






在本文中,通过深入浅出的方式,为读者提供了对大模型技术全面而深入的理解,同时也强调了理性看待大模型的重要性。

为什么要聊这个话题?
原因有三:
- 读懂历史才能预测未来。我们了解一个新事物最快速的方式就是从它历史出发,更能清楚的知道它从哪里来要到哪里去;
- 知其然更要知其所以然。了解大模型生成能力背后的运作方式,才能更好地结合我们自有的一些业务来提升效率。
- 祛魅。相信我们大家也都看过很多鼓吹大模型的一些文章,当然也有一些diss大模型的一些文章。知道它的原理、流程之后,我们就更能够理解大模型的能力边界,更理性地看待这一场大模型的风波。
一、大模型之前的人工智能——弱人工智能(Weak AI)
在大模型之前的人工智能,属于弱人工智能,你可以把它理解为它就是一个专才,它是服务于某个专业领域的一个技术人员。即使是强者如阿尔法狗,它是在这个地球上最强的一个下围棋的智能体。但是它除了围棋之外,其他领域依旧是一个小白。
但大模型是一个通才。因为它接受了大量的各种领域的数据训练,像语文、数学、围棋等等,ChatGPT也在两个月的时间突破了一亿的用户,也超过了之前tiktok 9个月创下的记录。
 产品经理到底该不该选择做B端?近几年互联网经历了砸钱做市场的热潮后,越来越意识到,仅靠C端发力是不行的,需要尽快补齐B端的短板。那产品经理到底该不该选择转型做B端呢?查看详情 >
产品经理到底该不该选择做B端?近几年互联网经历了砸钱做市场的热潮后,越来越意识到,仅靠C端发力是不行的,需要尽快补齐B端的短板。那产品经理到底该不该选择转型做B端呢?查看详情 >
那为什么它在这个时间点横空出世呢?以下是三个必不可少的一个因素,而且这三个因素也是训练大模型的一些核心要素,也就是数据、算法以及算力。
数据的话贯彻了字节的大力出奇迹,把模型的参数量还有训练数据搞的无限量大,然后就出现了某种程度上的智能,也叫涌现,也就是他可以执行他之前没有预料到的一些任务;
第二个就是算法,目前国际上以及国内的主流的大模型都是transformer作为底层的模型架构;
第三个就是算力,有一篇论文就是在讲训练大模型的时候,用GPU来训练大模型会比CPU训练的效率更好。所以我们就开始用GPU来进行训练大模型,后来也造就了英伟达目前两兆亿美元的市值。
二、大模型是通往强人工智能(strong AI)/通用人工智能(AGI)之路吗?
刚才说到像大模型这样的通才,更符合我们对于人工智能的想象,我们的想象可能就像是钢铁侠里面的他的助手贾维斯一样,他是跟我们人可以这种这种可以自在流畅的一个交流,而不是像siri或小爱同学,某种程度上它是有点像人工智障。因为它是这种关键词的一个匹配,触发到某个关键词,它就会有对应的回复。我们想象中的这种人工智能,我们也把它称为强人工智能(strong AI),或者就是通用人工智能(AGI)。
AGI时代的大模型是一个通才,是一个无所不知的一个一种能力,它也是AGI时代机器人的大脑,给它装上四肢后,他就是一个机器人。所以大模型也带火了另一个产业,就叫具身智能(Embodied AI),这个赛道我也很看好。
三、大语言模型与 AGI 的关系
那大模型和人工智能之间是什么样的关系呢?
