







本文内容整理主要来自知乎用户@巫婆塔里的工程师 发布的文章,建议大家去看原文(一位很有深度,专业性极强的宝藏博主,搬运的目的也是为了记录自己学习的过程,没有其他用途)侵权删。
1.前言
自动驾驶感知技术所采用的传感器主要包括摄像头、激光雷达和毫米波雷达,如何高效的融合多种传感器数据,成为了感知算法研究的热点之一。本篇文章介绍如何在感知任务中融合激光雷达和摄像头,重点是目前主流的基于深度学习的融合算法。
摄像头产生的数据是2D图像,对于物体的形状和类别的感知精度较高。深度学习技术的成功起源于计算机视觉任务,很多成功的算法也是基于对图像数据的处理,因此目前基于图像的感知技术已经相对成熟。图像数据的缺点在于受外界光照条件的影响较大,很难适用于所有的天气条件。对于单目系统来说,获取场景和物体的深度(距离)信息也比较困难。双目系统可以解决深度信息获取的问题,但是计算量很大。激光雷达在一定程度上弥补了摄像头的缺点,可以精确的感知物体的距离,但是限制在于成本较高,车规要求难以满足,因此在量产方面比较困难。同时,激光雷达生成的3D点云比较稀疏(比如垂直扫描线只有64或128)。对于远距离物体或者小物体来说,反射点的数量会非常少。
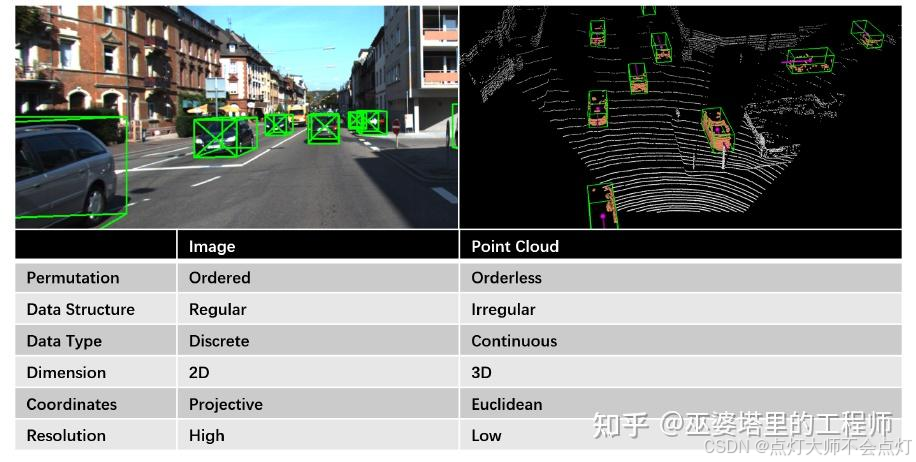
如下图所示,图像数据和点云存在着巨大的差别。首先是视角不同,图像数据是真实世界通过透视投影得到的二维表示,而三维点云则包含了真实世界欧式坐标系中的三维信息,可以投影到多种视图。其次是数据结构不同,图像数据是规则的,有序的,稠密的,而点云数据是不规则的,无序的,稀疏的。在空间分辨率方面,图像数据也比点云数据高很多。
