






在面对特定领域知识时,LLM 有时会出现“幻觉”,容易胡编乱造。尤其是当针对企业或用户的私有数据(如产品使用文档、财务报告)提出一些复杂问题时,通用模型往往难以满足我们的需求。为了解决这个问题,RAG(Retrieval-Augmented Generation)技术应运而生,它可以从外部知识库中实时检索信息,辅助回答。然而,在回答一些内部文档中没有直接提及的问题时,RAG系统往往无法给出准确地答案。为解决这个痛点,本文将引入 LangChain ReAct Agents ,构建一个RAG问答系统,来处理需要进行多步推理分析的问题。
LangChain ReAct Agents
LangChain ReAct Agents 是基于 LangChain 框架实现的一种智能代理(Agent),它采用了 ReAct(Reasoning + Acting,推理与行动)框架。ReAct 是一种提示词技术,最初在论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出,旨在通过结合语言模型的推理能力和行动能力,提升其在复杂任务中的表现。
ReAct 的核心思想是让大型语言模型(LLM)通过一系列“思考-行动-观察”(Thought-Action-Observation)的循环来解决问题,而不是一次性直接生成最终答案。具体来说:
-
Thought(思考):模型分析问题,决定下一步该做什么。
-
Action(行动):根据思考结果选择并执行一个动作(比如调用外部工具、搜索信息等)。
-
Observation(观察):获取行动的结果并反馈给模型,用于下一步推理。
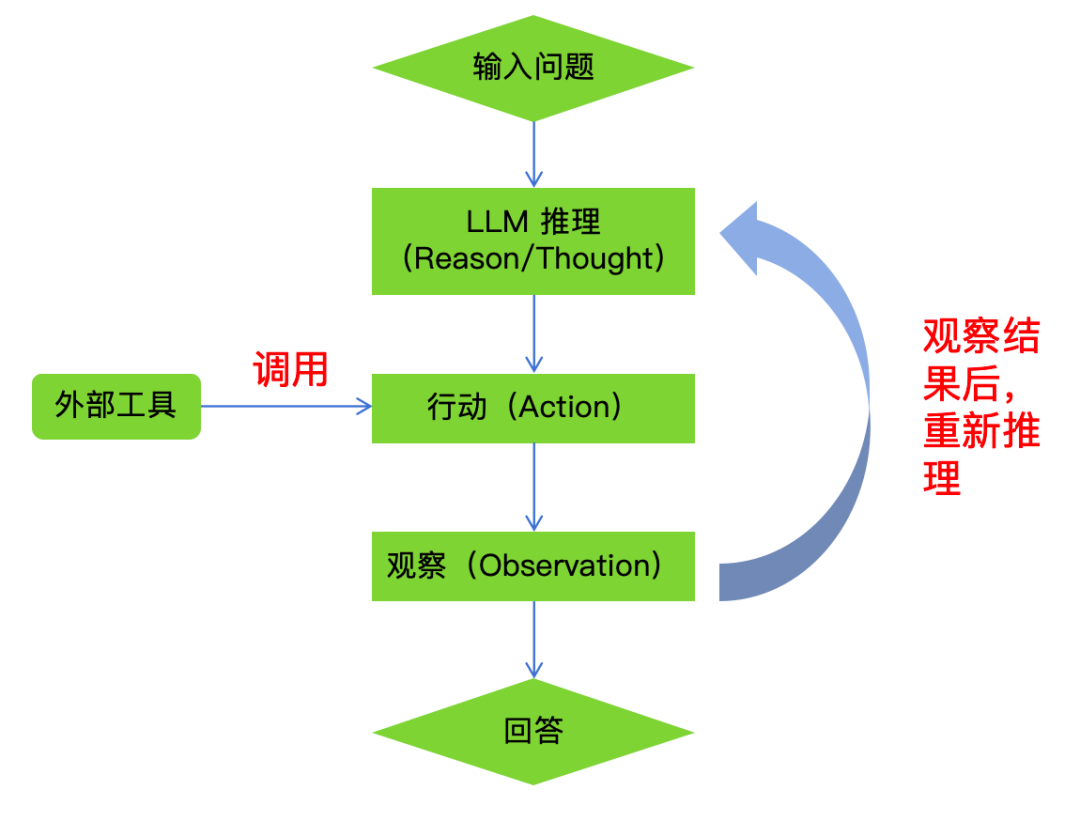
LangChain ReAct Agents工作流程
这种方法模仿了人类解决问题的过程,通过逐步推理和与外部环境的交互,减少幻觉并提高答案的准确性。
RAG
RAG(Retrieval-Augmented Generation)就是“检索增强生成”技术,它的作用可以简单理解为:让大模型具备‘查资料’的能力。在生成回答前,先去指定的外部知识库或数据库里检索到相关内容,把检索到的信息和问题一起输入给大模型,让它基于这些“新查到的资料”来生成答案。
搭建环境
本文需要用到的核心组件如下:
-
Qdrant:向量搜索引擎和数据库,可以存储文本的嵌入向量(embeddings),以实现快速的相似性搜索。
-
LangChain:提供了工具来处理文本、创建 Agent,并集成外部数据源。
-
ChatGroq: Groq 开发的一个 API 接口,用于调用语言模型。
项目结构
本文的数据集存放在Data文件夹中,我使用了2个文件,ChatGPT.txt 文件介绍了该产品,Google.txt 文件则主要介绍谷歌的用户条款,你可以其替换为任意文件。所有代码均在app.ipynb文件中书写。
项目结构
实现过程
-
导入第三方库
import os
