







Tensorflow数据集
import tensorflow_datasets as tfds预加载数据的问题和解决
加载可能会报错,原因在于etils库太新不兼容,以下操作解决问题
conda install etils=0.8.0
之后tfds.load 会出现无法访问远程连接,也就是国内网络被墙的问题,参考以下blog解决(还是要翻墙('~'))
TensorFlow Dataset下载速度慢手动下载替换数据集_tensorflow dataset数据集手动下载-CSDN博客
数据的预处理
def normalize_img(image, label):
# normalize images
return tf.cast(image, tf.float32) / 255.0, label
AUTOTUNE = tf.data.experimental.AUTOTUNE
BATCH_SIZE = 64
ds_train = ds_train.map(normalize_img, num_parallel_calls=AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(ds_info.splits['train'].num_examples)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(AUTOTUNE)
ds_test = ds_test.map(normalize_img, num_parallel_calls=AUTOTUNE)
ds_test = ds_test.batch(128)
ds_test = ds_test.prefetch(AUTOTUNE)- normalize 归一化
- cache 使部分数据常驻内存,加快训练时加载速度
- shuffle 打乱
- batch 批处理
- preferch 取回批处理数据
自建个简单模型然后训练
model = keras.Sequential([
keras.Input((28, 28, 1)),
layers.Conv2D(32, 3, activation='relu'),
layers.Flatten(),
layers.Dense(10),
])
model.compile(
optimizer=keras.optimizers.Adam(lr=0.001),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
model.fit(ds_train, epochs=5, verbose=2)
model.evaluate(ds_test)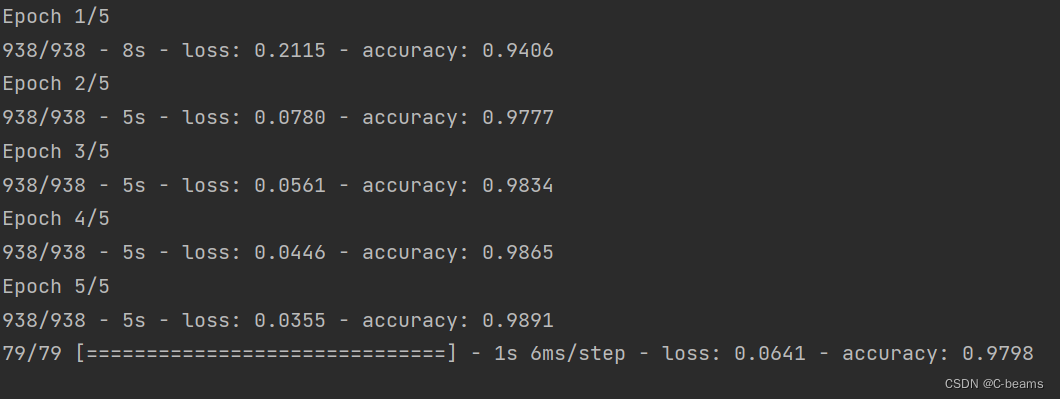
文本处理
数据预处理
- 导入
(ds_train, ds_test), ds_info = tfds.load(
'imdb_reviews',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)- 标记
tokenizer = tfds.deprecated.text.Tokenizer()- 建立词汇集
def build_vocabulary():
vocabulary = set()
for text, _ in ds_train:
vocabulary.update(tokenizer.tokenize(text.numpy().lower()))
return vocabulary
vocabulary = build_vocabulary()- 编码成数字
encoder = tfds.deprecated.text.TokenTextEncoder(
vocabulary, oov_token='<UNK>', lowercase=True, tokenizer=tokenizer
)
def my_encoding(text_tensor, label):
return encoder.encode((text_tensor.numpy())), label
def encode_map(text, label):
encoded_text, label = tf.py_function(
my_encoding(), inp=[text, label], Tout=(tf.int64, tf.int64)
)
encoded_text.set_shape([None])
label.set_shape([])
return encoded_text, label- shuffle, batch, prefetch
AUTOTUNE = tf.data.experimental.AUTOTUNE
ds_train = ds_train.map(encode_map, num_parallel_calls=AUTOTUNE).cache()
ds_train = ds_train.shuffle(10000)
ds_train = ds_train.padded_batch(32, padded_shapes=([None], ()))
ds_train = ds_train.prefetch(AUTOTUNE)
ds_test = ds_test.map(encode_map)
ds_test = ds_test.padded_batch(32, padded_shapes=([None], ()))compile and fit
model = keras.Sequential([
layers.Masking(mask_value=0),
layers.Embedding(input_dim=len(vocabulary)+2, output_dim=32),
# BATCH_SIZE x 1000 -> BATCH_SIZE x 1000 x 32
layers.GlobalAveragePooling2D(),
# BATCH_SIZE x 32
layers.Dense(64, activation='relu'),
layers.Dense(1), # less than 0 negative, greater or equal than 0 positive
])
model.compile(
loss=keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=keras.optimizers.Adam(3e-4, clipnorm=1),
metrics=['accuracy']
)
model.fit(ds_train, epochs=10, verbose=2)
model.evaluate(ds_test)数据增强Data augmentation
第一种方式:函数定义(运行在CPU上)
def augment(image, label):
new_height = new_width = 32
image = tf.image.resize(image, (new_height, new_width))
if tf.random.uniform((), minval=0, maxval=1) < 0.1:
image = tf.tile(tf.image.rgb_to_grayscale(image), [1, 1, 3])
image = tf.image.random_brightness(image, max_delta=0.1)
image = tf.image.random_contrast(image, lower=0.1, upper=0.2)
image = tf.image.random_flip_left_right(image) # 50%
return image, label在batch之前使用增强
ds_train = ds_train.map(augment,num_parallel_calls=AUTOTUNE)第二种方式:作为模型的一部分
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.Resizing(height=32, width=32),
layers.experimental.preprocessing.RandomFlip(mode='horizontal'),
layers.experimental.preprocessing.RandomContrast(factor=0.1),
]
)
model = keras.Sequential([
keras.Input((32, 32, 3)),
data_augmentation,
layers.Conv2D(4, 3, padding='same', activation='relu'),
layers.Conv2D(8, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10),
])一些问题
类似于添加正则化l2,dropout 的数据增强, 这种不容易导致过拟合

















 728
728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









