







万字长文,2024AI行业的科研角力
©作者|Zhongmei
来源|神州问学
前言
吴恩达的网站上周发表了一篇名为《A Year of Contending Forces》的文章,该文章是围绕着一个名为《State of AI Report - 2024》的年度报告的总结和点评。该报告由Nathan Benaich和Air Street Capital团队制作,这是该报告的第七年,新报告记录了过去一年推动AI发展的强相互作用力:开源与专有技术、公共与私人融资、创新与谨慎,汇聚了来自于2024年的研究论文、新闻文章、财报等的亮点。本文将对原报告内容进行解读。
为什么觉得这篇报告重要?
该报告是从投资者的角度审视了上次报告之后的一年时间里AI的发展,力图分析其中的变化并挖掘出趋势。作者们深入研究了今年的研究发现、商业交易和政治动态,希望以此为下个一年的AI提供全面的分析。同时,作为一个年度报告,该团队敢于做出明确的预测。并十分具有critical thinking,敢于在一年后评估自己的准确性,吴恩达也表示这种原则性方法很值得称赞。
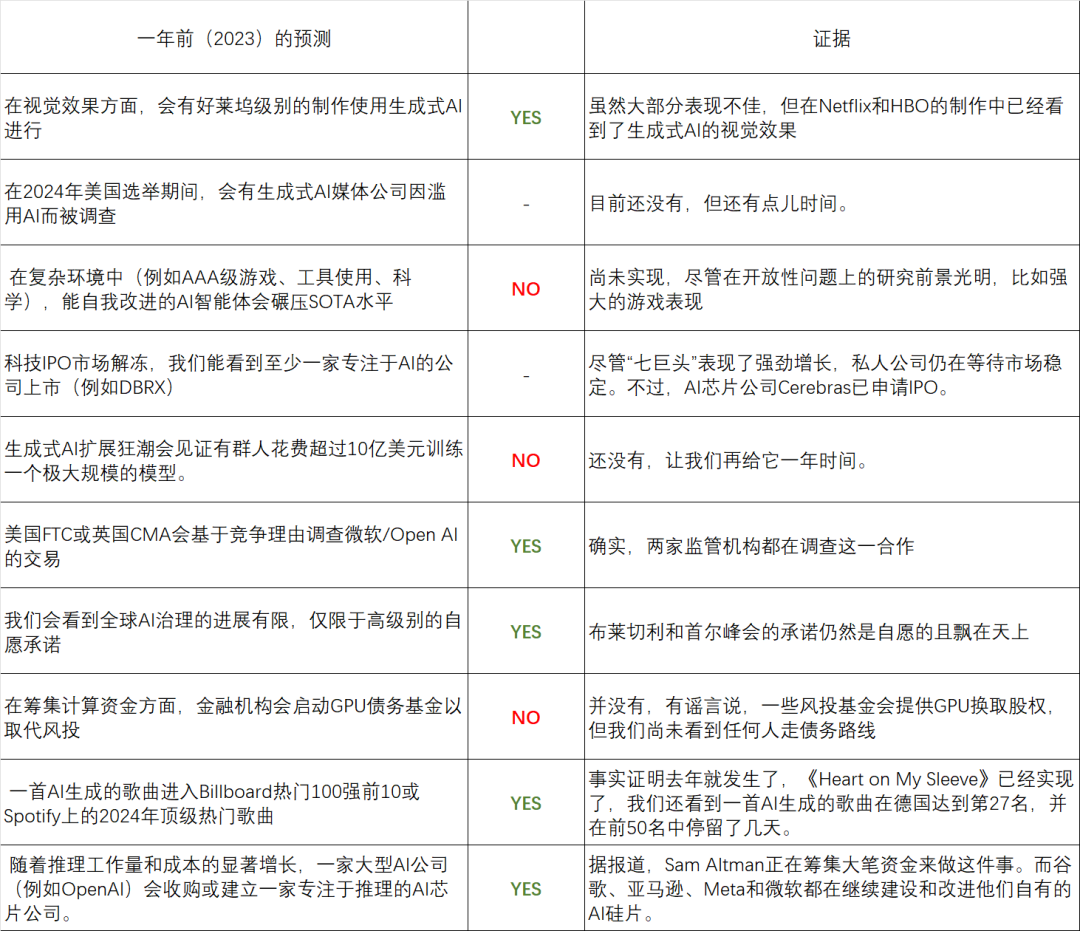
表一:Air Street Capital团队对自己去年的AI年报中做的预测进行的review
报告中的关键信息
报告中考虑了以下关键维度:
- 研究:技术突破及其能力。
- 行业:AI的商业应用领域及其商业影响。
- 政治:AI的监管,其经济影响以及AI不断演变的地缘政治。
- 安全:识别和缓解未来高能力AI系统可能对我们造成的灾难性风险。
- 预测:未来12个月会发生的事情
由于报告《State of AI Report - 2024》篇幅长达210+页,本篇将只涵盖研究部分的前一半,余下的会在下一周里陆续发出。
研究
● 顶尖模型
在这一年的大部分时间里,各种基准测试和社区排行榜都显示GPT-4与“其他最佳”之间存在一个巨大的鸿沟。但Anthropic的Claude 3.5 Sonnet、Google的Gemini 1.5和X.ai的Grok 2,基本消除了这一差距,模型性能现在开始趋于一致。模型现在一致被认为是高能力的编码者,擅长事实记忆和数学,但在开放式问题解答和多模态问题解决方面表现不佳。有些时候模型的差距也被认为是使用方式不同的产物。例如,GPT-4o在MMLU上表现优于Claude 3.5 Sonnet,但更具挑战性的MMLU-Pro基准上表现似乎不如后者。考虑到架构之间相对微妙的技术差异以及预训练数据中可能存在大量重叠,模型构建者现在越来越需要在新能力和产品特性上进行竞争。
● 推理计算
