






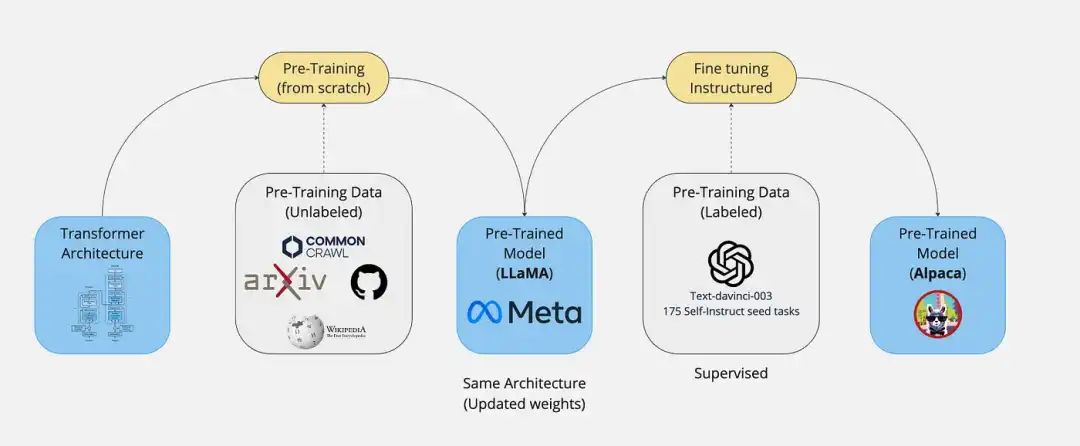
Pre-training vs Fine-tuning
预训练(Pre-training)是预先在大量数据上训练模型以学习通用特征,而微调(Fine-tuning)是在特定任务的小数据集上微调预训练模型以优化性能。

Pre-training vs Fine-tuning
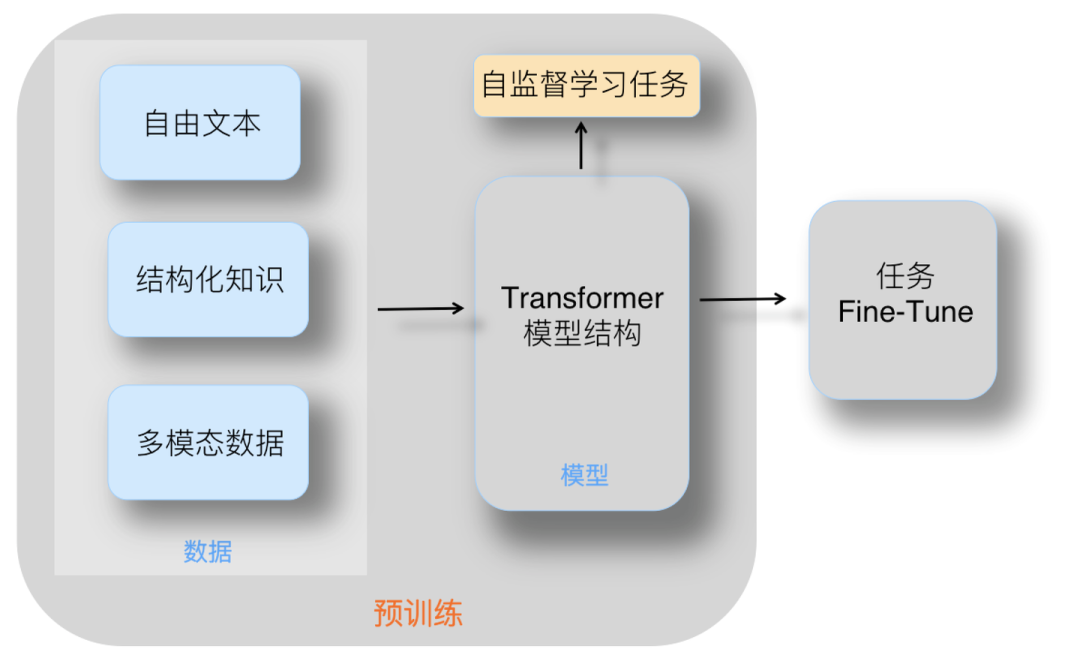
一、预训练(Pre-training)****
**为什么需要预训练?**预训练是为了让模型在见到特定任务数据之前,先通过学习大量通用数据来捕获广泛有用的特征,从而提升模型在目标任务上的表现和泛化能力。
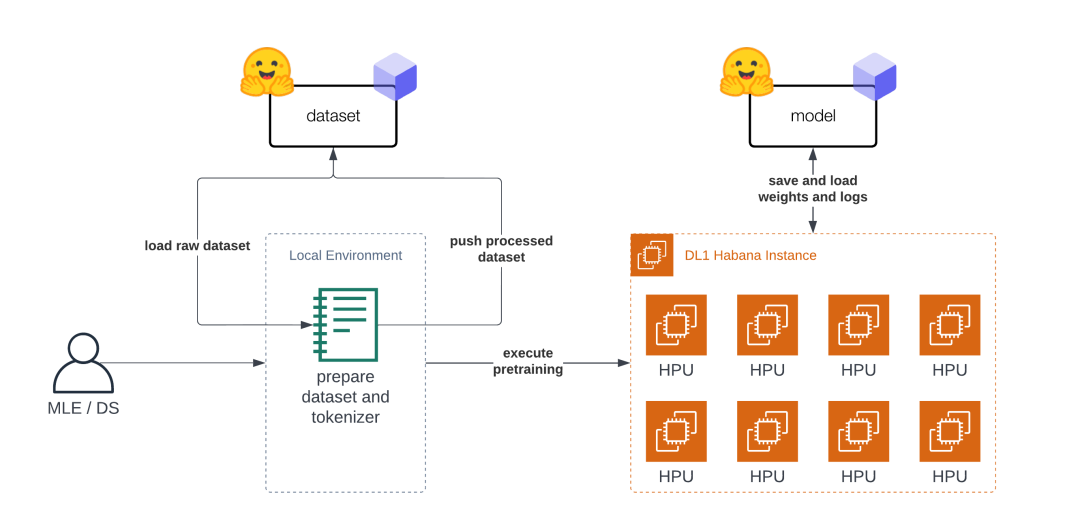
Pre-training
预训练技术通过从大规模未标记数据中学习通用特征和先验知识,减少对标记数据的依赖,加速并优化在有限数据集上的模型训练。
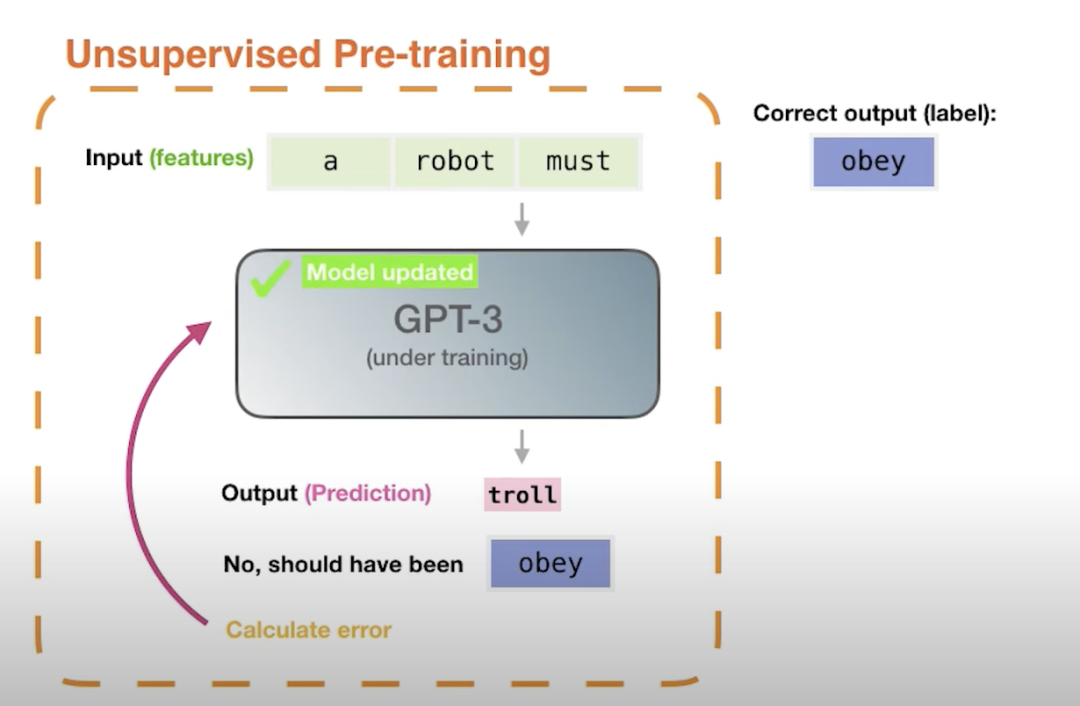
Pre-training
-
