







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
x
1
,
x
2
,
⋯
,
x
N
}
\left{x^{1}, x^{2}, \cdots, x^{N}\right}
{x1,x2,⋯,xN}和一组异常的数据
{
x
~
1
,
x
~
2
,
⋯
,
x
~
N
}
\left{\tilde{x}^{1}, \tilde{x}^{2}, \cdots, \tilde{x}^{N}\right}
{x1,x2,⋯,x~N},一起训练一个二分类的分类器。但是有个问题是异常数据并不是一种类型,无法视为一个class,只要是非正常的都是异常,如下图所示。而且实际中的异常数据也是小概率事件的,比如网络攻击,比如诈骗交易,会有正负样本不均匀的情况:

给定训练数据,并且带有某种类型的label
{
y
^
1
,
y
^
2
,
⋯
,
y
^
N
}
\left{\hat{y}^{1}, \hat{y}^{2}, \cdots, \hat{y}^{N}\right}
{y1,y2,⋯,y^N},使用这些数据先训练一个classifier。数据和label中并没有unknown,但是期望classifier在遇到一个未知数据时能给出unknown的判定。也被称为Open-set Recognition。
还有一种是训练数据是没有标签的,通过相似度来判断异常数据。这里面又分两种情况,一种是训练数据是clean,一种是polluted。

2 With Classifier
2.1 Base Method
给定一组Simpsons家族人物的数据,判断
x
x
x是否来自该家族:

而且这些数据都是有label的,可以训练一个Simpsons的家族分类器,输入人物图片,可以输出名字:

有了Classifier之后,期望使用这个来做异常侦测。输入一个人物,判断其是否属于Simpsons家庭。做法是输入
x
x
x之后,输出
y
y
y的同时输出一个信心分数
c
c
c,通过和设置的阈值
λ
\lambda
λ进行比较来判断是否异常,小于则是异常:

development set:用于训练过程中,指导调整超参数的样本集,使用起来类似于测试集。这个数据集中有labelled正常数据和异常数据。计算模型在这个数据集上的效果,来调整阈值lamda和其他超参数。

具体举例如下。当输出概率比较集中,最高的分数比较高的时候就是正常;概率比较平均,最高分数比较低就是异常:

也可以使用熵值或者其他方式来描述。
老师做了实验,结果也可以得到验证:

只是机器常常会把异常图片辨别为“柯阿三”这个人物,因为这个人物本身就和其他正常数据差距略大:

2.2 Evaluation
那么怎么评估模型的好坏呢? 给定100张正常simpsons家族图片和5张其他动漫图片,得到了以下结果。蓝色表示simpsons家族的得分,红色表示其他动漫的得分。因为样本不均衡的原因,所以使用accuracy是不准确的,因为负样本只有5个,对accuracy几乎无影响。

假设lamda设置在0.5-0.6之间,可以得到如下的混淆矩阵:

如果设置在0.8-0.9可以得到另外的混淆矩阵:

假阴性和假阳性都是我们不需要的,但是到底哪一个更重要,可以根据实际情况进行权重的调整。不同的任务,计算cost的方式也不一样:

2.3 More
2.3.1 Possible Issues
但是刚刚的方法也有一些问题。比如假设有一个classifier,可以区别猫和狗。classifier对于输入比如食蚁兽和羊驼来说,确实可以检测出他们是异常数据。但是对于老虎和狼,这些生物在猫和狗的特征上特别强烈,以至于classifier很难将它们挑出来。

所以会不会某些特征,比如颜色,会特别影响分类结果呢?老师将一些图片涂黄之后就会使得识别为simpsons家族的概率提高:

