






欢迎来到雲闪世界。在语言模型和代理 AI 的背景下,记忆和基础都是热门且新兴的研究领域。尽管它们在句子中经常紧密相关,但在实践中它们发挥着不同的作用。在本文中,我希望澄清围绕这两个术语的混淆,并展示记忆如何在模型的整体基础中发挥作用。

来源:Dalle3,描述:大脑的分裂部分以友好的卡通风格描绘记忆和基础
语言模型中的记忆
在我的上一篇文章中,我们讨论了记忆在 Agentic AI 中的重要作用。语言模型中的记忆是指 AI 系统保留和回忆相关信息的能力,有助于其推理和不断从经验中学习的能力。记忆可以分为 4 类:短期记忆、短期长期记忆、长期记忆和工作记忆。
听起来很复杂,但让我们简单地分解一下:
短期记忆(STM):
STM 只能在很短的时间内保留信息,可能是几秒到几分钟。如果你向语言模型提问,它需要保留你的信息足够长的时间才能为你的问题生成答案。就像人一样,语言模型很难同时记住太多东西。
米勒定律指出,“短期记忆是记忆的一个组成部分,它能在短时间内(通常为几秒到一分钟)以活跃、随时可用的状态保存少量信息。STM 的持续时间似乎在 15 到 30 秒之间,STM 的容量有限,通常认为约为 7±2 个项目。”
因此,如果你问语言模型“我在上一条消息中提到的那本书是什么类型的?”,它需要使用其短期记忆来参考最近的消息并生成相关的响应。
执行:
上下文存储在外部系统中,例如会话变量或数据库,其中包含部分对话历史记录。每个新的用户输入和助手响应都会附加到现有上下文中以创建对话历史记录。在推理过程中,上下文会与用户的新查询一起发送到语言模型,以生成考虑整个对话的响应。这篇研究论文更深入地介绍了实现短期记忆的机制。
短期长期记忆(SLTM):
SLTM 会保留信息一段时间,可能是几分钟到几小时。例如,在同一会话中,您可以从上次对话中断的地方继续,而无需重复上下文,因为它已存储为 SLTM。此过程也是一个外部过程,而不是语言模型本身的一部分。
执行:
可以使用标识符来管理会话,这些标识符会将用户随时间变化的交互联系起来。上下文数据的存储方式可以在定义的时间段内跨用户交互持续存在,例如数据库。当用户恢复对话时,系统可以从之前的会话中检索对话历史记录,并在推理过程中将其传递给语言模型。与短期记忆非常相似,每个新的用户输入和助手响应都会附加到现有上下文中,以保持对话历史记录为最新。
长期记忆(LTM):
LTM 会将信息保留管理员定义的一段特定时间,该时间可能是无限期的。例如,如果我们要构建一个 AI 导师,语言模型就必须了解学生在哪些科目上表现良好、在哪些方面仍存在困难、哪种学习方式最适合他们等等。这样,模型就可以回忆起相关信息,为其未来的教学计划提供参考。松鼠 AI就是一个使用长期记忆来“制定个性化学习路径、进行有针对性的教学并在需要时提供情感干预”的平台的例子。
执行:
信息可以存储在结构化数据库、知识图谱或文档存储中,并根据需要进行查询。根据用户当前的交互和过去的历史记录检索相关信息。这为语言模型提供了上下文,该模型随用户的响应或系统提示一起传回。
工作记忆:
