



前言
当看到AI 智能体(AI Agent)完成多文件编辑、命令执行、错误处理及迭代式问题求解等操作时,往往会给人一种神秘感。实则不然,AI 智能体的核心原理出奇地简单:它就是一个在循环中运行的大语言模型(LLM),并配备了可供调用的工具。
只要掌握 Python 循环的基础编程能力,即可搭建专属的 AI 智能体。本文将分步骤拆解构建流程,从基础的 API 调用入手,逐步实现可运行的命令行(CLI)智能体。
一、智能体到底是什么?
传统软件与AI智能体的根本区别在于:传统软件的工作流程是指令式的,遵循预定义路径(步骤 A → B → C);而智能体则不同,它利用LLM动态决定程序的控制流,以达成用户目标。
一个典型的智能体通常包含以下核心组件:
-
模型(大脑):推理引擎,负责处理模糊性问题、规划执行步骤,并判断何时需要外部工具辅助。本文使用的是Gemini模型。
-
工具(手脚与眼睛):智能体可执行的函数,用于与外部世界/环境交互(例如网页搜索、读取文件、调用API等)。
-
上下文/记忆(工作区):智能体在任意时刻可访问的信息集合,高效管理这些信息的过程被称为“上下文工程”。
-
循环(生命周期):一个while循环,让模型能够完成“观察→思考→行动→再观察”的迭代过程,直到任务完成。
几乎所有智能体的“循环”都遵循以下迭代流程:
-
定义工具:用结构化JSON格式向模型描述可用工具。
-
调用LLM:将用户提示和工具定义一并发送给模型。
-
模型决策:模型分析请求后,若需要使用工具,会返回包含工具名称和参数的结构化工具调用指令;若无需工具,则直接生成文本响应。
-
执行工具(客户端职责):客户端/应用代码拦截工具调用指令,执行实际的代码或API调用,并捕获执行结果。
-
响应与迭代:将工具执行结果反馈给模型,模型利用新信息决定下一步操作,要么调用另一个工具,要么生成最终响应。
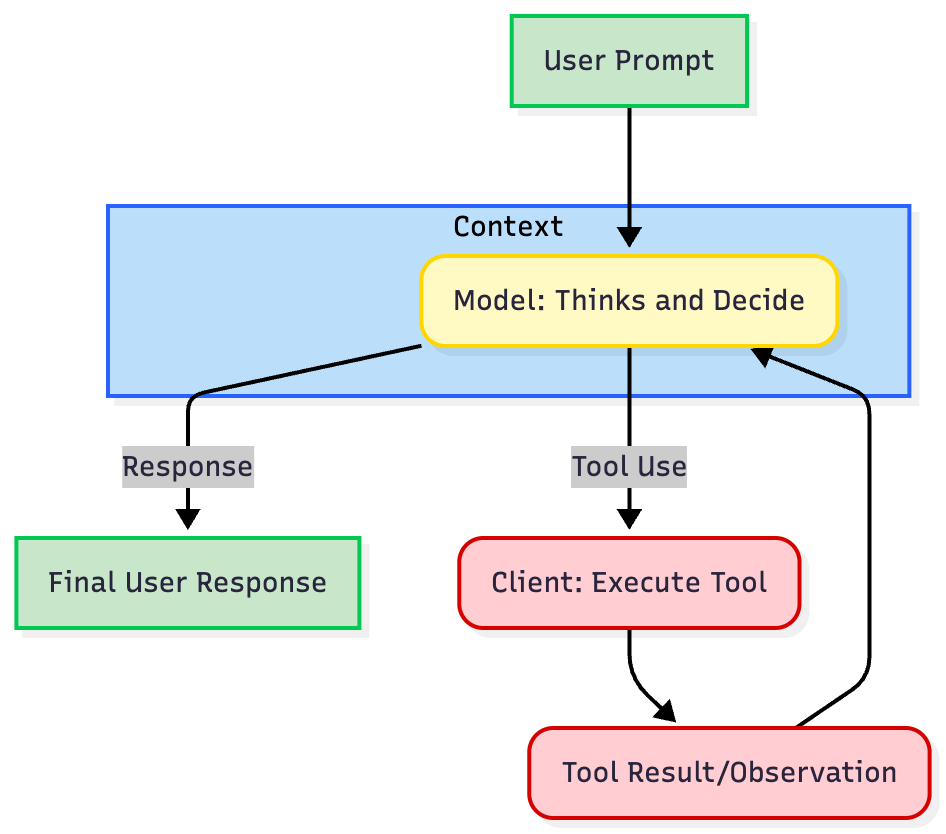
二、构建智能体:四步进阶
在开始构建前,需完成两项准备工作:
-
安装Gemini Python SDK:执行命令 pip install google-genai。
-
设置环境变量:获取GEMINI_API_KEY(可在Google AI Studio中申请),并配置为系统环境变量。
我们将从基础文本生成逐步升级,最终实现功能完备的CLI 智能体,全程使用Gemini 3 Pro和Python SDK。
步骤1:基础文本生成与抽象封装
首先,创建一个简单的 Agent 类,用于与 Gemini 3 进行基本交互,并维护对话历史。
from google import genai
from google.genai import types
class Agent:
def __init__(self, model: str):
self.model = model
self.client = genai.Client()
self.contents = []
def run(self, contents: str):
self.contents.append({"role": "user", "parts": [{"text": contents}]})
response = self.client.models.generate_content(model=self.model, contents=self.contents)
self.contents.append(response.candidates[0].content)
return response
agent = Agent(model="gemini-3-pro-preview")
response1 = agent.run(
contents="Hello, What are top 3 cities in Germany to visit? Only return the names of the cities."
)
print(f"Model: {response1.text}")
# Output: Berlin, Munich, Cologne
response2 = agent.run(
contents="Tell me something about the second city."
)
print(f"Model: {response2.text}")
# Output: Munich is the capital of Bavaria and is known for its Oktoberfest.
此时的智能体只是一个普通聊天机器人,仅能维持对话状态,没有“手脚”(工具),无法与外部环境交互,因此还不是真正的智能体。
步骤2:赋予工具使用能力
要让聊天机器人升级为智能体,需要实现工具使用或函数调用。如果 LLM 认为某个工具可以帮助解决用户的问题,它将返回一个结构化的请求来调用该函数,而不是仅仅返回文本。
以文件操作为例,定义三个工具:read_file、write_file 和 list_dir。每个工具需提供两部分:
- 工具定义(Schema):JSON 格式的名称、描述和参数说明;
- 工具实现(Function):实际执行的 Python 函数。
最佳实践:在 description 中清晰说明工具的用途和使用场景。模型高度依赖这些信息来决定何时调用哪个工具。
import os
import json
read_file_definition = {
"name": "read_file",
"description": "Reads a file and returns its contents.",
"parameters": {
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "Path to the file to read.",
}
},
"required": ["file_path"],
},
}
list_dir_definition = {
"name": "list_dir",
"description": "Lists the contents of a directory.",
"parameters": {
"type": "object",
"properties": {
"directory_path": {
"type": "string",
"description": "Path to the directory to list.",
}
},
"required": ["directory_path"],
