






编者按: 目前,LLMs 在机器翻译、文本生成、多轮问答等任务上已表现得非常出色了。人们开始思考它们是否也可以用于数据标注工作。数据标注是训练和评估各种机器学习模型的基础,一直是一项昂贵且耗时的工作。是否能够借助 LLMs 的强大能力来为数据标注流程降本增效呢?本文深入探讨了这一问题。
本文作者从业界最新研究入手,全面评估了 LLMs 在数据标注领域的应用前景。文章指出,在某些场景下使用 LLMs 确实可以加快标注流程、降低成本,但也需要注意 LLMs 存在一些局限性,如对提示词的高度敏感性、不能支持多种人类语言符号,以及难以模拟人类的内在推理逻辑等。因此,我们不能期望 LLMs 完全取代人工标注,特别是在涉及需要主观判断或敏感内容的领域。
本文立足前沿,观点中肯,为 LLMs 在数据标注领域的应用前景勾勒出了轮廓,同时也直面了其短板,启发读者理性审视这一新兴技术在实践中的利弊权衡,为未来研究和实践提供了极有价值的思路,对于推动人工智能技术在数据标注领域的良性发展具有重要意义。
本文旨在提供一份简单易懂的技术总结,介绍有关使用 LLMs 对数据进行标注的研究。我们将探讨当前关于使用 LLMs¹ 标注文本数据的观点,以及在实践中使用该技术方案时需要注意的事项。
文章总览:
- 为什么使用 LLMs 进行数据标注?
- 当前业界主流观点
- 使用 LLMs 进行数据标注时需要注意哪些事项
- Summary | TL;DR

Source: Pexels
01
为什么使用 LLMs 进行数据标注?
高质量的标注数据是训练和评估各种机器学习模型的基础。 目前,最常见的数据标注方法是雇佣众包工人(例如 Amazon Mechanical Turk),或在涉及专业知识时雇佣相关领域专家。
这些方法可能相当昂贵且极其耗时,因此很多人开始想了解是否可以使用 LLMs 完成数据标注工作。对于预算有限的企业,可以通过构建满足其特定需求的专用数据标注模型(specialised models)来完成数据标注需求。在医学等较为敏感的领域,可以通过让相关领域专家审查和修正 LLM 的标注内容来加快标注流程,而不是从头开始进行数据标注。
此外, 卡内基梅隆大学(Carnegie Mellon) 和 谷歌(Google)的研究人员还发现,保护人工标注者免受标注过程中(例如仇恨言论)造成的心理伤害,以及保证数据中观点的多样性,也是行业推动使用 LLMs 进行数据标注的动机之一。
02
当前业界主流观点
关于 LLMs 是否有潜力成为优秀的数据标注工具,各项研究的意见不一。虽然一些研究对其能力持乐观态度,但也有一些研究持怀疑态度。表 1 概述了十二项相关研究的研究方法和研究结论。您可以在本文末尾的参考文献中找到这些内容的出处。

