






注意力机制自从2014年被正式提出后,逐渐成为了NLP中应用最广泛的设计。借助简单而又变幻莫测的Attention机制,一系列横扫SOTA的模型被提出。自注意力机制(Self-Attention),允许序列中的标记相互交互,并计算输入和输出序列的表示,成为了大语言模型主流架构Transformer的关键组成部分。Transformer 结构中,自注意力机制的时间和存储复杂度与序列的长度呈平方的关系,因此占用了大量的计算设备内存和并消耗大量计算资源。因此,如何优化自注意力机制的时空复杂度、 增强计算效率是大语言模型需要面临的重要问题。
1. 自注意力机制概述
注意力机制源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择视觉区域中的特定部分,集中关注它,同时忽略其他可见的信息。上述机制通常被称为注意力机制。这种只将注意力引向感兴趣的一小部分信息的能力,使我们的大脑能够更明智地分配资源来生存、成长和社交。
基于注意力机制的深度学习,核心在于让机器学会去感知数据中的重要和不重要的部分。比如在做机器翻译等任务时,要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。一个Attention的计算过程有三步:
1. query 和 key 进行相似度计算,得到一个 query 和 key 相关性的分值 。
2. 将这个分值进行归一化(softmax),得到一个注意力的分布 。
3. 使用注意力分布和 value 进行计算,得到一个融合注意力的更好的 attention value 值。
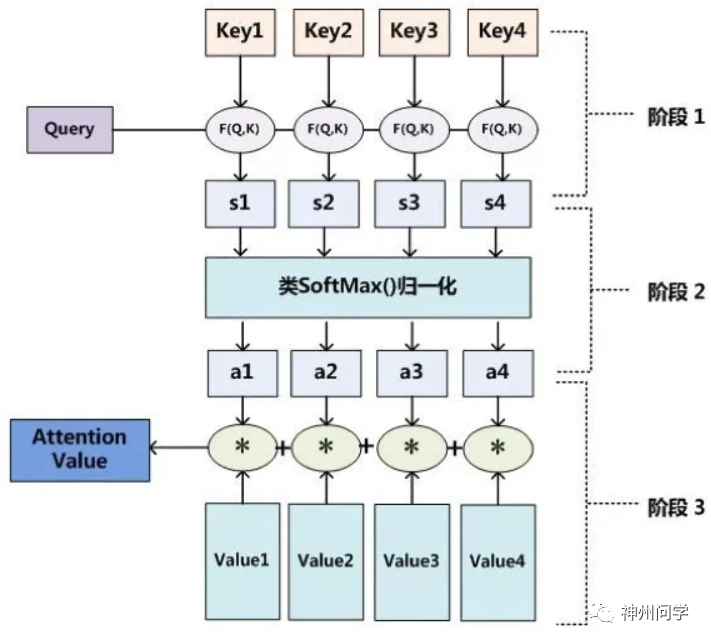
Self Attention,自注意力机制,又称内部注意力机制,顾名思义,是一种将单个序列的不同位置关联起来以计算同一序列的表示的注意机制。对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的"表决"来决定应该关注哪些输入项。在Attention诞生之前,常见的是CNN和RNN及其变体模型,对比之下attention结构不再要求编码器将所有信息全输入在一个固定长度的向量中。更重要的是,Self Attention可以捕获同一个句子中单词之间的一些句法特征或者语义特征。同时,引入Self Attention后会更容易捕获句子中长距离的相互依赖的特征,因为如果是RNN或者LSTM,需要依次序序列计算,对于远距离的相互依赖的特征,要经过若干时间步步骤的信息累积才能将两者联系起来。距离越远,有效捕获的可能性越小。但是Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤联系起来,所以远距离依赖特征之间的距离被极大缩短,更有利于有效地利用这些特征。除此外,Self Attention 解决了 RNN 不能并行计算的问题。Self Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。这也是Self Attention逐渐被广泛使用的主要原因。