2.3.2 Network for Confidence Estimation
刚刚那种方法虽然简单,但是效果是不错的。还有另外一种更好的方法,即学习一个网络可以直接输出信心分数:

2.3.3 Obtain Anomaly
异常数据是难以获得的,所以有人考虑一种生成器可以生成一些异常资料:

3 Without Labels
就是指的训练数据是没有标签的。假设很多人可以同时操作一个游戏角色,那么多数玩家都是期望游戏可以正常进行的,而假设存在一些玩家恶意阻止游戏进行,那么考虑怎样检测出来。给定一组训练数据,给定input
x
x
x,
x
x
x每个维度代表玩家的某种行为:

同样的,输入x,可以判断是否为异常数据。但是这里已经没有classifier了,所以使用了一个几率函数P来判断:

因为玩家的行为是可以统计的,假设有两个维度,可以获得不同玩家行为的概率分布。直观上可以感知哪些位置概率高,哪些概率低,但是仍然需要数值化的方法:

假设给定一种概率密度函数可以描述数据的分布,其参数
θ
\theta
θ(指代所有的参数)是未知的,那么可以通过极大似然估计来获取参数的值。选择不同的
θ
\theta
θ值可以算出不同的似然值,而我们需要一组
θ
\theta
θ使得似然最大。

使用高斯分布举例,参数就是均值和方差,也就是我们关注的
还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
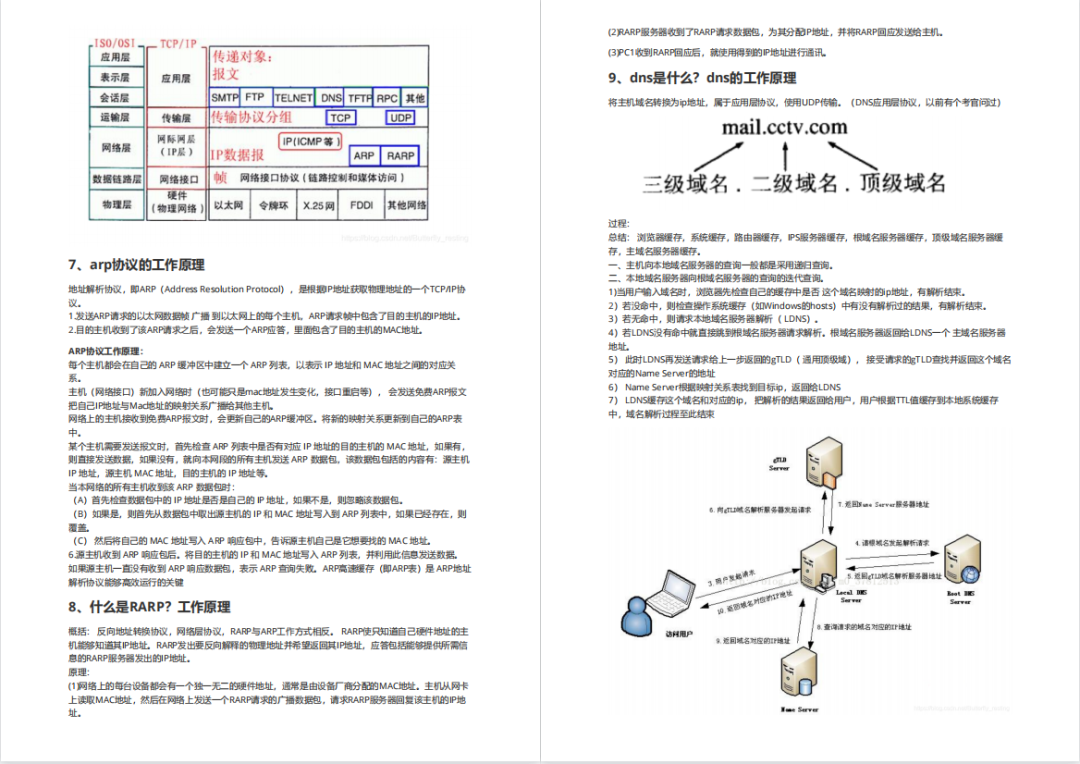