通用人工智能是我们在追寻的一个目标,机器学习和深度学习,它都是我们想去实现这个目标的一个手段。
生成式人工智能其实是通用人工智能的目标之一,但是因为目前我们的生成式人工智能都是用深度学习这样的技术来去实现的,所以我们把它归到深度学习里面。大模型是生成式人工智能的一个技术之一。
因为大语言模型是目前非常多,像主流的国内主流的像文心言、kimi、通义千问,国际上ChatGPT、llama、gemini,但他们的原理都是很类似的,这里讲解主要用ChatGPT作为例子。

那什么是机器学习呢?我们刚才有提到机器学习和深度学习,机器学习其实就是在去再去从一堆资料当中去找一个方程式。相信我们大家都会解这样的一个方程式:y=ax+b

给定X1多少,Y1是多少,然后X2是多少,Y2是多少,那我们就可以把这个未知数a和b给求出来,也就是两个已知条件,两个未知数。那时候我们叫未知数a、b,在机器学习当中他们就叫参数。ChatGPT中介绍的那种参数,千亿级别的或者10亿级别的,其实就是这边的一个参数量,目前普遍的定义是大于10亿的参数量才叫大语言模型,小于10亿的它就不叫大语言模型。有了这样的一组参数之后,我们给他一个输入,他是就会有一个输出了,这也就是ChatGPT在做事情。
四、ChatGPT在做的事:预测下一个字的文字接龙游戏
那ChatGPT它其实就是一个大于10亿参数量的方程式。给模型一批训练资料,从这些训练资料去把数10亿参数给找出来,这个过程就叫训练,或者我们要叫学习过程。训练好之后,给它一个输入,它有一个输出,这个使用的过程叫推理,或者叫测试的阶段。

