






大语言模型LLM的推理引擎经过一年时间发展,现在主流方案收敛到了开源的vLLM和半闭源的TensorRT-LLM。
TRT-LLM基于C++开发,有NV算子开发黑魔法加持,在其重点支持的场景里,性能可以做到极致。vLLM基于python开发,代码简洁架构清晰,和开源互动紧密,灵活地满足了二次开发的需求。比如,最近流行的分离式架构,比如Sarathi-Serve,Mooncake等都是基于vLLM。
vLLM时代和时代中的vLLM
纵观古今,vLLM算是现象级的开源项目。这个自UCB的项目,从一篇Paged Attention技术论文作为起点,逐渐演化为惠及全球大模型开发者的开源产品。时势造英雄,英雄造时势,两个原因相辅相成,成就了vLLM。
-
技术创新:Paged Attention(PA)创新性解决了高吞吐场景下的性能问题,vLLM率先享受了这项技术进步的红利,带来了初始流量。
-
兼顾性能和易用性:vLLM的PA kernel虽然用cuda开发,但是其余部分都是pytorch开发,包括Batch调度、模型定义、并行推理等。相比TRT-LLM来说,虽然引入了PyTorch的overhead,但是显著增加了灵活性,降低了开发者参与的门槛。
-
开源社区经营:继承自UCB优秀传统,vLLM开源社区经营方式很成熟。每年都有summit,定时同步自己的roadmap。这让vLLM从力变场,成为汇聚模型开发者、模型使用者、技术创新者的平台。即使TRT-LLM性能更优,仍然无法撼动其社区属性。
-
多硬件支持:vLLM支持AMD、Intel等厂商的GPU。这也是TRT-LLM难以触及的禁区。
尽管vLLM已经非常成功了,对大模型发展的贡献也是史诗级的。正如吕布之后后,人皆称赛吕布;vLLM开源之后,人人皆可“自研”LLM推理框架。
但是以史为鉴,我认为大模型推理引擎的发展仍是初级阶段。
就像当年深度学习框架发展经历了cuda-convnet(2012)-> Caffe (2014)-> TensorFlow(2016)-> PyTorch(2017)长达五年跨度若干的阶段,大模型推理框架一步到位也不太现实。vLLM有点像当年的Caffe阶段,比如下面几个方面:
-
高性能:Caffe率先做到了在GPU上高性能运行,它写了大量cuda kernel,比如im2col后调用cuBLAS来优化卷积算子。同时很早支持数据并行方式多卡训练。其性能优势让很多人从Theano切换到Caffe,正如vLLM的Paged Attention打开了吞吐天花板。
-
开源影响力:工程和学术界大量model zoo都基于caffe开发,比如很多年的ImageNet比赛的模型都用Caffe,其中就包括CVPR 16’ best paper Resnet。和vLLM现在的地位颇为相似。
-
学术机构维护:Caffe和vLLM都诞生于UCB实验室项目。Caffe的主程Yangqing Jia后来去Facebook,写了Caffe2后来合并进了PyTorch项目。
随着深度学习需求的升级,导致Caffe被更灵活和更高效设计替代。原因是多方面的,首先,更复杂的模型架构,Caffe就很难定义其计算图,比如循环架构的LSTM。另外,随着竞争加剧,实验室方式维护开源项目难以为继,后期的TensorFlow和PyTorch成功都离不开大公司的投入与推广。种种原因导致Caffe淡出历史舞台,但是Caffe的影响还是广泛存在于现在的深度学习基础设施之中。
vLLM今天很可能面临着和当年Caffe相似的局面。在Caffe时代,深度学习框架完成了算子库和框架解耦,Caffe从自己实现各种算子进化成调用cuDNN。vLLM也重演了类似的演化,现在vLLM开始利用FlashInfer和xformers作为算子库,最开始PA的cuda代码渐渐淡出。
SGLang:从LLM Inference到LLM Programs
vLLM主要考虑简单的单轮对话形式与LLM进行交互,输入prompt,Prefill+Decode计算后输出。**随着大模型应用发展深入,LLM的使用方式正在发生深刻的变化。**比如,LLM参与multi-round planning、reasoning和与外部环境交互等复杂场景,需要LLM通过工具使用、多模态输入以及各种prompting techniques,比如self-consistency,skeleton-of-thought,and tree-of-thought等完成。这些过程都不是简单的单轮对话形式,通常涉及一个prompt输出多个结果,或者生成内容包含一些限制,比如json格式或者一些关键词。
这些模式的涌现标志着我们与LLMs交互方式的转变,从简单的聊天转向更复杂的程序化使用形式,这意味着使用类似编程语言的方式来控制LLMs的生成过程,称为LM Programs。LM Programs有两个共同特性:(1)LM Program通常包含多个LLM调用,这些调用之间穿插着控制流。这是为了完成复杂任务并提高整体质量所必需的。(2)LM Program接收结构化输入并产生结构化输出。这是为了实现LM Program的组合,并将其集成到现有的软件系统中。
最近广受关注的工作SGLang正是瞄准LLM Programs设计的。SGLang这个工作去年就发布了,当时其实就引起了很多关注,其RadixAttention共享KVCache Prefix的优化,也被最近的各种新型推理引擎所采用,比如MoonCake,MemServe等之中。最近SGLang的论文升级了一个版本,也更新了性能数据,效果直逼TRT-LLM引起了不少轰动。
SGLang作者也是来自UCB的团队的青年才俊,很多人都是vLLM的作者,UCB在大模型时代,仍然是Computer System领域的宇宙中心。Lianming Zheng是自动并行系统Alpa的一作,Sheng Ying是FlexGen、S-LoRA的一作,还有Liangsheng Yin是SJTU ACM班的,现在在 UCB 暑研, https://www.zhihu.com/people/e13d1cefdc0ed34fa887913f8b03c7c3 之前在Meituan开发LLM推理引擎,经验丰富。
https://github.com/sgl-project/sglang/
知乎上已经有了新鲜分析,https://zhuanlan.zhihu.com/p/711167552
SGLang采用了编译器方式的设计。当输入和输出是多对多的,就有很多Lazy方式来优化调度的空间,这就很自然的映射到编译器设计,可以分frontend和backend两部分。