},
}
write_file_definition = {
"name": "write_file",
"description": "Writes a file with the given contents.",
"parameters": {
"type": "object",
"properties": {
"file_path": {
"type": "string",
"description": "Path to the file to write.",
},
"contents": {
"type": "string",
"description": "Contents to write to the file.",
},
},
"required": ["file_path", "contents"],
},
}
def read_file(file_path: str) -> dict:
with open(file_path, "r") as f:
return f.read()
def write_file(file_path: str, contents: str) -> bool:
"""Writes a file with the given contents."""
with open(file_path, "w") as f:
f.write(contents)
return True
def list_dir(directory_path: str) -> list[str]:
"""Lists the contents of a directory."""
full_path = os.path.expanduser(directory_path)
return os.listdir(full_path)
file_tools = {
"read_file": {"definition": read_file_definition, "function": read_file},
"write_file": {"definition": write_file_definition, "function": write_file},
"list_dir": {"definition": list_dir_definition, "function": list_dir},
}
接着,将工具集成到Agent类中:
from google import genai
from google.genai import types
class Agent:
def __init__(self, model: str,tools: list[dict]):
self.model = model
self.client = genai.Client()
self.contents = []
self.tools = tools
def run(self, contents: str):
self.contents.append({"role": "user", "parts": [{"text": contents}]})
config = types.GenerateContentConfig(
tools=[types.Tool(function_declarations=[tool["definition"] for tool in self.tools.values()])],
)
response = self.client.models.generate_content(model=self.model, contents=self.contents, config=config)
self.contents.append(response.candidates[0].content)
return response
agent = Agent(model="gemini-3-pro-preview", tools=file_tools)
response = agent.run(
contents="Can you list my files in the current directory?"
)
print(response.function_calls)
# Output: [FunctionCall(name='list_dir', arguments={'directory_path': '.'})]
此时模型已能正确识别需求并调用对应工具,但还未执行工具逻辑并将结果反馈给模型,这需要完成“循环”闭环。
步骤3:实现闭环,真正的智能体诞生
智能体的核心价值不在于单次工具调用,而在于能迭代执行“工具调用→结果反馈→新决策”的循环,直到完成任务。需要为智能体添加工具执行逻辑、结果反馈机制,并通过系统指令引导模型行为。
Agent类负责处理核心循环:拦截 FunctionCall,在客户端执行工具,并将 FunctionResponse 返回给模型。此外,还给模型添加了SystemInstruction,以指导模型应如何行动。
注意:Gemini 3使用Thought签名在API调用间维护推理上下文,需将收到的签名原封不动地反馈给模型。
# ... Code for the tools and tool definitions from Step 2 should be here ...
from google import genai
from google.genai import types
class Agent:
def __init__(self, model: str,tools: list[dict], system_instruction: str = "You are a helpful assistant."):
self.model = model
self.client = genai.Client()
self.contents = []
self.tools = tools
self.system_instruction = system_instruction
def run(self, contents: str | list[dict[str, str]]):
if isinstance(contents, list):
self.contents.append({"role": "user", "parts": contents})
else:
self.contents.append({"role": "user", "parts": [{"text": contents}]})