表 1 — z: zero-shot,f: few-shot,z&f: zero&few-shot;en+: 主要为英文语料 | 图片由原文作者提供
2.1 模型²
表 1 中的 Model Families 列元素数量显示 —— 大多数研究只测试了一个 Model Families。查看使用的具体模型可以发现,除了研究[7][11]外,几乎所有研究都使用了 GPT。研究[7]是唯一****专注于探索开源 LLMs 的研究(见表2)。
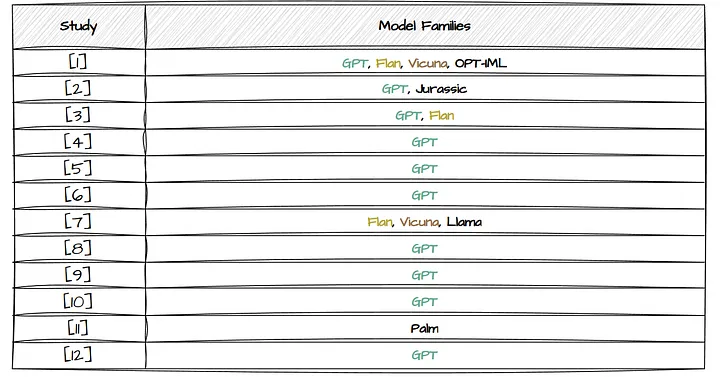
表 2 | 图片由原文作者提供
*2.2 数据集*
表 1 的 Number of Datasets 列介绍了该研究用于数据标注的数据集数量。不同的研究所探索的任务不同,因此也探索使用了不同的数据集。大多数研究在多个数据集上进行了性能测试。研究[3]通过在20个不同数据集上测试 LLM 的分类性能(LLM classification performance)而显得特别突出。关于数据集的更多细节,请在下方的表 3 中寻找,应当可以帮助您找到最相关的研究。
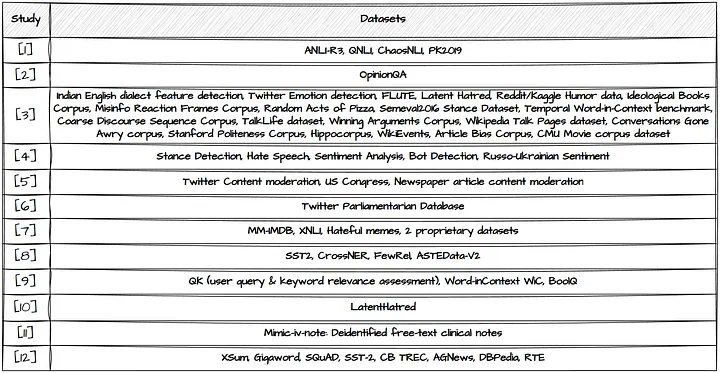
表 3 | 图片由原文作者提供
如果一开始手头没有标注数据:请寻找、查看现有的与目标任务类似的标注数据集(labelled datasets),并用 LLM 对其进行标注。通过详细分析错误和潜在问题(the errors and potential issues),将 LLM 生成的标签与人工标注的标签进行比较。这样,就能够帮助我们了解 LLM 在目标任务中的表现,以及是否值得投入时间和其他成本。
2.3 Perspectivist Approach
Perspectivist Approach 简单来说就是认识到理解数据集或解决问题(understand a dataset or solve a problem)没有一种“唯一正确”的方法。从不同的角度看问题可以带来不同的见解(insights)或解决方案(solutions)。在传统方法中,大多数数据集都是使用 majority voting approach(译者注:会让多个人(如专家或众包工人)为同一个数据样本打上标签。由于每个人的判断可能有出入,最终需要一种机制来确定这个数据样本的“ground truth”(真实标签)。在传统的数据标注过程中,这种机制通常为“少数服从多数”。)进行标注,这意味着最常被选择的标签被视为“ground truth”(真实标签):

Majority Voting Vs. Perspectivist Approach | 图片由原文作者提供
在表 1 中,根据研究采用的是 majority voting 方法还是 perspectivist mindset 方法,对数据标注方法进行了分类。可以看到,大多数研究都采用了 majority voting 方法进行数据标注工作。
2.4 真的可以将 LLMs 使用为数据标注工具?
最后一列总结了每项研究的结果,打勾☑️表示该研究倾向于认为 LLMs 可以在数据标注过程中发挥作用。虽然有些研究对其潜力非常乐观,甚至认为完全可以取代人工标注者,但也有一些研究认为它们更适合作为辅助工具,而不是完全替代人类进行数据标注。即便在这些持积极态度的研究中,也有些任务场景是 LLMs 表现不够出色的。
此外,有三项研究(其中两项采用了 perspectivist approach 方法)得出结论认为 LLMs 不适合用于数据标注。另一项研究(未在表中记录)采用了不同的方法,表明目前通过单一奖励函数(single reward function)对 LLMs 进行对齐的方法,并不能反映不同人类子群体(human subgroups)的偏好多样性(diversity of preferences),特别是少数群体的观点。
03
使用 LLMs 作为标注工具时需要考虑的事项
3.1 Prompting: Zero vs. Few-shot
直接从 LLMs 中获得非常有意义的模型响应可能颇具挑战。那么,**如何最有效地通过提示词让 LLM 来标注数据集呢?**从表 1 中我们可以看到,上述研究探讨了 zero-shot 或 few-shot prompting (译者注:Zero-shot prompting 不向语言模型提供任何相关示例,直接向模型发送自然语言的问题或指令,让模型自行生成答案或执行任务。没有提供任何“示例”说明预期的输出应该是什么样的。Few-shot prompting 在prompt中包含了少量的“示例”内容,告诉大模型用户期望的输出格式和风格是什么样的。),或两者兼而有之。Zero-shot prompting 要求 LLM 在没有任何示例的情况下回答问题。而 Few-shot prompting 则在提示词中包含多个示例,以便 LLM 能理解用户期望的回答格式:

