






欢迎来到雲闪世界。我们正处于生成式人工智能应用历程的关键时刻,我们开始听到有关生成式人工智能变革潜力的相互矛盾的观点。
大型语言模型 (LLM) 提供商,例如 Open AI、Mistral、Google、Meta 等,正在陆续推出一个又一个 LLM — 每次迭代都比前一个更小、更高效。但这些都是通用的预训练 LLM,没有明确的业务用例,或者说,业务特定的用例仍然需要在这些基础 LLM 之上开发。因此,这些 LLM 只是一种推动因素,而不是衡量业务影响的指标。当然,我们确实有一些超大规模企业和技术供应商吹嘘他们已经实施的数百(或数千)个基于 LLM 的用例,这些用例具有量化的业务价值。
另一方面,我们看到企业/专家开始对人工智能持更“悲观”的看法。例如,高盛最近的报告就是一个很好的例子。标题“人工智能:花费太多,收益太少?”是不言而喻的,我不会详细阐述——只需说,虽然没有人否认人工智能的未来潜力,但他们没有看到人工智能(截至目前)解决任何复杂的商业战略问题。
这里的问题之一显然是正在进行大量的探索/概念验证 (PoC) — — 但这些 PoC 并未投入生产。根据一些研究(例如《福布斯》、《Everest》),Gen AI PoC 的失败率高达 80%–90%。TruEra 在最近的一项研究中也强调了这一点,他们推测“只有 11% 的企业将超过 25% 的 GenAI 计划投入生产。”他们指出,随着企业寻求将更多 LLM 用例投入生产,需要进行持续和程序化的 LLM 评估(和 LLM 可观察性)。
我们认为,导致失败的一个主要原因是缺乏针对 PoC 的全面 LLM 评估策略,缺乏针对特定用例的成功指标。
这种情况似乎与开创性的 MLOps 论文《机器学习系统中的隐藏技术债务》非常相似,其中研究人员强调,训练机器学习 (ML) 模型只是整个 ML 训练到部署生命周期的一小部分。同样,评估基础 LLM 的能力只是执行针对企业用例的用例特定 LLM 评估的一小部分。
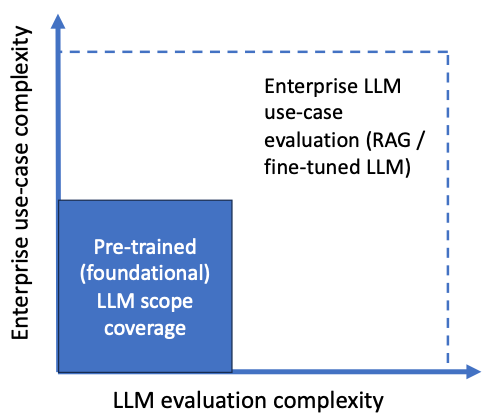
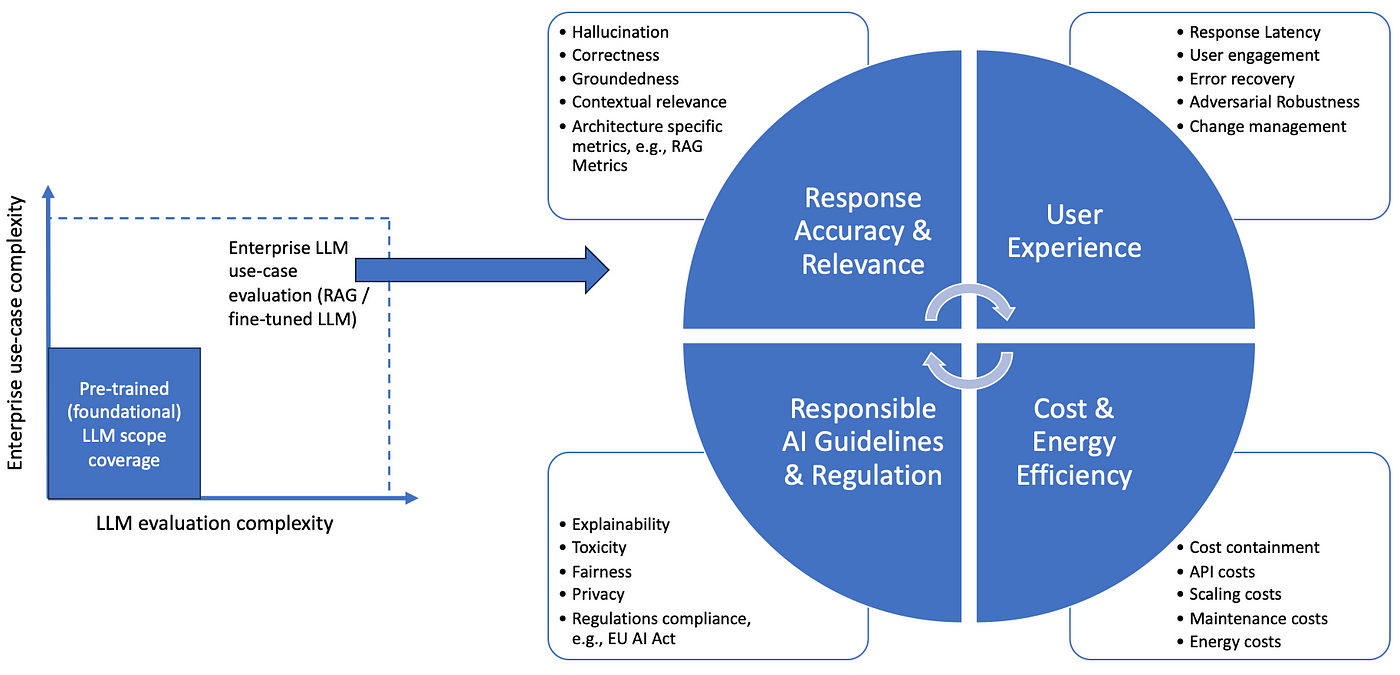
图:企业用例与基础 LLM 评估(图片来自作者)
在本文中,我们迈出了定义以企业用例为重点的全面 LLM 评估策略的第一步。这是一个多方面的问题,需要设计特定于用例的验证测试,涵盖功能和非功能指标,同时考虑底层 LLM、解决方案架构(检索增强生成 - RAG、微调)、适用法规和企业负责任的 AI 指南/政策。
LLM 评估策略
全面的 LLM 评估策略是将开发的解决方案从 PoC 转移到生产的关键。它由以下 4 个重叠(有时相互冲突)的评估标准组成:
- 响应准确性和相关性
- 用户体验:提高用户满意度
- 成本控制和能源效率
- 遵守负责任的人工智能准则和法规遵从性
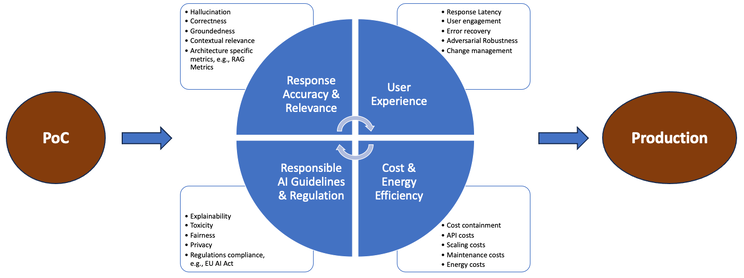
图:LLM 评估标准(作者供图)
(当前)法学硕士评估方法
