






论文标题:Language Models are Few-Shot Learners
论文链接:https://arxiv.org/pdf/2005.14165.pdf
论文代码地址:https://github.com/openai/gpt-3
GPT系列主要会分享生成式模型,包括gpt1、gpt2、gpt3、codex、InstructGPT、Anthropic LLM、ChatGPT等论文或学术报告。本文主要分享gpt3的论文。
重铸系列会分享论文的解析与复现,主要是一些经典论文以及前沿论文,但知识还是原汁原味的好,支持大家多看原论文。分享内容主要来自于原论文,会有些整理与删减,以及个人理解与应用等等,其中涉及到的算法复现都会开源,代码或者更多内容请关注微信公众号「学长论文指导」回复关键字「156」即可获取!

介绍
当前处理问题的主要范式是预训练+微调,这种方式的主要限制是需要任务相关的数据集以及特定的微调。每一个新的任务,都需要大量的带标签的数据,这极大地限制了预训练语言模型的能力。微调之后的预训练模型,也常常会过拟合任务数据,从而丢失处理其他问题的能力。反观人类,在绝大多数任务上,不需要大量的标记数据就能学习好。
由此本论文训练了一个1750亿参数的自回归语言模型--GPT3,并测试其in-context学习性能。论文测试了超过24种NLP数据集,并都以3种方式进行评估,分别是:few-shot学习,one-shot学习,zero-shot学习。