Zero Vs Few-Shot Prompting | source:https://github.com/amitsangani/Llama-2/blob/main/Building_Using_Llama.ipynb
至于哪种方法效果更好,研究结果各不相同。一些研究在解决目标任务时采用 few-shot prompting,另一些则采用 zero-shot prompting 。因此,我们可能需要探索哪种方法最适合我们的任务场景和使用的模型。
如果你想知道如何学习撰写提示词(Prompt),Sander Schulhoff 和 Shyamal H Anadkat 创建了 LearnPrompting[1],可以帮助我们学习有关提示词的基础知识和更高级的技巧。
3.2 LLMs 对提示词的敏感程度
LLMs 对 prompt(提示词)的细微变化非常敏感。 改变 prompt 中的一个词可能就会影响模型响应。如果想要尽量应对这种变化,可以参考研究[3]的做法。首先,由 task expert (译者注:对任务所在领域有深入理解的领域专家。)提供初始提示词。然后,使用 GPT 生成 4 个意义相似的提示词,并对这 5 个提示词的模型响应的内容评估指标取平均值。或者,我们也可以尝试使用 signature[2] (译者注:一种自动化的提示词生成方式,可以理解为一种参数化的提示词模板。)代替人工输入的提示词,并让 DSPy[3] 来优化提示词,如 Leonie Monigatti 的博客文章内容[4]所示。
3.3 如何选择用于数据标注的模型?
选择哪个模型来标注数据集?有几个因素需要考虑。让我们简要谈谈一些关键的考虑因素:
- 开源 vs. 闭源:是选择最新的、性能最好的模型?还是更注重定制化开源模型?需要考虑的因素包括预算、性能要求、是否需要定制、是否需要拥有模型所有权、安全需求以及社区支持要求等方面。
- 保护措施(Guardrails):LLMs 配备了防止产生不良信息或有害内容的保护措施。**如果目标任务涉及敏感内容,模型可能会拒绝标注这些数据。**而且,不同 LLMs 的保护措施强度不一,因此需要不断进行探索和比较,找到最适合目标任务的数据标注模型。
- 模型大小(Model Size):LLMs 有不同的 size ,较大的模型可能表现更好,但也需要更多的计算资源。如果你想要使用开源 LLMs 但是计算资源有限,可以试试使用模型量化技术[5]。就闭源模型而言,目前较大的模型每次使用的成本更高。但较大 size 的模型一定更好吗?
3.4 模型存在的偏见问题
根据研究[3],较大的、经过指令微调的³(instruction-tuned)模型在数据标注性能方面表现更优越。 然而,该研究并未评估其模型输出中是否存在偏见。另一项研究表明,偏见会随着模型规模(scale)和上下文模糊程度(ambiguous contexts)的增加而增加。 有几项研究还警告说,LLMs 有左倾倾向,并且在准确代表少数群体(如老年人或少数宗教)的观点方面能力有限。总体来看,当前的 LLMs 存在相当大的文化偏见(cultural biases),并且在看待少数群体的相关问题时存在刻板印象。这些都是在项目各个阶段需要根据目标任务考虑的问题。