随着风声很大的“Strawberry”的着陆,大家意识到应该加倍投入到推理计算的扩展中。通过将计算从 pre-training和post-training转移到推理,o1采用链式思考(COT)风格逐步推理复杂的提示,运用强化学习(RL)来加强COT及其使用的策略。这打开了过去LLM因预测下一个token的固有限制而挣扎的领域的可能性,比如多层次数学、科学和编程。OpenAI团队显然很早就意识到了推理计算的潜力,o1在其他实验室探索该技术的论文发表几周内就出现了。根据OpenAI报告,与4o相比,o1在以推理为重的基准测试中取得了显著进展,最明显的是在2024年AIME(竞赛数学)上,对比以前的13.4分,现在得分高达83.83。然而,这种能力的代价非常高昂:对于o1-preview来说,1M输入token的成本为15美元,而1M输出token的成本却高达60美元。这使其比GPT-4o贵3-4倍。甚至,OpenAI在其API文档中明确表示,它不是4o的直接替代品,也不是最适合需要快速响应、图像输入或函数调用的任务的模型。
● 开源与闭源
Llama 3 缩小了开源模型与封闭模型之间的差距。Meta坚持使用自Llama 1以来一直使用的相同的decoder-only架构,只进行了小的调整(即增加了更多的transformer层和注意力头的数量)。Meta在4月推出了Llama 3系列,7月推出了3.1版本。迄今为止最大的Llama 3.1 405B能够在推理、数学、多语言和长上下文任务中与GPT-4o和Claude 3.5 Sonnet匹敌。这标志着第一次一个开源模型与前沿商业模型之间的差距被赶上。Meta使用了15T token(明显超出了“Chinchilla最优”训练计算量)在16,000个H100 GPU上进行了Llama 3.1 405Bd的训练,这是第一个在此规模上训练的Llama模型。随即9月退出的Llama 3.2中加入了11B和90B的VLM,是Llama的多模态首次亮相。前者与Claude 3 Haiku竞争,后者与GPT-4o-mini竞争。该公司还发布了1B和3B的仅文本模型,设计用于在设备上运行。基于Llama的模型在Hugging Face上的下载量现已超过440M次。同时需要注意的是“开源”模型有多“开放”?一些研究者提出,这个术语常常被误导性地使用,有时候在权重、数据集、许可以及访问方法这些完不相同的方面,容易被混为一谈。
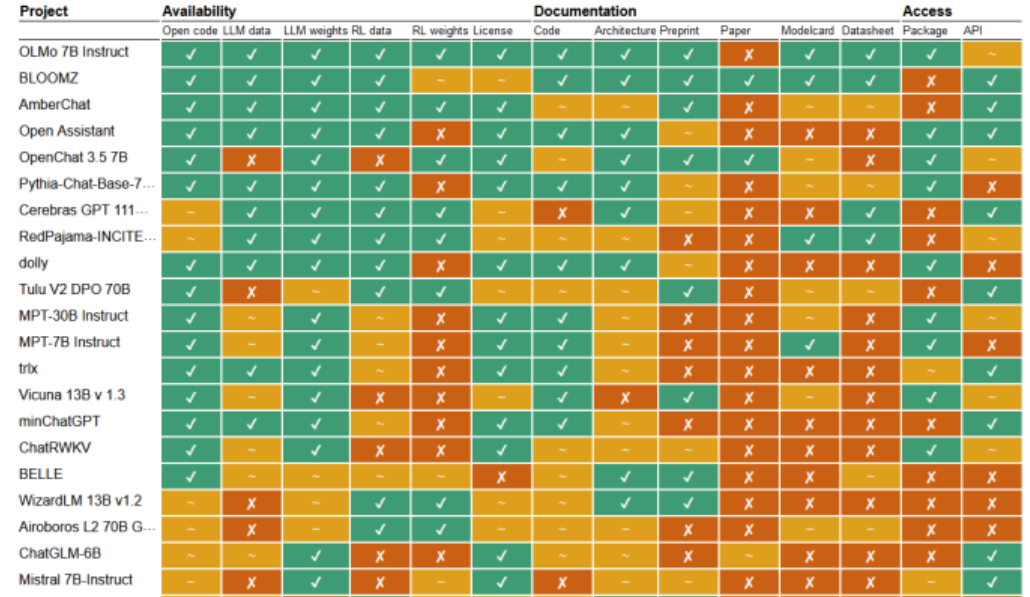
图1. 各模型开放情况对比(来源于《State of AI Report - 2024》)
● 数据污染
随着越来越多的新模型家族报告出色的基准性能,研究人员越来越关注数据集污染(即测试或验证数据泄漏到训练集中)。Scale的研究人员使用了一个新的Grade School Math 1000(GSM1k)数据集,对多种模型进行了重新测试,该数据集的风格和复杂性与GSM8k基准相似,他们发现某些情况下测试结果出现显著下降。同样ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