但是随注意力机制而来的就是计算复杂程度问题:一方面,需要为每个输入输出组合分别计算attention。如果现有一个输入序列(query)长度是50,为了捕捉每个 value 或者 token 之间的关系,需要对应产生 50 个 key 与之对应,并将 query 与 key 之间做 dot-product,就可以产生一个2500维的注意力矩阵。当序列长度太长的时候,对应的注意力矩阵维度太大,会给计算带来麻烦。另一方面,attention在决定专注于某个方面之前需要遍历一遍记忆再决定下一个输出是以什么。所以随着序列长度的增加,时间成本也会剧增。
2. 自注意力机制的优化策略
2.1 稀疏注意力机制
直观上说,如果上下文长度为100K,很大程度上并非所有词元之间都存在相关性。事实上,通过对一些训练好的 Transformer 模型中的注意力矩阵进行分析发现,其中很多通常是稀疏的。因此减少计算量的一种方法是在计算注意力分数时仅考虑部分词元,通过限制 Query-Key 对的数量,使计算复杂度与n呈线性关系,而非二次方关系。这类方法就称为稀疏注意力(Sparse Attention)机制。可以将稀疏化方法进一步分成两类:基于位置信息和基于内容。
2.1.1 基于位置的稀疏注意力机制
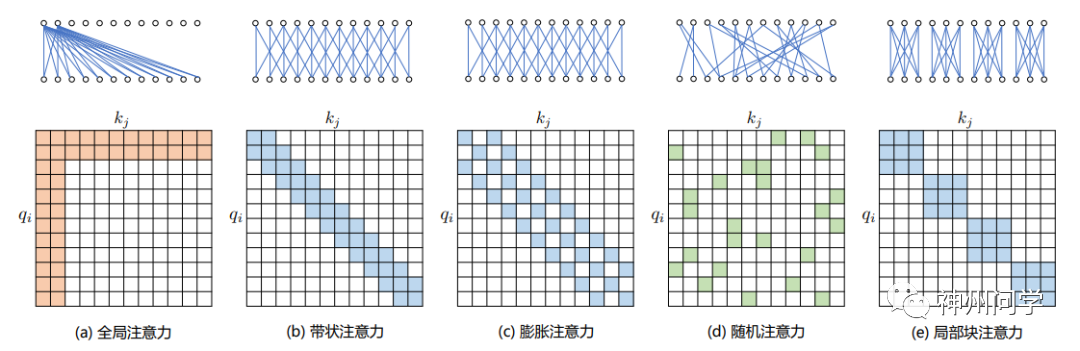
基于位置的稀疏注意力机制的基本类型如图所示,主要包含如下五种类型:
(1)全局注意力(Global Attention):为了增强模型建模长距离依赖关系,可以预选几个输入位置加入全局注意力节点。这样具有全局注意力的词元会关注序列中的所有词元,并且序列中的所有词元都会关注它。
(2)带状注意力(Band Attention):限制 Query 只与相邻的几个节点进行交互。在每个词元周围采用了固定大小的窗口注意力。在这一注意力机制中,给定一个固定的窗口大小w,每个词元会关注其两侧的w/2个词元。
(3) 膨胀注意力(Dilated Attention):与 CNN 中的 Dilated Conv 类似,通过增加空隙以获取更大的感受野。膨胀注意力为了进一步增加接收域而不增加计算量,可以在(2)中窗口间留大小为d的间隙。假设所有层的d和w是固定的,那么每个注意力层的接收域是 d × w。在多头注意力中,每个注意力头计算不同的注意力得分,每个头有不同膨胀配置的设置可以提高性能,因为这样允许一些无膨胀的头专注于局部上下文,而其他有膨胀的头则专注于更长的上下文。
(4)随机注意力(Random Attention):通过随机采样,提升非局部的交互。
(5)局部块注意力(Block Local Attention):使用多个不重叠的块(Block)来限制信息交互。每个查询块都只关注自己对应内存块中的键值。
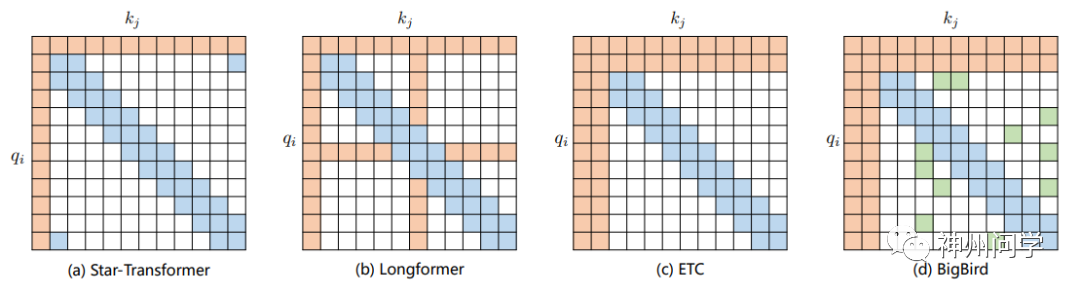