数据稀缺性:**在现实世界的应用中,收集并标注大量数据往往是一项既耗时又昂贵的任务。**特别是在某些专业领域,如医学图像识别或特定领域的文本分类,标记数据的获取更是困难重重。**预训练技术使得模型能够从未标记的大规模数据中学习通用特征,从而减少对标记数据的依赖。**这使得在有限的数据集上也能训练出性能良好的模型。
-
先验知识问题:在深度学习中,模型通常从随机初始化的参数开始学习。**然而,对于许多任务来说,具备一些基本的先验知识或常识会更有帮助。****预训练模型通过在大规模数据集上进行训练,已经学习到了许多有用的先验知识,如语言的语法规则、视觉的底层特征等。**这些先验知识为模型在新任务上的学习提供了有力的支撑。
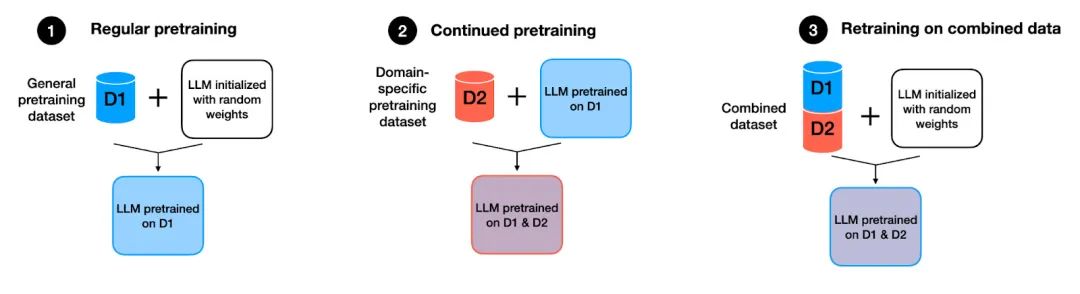
Pre-training
预训练的技术原理是什么?预训练利用大量无标签或弱标签的数据,通过某种算法模型进行训练,得到一个初步具备通用知识或能力的模型******。**********

Pre-training
********预训练是语言模型学习的初始阶段。**************在预训练期间,模型会接触大量未标记的文本数据,例如书籍、文章和网站。******目标是捕获文本语料库中存在的底层模式、结构和语义知识。
-
