






小显存大模型:24G显存运行DeepSeek-R1 671B的神奇方法
©作者|Lorne
来源|神州问学
背景
随着大语言模型技术的快速发展,参数规模不断扩大,模型性能日益增强。然而,模型参数量的增加往往意味着推理时显存需求的激增,如何在保证推理性能的同时降低显存占用,成为众多科研人员关注的重点。近年来,GPTQ量化技术、PagedAttention、FlashAttention等性能优化技术相继出现,并被集成到vLLM等主流推理框架中,大幅提升了推理效率。
2025年1月20日,临近中国春节,DeepSeek团队发布了DeepSeek-r1模型,迅速引爆中文互联网,被人誉为“国运级科技成果”。尽管该模型完全开源,但其性能已逼近OpenAI的商业闭源模型GPT-o1,引发了广大科技爱好者的极大关注。然而,DeepSeek-v3/r1模型高达671B的参数量使其推理所需显存需求高达数百上千GB,通常需要配备至少8张80GB显存的H800服务器才能正常部署。对于企业用户而言,这种硬件配置或许在可承受范围内,但对于个人开发者和爱好者而言,高昂的成本无疑构成了巨大的门槛。
那么,是否存在在个人消费级显卡上运行DeepSeek-r1/v3的可能?答案是肯定的。
早在2024年7月,清华大学KVCache.AI项目团队联合Approaching AI开源了一款轻量级推理框架——Ktransformers。该框架通过一系列内存优化及技术,成功在21GB VRAM显卡搭配136GB内存的设备上本地部署了246B参数的DeepSeek-v2模型。2025年2月10日,Ktransformers团队更进一步,成功在单张RTX 4090D (24GB VRAM) 配合382GB内存的配置下,实现了对DeepSeek-r1/v3模型的推理,并将推理速度相较于llama.cpp框架提升了3-28倍。

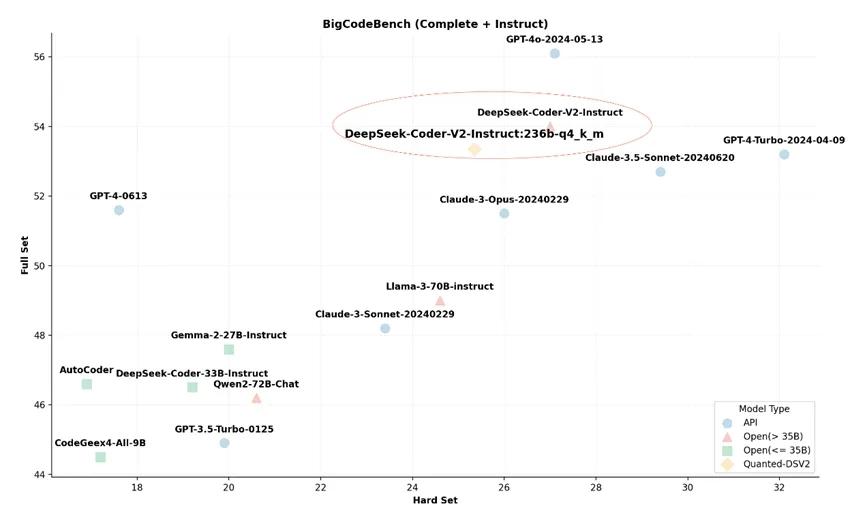
图1:21GB VRAM+136GB DRAM推理DeepSeek-v2的4 bit量化版本
从图中可以看出,基于Ktransformers推理框架的模型版本与原版表现基本一致,没有明显的性能下降情况。

表1:单插槽: 382G 内存,至少 14GB 显存 双插槽: 1T 内存,至少 14GB 显存
表格中展示了Ktransformers v0.2版本本地推理671B DeepSeek-v3 4 bit量化版本的速度与llama.cpp技术的对比,6个专家是v0.3的前瞻版本,使用了专家选择策略和英特尔AMX指令集进一步提升了预填充和解码速度。
Ktransformers项目地址:https://github.com/kvcache-ai/ktransformers
技术细节