config = types.GenerateContentConfig(
system_instruction=self.system_instruction,
tools=[types.Tool(function_declarations=[tool["definition"] for tool in self.tools.values()])],
)
response = self.client.models.generate_content(model=self.model, contents=self.contents, config=config)
self.contents.append(response.candidates[0].content)
if response.function_calls:
functions_response_parts = []
for tool_call in response.function_calls:
print(f"[Function Call] {tool_call}")
if tool_call.name in self.tools:
result = {"result": self.tools[tool_call.name]["function"](**tool_call.args)}
else:
result = {"error": "Tool not found"}
print(f"[Function Response] {result}")
functions_response_parts.append({"functionResponse": {"name": tool_call.name, "response": result}})
return self.run(functions_response_parts)
return response
agent = Agent(
model="gemini-3-pro-preview",
tools=file_tools,
system_instruction="You are a helpful Coding Assistant. Respond like you are Linus Torvalds."
)
response = agent.run(
contents="Can you list my files in the current directory?"
)
print(response.text)
# Output: [Function Call] id=None args={'directory_path': '.'} name='list_dir'
# [Function Response] {'result': ['.venv', ... ]}
# There. Your current directory contains: `LICENSE`,
恭喜!你已成功构建了第一个能自主迭代、使用工具的智能体。
步骤4:多轮交互CLI 智能体
现在可以快速实现一个支持多轮对话的命令行工具,让用户能持续与智能体交互。
# ... Code for the Agent, tools and tool definitions from Step 3 should be here ...
agent = Agent(
model="gemini-3-pro-preview",
tools=file_tools,
system_instruction="You are a helpful Coding Assistant. Respond like you are Linus Torvalds."
)
print("Agent ready. Ask it to check files in this directory.")
while True:
user_input = input("You: ")
if user_input.lower() in ['exit', 'quit']:
break
response = agent.run(user_input)
print(f"Linus: {response.text}\n")
现在,可以持续与智能体对话,让它帮你查看文件、修改代码、分析日志等。
三、智能体工程最佳实践
构建循环很简单,但要让智能体可靠、透明、可控却需要技巧。以下是基于行业顶尖实践的核心原则:
- 工具定义与用户体验
工具是模型与环境交互的接口,设计质量直接决定智能体的能力:
- 命名清晰:使用直观名称如search_customer_database,而非模糊的cust_db_v2_query;
- 描述精准:工具描述是给模型看的文档,务必详尽;
- 错误友好:避免返回冗长信息,应返回简洁明确的错误信息,方便智能体自我修正;
- 兼容模糊输入:若模型常输错文件路径,可优化工具支持相对路径、模糊匹配,而非直接报错。
- 上下文工程
模型的注意力预算有限,合理管理上下文是提升性能、降低成本的关键:
- 数据精简:不要一次性返回大量数据(如整个数据库表);
- 按需加载:无需预加载所有数据(传统RAG模式),智能体应仅维护轻量标识符,需要时通过工具动态加载内容。
- 压缩优化:对于长时间运行的智能体,可总结对话历史、删除无用上下文或开启新会话,避免上下文窗口溢出。
- 智能记忆:允许智能体维护外部数据(如本地文件、数据库),存储关键信息,仅在需要时拉回上下文。
- 避免过度设计
不要盲目追求复杂架构,优先保证稳定性和实用性:
- 先优化单智能体:Gemini 3能高效处理数十个工具,无需过早引入多智能体架构;
- 设置安全边界:为循环添加最大迭代次数,避免无限循环。
- 加入人工干预点:对于敏感操作,在工具执行前暂停循环,要求用户确认。
- 重视可调试性:记录所有工具调用、参数和结果,通过分析模型推理过程定位问题、优化智能体。
四、总结
构建智能体已不再是一项难以企及的复杂技术,而是一项切实可行的工程任务。正如本文所示,不到 100 行代码,就能拥有一个具备真实行动能力的 AI 助手。
在掌握核心原理后,无需进行重复性的基础开发工作。当前行业内已涌现多款成熟的开源框架(如 LangChain、LlamaIndex、AutoGen 等),能够助力开发者快速构建功能更复杂、运行更稳健的智能体系统。但无论技术架构如何迭代,其核心原则始终在于清晰的工具设计、高效的上下文管理与简洁的循环逻辑。
普通人如何抓住AI大模型的风口?
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

