






随着基础模型规模不断扩大,传统微调方法计算成本高。LoRA 技术应运而生,它能高效微调基础模型且计算开销小。这一技术在多个领域广泛应用,对推动人工智能发展、提升模型适应性意义重大。
本文综述了 LoRA 技术在基础模型中的应用,介绍了其技术基础如参数效率增强、秩适应策略等,探讨了在持续学习、联邦学习等前沿领域的发展,列举了在自然语言处理、计算机视觉等多领域的应用,分析了面临的理论、架构、计算等方面的挑战,并指出了未来研究方向。
摘要&解读
基础模型(在多样、大规模数据集上训练的大规模神经网络)的快速发展引发了人工智能领域的变革,在自然语言处理、计算机视觉和科学发现等多个领域实现了前所未有的进步。然而,这些模型通常具有数十亿甚至数万亿的参数,在适应特定下游任务时带来了巨大挑战。低秩适应(LoRA)作为一种极具前景的方法应运而生,它提供了一种参数高效的机制,能够以极小的计算开销对基础模型进行微调。本综述首次全面回顾了 LoRA 技术在从大型语言模型到一般基础模型的应用,涵盖了低秩适应在多个领域的最新技术基础、新兴前沿和应用。最后,本文讨论了在理论理解、可扩展性和鲁棒性方面的关键挑战和未来研究方向。本综述为从事高效基础模型适应的研究人员和从业者提供了宝贵资源。
-
研究背景: 基础模型规模庞大,传统全参数更新的微调方法在计算资源上难以满足需求,因此催生了参数高效微调技术,LoRA 便是其中一种重要方法,旨在解决基础模型适应特定任务时的计算挑战。
-
技术贡献:
-
首次对 LoRA 技术在基础模型领域进行全面综述,涵盖多领域应用。
-
系统分析了 LoRA 的技术基础,包括参数效率策略、秩适应机制等。
-
探索了 LoRA 在多个新兴前沿领域的发展,如与专家混合等架构创新。
-
实现设计:
-
通过将更新矩阵约束为低秩,利用矩阵分解减少参数学习量。
-
采用特定的参数初始化策略和微调过程,冻结原始权重,仅训练低秩矩阵。
-
运用多种技术实现参数效率增强,如参数分解、剪枝、冻结与共享、量化等,并通过不同方法优化秩适应。
-
关键词:基础模型;大型语言模型;低秩适应;参数高效微调;多任务学习