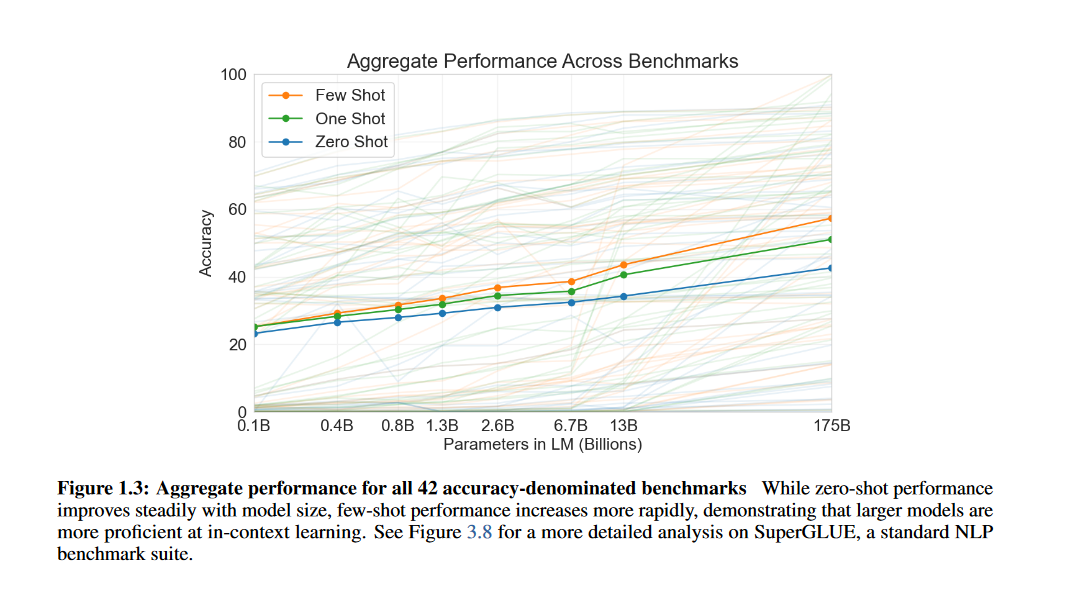
论文发现,对大部分任务,其性能都随着模型容量的增加而提高,这可能表明越大的模型越适合in-context学习方式。下图就展示了所有任务汇总的指标,在三种评估方式下,随着模型参数变化的情况。
模型
GPT3的基本上就是一个大号的GPT2,更大的模型容量,更多的训练数据,和更长时间的训练。
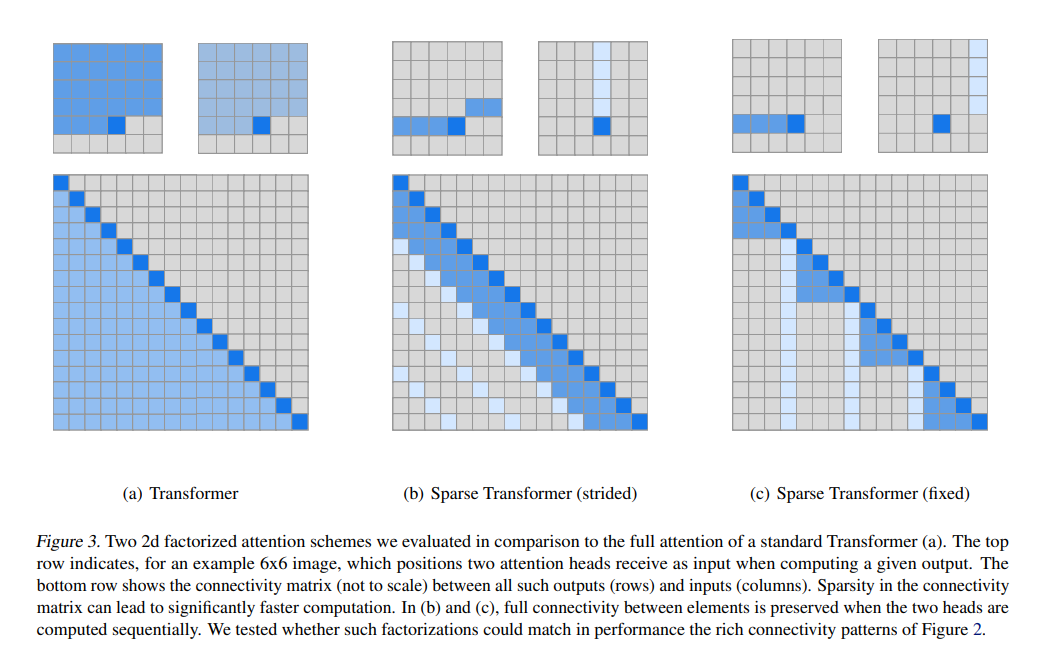
GPT3和GPT2的模型结构基本一致,除了Transformer内部结构。GPT3的Transformer使用的是类似稀疏Transformer【1】的结构,如下图展示的那样,这种结构可以提高Transformer计算的效率。下图中深蓝和浅蓝都是需要计算的点,左侧是原始结构需要计算的示例图,中间是图片输入的计算图,右侧是文本输入需要计算的图。具体计算公式,请参考论文【1】。
训练过程中会计算梯度噪声尺度,用来指导选择batch size的大小。相关的一些超参数,像模型优化器、学习率等超参数如下所示:
Adam
梯度截断:1.0
正则权重衰减:0.1
学习率
在头3.75亿token内,线性提高lr大小。
在2600亿token内,cosine衰减到10%大小,然后保持该大小继续训练。
batch size
在头40-120亿token内,从32k慢慢提高到该模型尺寸的最大值。
序列最大长度:2048
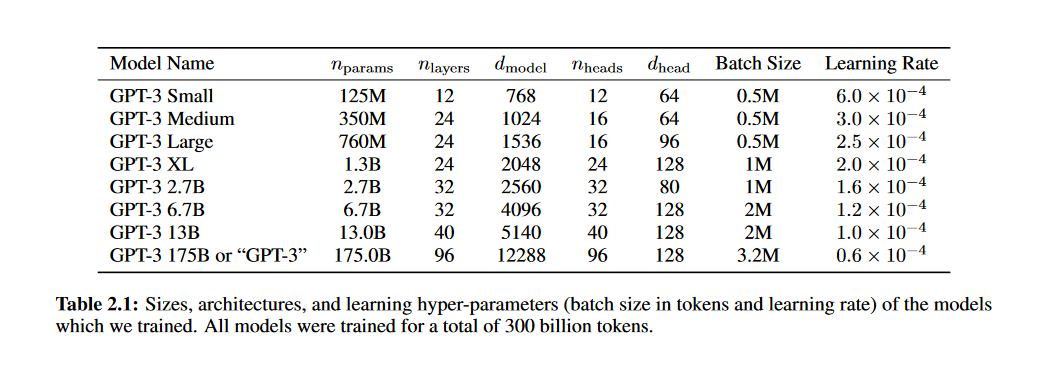