前端定义一种DSL,嵌入在Python中。下图展示了一个使用分支-解决-合并提示方法评估关于图像的论文的LLM Program。函数multi_dimensional_judge接受三个参数:s、path和essay。s管理提示状态,path是图像文件路径,essay是论文文本。可以使用+=操作符将新字符串和SGLang原语附加到状态s中以供执行。首先,函数将图像和论文添加到提示中。然后,它使用select检查论文是否与图像相关,并将结果存储在s[“related”]中。如果相关,提示会分成三个副本进行不同维度的并行评估,使用gen将结果存储在f[“judgment”]中。接着,它合并判断结果,生成总结,并评分ABCD。最后,它按照正则表达式约束regex定义的模式,以JSON格式返回结果。
SGLang后端执行时极大地简化了这一程序,如果使用类似OpenAI API的接口编写等效程序需要多出2.1倍的代码。

SGLang的后端Runtime有三个核心创新优化点,我下面分别介绍:
1. Efficient KV Cache Reuse with RadixAttention
上图Figure 2钟,SGLang程序可以通过“fork”原语链接多个生成调用并创建并行副本。此外,不同的程序实例通常共享一些公共部分(例如,系统提示)。这些情况在执行过程中创建了许多共享提示前缀,从而提供了许多重用KV缓存的机会。下图Figure 9所示,展示了各种KVCache Prefix共享的场景。
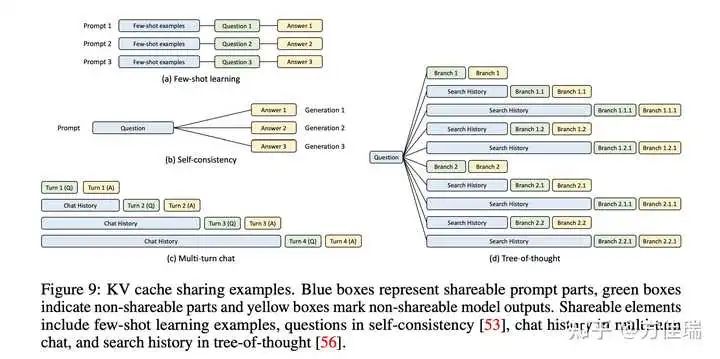
SGLang V1版本论文就提出了RadixAttention,这是一种在运行时自动和系统化重用KVCache的新技术。与现有系统在生成请求完成后丢弃KV缓存不同,我们的系统在RadixTree中保留prompt和生成结果的KVCache,实现高效的前缀搜索、重用、插入和驱逐。SGLang用LRU驱逐策略和缓存感知调度策略,以提高缓存命中率。
Mooncake也有相似的KVCache Prefix Sharing优化,不过场景略有差异,mooncake是在不同用户请求间很多共享前缀,SGLang还是在一个Program内。大家可以参考MoonCake中的Prefill Pool设计,RadixAttention和Hash设计有千丝万缕联系。我猜测,之前大家没想到请求间Prefix共享机会那么大,实际上对于RAG+LLM方式使用,请求间前缀相同概率挺大的,SGLang提出的RadixAttention很快变成了非常通用的设计,不止限于LLM Program中。
方佳瑞:Mooncake阅读笔记:深入学习以Cache为中心的调度思想,谱写LLM服务降本增效新篇章
2. Efficient Constrained Decoding with Compressed Finite State Machine
在LM Programs中,用户通常希望将模型的输出限制为遵循特定格式,如JSON模式。这可以提高可控性和鲁棒性,并使输出更易于解析。SGLang通过正则表达式提供了一个regex参数来强制执行这些约束,这在许多实际场景中已经足够表达。现有系统通过将正则表达式转换为有限状态机(FSM)来支持这一点。在解码过程中,它们维护当前的FSM状态,从下一个状态检索允许的token,并将无效token的概率设置为零,逐个token解码。
Constrained Decoding我去年也有关注,微软的https://github.com/guidance-ai/guidance算是比较早期工作,SGLang也引用了。不过SGLang做了一些进一步的优化。
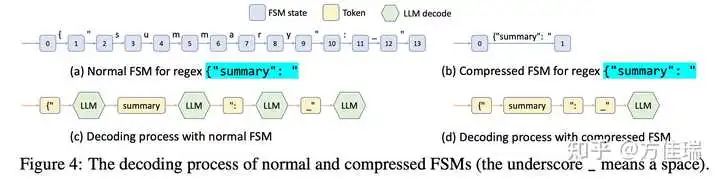