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈
1 引言
基础模型代表了人工智能领域的范式转变,其中在广泛而庞大的数据集上进行预训练的大规模神经架构建立了可泛化的表示框架,能够适应广泛的下游应用[1,2]。这些模型涵盖多个领域,包括自然语言处理(如 GPT-3.5[3]、LLaMA[4])、计算机视觉(如 Swin Transformer[5]、MAE[6]、SAM[7])、语音处理(如 Wav2vec2[8]、Whisper[9])、多模态学习(如 Stable Diffusion[10]、DALL·E 2[11])以及科学应用(如 AlphaFold[12]、ChemBERTa[13]、ESM-2[14])。
基础模型的特点是其前所未有的规模,参数数量可达数十亿甚至数万亿,并且具有涌现特性——即无需明确训练就自发产生的能力[1]。这些架构已成为现代人工智能系统的基本构建块,在不同领域实现了突破性的性能[1,2]。虽然这些模型具有广泛的能力,但通过微调进行特定任务的优化对于增强泛化能力[15]、促进算法公平性[16]、实现定制化[17]以及符合伦理和社会标准[18,19]仍然至关重要。然而,它们的规模带来了巨大的计算挑战,特别是在训练和微调所需的计算资源方面[20]。尽管传统的涉及全参数更新的微调方法在各种任务中已证明有效[21,22],但它们的计算需求往往使其在基础模型中不切实际[23,24]。
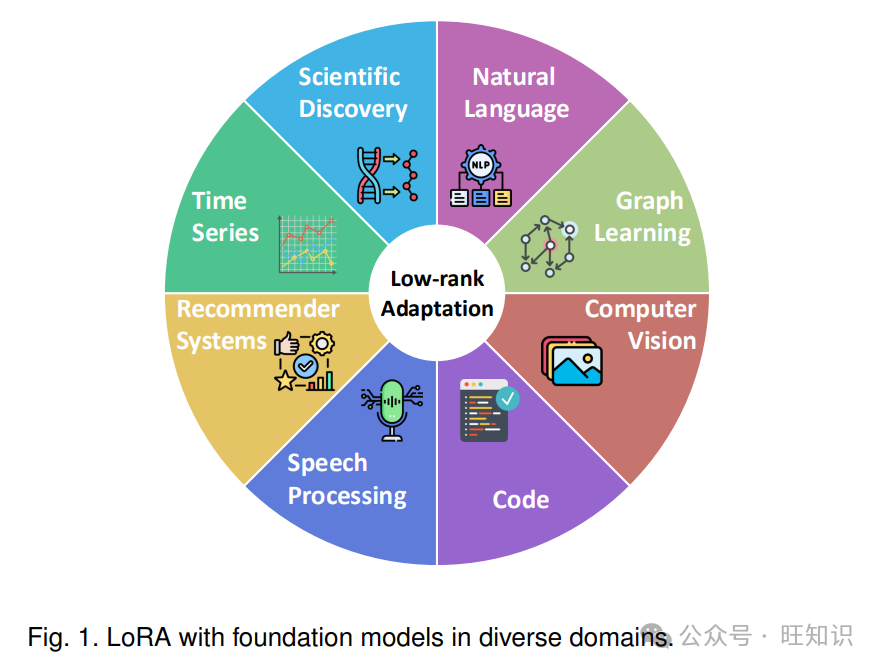
参数高效微调(PEFT)方法作为这些计算挑战的解决方案应运而生[17,24,25,26,27,28]。这些方法通过最小化可训练参数的数量来实现模型适应,在不影响任务性能的情况下大幅降低计算需求。在这些方法中,低秩适应(LoRA)[17]及其变体因其简单性、实证有效性以及在不同模型架构和领域的广泛适用性而受到广泛关注,如图 1 所示。
LoRA 基于两个关键见解:微调期间的权重更新通常位于低维子空间[29,30],并且特定任务的适应可以使用低秩矩阵有效捕获[17]。通过针对每个任务优化这些低秩矩阵并冻结原始模型参数,LoRA 实现了高效适应,并能够组合多个特定任务的适应,且不会增加推理延迟[17,31]。
