







谷歌最近发布了 Gemini 2.0 Flash 版本模型,这可能是当前性价比最高的 AI 模型了。
这个模型除了性价比之外,还有何魔力呢?为什么我会说 RAG 即将被淘汰呢?
RAG 究竟是什么?
RAG 全称是 Retrieval-Augmented Generation,即检索增强生成技术。这项技术常被用于帮助 ChatGPT 等 AI 模型访问其原始训练数据之外的外部信息。
你可能在不知不觉中就体验过它,用过 Perplexity 或其他 AI 搜索吗?
当它们边回答问题边检索资料时,那就是 RAG 在工作。
甚至当你向 ChatGPT 上传文件并提问时,同样运用了RAG技术。
RAG 之所以重要,是因为早期AI模型的记忆容量极其有限。
回到2023年初,主流模型只能处理约4,000个token(相当于6页文本)。
这意味着面对海量信息时,必须通过分块切割、向量化存储(嵌入技术/向量数据库/分块处理等)等复杂操作,
再按需检索相关片段。
但如今?
这套流程可能可以丢进历史了。
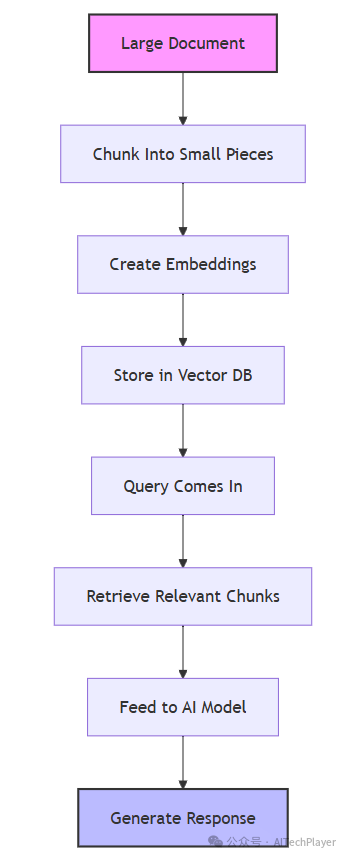
传统RAG处理流程图
Gemini 2.0 Flash 登场
虽然当前所有 AI 模型都能处理大量信息,但 Gemini 2.0有何特别?
它能一次性处理100万token。
某些模型甚至达到200万token。
这意味着你不再需要切分数据成零碎片段,而是可以将完整文档直接投喂给模型,让它整体推理。
更关键的是 — 新一代模型不仅记忆容量更大,准确性也显著提升。
谷歌最新模型的幻觉率(即胡编乱造的概率)创历史新低。
仅此一点就带来质的飞跃。

Gemini 2.0直读文档处理流程
范式变革的威力
举个真实案例:假设你有一份长达50,000 token的财报电话会议记录(这已经很大了)。
若采用传统 RAG 方案,你需要将其切割成 512 token 的小块存储。
当用户提问时,系统需要检索相关片段再输入模型。
问题在于:模型无法进行全局推理。
比如当用户问:
“该公司今年营收与去年相比如何?”
若仅提供零散文本块,答案必然不准确。
但若将完整记录输入 Gemini 2.0 呢?
它能通览全局 — 从 CEO 开场白到核心数据,再到分析师问答环节,都能给出更全面精准的解析。
因此当我说 RAG 已死 时,实际是指:
传统 RAG 方法论(将单个文档切分处理)已过时。
你不再需要这套繁琐流程。
直接把完整文档交给大模型即可。
但 RAG 并未彻底消亡
有人提出:
“如果有100,000份文档怎么办?”
问得好!
面对超大规模数据集 - 比如苹果过去十年的所有财报,这仍需筛选机制。
但方法论已革新,我的新方案是:
-
先检索相关文档(例如仅提取2020-2024年苹果财报)
-
将完整文档并行输入AI模型
-
整合各文档输出得出最终结论
相比传统分块法,这种方案准确度更高。
让 AI 在完整文档层面进行推理,而非处理零散的片段数据。
下图展示了现代方案处理海量文档的流程
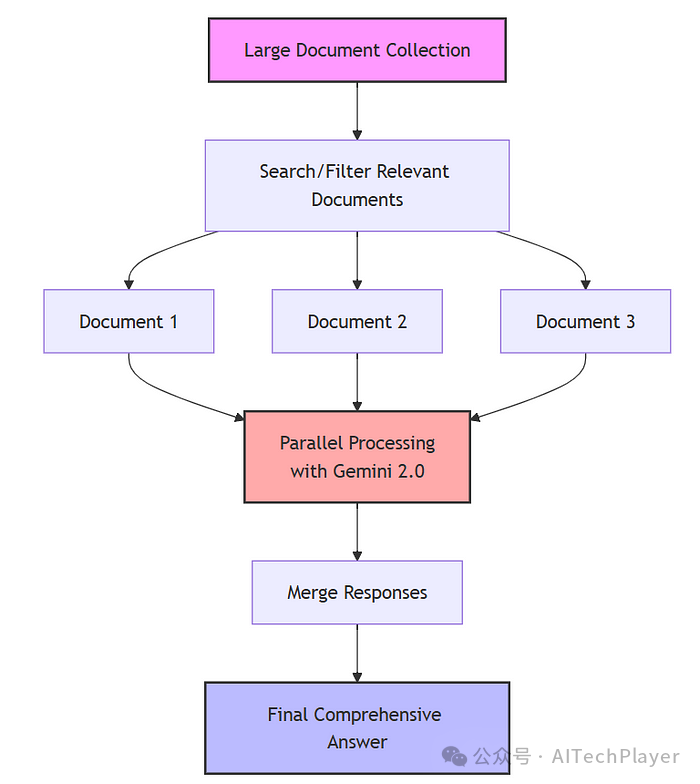
现代方案处理海量文档流程
核心启示
若你正在开发 AI 产品或进行实验,请记住大道至简。
多数人容易陷入过度设计的陷阱。
直接向 Gemini 2.0(或任何大上下文窗口 AI 模型)上传完整文档,让模型自主推理。
明年技术会再次迭代吗?很有可能。
AI 模型正朝着更便宜、更智能、更快速的方向发展。
但当下?传统 RAG 方法论可以退场了。
把你的数据灌入谷歌新模型,就能以更简捷的方式获得更优质的结果。
如果你现在就有需要分析的文档,不妨立即尝试。
或许会惊喜地发现:一切竟变得如此简单。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