现有做法通常是基于上述五种基于位置的稀疏注意力机制的复合使用。比如:星型变换器(Star-Transformer)结合了一个宽度为3的带状注意力和一个全局注意力。Longformer 使用带状注意力、内部全局节点注意力(Internal Global-node Attention)以及膨胀注意力三者的组合,使其能够轻松处理数千个标记或更长的文档。此外,同期的Extended Transformer Construction(ETC)利用带状注意力和外部全局节点注意力(External Global-node Attention)的组合。BigBird则是在 Longformer 基础上随机选择 attention 赋值,进一步提高计算效率。
2.1.2 基于内容的稀疏注意力机制
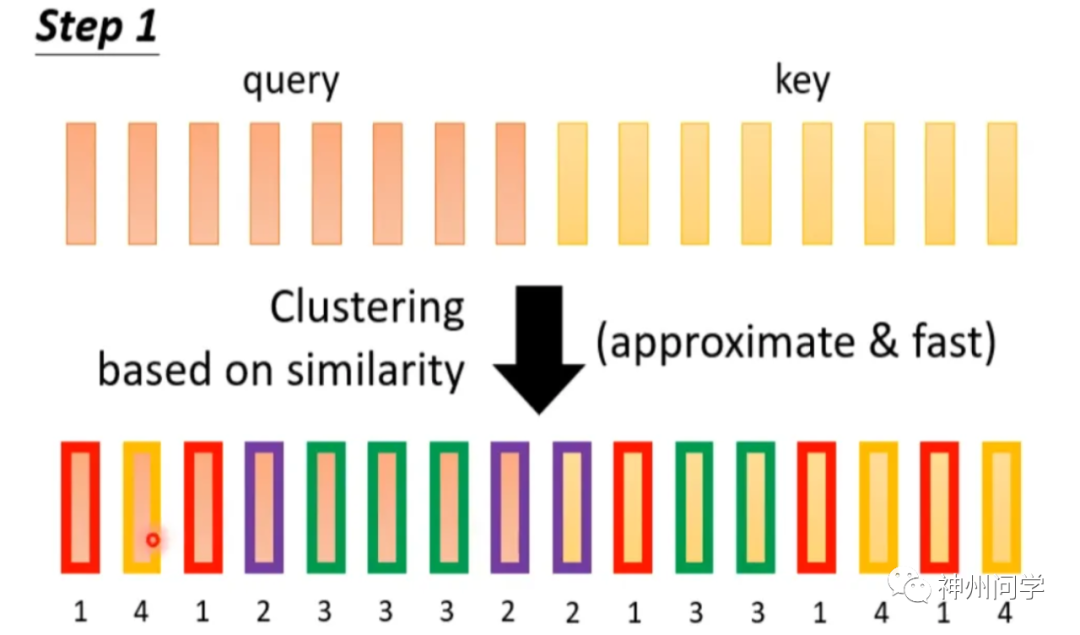
基于内容的稀疏注意力是是根据输入数据来创建稀疏注意力,其中一种很简单的方法是选择和给定查询(Query)有很高相似度的键(Key),换句话说就是一种 Clustering(聚类)的方案。即先对 query 和 key 进行聚类,属于同一类的 query 和 key 来计算 attention,不属于同一类的就不参与计算,这样就可以加快 Attention Matrix 的计算。比如下面这个例子中,分为 4 类:1(红框)、2(紫框)、3(绿框)、4(黄框)。
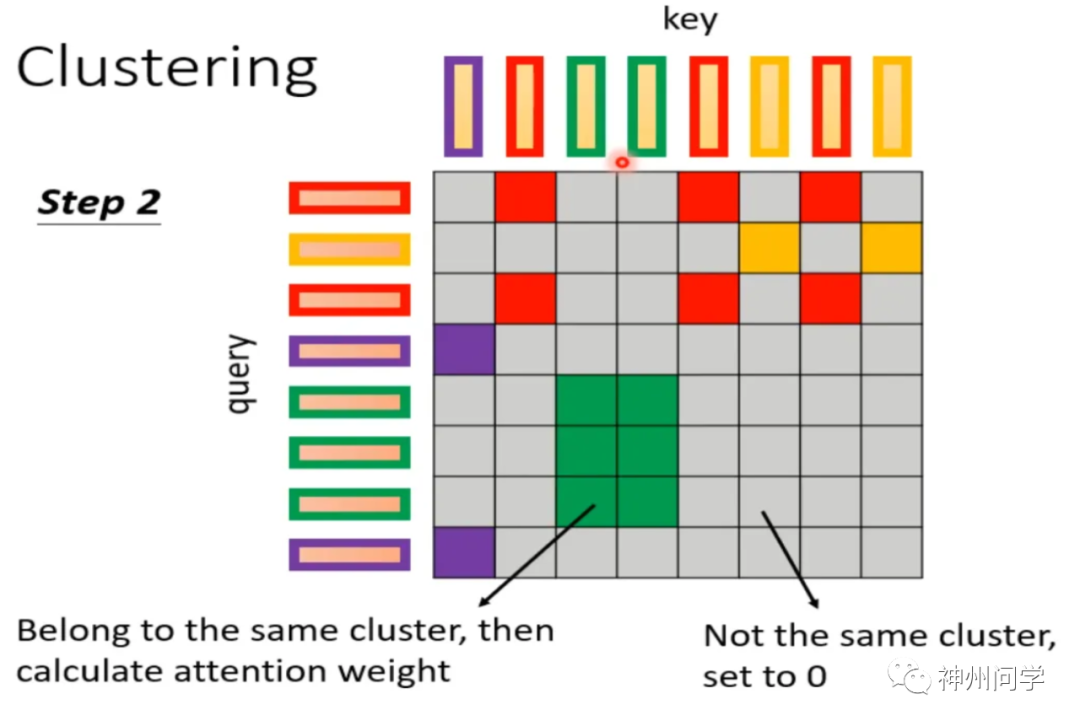
以下是两个快速粗略聚类的实践:Routing Transformer 采用 K-means 聚类方法,每个 Query 只与其处在相同簇(Cluster)下的 Key 进行交互。中心向量采用滑动平均的方法进行更新。Reformer 则采用局部敏感哈希(Local-Sensitive Hashing,LSH)方法来为每个 Query 选择 Key-Value 对,将Query们划分到多个桶内,提升在同一个桶内的 Query 和 Key 参与交互的概率。
2.2 Flash Attention
根据计算的密集程度,计算操作被分为两类:
● Compute-bound:计算密集型。整个计算的耗时主要在于计算本身,对显存的读写几乎可以忽略。典型的计算包括大矩阵乘法、大channel size的卷积操作等。对于这类操作,它们的FLOPS(floating point operations per second)决定了计算的时耗。
● Memory-bound:存储访问密集型。整个计算的耗时主要集中在存储的访问上,计算本身耗时较低。典型的计算包括逐元素操作(ReLU,Dropout等)、以及Reduce操作(求和、softmax、BatchNorm等)。对于这类操作,它们的MAC(Memory Access Cost)决定了计算的时耗。
