







最近秋招发放Offer已高一段落。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

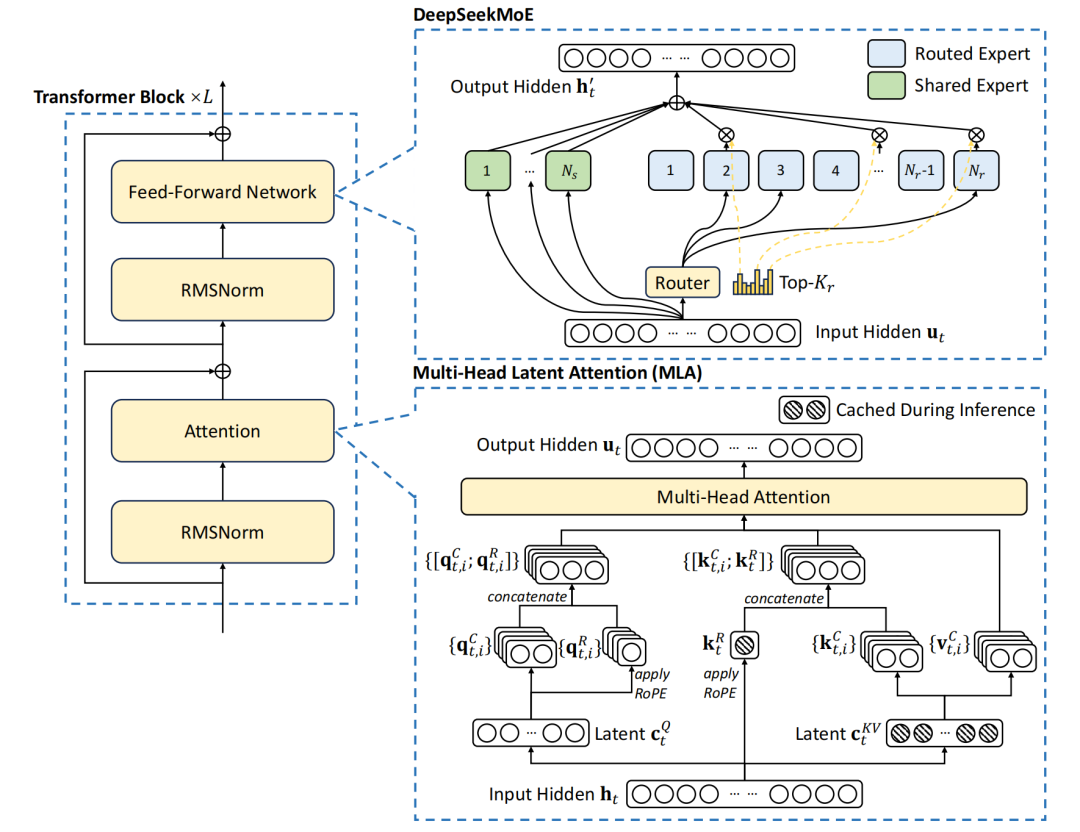
DeepSeek-V3的基本架构仍然基于Transformer框架,为了实现高效推理和经济高效的训练,DeepSeek-V3还采用了MLA(多头潜在注意力)。
MHA(多头注意力)通过多个注意力头并行工作捕捉序列特征,但面临高计算成本和显存占用;MLA(多头潜在注意力)则通过低秩压缩优化键值矩阵,降低显存占用并提高推理效率。
一、多头注意力(MHA)
多头注意力(Multi-Head Attention,MHA)是什么?多头注意力(MHA)是Transformer模型架构中的一个核心组件,它允许模型在处理输入序列时能够同时关注来自不同位置的不同表示子空间的信息。
MHA通过将输入向量分割成多个并行的注意力“头”,每个头独立地计算注意力权重并产生输出,然后将这些输出通过拼接和线性变换进行合并以生成最终的注意力表示。
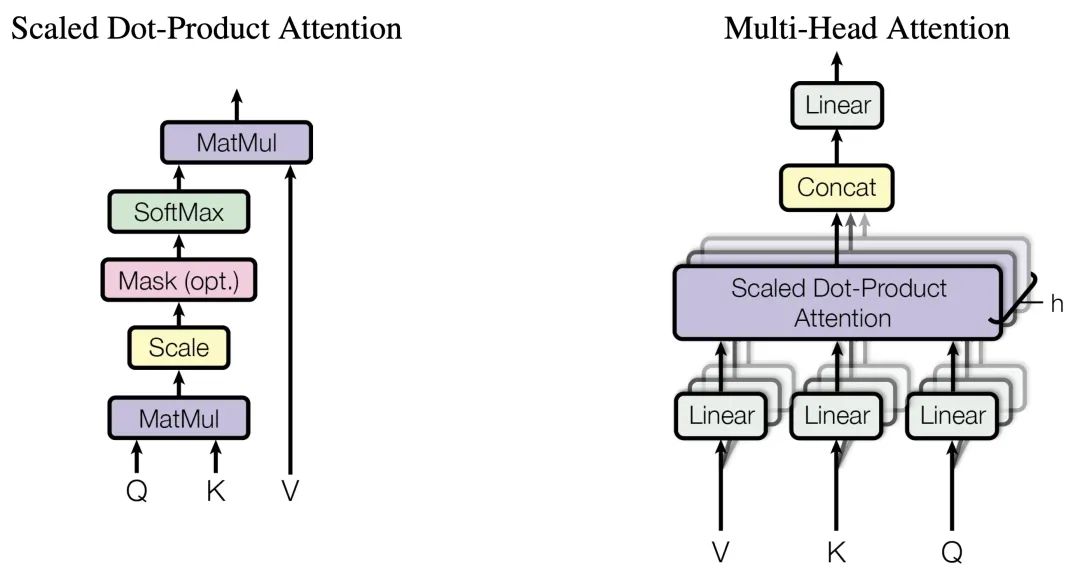
多头注意力(MHA)如何进行Q、K、V计算?多头注意力(MHA)通过线性变换将输入张量分别转换为查询(Q)、键(K)和值(V)矩阵,每个矩阵再被分割成多个头进行并行处理。
-
输入变换:输入序列首先通过三个不同的线性变换层,分别得到查询(Query)、键(Key)和值(Value)矩阵。这些变换通常是通过全连接层实现的。
-
分头:将查询、键和值矩阵分成多个头(即多个子空间),每个头具有不同的线性变换参数。
-
注意力计算:对于每个头,都执行一次缩放点积注意力(Scaled Dot-Product Attention)运算。具体来说,计算查询和键的点积,经过缩放、加上偏置后,使用softmax函数得到注意力权重。这些权重用于加权值矩阵,生成加权和作为每个头的输出。
-
拼接与融合:将所有头的输出拼接在一起,形成一个长向量。然后,对拼接后的向量进行一个最终的线性变换,以整合来自不同头的信息,得到最终的多头注意力输出。