我们在买GPU的时候,厂商就会介绍说,这样的GPU是适合训练阶段的,还是适合推理阶段的。可以理解为推理就是我们直接使用这样的一个大语言模型,训练的阶段就是要把它训练成我们想要的这种大语言模型的样子。
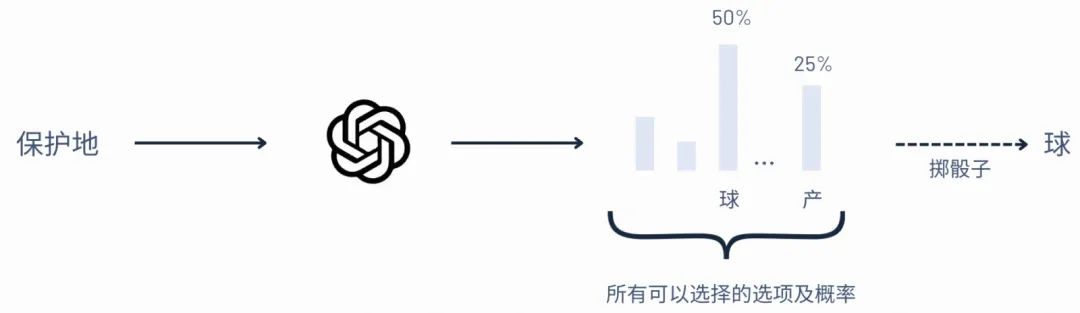
ChatGPT在做的事情就是预测下一个字的文字接龙的游戏。比如说一个输入(比如:保护地)给它,在其内部有多个可以选择的选项以及概率,这时候就掷骰子,看看他最有可能出现哪一个。像图片中概率最高“球”,那它就是50%,它就大概率用输出球。所以ChatGPT的输出是那种流式的那种结构,一个字一个字的吐出来,它其实就是在预测下一个字。
五、大模型训练三阶段
大模型训练就是分为三个阶段,第一个就是预训练,ChatGPT的P就是pretrain,就是预训练的意思。这个阶段可以理解为是ChatGPT它使用网络上面的大量的数据自己来学习,是积累实力的过程。第二个阶段就是微调的阶段,微调成我们人类想要它成为的样子,第三个阶段是人类反馈强化学习。

1. 预训练(Pre-train)
我们再依次来简单介绍一下这三个阶段。第一个阶段预训练,参数量可以理解为模型的复杂度,也可以理解为这个模型的它的一个天资。ChatGPT 1的参数量是117M,大概在一亿多一点。其实也算不上大语言模型,因为超过10亿才算大语言模型。
训练数据量就是给到他,让他去把这个参数量给计算出来的,就是用来拿文字学习文字接龙的一个资料量,也就是他后天的努力。在ChatGPT 1这个时候,只有7000本书的量。
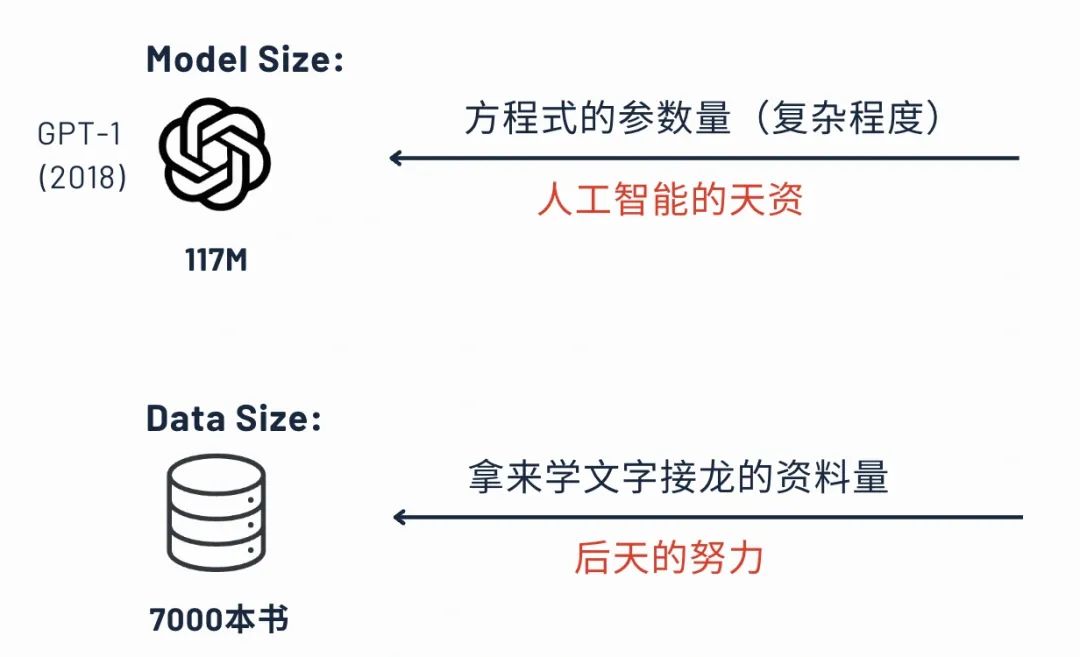
高手的话其实就是有非常高的天资,也就是说“大力出奇迹”的参数量要大,且它的训练数据比较大时,那就有可能会出现非常牛的一些大语言模型。