****无监督学习:****预训练通常是一个无监督学习过程,模型在没有明确指导或标签的情况下从未标记的文本数据中学习。
-
******屏蔽语言建模:******模型经过训练可以预测句子中缺失或屏蔽的单词、学习上下文关系并捕获语言模式。
-
******Transformer 架构:******预训练通常采用基于 Transformer 的架构,该架构擅长捕获远程依赖关系和上下文信息。
Pre-training
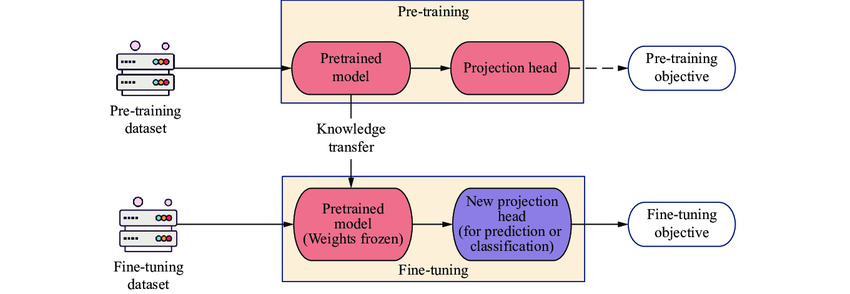
二、微调(Fine-tuning)
****为什么需要微调?******尽管预训练模型已经在大规模数据集上学到了丰富的通用特征和先验知识,但这些特征和知识可能并不完全适用于特定的目标任务。**微调通过在新任务的少量标注数据上进一步训练预训练模型,使模型能够学习到与目标任务相关的特定特征和规律,从而更好地适应新任务。

Fine-tuning
模型微调可以更好地利用预训练模型的知识,加速和优化新任务的训练过程,同时减少对新数据的需求和降低训练成本。
-
**减少对新数据的需求:****从头开始训练一个大型神经网络通常需要大量的数据和计算资源,而在实际应用中,我们可能只有有限的数据集。**通过微调预训练模型,我们可以利用预训练模型已经学到的知识,减少对新数据的需求,从而在小数据集上获得更好的性能。
-