之前的一些工作表明,如果有足够多的训练数据,验证集上的loss和模型大小会逼近平滑的幂率分布【2】。所以本论文也训练了不同大小的模型,在验证集和下游任务上来验证这一假设。各个模型的规模参数如下表所示:
训练数据
Common Crawl有足够多的数据,但是质量较低,论文中采取了3个步骤来提高数据质量。
-
以WebText内的数据作为高质量数据,Common Ceawl的为低质量数据,训练了一个简单的逻辑回归模型来判断数据质量,通过这个模型进行过滤获取了一版Common Crawl数据。
-
进行了模糊去重处理,保证了不会在留作验证集的保留数据上过拟合。
-
增加了已知的一些高质量的数据集,提高数据集的多样性。
论文下载的Common Crawl数据包含了45TB的文本,过滤后还保留570GB,大约相当于4000亿的BPE token数量。不过在实际训练过程中,并不是按照数据集的大小来进行采样的,而是将质量更高的数据集赋予了更大的采样权重。实际上就是使用少量数据的过拟合来交换更高质量的训练数据。各个数据的采样分布如下表所示。
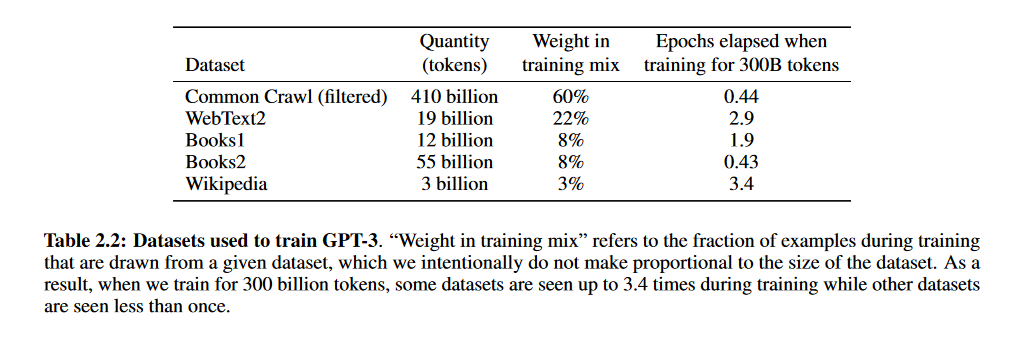
训练数据处理,还有一个比较重要的事,就是判断跟各个任务评测数据集的重合度,以降低靠记忆数据带来的指标虚假提高。论文中表示,原本是计划实现去除重复的数据的,不过过滤过程出现了bug,导致一些数据并没有被过滤掉,但重新训练模型成本实在太大(豪如openAI也负担不起),只能在后续评测过程中,反向操作,删除出现在训练数据里的测试数据。