需要体系化学习资料的朋友,可以加我V获取:vip204888 (备注网络安全)
内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
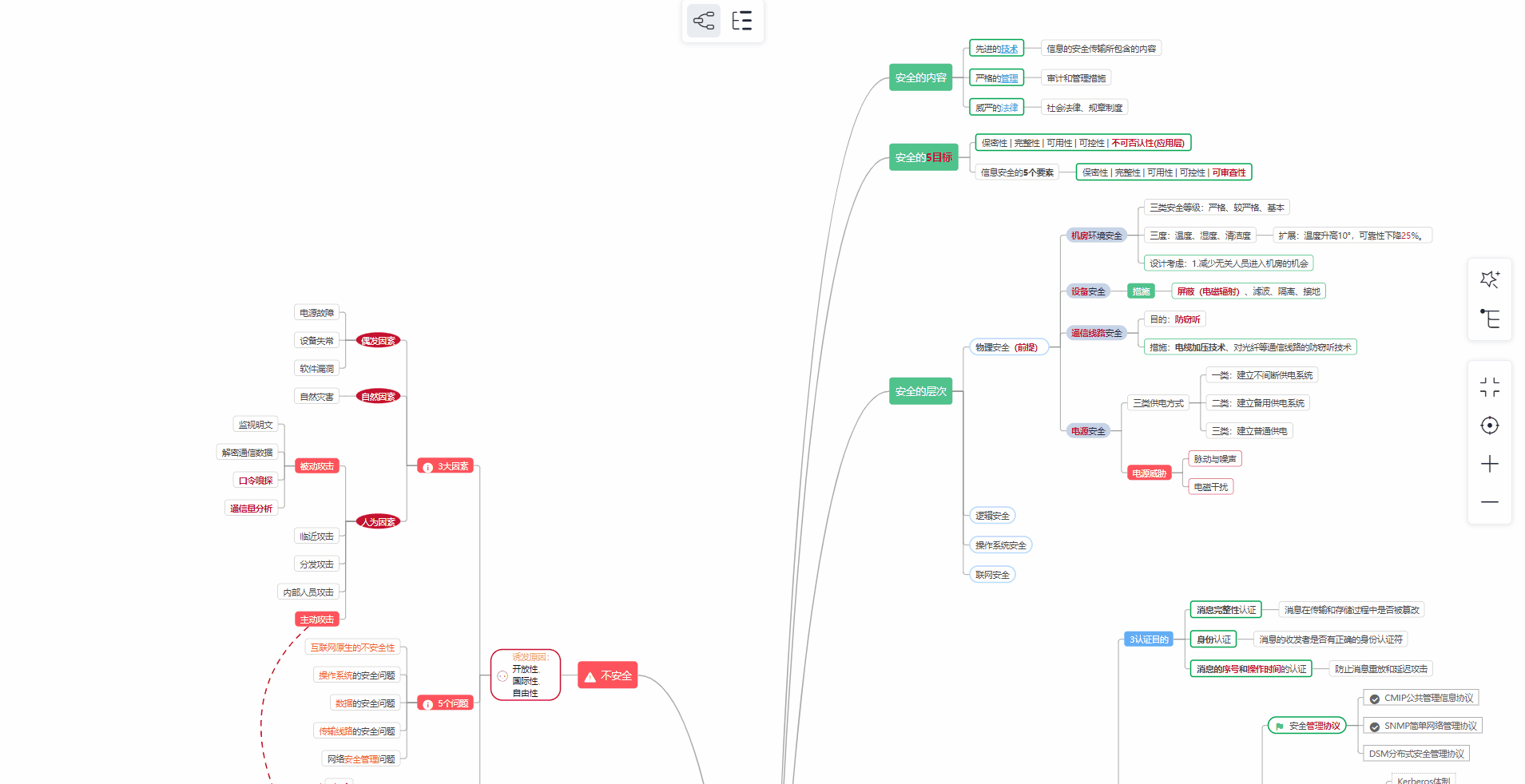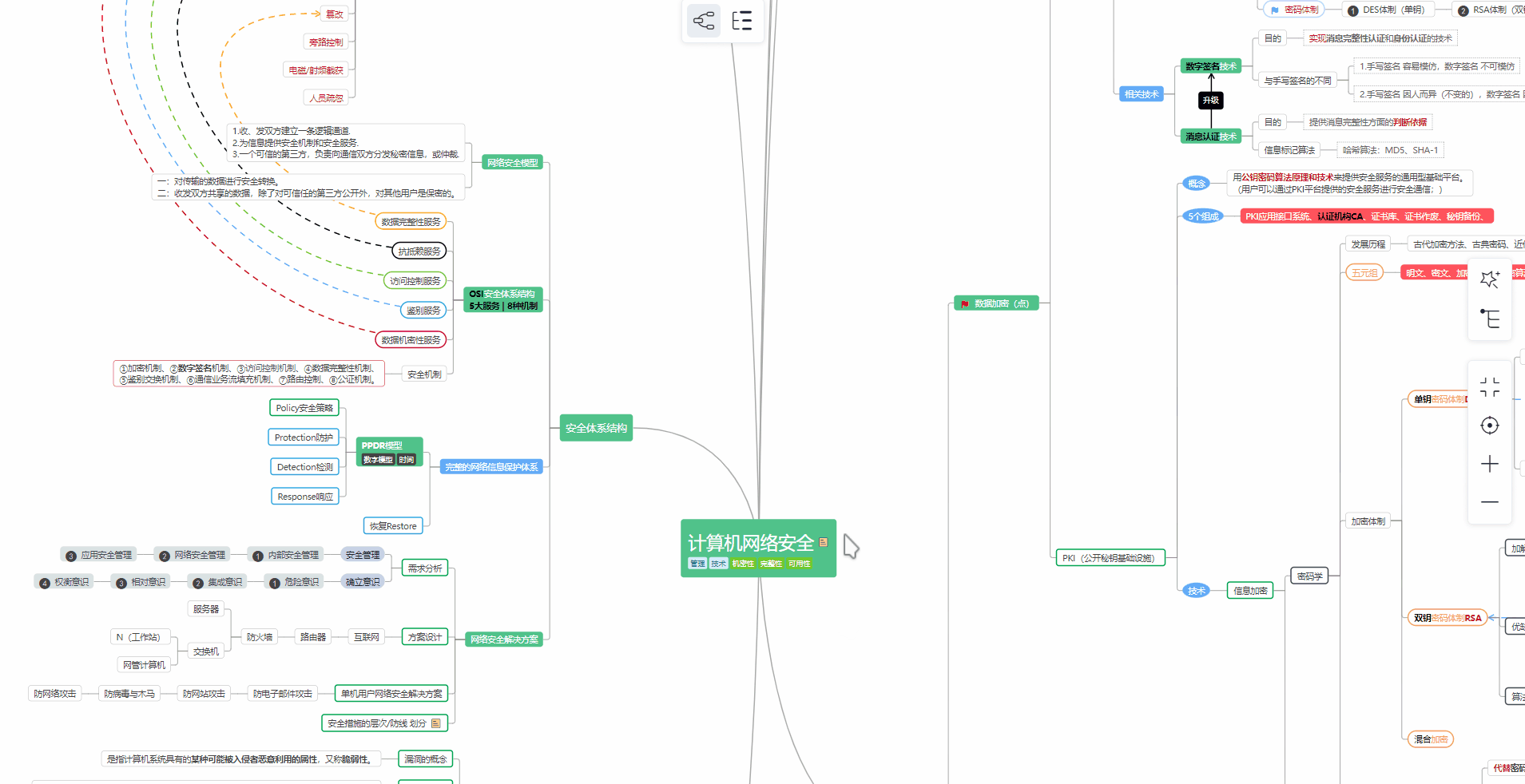