自动驾驶感知系统中有两个典型的任务:物体检测和语义分割。深度学习技术的兴起首先来自视觉领域,基于图像数据的物体检测和语义分割已经被广泛和充分的研究, 另一方面,随着车载激光雷达的不断普及以及一些大规模数据库的发布,点云数据处理的研究这几年来发展也非常迅速。下面以物体检测任务为主来介绍不同的融合方法。语义分割的融合方法可以由物体检测扩展得到,就不做单独介绍了。
2.不同的融合策略
物体检测的策略分为:决策层融合,决策+特征层融合,以及特征层融合。在决策层融合中,图像和点云分别得到物体检测结果(BoundingBox),转换到统一坐标系后再进行合并。这种策略中用到的大都是一些传统的方法,比如IoU计算,卡尔曼滤波等,与深度学习关系不大,重点来讲讲后两种融合策略。
2.1决策+特征层融合
这种策略的主要思路是将先通过一种数据生成物体的候选框(Proposal)。如果采用图像数据,那么生成的就是2D候选框,如果采用点云数据,那么生成的就是3D候选框。然后将候选框与另外一种数据相结合来生成最终的物体检测结果(也可以再重复利用生成候选框的数据)。这个结合的过程就是将候选框和数据统一到相同的坐标系下,可以是3D点云坐标(比如F-PointNet),也可以是2D图像坐标(比如IPOD)。
F-PointNet[2]由图像数据生成2D物体候选框,然后将这些候选框投影到3D空间。每个2D候选框在3D空间对应一个视椎体(Frustum),并将落到视椎体中所有点合并起来作为该候选框的特征。视椎体中的点可能来自前景的遮挡物体或者背景物体,所以需要进行3D实例分割来去除这些干扰,只保留物体上的点,用来进行后续的物体框估计(类似PointNet中的处理方式)。