二、多头潜在注意力(MLA)
多头潜在注意力(Multi-Head Latent Attention,MLA)是什么?多头潜在注意力(MLA)是一种改进的注意力机制,旨在提高Transformer模型在处理长序列时的效率和性能。
在传统的Transformer架构中,多头注意力(MHA)机制允许模型同时关注输入的不同部分,每个注意力头都独立地学习输入序列中的不同特征。然而,随着序列长度的增长,键值(Key-Value,KV)缓存的大小也会线性增加,这给模型带来了显著的内存负担。为解决MHA在高计算成本和KV缓存方面的局限性,DeepSeek引入了多头潜在注意力(MLA)。
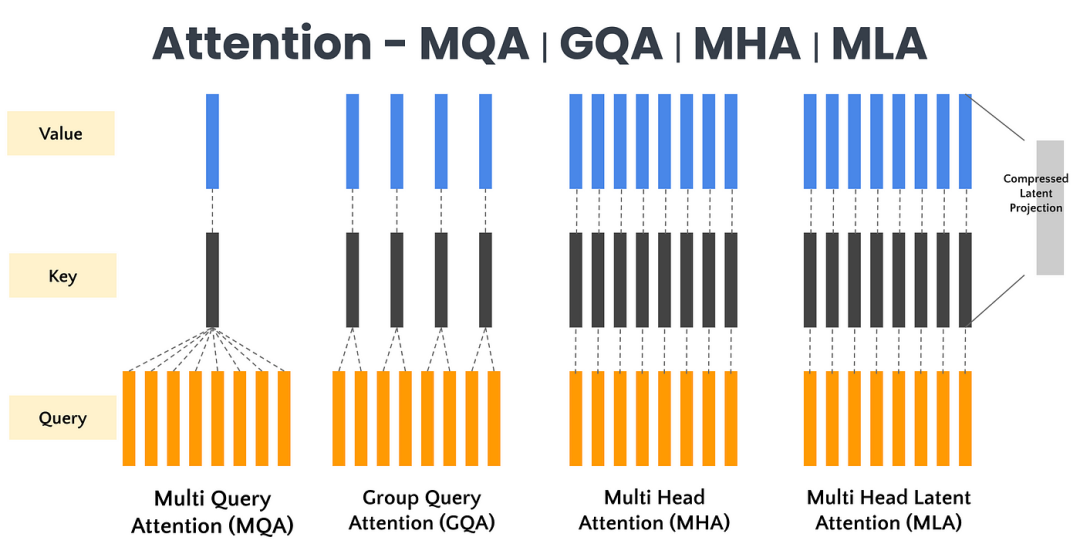
多头潜在注意力(MLA)技术创新是什么?多头潜在注意力(MLA)采用低秩联合压缩键值技术,优化了键值(KV)矩阵,显著减少了内存消耗并提高了推理效率。
-
低秩联合压缩键值:MLA通过低秩联合压缩键值(Key-Value),将它们压缩为一个潜在向量(latent vector),从而大幅减少所需的缓存容量。这种方法不仅减少了缓存的数据量,还降低了计算复杂度。
-
优化键值缓存:在推理阶段,MHA需要缓存独立的键(Key)和值(Value)矩阵,这会增加内存和计算开销。而MLA通过低秩矩阵分解技术,显著减小了存储的KV(Key-Value)的维度,从而降低了内存占用。
MLA通过“潜在向量”来表达信息,避免了传统注意力机制中的高维数据存储问题。利用低秩压缩技术,将多个查询向量对应到一组键值向量,实现KV缓存的有效压缩,使得DeepSeek的KV缓存减少了93.3%。

















 1413
1413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