from langchain_community.vectorstores import Qdrant
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain.agents import Tool
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_groq import ChatGroq
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
GROQ_API_KEY = "" # 替换为自己的key
2. 切分文件内容
directory_path = "Data"
txt_files = [file for file in os.listdir(directory_path) if file.endswith('.txt')]
all_documents = {}
for txt_file in txt_files:
loader = TextLoader(os.path.join(directory_path, txt_file))
documents = loader.load()
# 定义文本切分器:
# - 每段 chunk 最大 1200 个字符
# - chunk 之间有 100 个字符的重叠,避免语义割裂
text_splitter = CharacterTextSplitter(chunk_size=1200, chunk_overlap=100, separator="\n")
docs = text_splitter.split_documents(documents)
for doc in docs:
doc.metadata["source"] = txt_file
all_documents[txt_file] = docs
这段代码的作用就是:将源数据按固定大小切分成小块 ,每块记录来源文件名 ,存入一个字典,方便后续做搜索、向量化、知识库等处理。最终的 all_documents 结构类似于:
{
"a.txt": [doc1, doc2, doc3, ...],
"b.txt": [doc4, doc5, doc6, ...],
}
每个 doc 对象大概长这样:
{
"content": "具体文本内容...",
"metadata": {
"source": "a.txt"
}
}
3. 引入文本向量模型
from langchain_huggingface import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-mpnet-base-v2"
)
sentence-transformers/all-mpnet-base-v2 是 HuggingFace 上一个非常流行的文本向量模型。它可以把一段文本转换为一个向量,这个向量可以表示文本的语义特征。例如:
text1 = "你好吗?"
text2 = "最近怎么样?"