这种基于视椎的方法,其缺点在于每个视椎中只能处理一个要检测的物体,这对于拥挤的场景和小目标(比如行人)来说是不能满足要求的。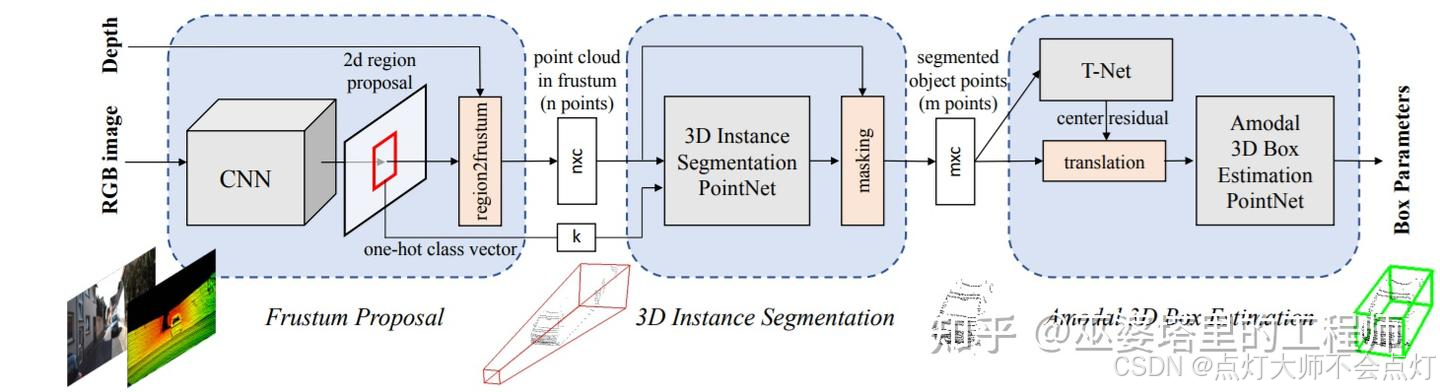
针对视椎的上述问题,IPOD[3]提出采用2D语义分割来替换2D物体检测。首先,图像上的语义分割结果被用来去除点云中的背景点,这是通过将点云投影到2D图像空间来完成的。接下来,在每个前景点处生成候选物体框,并采用NMS去除重叠的候选框,最后每帧点云大约保留500个候选框。同时,PointNet++网格被用来进行点特征提取。有了候选框和点特征,最后一步采用一个小规模的PointNet++来预测类别和准确的物体框(当然这里也可以用别的网络,比如MLP)。IPOD在语义分割的基础上生成了稠密的候选物体框,因此在含有大量物体和互相遮挡的场景中效果比较好。 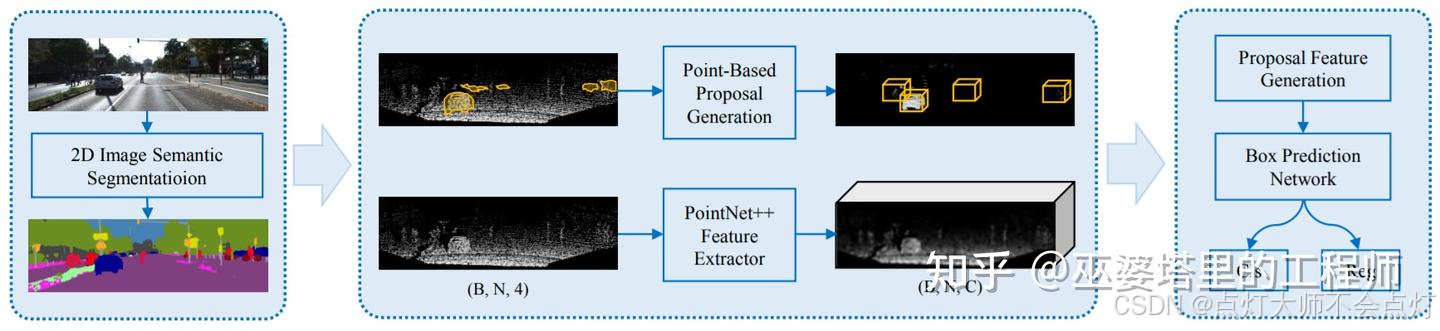
上面两个方法分别通过2D图像上的物体检测和语义分割结果来生成候选框,然后只在点云数据上进行后续的处理。SIFRNet[4]提出在视椎体上融合点云和图像特征,以增强视椎体所包含的信息量,用来进一步提高物体框预测的质量。 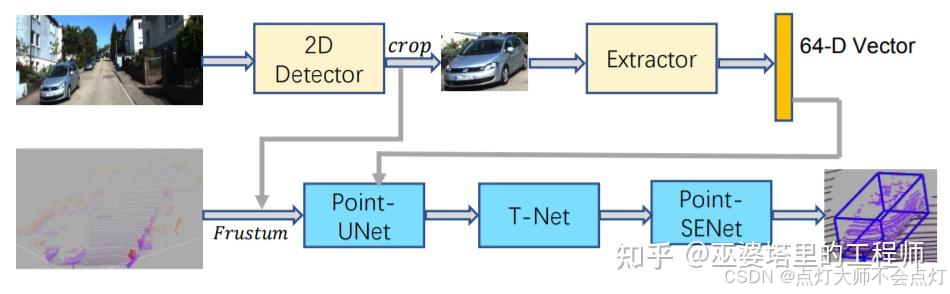
近年来,随着3D物体检测技术的快速发展,物体候选框的选取也从逐渐从2D向3D转变。MV3D[5]是基于3D候选框的代表性工作。首先,它将3D点云映射到BEV视图,并基于此视图生成3D物体候选框。然后,将这些3D候选框映射到点云的前视图以及图像视图,并将相应的特征进行融合。特征融合是以候选框为基础,并通过ROI pooling来完成的。 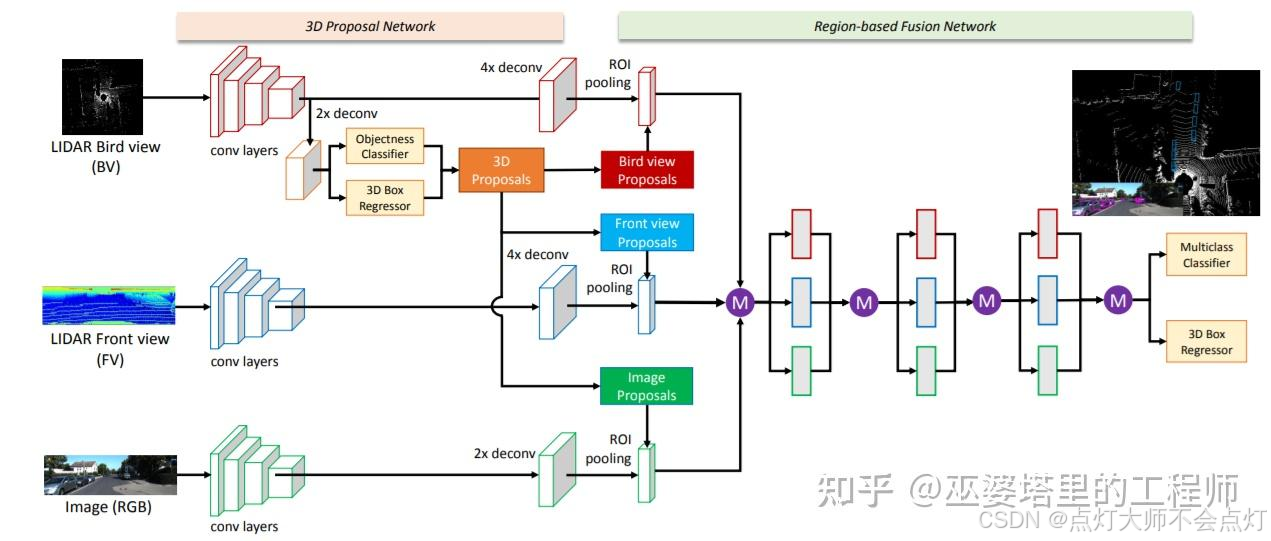