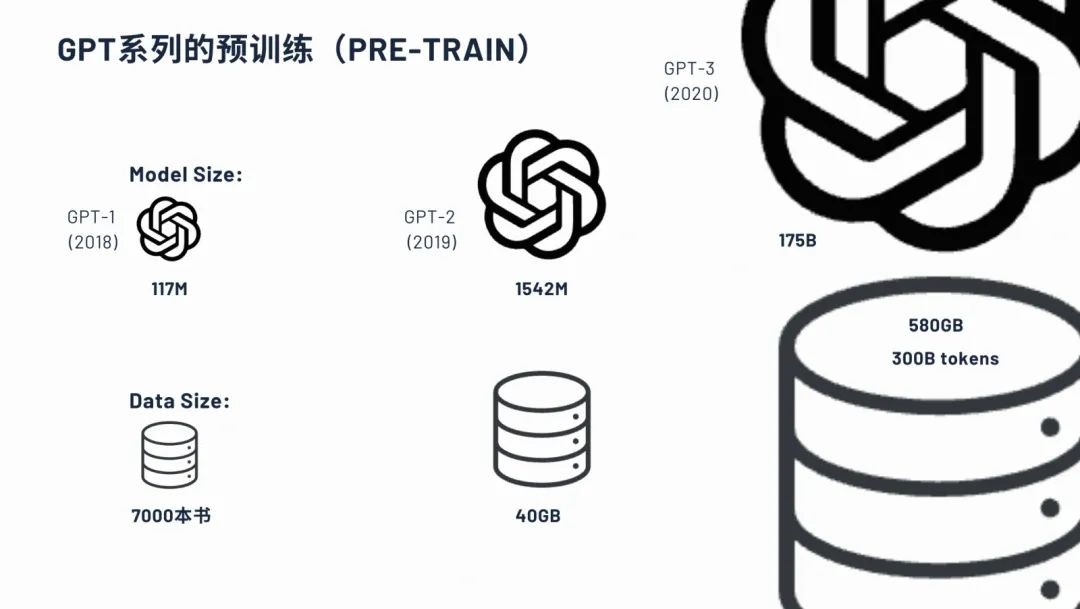
对比ChatGPT 1到3,它的一个训练量和和参数量。2018年的时候,1亿多个参数量,2019年的ChatGPT 2就变成了15个亿多的一个参数量,这个阶段已经算是大语言模型的一个阵列了,到了ChatGPT 3的时候,一下扩充到了一百多倍,也就是1750亿个参数的量,训练数据也达到了580G。
2. 找参数的过程——最佳化(optimization)
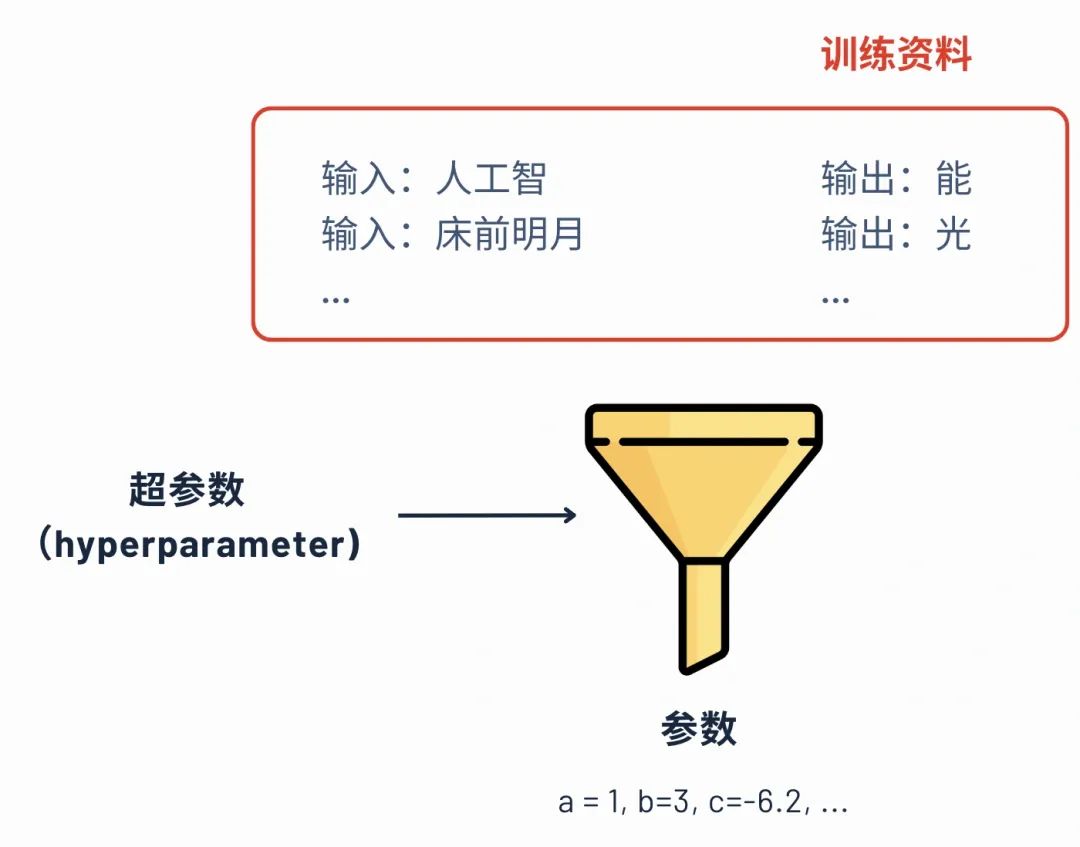
刚才讲到就是再去算那些未知数,也就是说算参数的这样一个过程,这个过程叫最佳化。也就是这些训练资料丢给大模型,然后它会自动会计算出这些参数。计算参数其实还有一个关键因素就是叫超参数。这个超参数是可以辅助他找参数的一个计算,可以理解为你要写一篇作文的话,我们给你一个范例这种感觉。
但是在算这个参数的时候,他是有可能失败的。那什么叫失败呢?失败的话也就是说我们给他一个输入,他没有符合我们的训练资料,或者是没有符合我们的测试集。比如说我们现在给他输入“床前明月光”,那他下面输入它不是“疑是地上霜”,那这样的话他参数就找错了,对不对?那参数找错怎么办呢?我们就要重新再来一遍,要调整这个超参数,让他重新再把这些训练资料再丢给他,让他重新再找一遍参数。
这个过程它是非常痛苦的,需要去调参数,重新再去跑这个流程。所以在这个流程当中,它是需要非常消耗算力的,算力其实就硬件资源就是GPU。这也就是为什么英伟达显卡卖那么贵,英伟达的市值那么高的一个其中很大的原因。
3. 训练三阶段之指令微调(instruction fine-turning)