逐个token的方法在有机会一次性解码多个token时效率低下。例如,前面Figure 2中的常量序列{“summary”: "在图4(c)所示的正常解码过程中跨越多个token,需要多个解码阶段,尽管在解码时只有一个有效的下一个token。因此,整个序列可以在一个步骤(即前向传递)中解码。然而,现有系统只能一次解码一个token,因为现有系统中FSM与模型运行器之间缺乏集成,无法进行多token处理,导致解码速度慢。
SGLang通过创建一个带有压缩FSM的快速约束解码运行时来克服这一限制。该运行时分析FSM并将FSM中相邻的单一转换边压缩为单一边,如图Figure(b)所示,使其能够识别何时可以一起解码多个token。在Figure 4(d)中,压缩转换边上的多个token可以在一次前向传递中解码,这大大加速了解码过程。它也是通用的,适用于所有正则表达式。
3. Efficient Endpoint Calling with API Speculative Execution
上述优化RadixAttention和Constrained Decoding还是针对模型是白盒情况。如果调用的模型是OpenAI这种黑盒API,SGLang通过使用推测执行来加速多调用SGLang程序的执行并降低API成本。
例如,一个程序可能要求模型通过多调用模式生成一个角色的描述:s += context + “name:” + gen(“name”, stop=“\n”) + “job:” + gen(“job”, stop=“\n”)。简单来说,这两个gen原语对应于两次API调用,这意味着用户需要为上下文支付两次输入令牌费用。在SGLang中,我们可以在第一次调用时启用推测执行(Speculative Execution),并让它忽略停止条件继续生成几个额外的令牌。解释器保留这些额外的生成输出,并与后面的原语进行匹配和重用。在某些情况下,通过提示工程,模型可以高准确度地匹配模板,从而节省我们一次API调用的延迟和输入成本。
文章没细讲遇到什么样的程序描述会开启Speculative Execution,因为如果推测失败,反而多消耗了token。我觉得这一章节抛砖引玉,强调了SGLang不只是推理引擎,还可以做作为推理引擎的上层调用框架。有点类似llvm和机器码执行器之间的关系。
令人惊艳的SGLang性能
使用RadixAttention和Constrained Decoding可以减少LLM Program的计算量,这些优化也是和vLLM的PA、Continous Batching兼容的。如果你对LLM的用法可以使用SGLang定义成LLM Program,在业务中是可以显著获得收益的。
不过如果还是展示SGLang V1论文的场景格局就小了。SLGang在不用RadixAttention和Constrained Decoding优化前提下,相比vLLM有明显加速,而且性能接近TRT-LLM。我这里贴了博客中的H100的性能,有些case甚至远超TRT-LLM。SLGang团队跟我说原因在于软件调度写得好,是实打实的更好的工程实现的结果。这个结果确实非常惊艳的,我没有实测,不过听说NVIDIA是可以复现这个结果的。这也说明现有的推理引擎vLLM有很大的重构提升空间。
https://lmsys.org/blog/2024-07-25-sglang-llama3/

总结
大模型推理引擎经过一年多发展,进入了一个关键的调整期。一方面,针对定制集群的分离式架构出现,很多业务方自己定制更复杂的并行和调度方案。另一方面,LLM的用法更加复杂,催生了LLM Programs使用范式。此外,非NVIDIA的NPU如雨后春笋般涌现,它们独特的硬件特性亟待新的系统架构来充分挖掘与利用。
在这一背景下,以vLLM为代表的开源LLM推理引擎正面临着前所未有的进化压力。而SGLang此次的升级,不仅从框架层面揭示了vLLM仍有巨大的提升潜力,也对LLM场景需求进行了一些探索,值得大家关注。















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