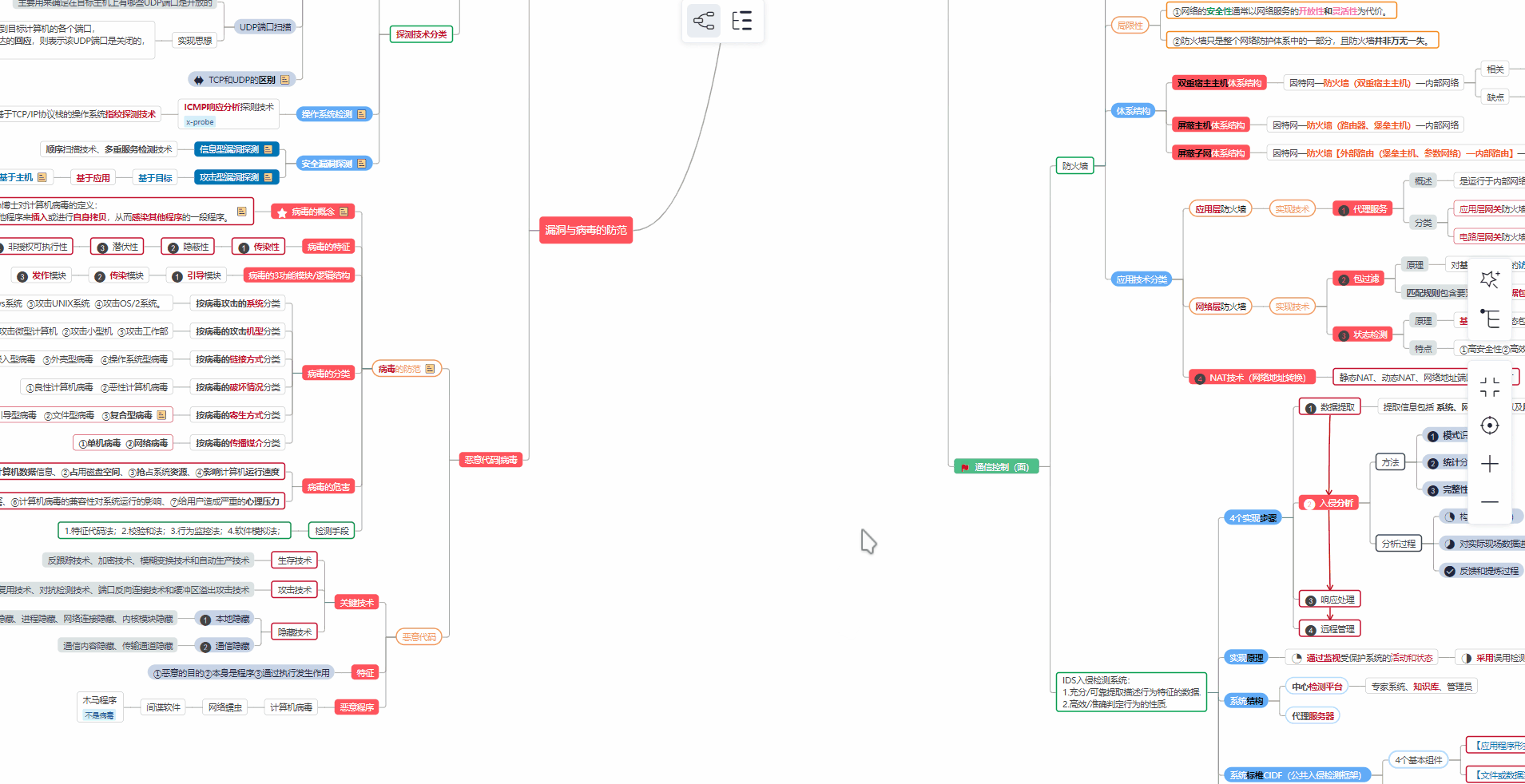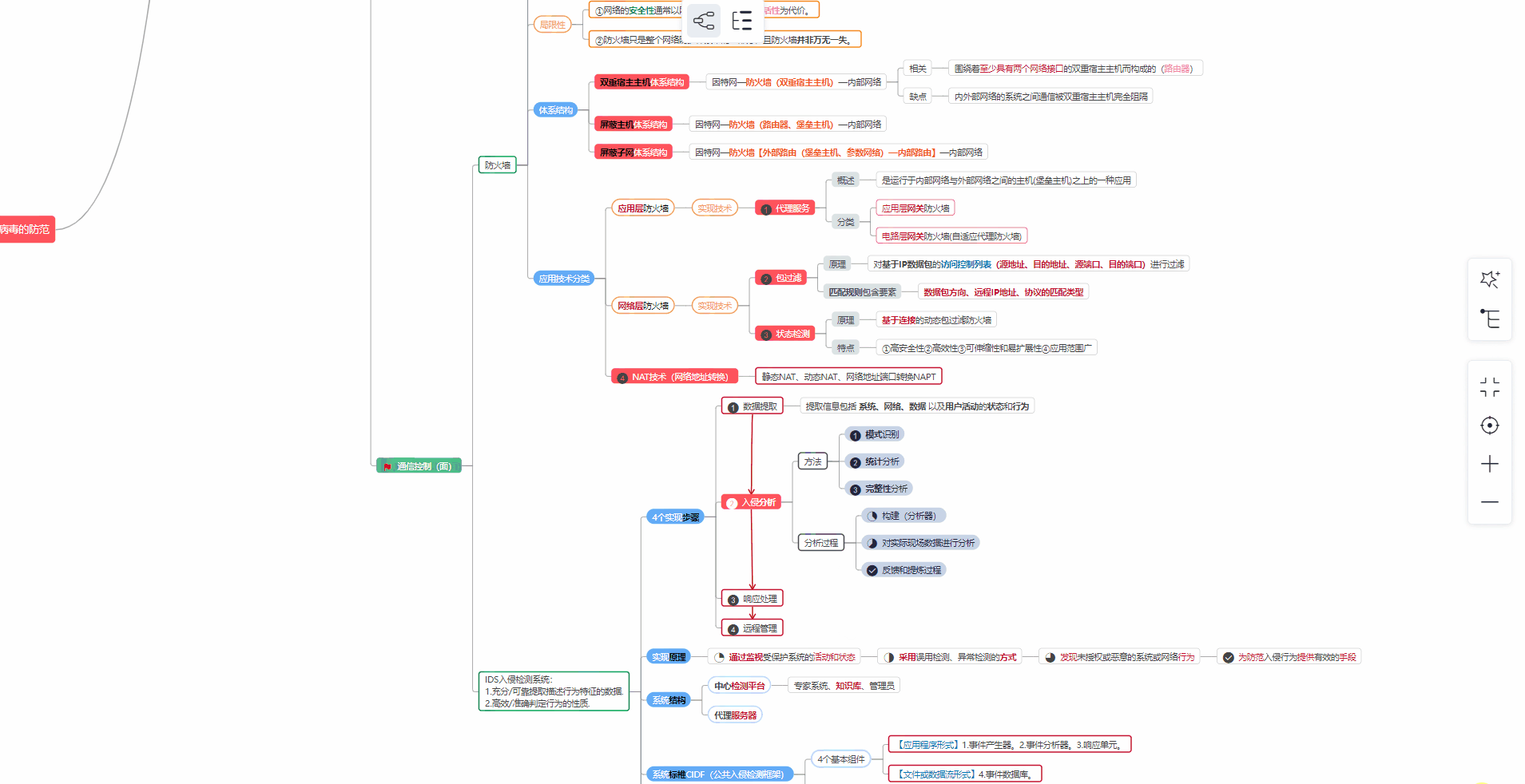
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









