tensorflow import keras输出结果:

10.2 构建4层全连接前馈神经网络:
model = keras.models.Sequential([
keras.layers.Flatten(input_shape = [784]), # 输入层(784个神经元)
keras.layers.Dense(300, activation = "relu"), # 隐藏层1(300个神经元)
keras.layers.Dense(100, activation = "relu"), # 隐藏层2(100个神经元)
keras.layers.Dense(10, activation = "softmax") # 输出层(10个神经元)
])输出结果:

10.3 观察神经网络的整体情况:
- 获取第一个隐藏层的权重和偏差参数,并打印出它们的形状
model.layers[1]输出结果:

- 从第一个隐藏层中获取了权重(weights)和偏差(bias)参数。
weights_l,bias_l = model.layers[1].get_weights()输出结果:

- 打印权重参数和偏差参数的形状
print(weights_l.shape)
print(bias_l.shape)输出结果:

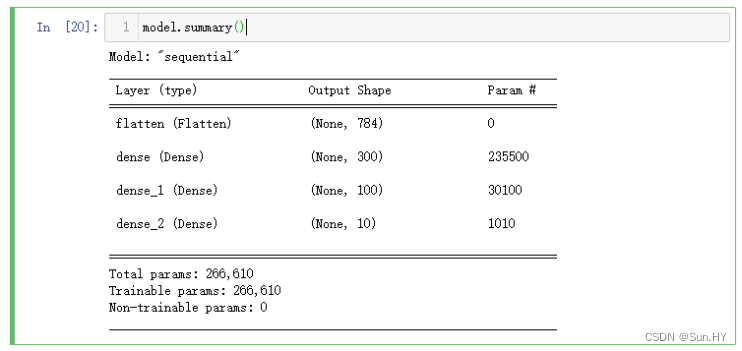
10.4 打印出模型的摘要信息:
model.summary()输出结果:
11. 编译网络:
# 编译网络
model.compile(loss="sparse_categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])输出结果:
![]()
12. 训练网络:
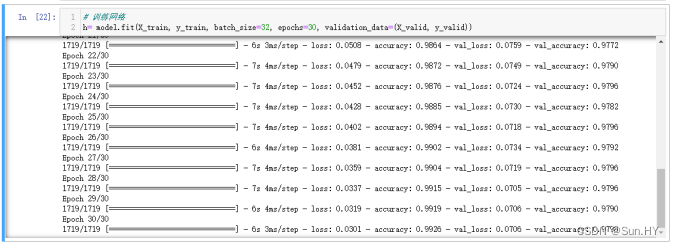
12.1 使用训练样本训练网络:
- 执行了30个模型训练,每次迭代使用32个样本,并在验证集上评估模型的性能。训练过程的历史信息被存储在变量h中,用于进一步的分析和可视化
# 训练网络
h=model.fit(X_train,y_train,batch_size=32, epochs=30, validation_data=(X_valid, y_valid))输出结果:
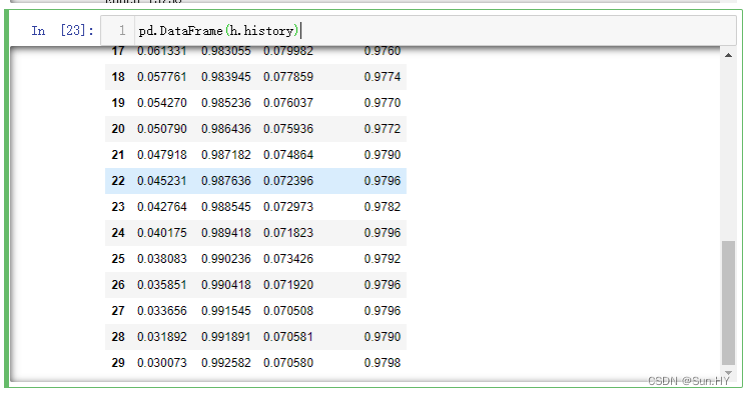
12.2 查看训练过程中loss和accuracy的变化:
pd.DataFrame(h.history)输出结果:
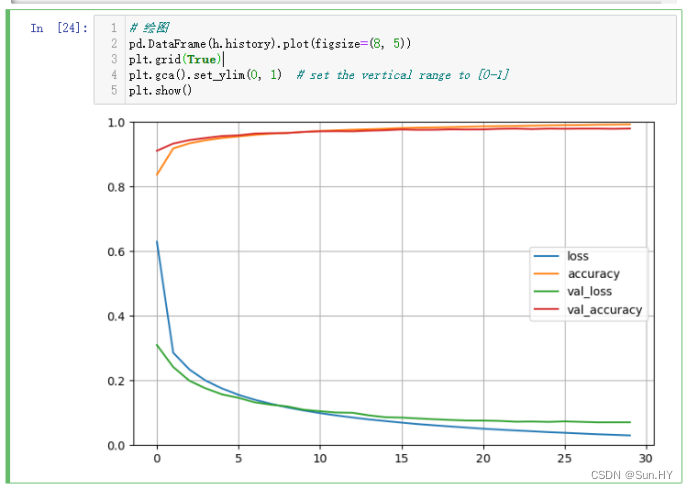
12.3 绘图:
# 绘图
pd.DataFrame(h.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1) # set the vertical range to [0-1]
plt.show()输出结果:
12.4 测试集验证训练模型手写识别的准确率(97%):
model.evaluate(X_test, y_test, batch_size = 1)输出结果:

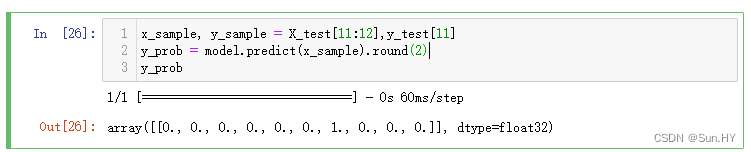
12.5 随机挑选测试样本数据集中的第12个样本:
x_sample, y_sample = X_test[11:12],y_test[11]
y_prob = model.predict(x_sample).round(2)
y_prob输出结果:
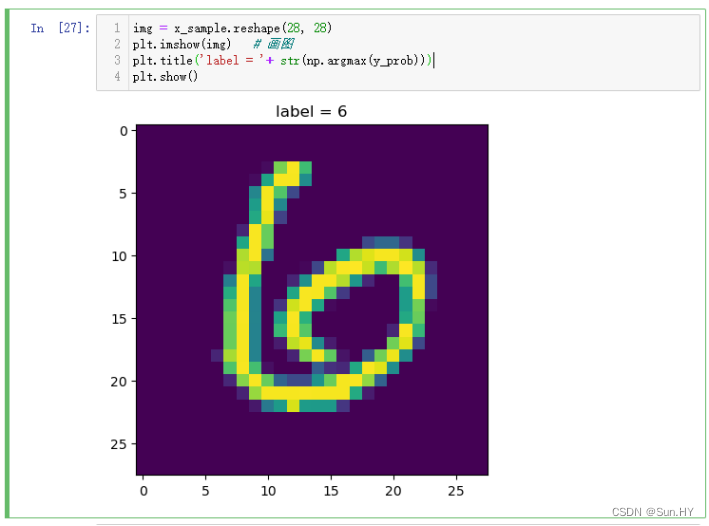
12.6 查看对图像样本的预测结果:
- 将一个图像样本绘制出来,并在图像上显示模型预测的类别标签
img = x_sample.reshape(28, 28)
plt.imshow(img) # 画图
plt.title('label = '+ str(np.argmax(y_prob)))
plt.show()输出结果:















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