目前流行的 LLM 评估方法主要有三种:
- 通用基准和数据集
- 法学硕士法官专业
- 手动评估
让我们首先考虑公开的 LLM 排行榜,例如Hugging Face Open LLM Leaderboard。虽然它们很有用,但它们主要侧重于使用公共数据集在通用 NLP 任务(例如问答、推理、句子完成)上测试预先训练的 LLM,例如
- SQuaD 2.0 — 问答
- 羊驼评估— 遵循指导
- GLUE——自然语言理解(NLU)任务
- MMLU——多任务语言理解
- DecodingTrust — 负责任的 AI 维度,是 HuggingFace LLM 安全排行榜的基础框架
这里的关键限制是这些排行榜专注于评估通用自然语言处理 (NLP) 任务上的基础 (预训练) LLM。
企业用例情境化需要进一步应用检索增强生成/使用企业数据对预训练的 LLM 进行微调。因此,这些通用基准测试结果不能按原样应用(不足以)执行特定用例的 LLM 评估。
图:企业 LLM 语境化(图片来自作者)
LLM -as-a-Judge方法使用“评估”LLM(另一个预先训练过的 LLM)来评估目标 LLM 的响应质量,并使用 LangChain 的CriteriaEvalChain等方法对其进行评分。不幸的是,用例特定的限制在这种情况下仍然存在。它的优点是加速 LLM 评估过程,但(在大多数情况下)由于使用第二个 LLM,成本会更高。
最后一种选择是借助企业主题专家 (SME) 进行 (外包) 手动验证。虽然它可以作为后备选项,但它具有 (高) 成本和工作量影响,需要考虑 SME 的可用性进行规划,并以标准化方式执行以适应人为偏见。
企业用例特定的 LLM 评估策略
在本节中,我们重点介绍特定用例的 LLM 评估策略。重点是,如果企业用例与金融、法律等相关,我们需要设计一个评估策略,其中要考虑底层用例的底层领域数据、(子)主题、用户查询、性能指标和监管要求等。
例如,在联络中心环境中(当今采用 Gen AI 最多的领域之一),
- 总结用例千差万别,从浓缩客户投诉,到概述销售电话的结果,再到提取电话中提到的消费价值。
- 呼叫中心的记录也存在不完整的通话和涉及多个主题的对话的问题。
- 从对话的角度来看,总结技术支持电话与总结产品咨询电话需要不同的理解和重点。
鉴于此,需要设计一个针对联络中心用例的 LLM 评估策略,同时考虑生成的响应的语义上下文和分布。
我们首先重点讨论针对 LLM 准确度的用例特定评估。
LLM 用例准确性(关于幻觉)
LLM 幻觉(理所当然地)被认为是 LLM 产品化的最大障碍之一。已经提出了许多统计指标来量化模型准确性:
- 困惑度:量化模型如何预测文本——分数越低,模型越好。
- BLEU(双语评估评分):BLEU 是机器翻译任务中常用的指标。它将生成的输出与一个或多个参考翻译进行比较,并测量它们之间的相似度。分数越高,模型越好。
- ROUGE(面向召回率的 Gissing 评估替补):ROUGE 是一套用于评估摘要质量的指标。它将生成的摘要与一个或多个参考摘要进行比较,并计算准确率、召回率和 F1-Score。F1-Score 越高,模型越好。