评测方式
论文使用三种方式来评测所有的任务,包括few-shot、one-shot和zero-shot。
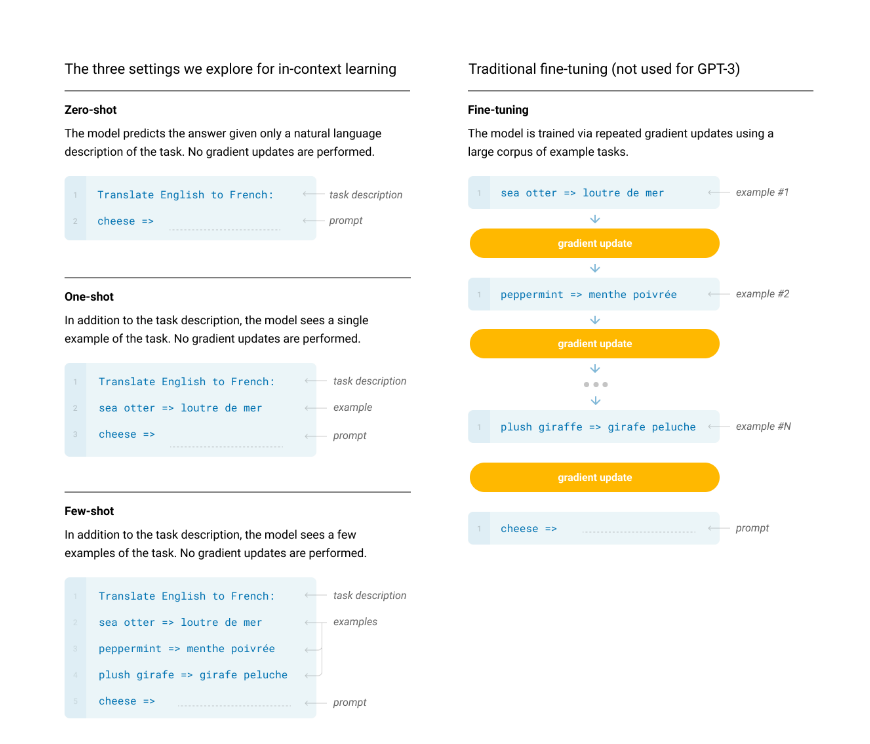
上图简单描述了这三种方式以及当前流行的fine-tuning的方式。简单地说,few-shot就是给定K个样本(一般10-100个之间),然后预测任务,通常情况下,K越大效果越好,但也不是一定的;one-shot就是只给定一个样本;而zero-shot就是一个样本都不给,直接预测任务。当然,除了是否给样本之外,还会给出一个任务描述,让模型能够更好地处理不同的任务,如图中所示的任务描述“Translate English to French”。除此之外,这三种方式,跟原本的fine-tuning最大的不同,在于是否改变模型的参数。fine-tuning会在学习样本的过程中,不断调整自身模型的参数,而本文的几种方式,则完全不会调整模型的参数。这也是一个模型处理所有任务的基础所在。
实验
Power-law
本论文也证明了【2】中的观点,在充分利用训练计算效率时,语言模型的性能是符合幂律的,如下图所示。除此之外,后续在各个任务上的实验也证明,随着loss的下降,各个任务上效果也得到了一致的提升。

此段笔者增加。随着训练计算量的增加,各个大小的模型的验证集loss在不断下降,但在某个点之后,loss下降的速度大幅减小,不同模型的这个点和其容量大小符合幂律分布。基于此,在训练不同大小的模型时,可以在最优的时间点停止模型训练,从而达到计算资源利用率最大的效果,如果想进一步提高模型效果,选择一个更大容量的模型会更明智。