“默认情况下,LLM 的响应更类似于某些群体的观点,如来自美国、某些欧洲和南美洲国家的群体” — 摘自研究[2]
3.5 模型参数:Temperature
表 1 中的大多数研究都提到了 temperature 参数,该参数主要用于调整 LLMs 输出内容的“创造力”表现。研究[5]和[6]在较高和较低的 temperature 参数值下进行了实验,发现使用较低的 temperature 参数值时 LLMs 响应的一致性更高(译者注:对于同一提示词输入,模型在不同时刻生成的响应彼此之间的差异较小,更加一致),同时不影响准确性。因此,他们建议在数据标注任务中使用较低的 temperature 参数值。
3.6 使用 LLMs 进行数据标注任务存在语言方面的限制
如表 1 所示,大多数研究都评估了 LLMs 在英语数据集上的标注性能。**研究[7]探索了法语、荷兰语和英语数据集的性能,发现非英语语言的标注性能显著下降。**目前,LLMs 在英语数据集中的表现更好,但也有其他方法尝试将这种优势扩展到非英语语言。包括 Aleksa Gordić 开发的 YugoGPT[6](用于塞尔维亚语、克罗地亚语、波斯尼亚语、黑山语)和 Cohere for AI 的 Aya[7](支持101种不同语言)。
3.7 分析人类的标注内容,来窥探和理解人类在做出某些判断时的内在推理逻辑和行为动机
除了简单地请求 LLM 为数据打上标签外,我们还可以要求其为所选择的标签提供一段解释。**研究[10]发现,GPT 提供的解释内容与人类的解释内容相当,甚至更为清晰。**然而,卡内基梅隆大学和谷歌的研究人员指出,LLMs 尚未能模拟人类的决策过程[8],在标签的选择决策过程中也未表现出类似人类的行为[9]。他们发现,经过指令微调的模型更无法表现出类似人类的行为,因此他们认为在标注流程中, 不应当使用 LLMs 来替代人类。在目前的阶段,作者建议谨慎使用大语言模型(LLM)生成的自然语言解释内容。
“使用 LLMs 替代标注员会影响三种价值观:参与者利益的代表性(译者注:如果完全由 LLM 生成自然语言解释内容,可能无法充分代表参与标注任务的人员(如专家、工人等)的真实利益和关切点。);人类在开发过程中的参与权、发言权、主导权和决策权。” — 摘自 Agnew(2023)
04
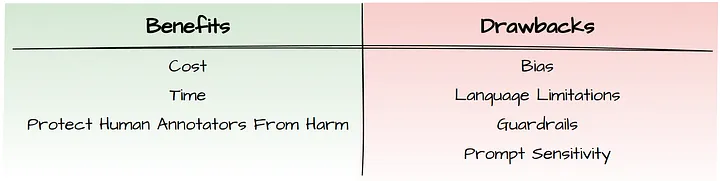
Summary | TL;DR
使用 LLMs 进行数据标注优点与缺点 | image by author
- 对于那些预算有限、任务相对客观的情况,使用 LLM 进行数据标注是一个不错的选择,在这些任务中,一般关注的是最可能的标签。 在意见可能存在较大分歧的主观任务中,对正确标签(correct label)的看法可能会大相径庭,这时就要小心了!
- 避免使用 LLMs 来模拟人类的内在推理逻辑和行为动机。
- 对于更关键的任务(如医疗保健领域任务),可以使用 LLMs 来加速标注过程,让人类来纠正已标注的数据;但千万不要让人类完全脱离数据标注过程!
- 批判性地评估标注方案,检查是否存在偏见和其他问题,并考虑这些错误可能带来的麻烦是否值得。
这篇文章并非对使用 LLMs 和人工标注进行详尽的比较。如果您有其他资料或在使用 LLM 进行数据标注的个人经验,烦请在评论中留言分享。
References
- 由于参考资料较多,此链接单独列出了用于撰写这篇博客文章所参考的所有论文:https://towardsdatascience.com/can-large-language-models-llms-label-data-2a8334e70fb8#1525
- 如果您想了解表 1 和这些研究的更多信息,请参阅此论文:https://arxiv.org/abs/2405.01299
脚注 Footnotes
¹这不是对所有相关文献的全面回顾,仅涵盖了我在研究这一主题时发现的论文。此外,我主要关注的还是分类任务(classification tasks)。
²鉴于 LLM 的发展速度,与本文介绍的这些研究中测试的模型相比,现在肯定还有很多更强大的模型可用于数据标注。
³经过指令微调过的大模型(Instruction-tuned models)的训练重点是根据给定的指令/提示词(instructions/prompts)理解和生成准确且连贯的模型响应。
Thanks for reading!
Maja Pavlovic
Google DeepMind PhD Scholar, simplifying Data Science and Deep Learning concepts || London (UK) ||
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
本文转自 https://blog.csdn.net/python122_/article/details/141253617,如有侵权,请联系删除。















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