在第二个阶段就是指令微调,这个部分其实就是人工去标注一些数据,去给到模型进行训练。你可以看到它标注的大概的流程就是用户的问题及产出的答案,由于这个需要人力的介入,也叫监督学习。

这个阶段也是要进行找参数的,所以也是要有这样最佳化找参数的过程。预训练时候的参考参数它是叫超参数,参考参数它可以直接用预训练结束时的参数,所以只做了预训练的模型也叫基座模型,在此开源模型基础上再做微调,比如现在我们国内一般就调通义千问了的开源的接口去做的微调训练模型。借助于预训练基座模型的参数做的微调,参数不会和第一阶段的参数差太多,所以也是这个阶段叫微调的其中的一个原因。
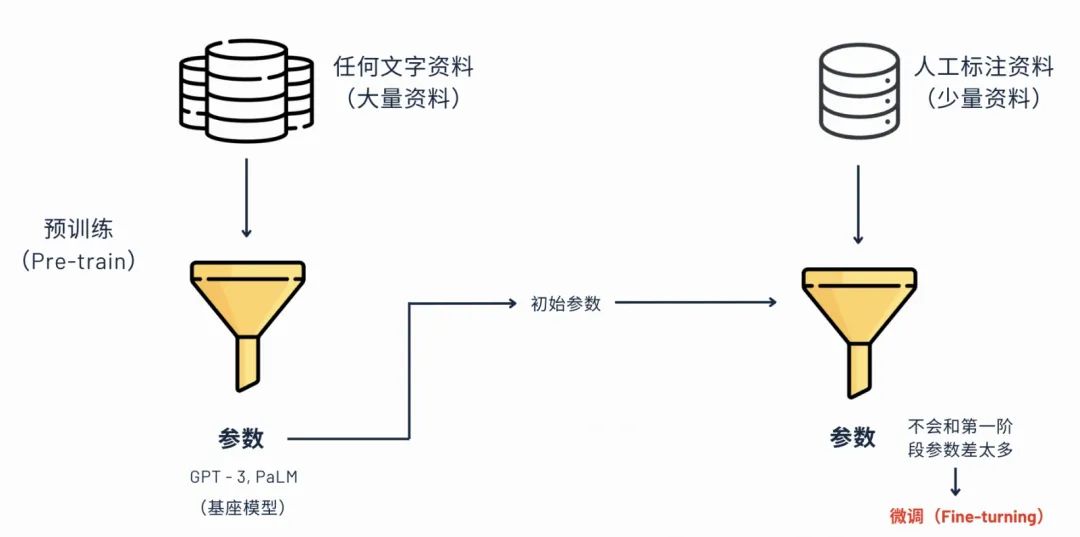
业界常用的一个微调手段是Laura,举一个例子来讲,如果我们现在想要ChatGPT去写一个公文的风格的一篇文章,那其实他的输出的这种形式很大程度上是要取决于他之前的训练数据是怎样的,但是他训练的数据跟我想要的,这时候就想对他进行微调。就是人工标注数据对,给他输入是怎么样的,输出是怎么样子。微调后产出的文章,就会符合具体的业务场景。
这个在底层的原理就是对于原本的这个参数不改变,只不过是在这个参数的基础上再去加一些参数。所以它的好处就是第一个减少了运算量。从而就不需要那么大的一个算力支出;第二个就是新的参数跟初始参数是类似的,因为它是在原本的基础上再加的,所以就保证模型的质量就不会太差。

4. 人类反馈强化学习(IReinforcement Learning from Human Feedback, RLHF)
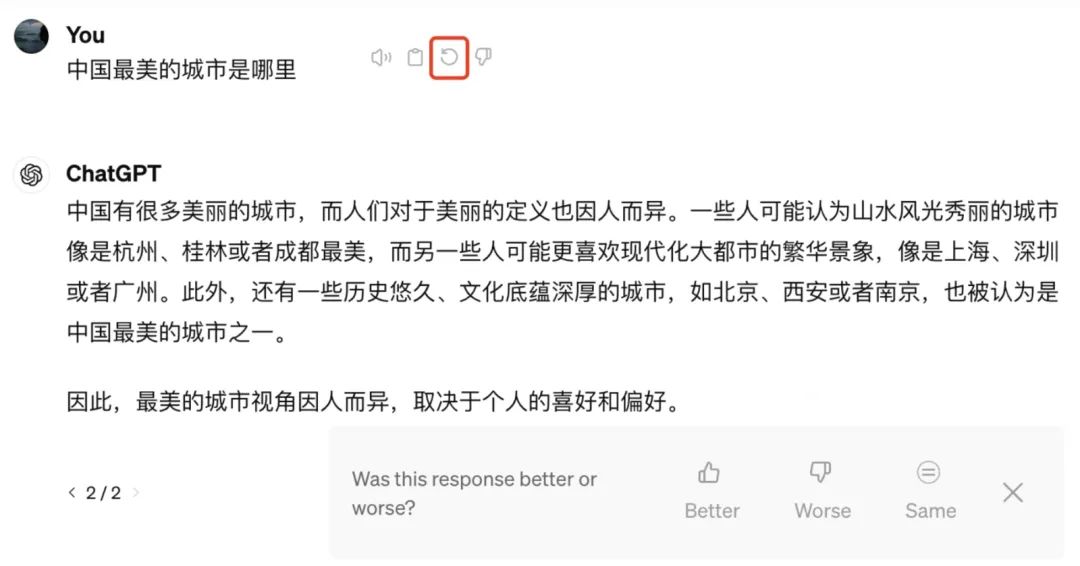