Task
论文评测了大量的nlp任务,这边不会详细介绍,任务内容大体分为下面几类:
-
Language Modeling,Cloze,and Completion Tasks
-
Closed Book Question Answering
-
Translation
-
Winograd-Style Tasks
-
Common Sense Reasoning
-
Reading Comprehension
-
SuperGLUE
-
NLI
-
Synthetic and Qualitative Tasks
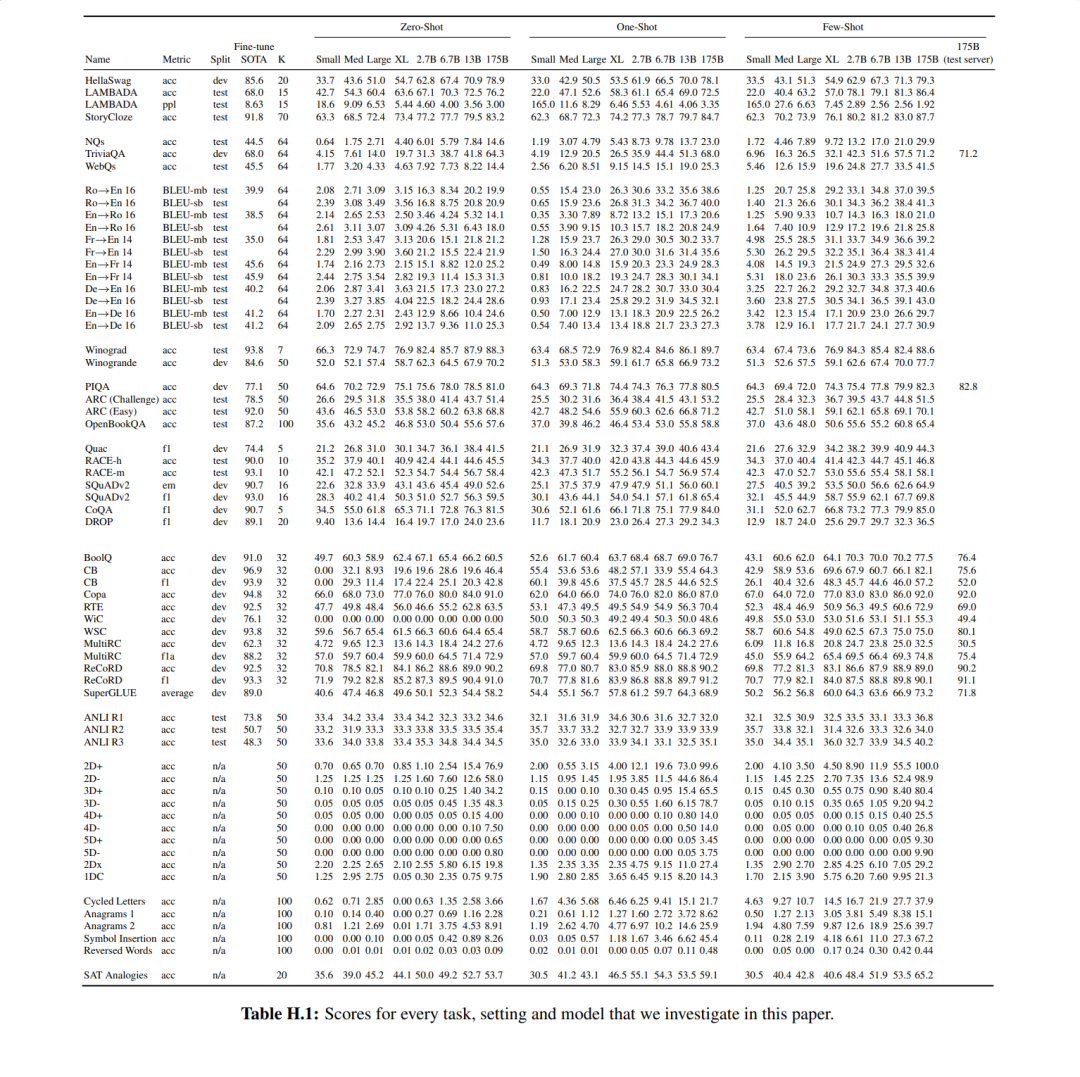
各个大小的模型,在各个任务上的指标如上表所示,其中也包含了当时最优方法的效果。与GPT2相比,GPT3的在各个任务上的效果都提了一大截,在某些任务上,甚至比SOTA的有监督方法更好。
新任务
这一块就是上一个小节里面'Synthetic and Qualitative Tasks'的任务,包含一些即时计算推理任务、不太可能在训练中发生的新模式任务、或者不寻常的任务等。
其中比较有意思的,数学(加减乘)计算任务,新词造句任务(创造一个新词,给解释,然后让模型造句),以及文章生成任务。
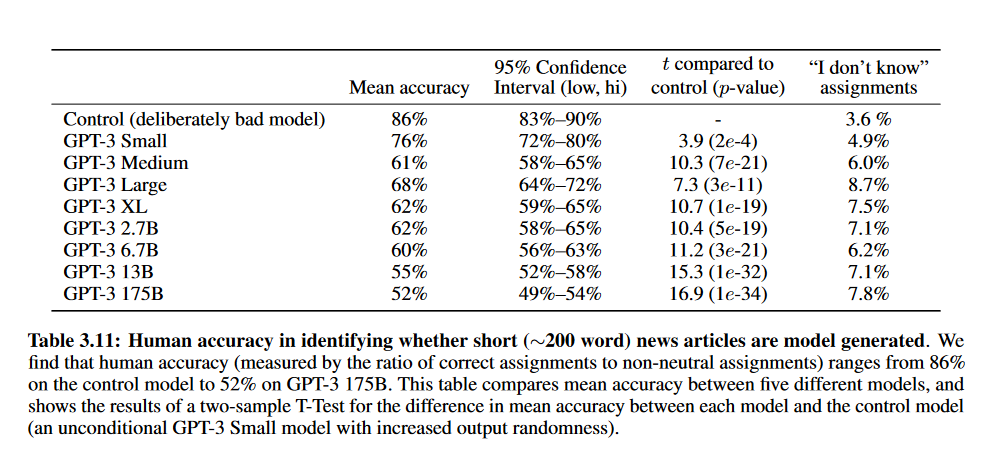