**降低训练成本:**由于我们只需要调整预训练模型的部分参数,而不是从头开始训练整个模型,因此可以大大减少训练时间和所需的计算资源。这使得微调成为一种高效且经济的解决方案,尤其适用于资源有限的环境。
Fine-tuning
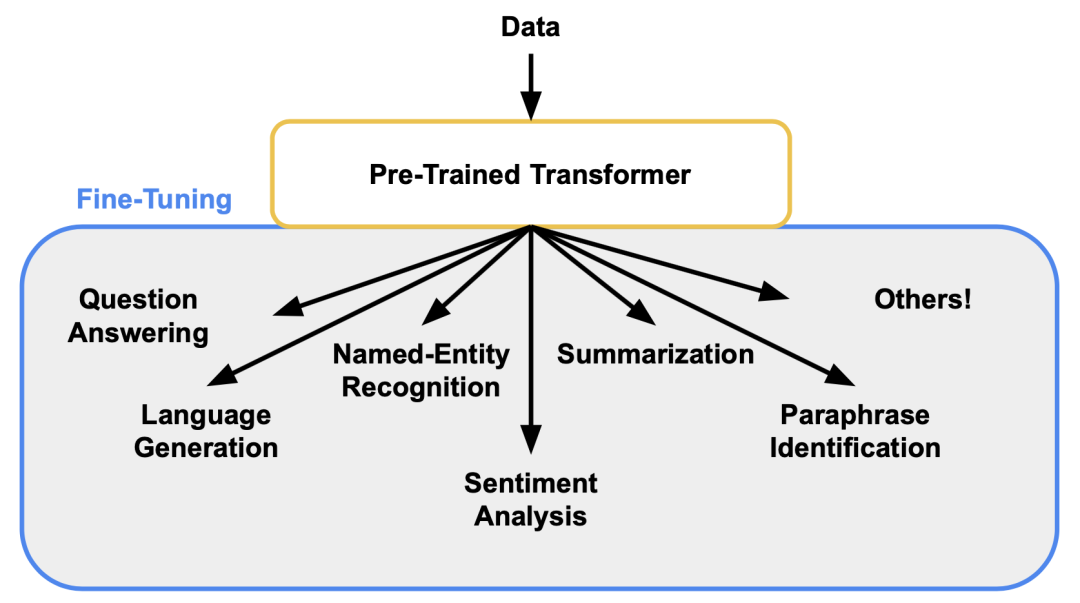
微调的技术原理是什么?在预训练模型的基础上,针对特定任务或数据领域,通过在新任务的小规模标注数据集上进一步训练和调整模型的部分或全部参数,使模型能够更好地适应新任务,提高在新任务上的性能。
Fine-tuning
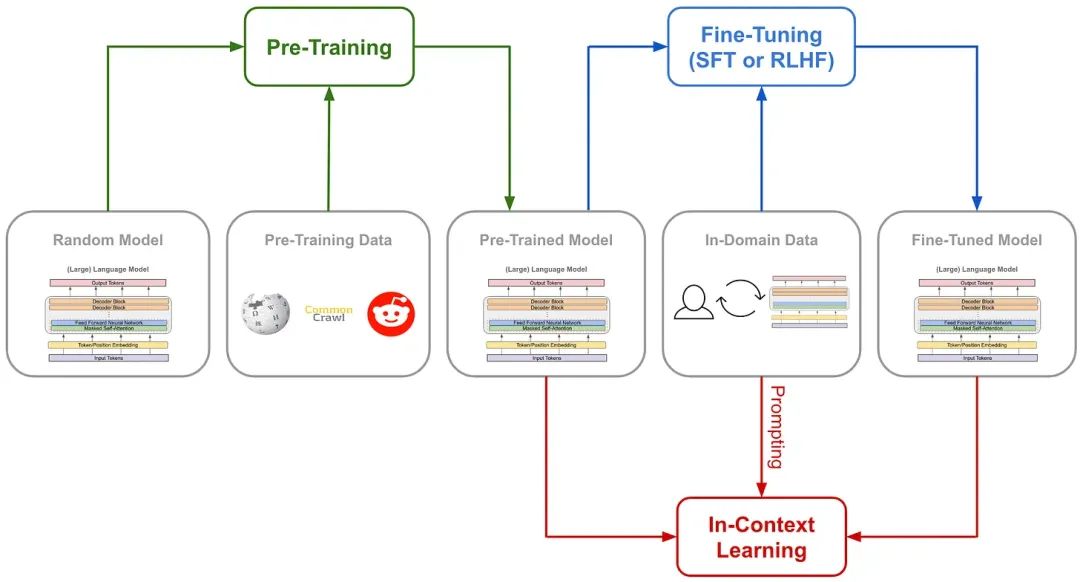
**********微调如何分类?**********微调分为在新任务数据集上全面或基于人类反馈的监督训练(SFT与RLHF),以及调整模型全部或部分参数以高效适应新任务(Full Fine-tuning与PEFT)。
1. 在新任务的小规模标注数据集上进一步训练
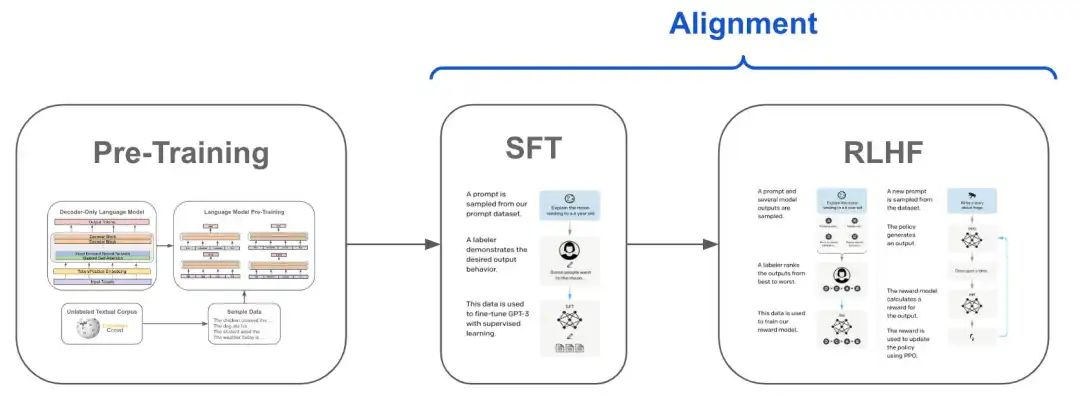