在绝大多数的神经网络中,都含有大量的Memory-bound操作,但是绝大多数Efficient Transformer把改进方法集中在降低模型的FLOPS上。这就导致这些方法的计算速度并没有显著降低。于是FlashAttention将优化重点放在了降低存储访问开销(MAC)上。与CPU的情况类似,在GPU中,当需要计算时,需将数据从显存中读取并由计算单元进行计算操作。在计算完毕后,再写回到显存中。所以在自注意力机制运行中,存储访问的开销主要来自两方面。一是从存储中读取数据,二是向存储中写数据。标准 Attention 算法中,Softmax 计算按行进行,即在与 V 做矩阵乘法之前,需要将 Q、K 的各个分块 完成一整行的计算。在得到 Softmax 的结果后,再与矩阵 V 分块做矩阵乘。也就是说标准自注意力计算包含八次矩阵读写操作:
● 对 Q和K读取用于相乘,共两次,对矩阵乘法结果写一次,总共三次;
● Softmax前后一读一写,总共两次;
● Softmax和V读取用于相乘,共两次,对结果写一次,总共三次。
为了减少对显存的读写,FlashAttention将参与计算的矩阵分割成块分块送进GPU静态缓存,来提高整体读写速度。这是一个增量计算的过程。首先计算一个分块的局部softmax值,存储起来。当处理完下一个分块时,可以根据此时的新的全局最大值和全局EXP求和项来更新旧的softmax值。接着再处理下一个分块,然后再更新。当处理完所有分块后,此时的所有分块的softmax值都是“全局的”。值得注意的是,FlashAttention 算法并没有将计算时的过程矩阵写入全局内存,而是通过分块写入,存储前向传递的 Softmax 归一化因子,在后向传播中快速重新计算注意力。这比从全局内容中读取中间注意力矩阵的标准方法更快。由于大幅度减少了全局内存的访问量,即使重新计算导致 FLOPs 增加,但其运行速度更快并且使用更少的内存。
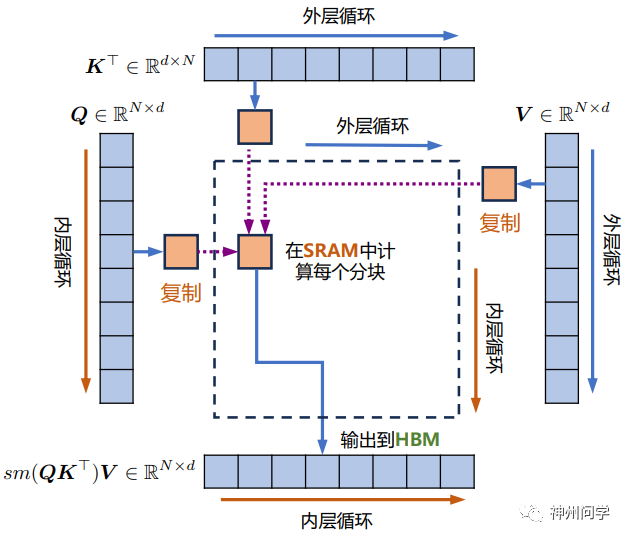
FlashAttention的工作原理示意图
ChatGLM-6B-32k就是基于 FlashAttention 技术,将上下文长度由基座模型ChatGLM-6B 的 2K 扩展到了 32K。阿里云最新开源的通义千问大模型系列的720亿参数规模的模型Qwen-72B官方仓库代码也支持并推荐使用FlashAttention。
2.3 多查询/分组查询注意力
多查询注意力(Multi Query Attention)是一种多头注意力的变体,它在轻微牺牲模型质量的前提下显著减少计算成本。在多查询注意力中key-value对在不同的注意力头之间共享,即,所有注意力头使用同一个key投射和一个value投射,只单独保留了query。因此键和值的矩阵仅有一份,这大幅度减少了显存占用和解码所需的内存带宽需求。另外也有研究表明可以通过对已经训练好的模型进行微调来添加多查询注意力支持,仅需要约 5% 的原始训练数据量就可以达到不错的效果。具有多查询注意力的代表性模型包括PaLM 、StarCoder 、SantaCoder、Falcon、ChatGLM2等等。