计算任务上的表现,只能说差强人意;造句任务,则基本令人满意;文章生成任务,一定程度上表现了模型的能力所在,这类任务模型较为擅长,且生成出的文章,人类基很难辨别是否是模型生成的,相关指标如下表所示。
记忆or泛化
跟GPT2的论文一样,本论文也讨论了模型的效果,是因为有泛化能力,还是只因为记住了测试数据而已(因为测试数据可能出现在训练数据中)。
overfit
GPT3的模型大小及其训练数据,都比GPT2大上两个数量级,这增加了GPT3过拟合的风险。从下图中可以看出,训练集和验证集的loss是同步下降的,随着训练时间增加,两个loss的差距并没有显式增加,可以认为这个差距并不是过拟合引起的,而是训练集和验证集的数据差异导致的。在参数量1750亿的GPT3上,也是同样的走势,这表明所有模型均没有在训练集上过拟合。
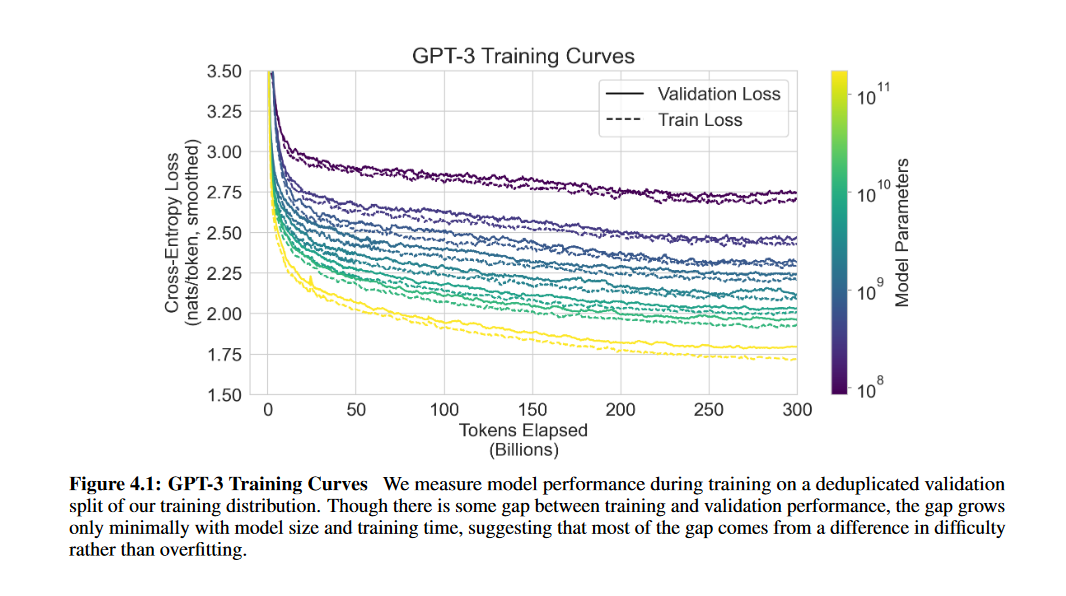
overlap
倒霉的是,由于在清洗数据时的一个bug,导致各个任务上测试集的数据跟训练数据有一定的重合,但重新训练模型又代价昂贵。所以,在每个任务上,都移除了重复数据,再进行评估。下面的图和表,都表示了,各个任务的测试数据和模型训练数据的重合度,以及清理重复数据前后的指标。
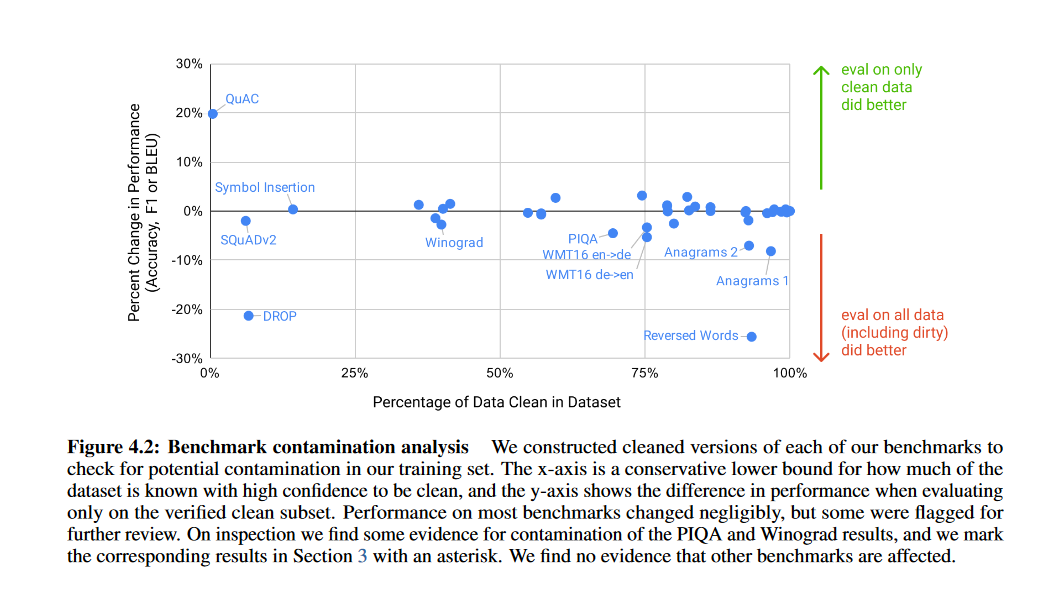
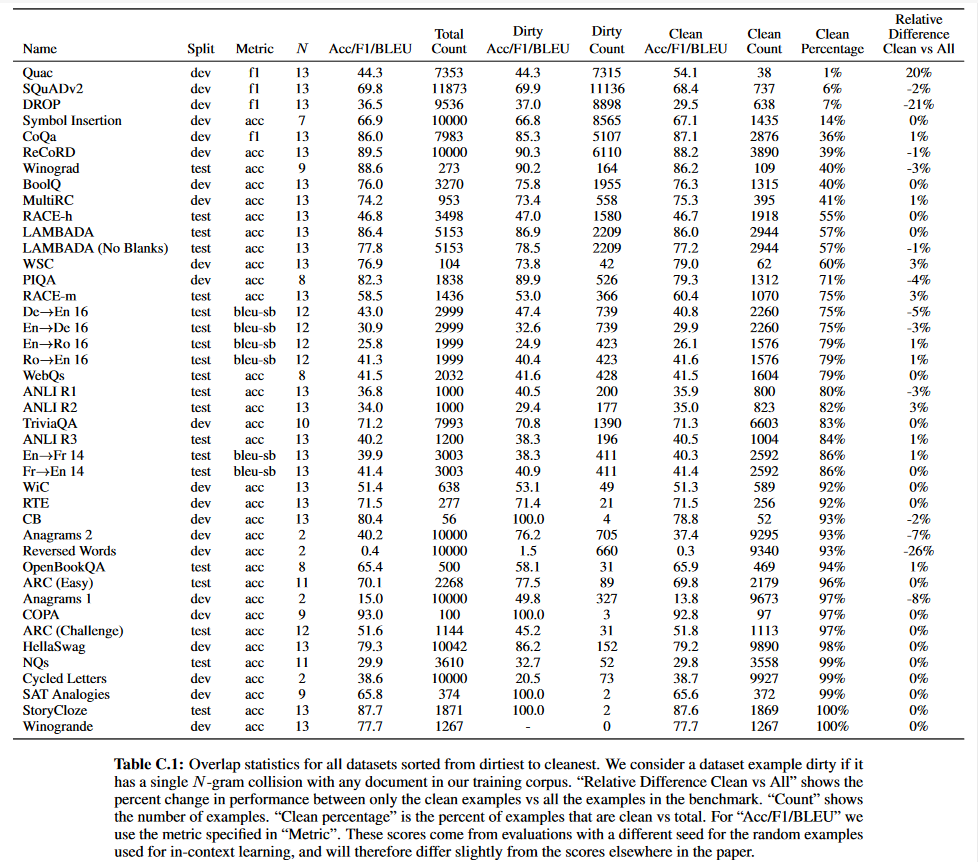
局限
-
GPT3在文本合成和一些NLP任务上效果仍然较弱。比如GPT3有时会在文档级别上不断重复自己,在较长的文章上会失去连贯性,自相矛盾,或者生成不符逻辑的语句,也较难理解物理常识等。