图2:Ktransformers架构图
CPU与GPU的异构划分
不同于Llama3.1和Qwen2.5系列的dense架构,DeepSeek采用了一个稀疏的MoE架构,即混合专家模型。这就意味着,对于236B的DeepSeek-v2模型,每次只需要激活21B的参数,而对于671B的DeepSeek-v3模型,每次只需要激活37B的参数。基于MoE架构的特性,Ktransformers项目使用带宽低但是容量更大的CPU DRAM组合量化技术来实现本地推理的优化。即非共享部分的稀疏专家矩阵放到CPU/DRAM上,并采用llamafile提供的高速算子处理,稠密部分放到GPU上采用Marlin算子处理的异构划分策略。
CUDA Graph
大模型推理阶段的很多操作其实是很小粒度的线性代数计算,例如矩阵乘法、激活函数等,每一次操作都需要对应一个CUDA Kernel执行。但是目前GPU的运算性能很强,每一个小粒度操作的时间都非常短,但是GPU却要频繁等待调用,导致大量的时间与算力被浪费。为了解决这个问题,除了使用C++来缩短调用GPU动作的时间之外,也可以选择调用CUDA Graph来将多个运算操作合并成一个Kernel一次性执行,这样后续重复执行相同运算操作时只需要再将整个Graph再传给GPU就可以避免GPU的频繁等待。因此如何设计来减少Graph的断点。
虽然Torch和transformers已经针对于CUDA Graph做了一些集成和断点消除的工作,Ktransformers在此基础之上继续进行了优化,做到一次Decode操作仅有一个完整的CUDA Graph,并且在CUDA Graph中生成了一个调用CPU函数的可被caputure的node,以将MoE算子offload到CPU DRAM上运算,并每层进行一次同步。
灵活易配置
通过修改ktransformers的配置yaml文件,可以很方便地调整CPU/GPU运算的部分。按照基于计算强度指导的 Offload 策略,按照计算强度排序,优先将计算强度高的放入GPU(MLA > Shared Expert > Routed Expert),直到GPU放不下为止,还可以设置多张卡进行流水线并行。如果将Expert的运算交给CPU后仍然存在显存不够的问题,甚至可以将一部分算子也同时放进CPU和DRAM中,或者把性能较差的算子,如nn.Linear,替换成更快的算子,如Marlin,开发者也可以实现一个自己的算子并非常简单地移植到框架当中。
加速长文本推理
在一些支持长文本推理的模型场景中,即使模型本身可能不大,但是长上下文带来的KV cache仍然会占用大量的内存空间,从而很有可能仍然出现内存溢出的问题,如InternLM2.5-7B-Chat-1M 模型权重仅需 15.49GB 显存,但额外需要 145.49 GB 才能存下整个 1M 的 KVCache,这显然是一笔巨大的内存开销。不过近期的许多研究都发现,在推理阶段的注意力分布是稀疏的,也就是说,在一个很长的文本序列中,只有极少量的token会有较大的attention score,因此如果能够只针对于这些稀疏的attention score进行运算,就可以大大减少内存的需求。基于这些关于KV cache稀疏性的研究,Ktransformers提出了高效 CPU 稀疏 attention 算子通用框架。利用这个框架,测试发现相比于llama.cpp,在同样的硬件条件下Ktransformers的预训练速度可以达到llama.cpp的20.6~94.1倍,推理速度可以达到1.2~7.1倍。
Ktransformers体验
我们可以在一台显存不小于24GB,内存不小于400GB的服务器上对DeepSeek-R1模型进行部署,CUDA版本不小于12.1。
首先要下载DeepSeek-r1的Q4_K_M版本,可以在huggingface上直接选用unsloth量化好的版本下载使用。
解释
%pip install huggingface_hub
from huggingface_hub import snapshot_download
snapshot_download(
repo_id = "unsloth/DeepSeek-R1-GGUF",
local_dir = "DeepSeek-R1-GGUF",
allow_patterns = ["*Q4_K_M*"]
)
snapshot_download(
repo_id="deepseek-ai/DeepSeek-R1",
local_dir="./deepseek-r1-config",
ignore_patterns=["*.safetensors"]
)这段代码可以从huggingface社区上下载DeepSeek-r1的Q4_K_M版本权重,并且在DeepSeek-r1项目中下载模型的配置文件,忽略模型权重。接下来需要安装环境依赖和Ktransformers库。
在终端命令行中输入
解释
sudo apt-get update
sudo apt-get install build-essential cmake ninja-build
conda create --name ktransformers python=3.11
conda activate ktransformers
conda install -c conda-forge libstdcxx-ng
strings ~/anaconda3/envs/ktransformers-0.3/lib/libstdc++.so.6 | grep GLIBCXX
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip3 install packaging ninja cpufeature numpy
pip3 install flash-attn
git clone https://github.com/kvcache-ai/ktransformers.git
cd ktransformers
git submodule init
git submodule update
bash install.sh上面的代码安装了一些必要的C++依赖,建立了一个conda虚拟环境,然后安装了必要的Python库,最后从Github上克隆并安装了Ktransformers库。
也可以选择安装v0.3前瞻版本,这个版本基于英特尔AMX指令集和专家选择机制对prefill速度又进行了一定的优化,但注意该版本仅支持英特尔处理器。
模型和推理框架都下载安装完成后,我们便可以很方便地用指令来启动Ktransformers推理服务。
解释
ktransformers --model_path /path/to/deepseek/config --gguf_path /path/to/deepseek/gguf --port 10002
这条指令会在本机的10002端口暴露出一个RESTful风格的API接口,然后就可以通过这个端口和模型聊天,或者基于这个端口开发一些简单的私人助手应用了。例如你可以重新打开一个新的命令行窗口,执行下面的代码来发起请求。
解释
curl -X 'POST' http://localhost:10002/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-R1",
"messages": [{"role": "user", "content": "你好!DeepSeek!"}],
}'就可以与DeepSeek进行交互了。
你也可以在启动推理服务的命令中加入其他参数来进一步管理框架。如你可以设置参数--cpu_infer num_of_cores来规定使用多少个CPU核心,你也可以设置—force_think true来使DeepSeek-R1强制进行深度思考等等。
总结思考
借助前人的研究成果和开发人员的创新精神,Ktransformers利用多种技术共同将硬件算力资源使用达到了极致。同时开发人员也表示,有意将改进的代码贡献到vLLM或llama.cpp等推理框架或者上游代码库,相信今后我们很快也能在主流模型推理框架上享受到Ktransforemers的内存占用级别,并且支持offload到CPU运算来节省显存。
这种技术突破不仅降低了高性能大模型推理的硬件门槛,也让更多个人开发者和中小企业有机会参与到大语言模型的研究与应用中。这也体现了人工智能社区中开源精神的力量,打破了技术壁垒,推动了AI技术的普及与发展。随着Ktransformers的不断完善以及社区的广泛参与,未来AI推理框架将更加高效、灵活,进一步加速大语言模型的落地应用,助力AI技术的发展进入一个全新的时代。

















 2978
2978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