AVOD[6]的思路也是在3D候选框的基础上融合图像和点云特征。但是原始候选框的生成并不是通过点云处理得到,而是通过先验知识在BEV视图下均匀采样生成的(间隔0.5米,大小为各个物体类的均值)。点云数据用来辅助去除空的候选框,这样最终每帧数据会产生8万到10万个候选框。这些候选框通过融合的图像和点云特征进行进一步筛选后,作为最终的候选再送入第二阶段的检测器。因此,也可以认为AVOD的候选框是同时在图像和点云上得到的。 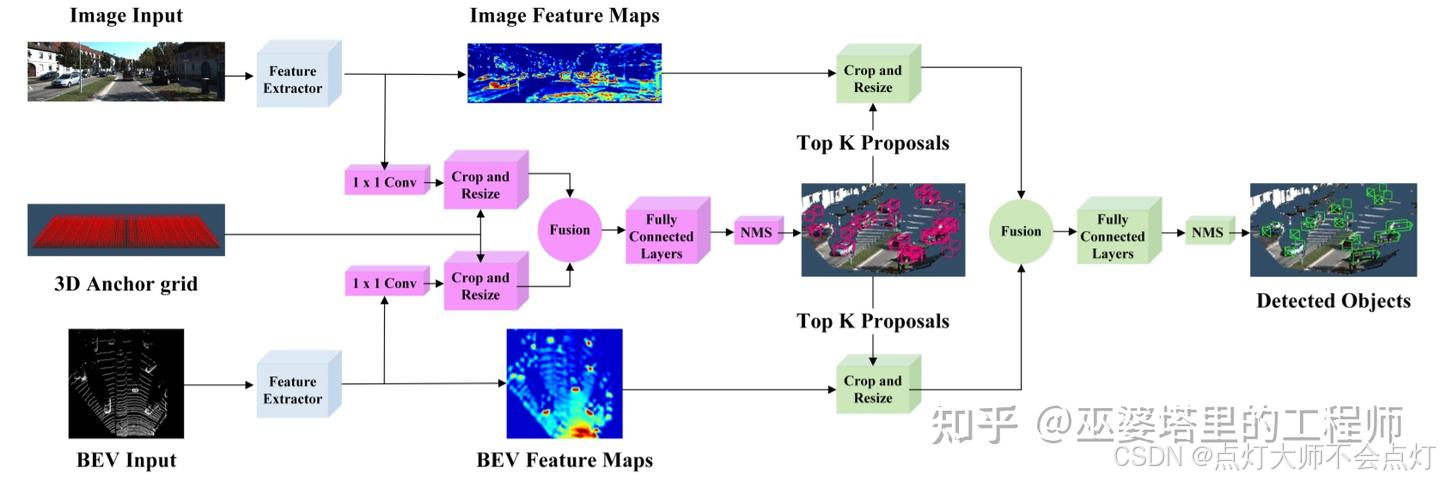
2.2特征层融合
决策+特征层融合的特点是以物体候选框为中心来融合不同的特征,融合的过程中一般会用到ROI pooling(比如双线性插值),而这个操作会导致空间细节特征的丢失。另外一种思路是特征层融合,也就是直接融合多种特征。比如说将点云映射到图像空间,作为带有深度信息的额外通道与图像的RGB通道进行合并。这种思路简单直接,对于2D物体检测来说效果不错。但是融合的过程丢失了很多3D空间信息,因此对于3D物体检测来说效果并不好。由于3D物体检测领域的迅速发展,特征层融合也更倾向于在3D坐标下完成,这样可以为3D物体检测提供更多信息。

















 5779
5779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