用例
让我们考虑一个人工智能产品,它根据营销经理提供的输入提供社交媒体活动的用户响应摘要。
用户输入:您能否提供一些见解,让我们能够在即将到来的活动中做得更好,尤其是针对巧克力?
LLM 成果:对于您的巧克力产品活动,通过社交媒体平台上具有视觉吸引力和令人垂涎的图像来突出其独特的风味特征。考虑与受欢迎的美食博主或有影响力的人合作,创造诱人的内容并吸引更广泛的受众。提供限时促销或独家折扣,以营造紧迫感并推动销售。
对于上面的例子,Perplexity 会很低,BLEU 和 ROGUE 会很高。
正确性与扎实性
广义上讲,LLM 用例准确性可以通过以下方面来衡量:
- 正确性:指 LLM 答复的事实准确性
- 根基性(Groundedness):指LLM的回应与其底层KB之间的关系。
研究表明,答案可能是正确的,但依据仍然不正确。
当检索结果不相关时可能会发生这种情况,但解决方案以某种方式设法产生正确答案,错误地断言不相关的文档支持其结论。
让我们面对现实:幻觉是任何文本生成系统的固有特征。
如果没有生成功能(按照这种逻辑,这就是幻觉),法学硕士 (LLM) 将仅仅成为一个检索系统,而没有生成任何“新”文本的能力。
RAG 在解决 LLM 幻觉方面的局限性
RAG 被广泛宣传为治疗幻觉的良药。不幸的是,虽然 RAG 可以限制幻觉,但无法完全消除幻觉。
在最近的一项研究中,Manning 等人强调了 RAG 在法律用例中的局限性。在法律环境中,模型产生幻觉的方式主要有 3 种:
- 它可能会不忠于训练数据,
- 不忠于及时输入,
- 或不忠于世界的真实事实。
他们专注于事实幻觉,并强调了许多特定于法律领域的检索挑战,例如,
- 法律问题通常没有单一、明确的答案——答复分散在跨时间和地点的多份文件中。
- 法律语境中的文件相关性并非仅基于文本相似性。在不同的司法管辖区和不同的时间段,适用的规则或相关法理可能会有所不同。
简而言之,他们表明,虽然 RAG 有助于减少最先进的预训练 GPT 模型的幻觉,但它们仍然会有 17% 和 33% 的时间产生幻觉。
结论
在本文中,我们表明基于用例的 LLM 评估对于企业中的 LLM 生产化至关重要。我们总结了当前的 LLM 评估策略,这些策略主要侧重于在通用 NLP 任务上对预训练的 LLM 进行基准测试。然后,我们概述了一种基于这一基础 LLM 评估的综合评估策略,其中考虑到底层用例的数据和对话相关要求/分布。
在本文中,我们主要关注了 LLM 对幻觉的准确性评估。我们计划在未来将其扩展为一系列文章,涵盖其他 LLM 评估维度,从负责任的 AI 指标开始,例如毒性、公平性、隐私性。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 5016
5016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