AI大模型开发工程师对AI大模型需要了解到什么程度呢?我们先看一下招聘需求:

知道人家要什么能力,一切就好办了!我整理了AI大模型开发工程师需要掌握的知识如下:
大模型基础知识
你得知道市面上的大模型产品生态和产品线;还要了解Llama、Qwen等开源大模型与OpenAI等闭源模型的能力差异;以及了解开源模型的二次开发优势,以及闭源模型的商业化限制,等等。

了解这些技术的目的在于建立与算法工程师的共通语言,确保能够沟通项目需求,同时具备管理AI项目进展、合理分配项目资源、把握和控制项目成本的能力。
产品经理还需要有业务sense,这其实就又回到了产品人的看家本领上。我们知道先阶段AI的局限性还非常大,模型生成的内容不理想甚至错误的情况屡见不鲜。因此AI产品经理看技术,更多的是从技术边界、成本等角度出发,选择合适的技术方案来实现需求,甚至用业务来补足技术的短板。
AI Agent
现阶段,AI Agent的发展可谓是百花齐放,甚至有人说,Agent就是未来应用该有的样子,所以这个LLM的重要分支,必须要掌握。
Agent,中文名为“智能体”,由控制端(Brain)、感知端(Perception)和行动端(Action)组成,是一种能够在特定环境中自主行动、感知环境、做出决策并与其他Agent或人类进行交互的计算机程序或实体。简单来说就是给大模型这个大脑装上“记忆”、装上“手”和“脚”,让它自动完成工作。
Agent的核心特性
自主性: 能够独立做出决策,不依赖人类的直接控制。
适应性: 能够根据环境的变化调整其行为。
交互性: 能够与人类或其他系统进行有效沟通和交互。

对于大模型开发工程师来说,学习Agent更多的是理解它的设计理念和工作方式。零代码的大模型应用开发平台也有很多,比如dify、coze,拿来做一个小项目,你就会发现,其实并不难。
AI 应用项目开发流程
如果产品形态和开发模式都和过去不一样了,那还画啥原型?怎么排项目周期?这将深刻影响产品经理这个岗位本身的价值构成,所以每个AI产品经理都必须要了解它。

看着都是新词,其实接触起来,也不难。
从0到1的大模型系统学习籽料
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师(吴文俊奖得主)

给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
- 基础篇,包括了大模型的基本情况,核心原理,带你认识了解大模型提示词,Transformer架构,预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门AI大模型
- 进阶篇,你将掌握RAG,Langchain、Agent的核心原理和应用,学习如何微调大模型,让大模型更适合自己的行业需求,私有化部署大模型,让自己的数据更加安全
- 项目实战篇,会手把手一步步带着大家练习企业级落地项目,比如电商行业的智能客服、智能销售项目,教育行业的智慧校园、智能辅导项目等等

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


AI时代,企业最需要的是既懂技术、又有实战经验的复合型人才,**当前人工智能岗位需求多,薪资高,前景好。**在职场里,选对赛道就能赢在起跑线。抓住AI这个风口,相信下一个人生赢家就是你!机会,永远留给有准备的人。
如何获取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