**这种方式通常使用预训练模型作为基础,并在新任务的小规模标注数据集上进行进一步的训练。这种训练过程可以根据具体的训练方法和目标细分为不同的策略,**如监督微调(Supervised Fine-tuning, SFT)和基于人类反馈的强化学习微调(Reinforcement Learning with Human Feedback, RLHF)。
SFT or RLHF
-
**定义:**在新任务的小规模标注数据集上,使用有监督学习的方法对预训练模型进行微调,以使其适应新任务。
-
**步骤:**加载预训练模型 → 准备新任务的数据集 → 调整模型输出层 → 在新任务数据集上训练模型。
-
**应用:**适用于那些有明确标注数据集的任务,如文本分类、命名实体识别等。
-
**定义:**在SFT的基础上,通过强化学习和人类反馈来进一步微调模型,使其输出更加符合人类的偏好或期望。
-
**步骤:**首先进行SFT → 收集人类反馈数据 → 训练奖励模型 → 使用奖励模型指导强化学习过程来微调模型。
-
应用:适用于那些需要高度人类判断或创造力的任务,如对话生成、文本摘要等。
SFT or RLHF
2. 调整模型的部分或全部参数
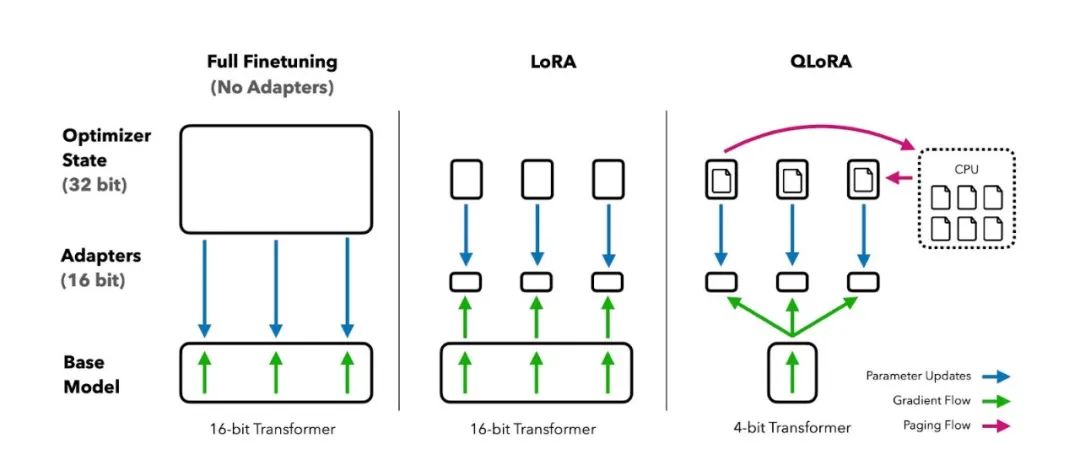
这种方式更加关注于模型参数层面的调整,根据是否调整全部参数,可以细分为全面微调(Full Fine-tuning)和部分/参数高效微调(Parameter-Efficient Fine-tuning, PEFT)。
Full Fine-tuning or PEFT
-
定义:在新任务上调整模型的全部参数,以使其完全适应新任务。
-
步骤:加载预训练模型 → 在新任务数据集上训练模型,调整所有参数。
-
应用:当新任务与预训练任务差异较大,或者想要充分利用新任务数据集时,可以选择全面微调。
-
**定义:**仅调整模型的部分参数,如添加一些可训练的适配器(adapters)、前缀(prefixes)或微调少量的参数,以保持模型大部分参数不变的同时,实现对新任务的适应。
-
**步骤:**加载预训练模型 → 在模型中添加可训练的组件或选择部分参数 → 在新任务数据集上训练这些组件或参数。
-
应用:当计算资源有限,或者想要快速适应新任务而不影响模型在其他任务上的性能时,PEFT是一个很好的选择。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