分组查询注意力(Group Query Attention)下,每个query有n_heads个注意力头,而key和value有n_kv_heads个注意力头,且一般来说,n_heads > n_kv_heads >= 1。也就是说注意力头被分配到不同的组中,属于同一组的注意力头共享相同的k、v变换矩阵。所以分组查询注意力介于多查询注意力和多头注意力之间(当n_kv_heads = n_heads 就是多头注意力,当n_kv_heads=1就是多查询注意力 ),它的速度和多头注意力一样快,但是参数量比多头注意力少,而且效果比多查询注意力好。特别地,分组查询注意力在LLaMA 2模型中得到了采用和经验验证。
2.4 分页注意力
在自回归 decoder 中,所有输入到 LLM 的 token 会产生注意力 key 和 value 的张量,这些张量保存在 GPU 显存中以生成下一个 token。这些缓存 key 和 value 的张量通常被称为 KV cache。如下图所示,在一张有40GB RAM的NVIDIA A100 GPU上进行13B参数的LLM的内存分布如下:大约65%的内存分配用于模型权重,这些权重在服务期间保持静态。接近30%的内存用于存储请求的KV-Cache。所以如果管理不善,KV缓存可能会显著限制批量大小,从而限制LLM的吞吐量。有研究表明, vLLM 库中 LLM 服务的性能受到内存瓶颈的影响:
● 显存占用大:在 LLaMA-13B 中,缓存单个序列最多需要 1.7GB 显存;而且KV缓存被存储在连续的内存空间中 。
● 动态变化:KV 缓存的大小取决于序列长度,这是高度可变和不可预测的。如果预分配的内存块具有最大限制的长度(如 2048 tokens),当实际的请求长度远小于最大长度时就会造成严重的碎片化。该研究发现,由于碎片化和过度保留,现有系统中只有20.4% - 38.2%的KV缓存内存用于存储实际的token状态,浪费了 60% - 80% 的显存。
● 缺乏内存共享:LLM服务通常使用高级解码算法,如并行采样和波束搜索,每个请求生成多个输出。在这些情况下,请求包括多个序列,这些序列可以部分共享KV缓存。但是现有系统无法利用内存共享的机会。

在NVIDIA A100上提供13B的LLM推理服务时的显存布局
为解决以上问题,该研究引入了PagedAttention,这是一种受操作系统中虚拟内存和分页经典思想启发的注意力算法。与传统的注意力算法不同,在PagedAttention中,KV缓存的块不一定存储在连续的空间中。具体来说,PagedAttention 将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的key和value。因为块在内存中不需要连续,因而可以像像操作系统的虚拟内存一样以更灵活的方式管理KV缓存:可以将块视为页面,将 token 视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块中。物理块在生成新 token 时按需分配。
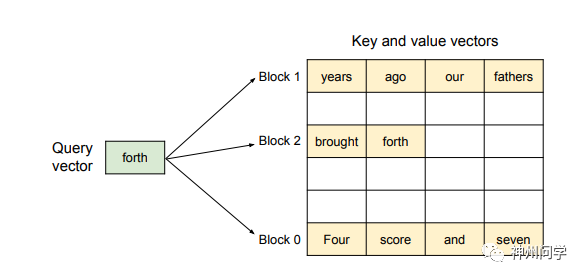