模型训练的最后一个阶段,也就是人类反馈的强化学习,我们也称之为RLHF。之前都是相当于是给一个输入和输出的一个过程,RLHF是输出结果的对比。它的一个原理就是问答结果概率的提升或下降,比如说一个问题是中国最美的城市在哪?一个上海一个北京。你如果给上海点了点赞,那他以后就会提高输出上海的一个概率,然后从而降低北京的输出的这样的一个概率,这就是它的一个最基本的一个原理。

在ChatGPT中也可以找到这样的一个入口,相当于我们每个人也为ChatGPT做这样的一个步骤。比如说你输入:中国最美城市,然后点击重新生成。在第二次生成的一个回答当中就会有这样的一个入口是询问你我现在这个回答是相较于第一个回答是更好了,更差了还是一样?那你这个如果做出反馈的话,你这笔数据就会给ChatGPT去做第三步RLHF。
5. 训练三阶段对比
再对比一下这三个阶段。第一个阶段就是预训练,第二个阶段就是微调,第三个阶段也就是RLHF。在第一个阶段我们也称之为训练基座模型,第二阶段和第三阶段我们称之为对齐。那么对齐的是什么?也就是我们人类的一个需求,以及我们人类的一些偏好。
同时他的训练数据上面也会有略有一些区别,第一个阶段他训练数据就是我在网络上面能抓到什么样的资料,然后都都丢进去掉。所以他是自己在学习的,是self supervisor learning自监督的一个学习;第二个阶段它的一个输入输出的资料是有这种user和AI这种标识符的,它是由人类进行一个介入的一个学习的,所以叫监督学习;第三个阶段它其实是这个回答的一个对比,他就是算是一个增强式学习,哪个回答更好一点,哪个回答更差一点这样子。

六、Chatgpt可以做什么?