-
结构和算法层面的局限。一些在双向模型结构上表现得好的任务,GPT3可能处理不好。所以结合双向模型做一些工作,是一个好的研究方向。
-
一个关于语言模型(不管自回归还是双向的)更基本的局限,是预训练时的目标函数。当前的目标函数是将所有的token都平等对待的,并不关心哪些更重要。纯粹地放大尺寸(模型容量,数据大小,训练时长等)可能已经达到自监督方法的上限了,所以用不同的方法来破局是必要的。未来比较有前景的研究方向,很可能是从人类这里学习目标函数、基于强化学习来微调(后续工作中chatgpt做了这个方向)、或者添加图像等不同模态的信息来更好地认识世界(后续工作中chatgpt4做了这个方向)。
-
预训练阶段,样本的利用率很低。虽然在预测阶段,只要较少的样本,但在预训练阶段,则是使用了太多的数据,远比一个人类一生能够接触的数据都多。所以提高预训练阶段的样本利用率是未来研究的一个重要方向,也许是提供了现实世界的一些信息,或许是算法层面的改进。
-
一个关于few-shot学习的局限,不确定GPT3模型是否是在推断时真的“从头开始”学习到了新知识,还是模型只是识别并分辨出在训练过程中学习过的任务。所以,理解few-shot为何有效也是一个重要的研究方向(【3】中做了相关的工作)。
-
GPT3的推理不方便又昂贵。对很多任务来说,大模型的能力是过剩的,所以后续的一个可能的方向,是将大模型定向蒸馏成一个适合大小的模型。
-
最后,一个在绝大数深度学习模型上都有的局限,就是缺乏解释性。
其他影响
大语言模型的应用,是把双刃剑。论文主要分析了有害影响,包括以下内容:
-
语言模型的滥用
-
模型中的偏见
-
能耗
论文之外
GPT3可以说就是GPT2在各个维度上的超级加强版,效果上来说也确实提高了不少,但基本上也达到了大力出奇迹的上限。论文验证的power-law对研究人员来说,也很有启发,可以提高研究效率,或者预估模型能达到的效果以及需要的计算资源等。GPT3证明了自回归模型的效果,同时也看到了自身的局限,可以说已经为chatgpt和gpt4指明了方向。
参考
【1】Generating long sequences with sparse transformers
【2】Scaling laws for neural language models
【3】Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
粉丝回馈
【一】上千篇CVPR、ICCV顶会论文
【二】动手学习深度学习、花书、西瓜书等AI必读书籍
【三】机器学习算法+深度学习神经网络基础教程
【四】OpenCV、Pytorch、YOLO等主流框架算法实战教程
➤ 请关注公众号【学长论文指导】回复【156】即可获取
➤ 还可咨询论文辅导❤【毕业论文、SCI、CCF、中文核心、El会议】评职称、研博升学、本升海外学府!















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