vec1 = embeddings.embed_query(text1)
vec2 = embeddings.embed_query(text2)
vec1 和 vec2 就是两个向量,通过计算它们的相似度,可以知道这两个文本的语义是否接近。
4. 将文本存入向量数据库
qdrant_collections = {}
for txt_file in txt_files:
qdrant_collections[txt_file] = Qdrant.from_documents(
all_documents[txt_file], # 需要存入的文档内容
embeddings, # 使用的文本 embedding 模型
location=":memory:", # 存储到内存中
collection_name=txt_file,
)
把之前切好的文本存储到 Qdrant 向量数据库中。每个 txt 文件对应一个独立的 collection(类似于一个表),存储在内存中(:memory:),方便后续做向量检索(相似度搜索)。
5. 创建 retriever 检索器
retriever = {}
for txt_file in txt_files:
retriever[txt_file] = qdrant_collections[txt_file].as_retriever()
检索器的作用就是:输入一个问题,返回和问题最相似的内容片段。
6. 为ReAct Agents创建工具
(1)根据输入的文档名,检索相应的文档内容
def get_relevant_document(name : str) -> str:
# 模糊匹配输入的 name
search_name = name
# 使用 fuzzywuzzy 进行模糊查找,找到最接近的 txt 文件
best_match = process.extractOne(search_name, txt_files, scorer=fuzz.ratio)
# 拿到第一个文件名
selected_file = best_match[0]
# 根据文件名获取对应的 retriever(检索器)
selected_retriever = retriever[selected_file]
global query # 获取要查的问题
# 使用向量检索器查找相关文档块
results = selected_retriever.get_relevant_documents(query)
global retrieved_text
total_content = "\n\n以下是相似度最高的内容: \n\n"
chunk_count = 0
for result in results:
chunk_count += 1
if chunk_count > 4:
break
total_content += result.page_content + "\n"
retrieved_text = total_content
return total_content
(2)对检索到的内容做摘要
def get_summarized_text(name : str) -> str:
from transformers import pipeline
summarizer = pipeline("summarization", model="Falconsai/text_summarization")
global retrieved_text
article = retrieved_text
return summarizer(article, max_length=1000, min_length=30, do_sample=False)[0]['summary_text']
(3)定义工具
get_relevant_document_tool = Tool(
name="Get Relevant document",
func=get_relevant_document,
description="Useful for getting relevant document that we need."
)
get_summarized_text_tool = Tool(
name="Get Summarized Text",
func=get_summarized_text,
description="Useful for getting summarized text for any document."
)
最终这些 Tool 可以直接集成到 LangChain 的 Agent 里,自动根据问题决定调用哪个工具,自动完成多步骤的知识问答流程。
7. 引入ReAct 提示词模板
prompt_react = hub.pull("hwchase17/react")
prompt_react.template = prompt_react.template + "\n请用中文回答最终答案。"
ReAct Prompt 是 LangChain 官方设计的一种标准 Prompt 格式,里面定义了工具调用的规则、思考的方式等。
8. 创建ReAct Agent
retrieved_text = ""
tools = [get_relevant_document_tool, get_summarized_text_tool]
model = ChatGroq(model_name="llama3-70b-8192", groq_api_key=GROQ_API_KEY, temperature=0)
react_agent = create_react_agent(model, tools=tools, prompt=prompt_react)
react_agent_executor = AgentExecutor(
agent=react_agent, tools=tools, verbose=True, handle_parsing_errors=True
)
构建了个基于 LangChain 的 ReAct Agent,结合多个 Tool(工具),并用 llama3 大模型做推理。 该 Agent 能自动根据问题调用不同工具(如检索知识、总结内容),回答问题。
功能测试
query = "给我总结一下Google为用户提供了哪些资源,用于帮助和指导用户使用其服务?"