我们训练好之后,ChatGPT可以用来做什么?我们把这个问题丢给ChatGPT,可以看他的回答一下。然后他的回答是他觉得他自己的核心能力有对话信息检索、文本理解,像这个图片生成,代码编写等等。

Chatgpt能做挺多的,我觉得它比较牛的一些功能是,第一个是编程。编程可能不仅仅是把如何编的给你展示出来,更重要是它是有集成一个python的一个编辑器。然后是可以直接直接去把这个代码给编译出来,然后去把最终结果也生成出来。当然你也可以通过写代码形式去生成一些图之类的。
然后第二个就是通过prompt的一些角色扮演。比如我们就他预设,他是一个面试的一个专家。然后我们把面试的一些文字的记录丢给他,然后他就会根据我们这些记录去给我们一些面试相关的一些建议。然后通过这种方式来进行面试复盘,这个方式也是非常有效的。

还有非常多其他的功能,比如说像通过ChatGPT可以生成文字云,然后也可以总结文章的重点,写工作总结,绘制图表,分类新闻等。
分类新闻这一点其实也挺厉害的,这个点是我们之现在接触的一个业务上面,你给它预设几个新闻类别,我们现在的文章我们可能有八卦、财经、政治等等,然后你现在就是输入一篇文章,说去帮我根据以上我的一些所定义的分类,把这篇这个新闻给我一个分类,它属于哪一类。然后他就会跟你讲,这个就直接把之前那个需要一些开发的一些流程就给就给省略掉了。
七、ChatGPT的缺陷
ChatGPT也不是万能的,它也有它自己的一些缺陷:
- 幻觉(胡说八道的能力)。最大的缺陷我认为是他的幻觉,也就是胡说八道的能力。其实你了解ChatGPT的原理,你就可以理解为它为什么会有这样的一个胡说八道的。因为它本质上它是在预测下一个字的文字接龙游戏,他是在做这样的一个事情,所以它是不保证下一个,不保证我们整体的一个真实性的。我只保证我下一个字的一个概情况,对不对?所以就出现像律师他用ChatGPT来写,就是有一些假的一些案例。那像马斯克也说,我们需要的是说真话的GPT。
- 过时的数据。训练是有时间差的,ChatGPT3.5的数据只更新到2022年11月份,到现在基本上两年的gap,当然这个部分也可以通过一些联网,RAG知识库的一些方式来部分的解决,我觉得联网这部分kimi做的挺好的。
- 有限的上下文窗口。ChatGPT3.5的上下文只支持大概3000个词的信息,也就是说你跟他聊着天,我们之前聊天信息突然忘记了,他是一个健忘的朋友或者助手。
当然,AI一天,人间十年,假以时日,以上三点缺陷我相信在未来的某个时间点,它都可以一定程度上进行突破!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
3.LLM
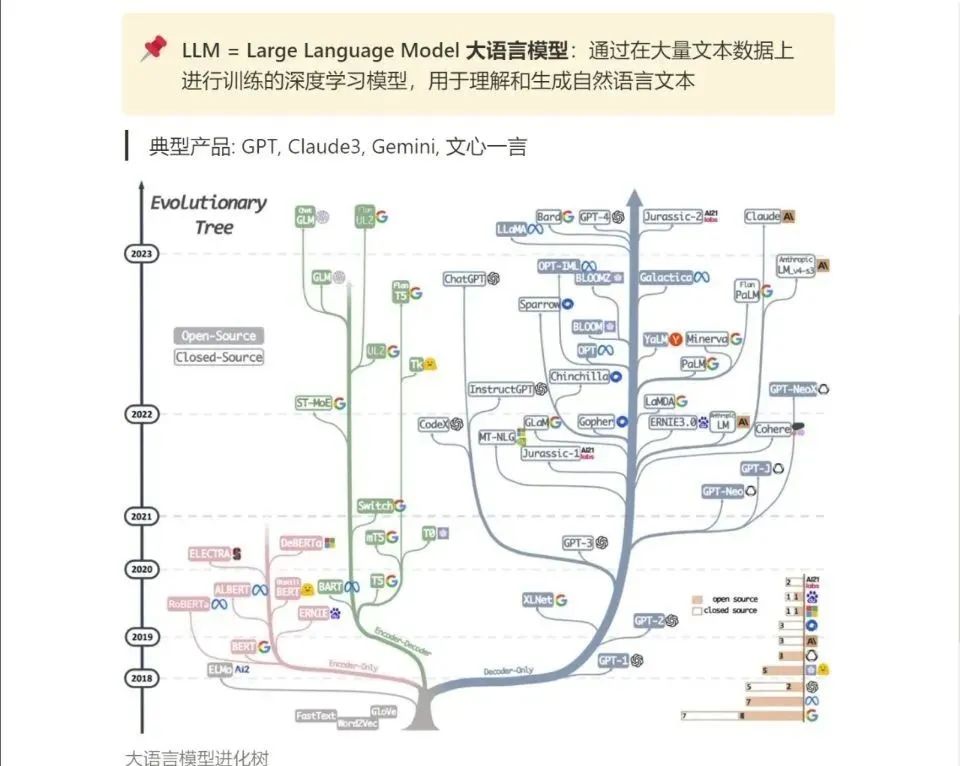
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