PagedAttention算法的示意图: 键和值向量以非连续块的形式存储在内存中
另一方面,PagedAttention 的另一个关键优势就是高效的内存共享。例如在并行采样中,多个输出序列是由同一个 prompt 生成的。在这种情况下PagedAttention自然地通过块表格来启动内存共享,让prompt 的计算和内存可以在输出序列中共享。这种做法使得在并行采样和集束搜索的内存使用量降低了 55%。这可以转化为高达 2.2 倍的吞吐量提升。
3. 未来前瞻
整体来说,目前基于自注意力的算法的改进方向主要存在于四个方面 :
1)增强局部上下文信息
比如当出现一个句子为“Bush held a talk with Sharon",当“Bush”对齐到“held”时,我们希望自注意力模型能同时将更多注意力放到其邻近的词“a talk”上。这样,模型能捕获短语“held a talk”获取到更多的信息。
2)降低复杂程度
代表就是sparse attention,通过降低FLOPS,达到对更长序列的处理。那么算法如何更优雅,效果如何更好便是追求的重点。
3)Kernel技术
核技巧是一种在机器学习中经常使用的方法,特别是在支持向量机中。其主要思想是通过某种函数(核函数)隐式地在高维空间中计算点积,而无需显式地计算高维表示。Kernel attention 则是一种近似机制,主要思想是使用核技巧(kernel trick)来估计原始注意力的计算。这种方法尤其在长序列上很有效,因为它可以显著减少计算和存储的需求。常见的方法比如FAVOR+,它的关键思想是使用特征映射 ϕ \phi 来近似 softmax 函数。
4)位置编码
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:
1、想办法将位置信息结合进输入序列中,这构成了绝对位置编码的一般做法;
2、通过调整self-attention矩阵来计算不同位置上的注意力值,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁。所以相信未来的位置编码也是研究的重点。
写在最后
目前计算能力依然是限制神经网络发展的瓶颈,自注意力机制作为transfomer中算力需求很大的一个模块,是优化的重点之一。如何将复杂度降低为线性或更低的同时保证模型的效果,就是优化的重点。对于随着自主机制而来的就是位置编码。两者在优化中的配合也是未来的优化方向之一。总而总之,不能重复造轮子,深度学习的算法优化总是应该多借鉴前人的工作,站在巨人的肩膀上。我们期待着未来有更多精巧的算法的涌现。

*本文部分插图来自论文《A Survey of Transformers》
*本文部分插图来自李宏毅老师2022 年春季机器学习课程
*本文部分插图使用 AI 生成















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