react_agent_executor.invoke({"input": query})
该系统的推理过程如下:
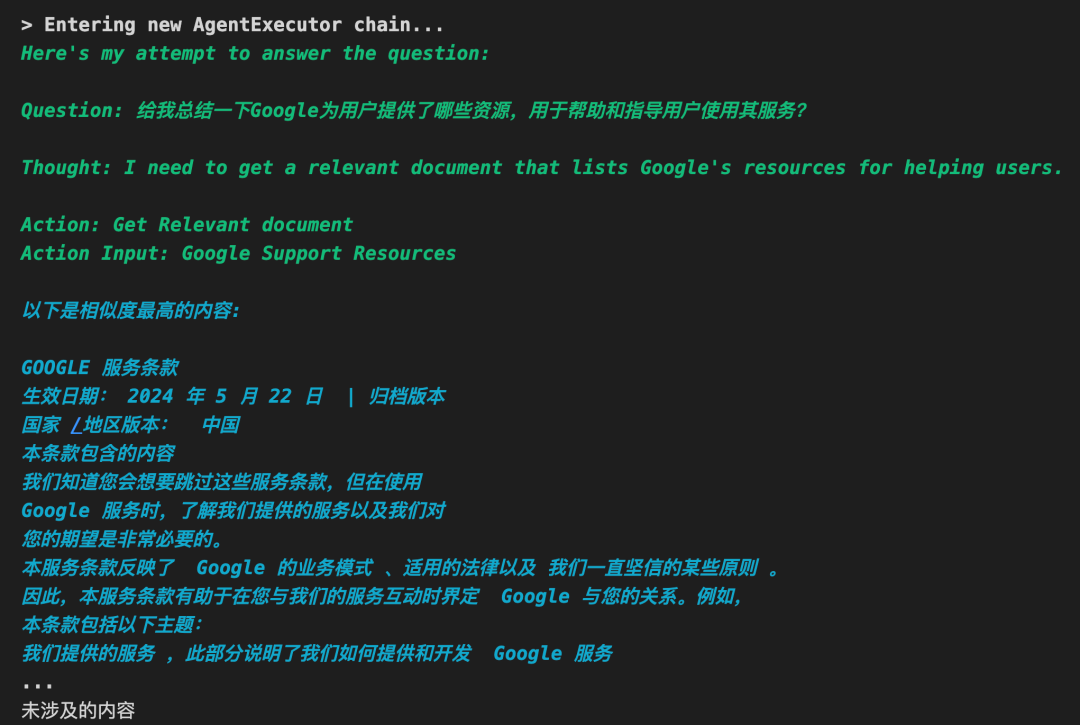
思考过程1
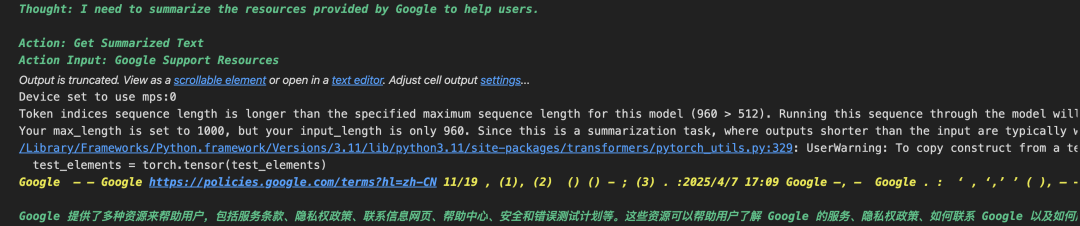
思考过程2
由上图可知,系统在收到提问后,进行了2轮“思考-行动-观察”的过程。
1. 第1轮:
-
思考:自己应该获取一份关于谷歌的相关文档,以帮助用户;
-
行动:调用对应工具 get_relevant_document_tool;
-
观察:获取到了对应文档中相似度最高的内容。
2. 第2轮:
-
思考:自己应该总结下获取的谷歌文档,以帮助用户;
-
行动:调用对应工具 get_summarized_text_tool;
-
观察:获得了最终答案。
结果如下:
{'input': '给我总结一下Google为用户提供了哪些资源,用于帮助和指导用户使用其服务?',
'output': 'Google 提供了多种资源来帮助用户,包括服务条款、隐私权政策、联系信息网页、帮助中心、安全和错误测试计划等。这些资源可以帮助用户了解 Google 的服务、隐私权政策、如何联系 Google 以及如何解决问题等信息。'}
总结
基于 LangChain ReAct Agents 和 Qdrant,我们构建了一个功能强大的 RAG 系统。这种方法不仅可以检索私有文档的信息,还能通过多步推理来获取文档中没有直接提及的内容,从而提升 LLM 的回答质量。本文使用的LLM、向量数据库等工具仅供参考,你可以根据自己的业务需求,选择合适的工具。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