工作记忆是语言模型本身的一个组成部分(与其他类型的外部过程记忆不同)。它使语言模型能够保存信息、操纵信息并对其进行改进,从而提高模型的推理能力。这很重要,因为当模型处理用户的要求时,它对任务的理解以及执行任务所需的步骤可能会发生变化。您可以将工作记忆视为模型自己的思维便笺簿。例如,当提供多步骤数学问题(例如 (5 + 3) * 2)时,语言模型需要能够计算括号中的 (5+3) 并存储该信息,然后再将两个数字相加并乘以 2。如果您有兴趣深入研究这个主题,论文“ TransformerFAM:反馈注意力是工作记忆”提供了一种扩展工作记忆的新方法,并使语言模型能够处理无限长度的输入/上下文窗口。
执行:
Transformer 中的注意层或循环神经网络 (RNN) 中的隐藏状态等机制负责维护中间计算,并能够在同一推理会话中操纵中间结果。当模型处理输入时,它会更新其内部状态,从而实现更强大的推理能力。
所有 4 种类型的记忆都是创建能够有效管理和利用不同时间范围和环境下信息的 AI 系统的重要组成部分。
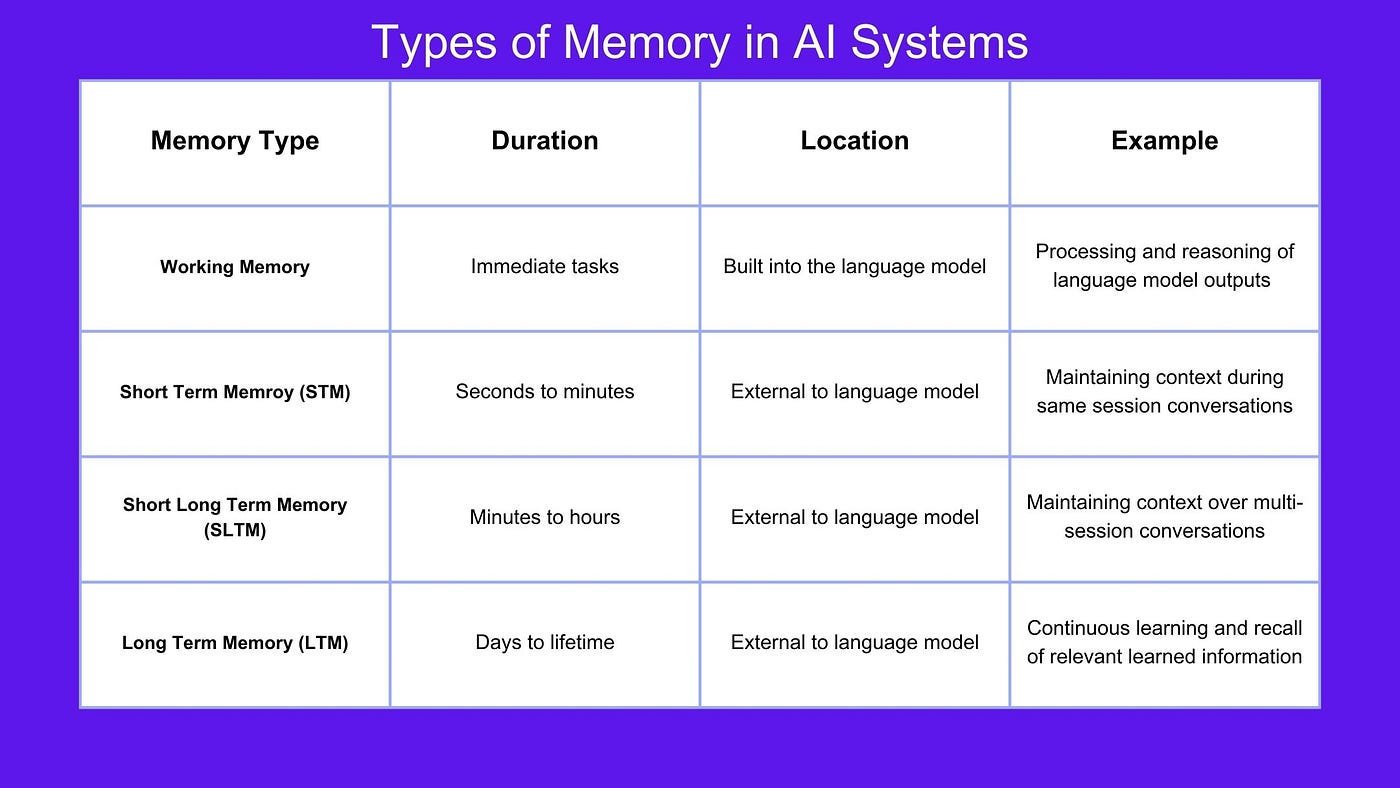
人工智能系统中的记忆类型表,来源:Sandi Besen
接地
语言模型的响应应始终在对话上下文中有意义 — 它们不应只是一堆事实陈述。基础衡量模型产生与上下文相关且有意义的输出的能力。语言模型的基础过程可以是语言模型训练、微调和外部过程(包括记忆!)的组合。
语言模型训练与微调
模型最初训练时所用的数据将对模型的扎实程度产生重大影响。在大量多样化数据上训练模型可以使其学习语言模式、语法和语义,从而预测下一个最相关的单词。然后,对预训练模型进行领域特定数据微调,这有助于它为需要更深领域特定知识的特定应用生成更相关、更准确的输出。如果您要求模型在特定文本上表现良好,而它在初始训练期间可能没有接触过这些文本,这一点就尤为重要。虽然我们对语言模型的能力期望很高,但我们不能指望它在从未见过的东西上表现良好。就像我们不会指望学生在没有学习过材料的情况下在考试中取得好成绩一样。
外部环境
为模型提供实时或最新的上下文特定信息也有助于它保持扎实。有很多方法可以做到这一点,例如将其与外部知识库、API 和实时数据集成。这种方法也称为检索增强生成 (RAG)。
记忆系统
人工智能中的记忆系统在确保系统基于之前采取的行动、经验教训、长期表现以及与用户和其他系统的经验保持基础方面发挥着至关重要的作用。本文前面概述的四种记忆类型在确保语言模型保持上下文感知和产生相关输出的能力方面发挥着至关重要的作用。记忆系统与训练、微调和外部上下文集成等基础技术协同工作,以增强模型的整体性能和相关性。
结论
记忆和基础是相互关联的元素,可增强 AI 系统的性能和可靠性。记忆使 AI 能够在不同时间范围内保留和处理信息,而基础则确保 AI 的输出具有上下文相关性和意义。通过整合记忆系统和基础技术,AI 系统可以在交互和任务中实现更高水平的理解和有效性。
感谢关注雲闪世界。(亚马逊aws和谷歌GCP服务协助解决云计算及产业相关解决方案)
订阅频道(https://t.me/awsgoogvps_Host)
TG交流群(t.me/awsgoogvpsHost)















 4288
4288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