贡献:据我们所知,本综述首次全面回顾了基于 LoRA 的技术在大型语言模型(LLM)领域之外的应用,将分析扩展到更广泛的基础模型领域。我们的主要贡献如下:(1)对技术基础的系统分析:我们对 LoRA 的最新技术进展进行了结构化分析,包括参数效率策略、秩适应机制、训练过程改进和新兴理论观点。(2)对新兴前沿的广泛研究:我们探索了新兴的研究前沿,包括结合多个 LoRA 组合和专家混合方法的先进架构,以及持续学习、遗忘学习、联邦学习、长序列建模和高效服务基础设施的方法。(3)对应用的全面回顾:我们全面回顾了 LoRA 在不同领域的实际应用,包括自然语言处理、计算机视觉、语音识别、科学发现,以及代码工程、推荐系统、图学习和时空预测等专业应用。
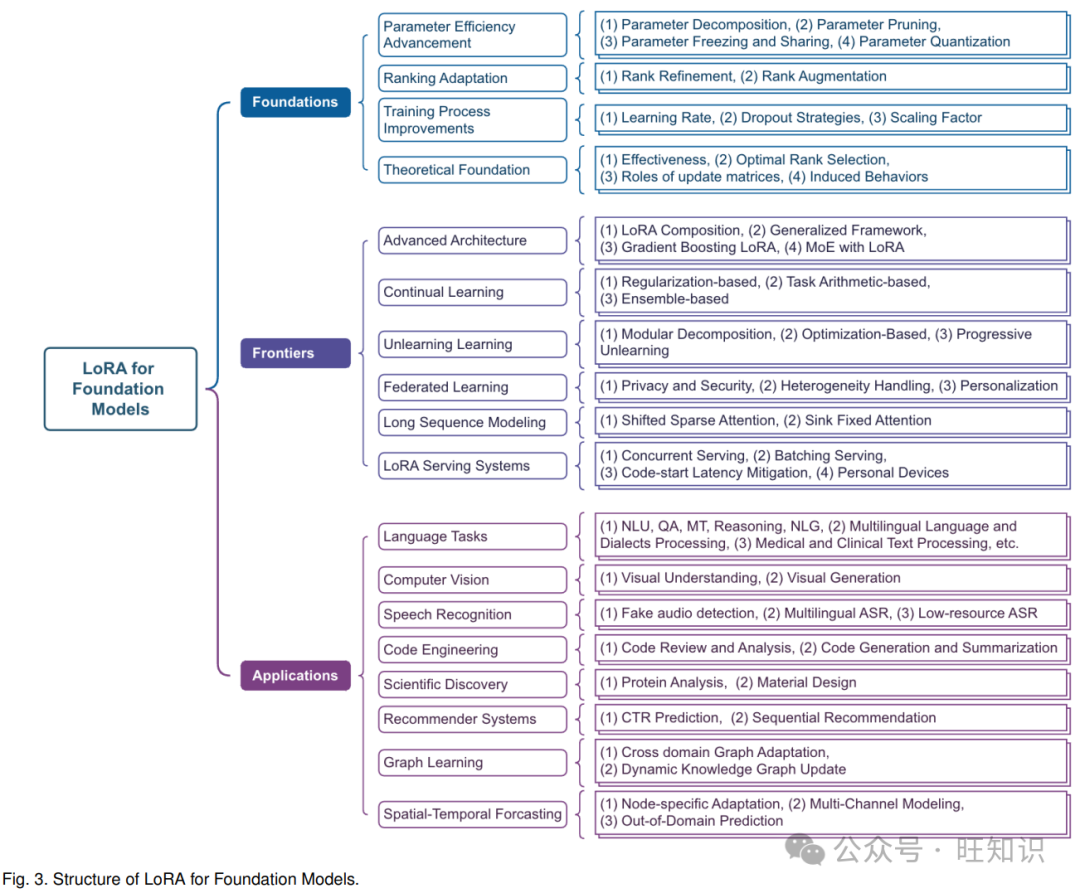
本综述组织了现有的 LoRA 研究,如图 3 所示,确定了第 6 节中的关键挑战和未来研究方向,为该领域的研究人员和从业者提供了宝贵资源。
2 基础
LoRA[17]是参数高效微调(PEFT)的一项重大进展。虽然最初是为大型语言模型开发的,但后续研究表明它在各种基础模型中都有效。
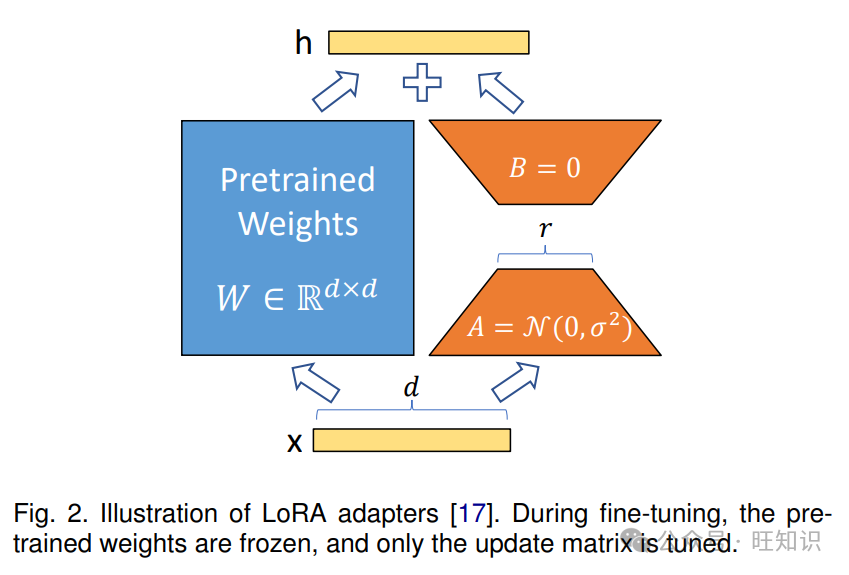
LoRA 的数学公式核心是在微调期间将更新矩阵约束为低秩,如图 2 所示,这通过矩阵分解实现:
其中,,且秩。通过将限制为低秩,LoRA 显著减少了微调过程中需要学习的参数数量,从而提高了计算和存储效率。
参数初始化策略:LoRA 采用特定的初始化策略以确保稳定和高效的训练。矩阵通常从随机高斯分布中抽取值进行初始化,而矩阵初始化为零,这确保在训练开始时,实际上是一个零矩阵。
微调过程:在 LoRA 中,微调过程遵循以下关键原则:原始预训练权重在训练期间保持冻结,不接收梯度更新。低秩矩阵和包含唯一的可训练参数,捕获特定任务的调整。和分别应用于输入向量,然后将它们的输出组合。输出乘以。最终的输出向量按元素相加:
其中是控制低秩更新幅度的缩放因子。在使用 Adam[33] 进行优化时,如果初始化适当,调整缩放因子大致类似于调整学习率[17]。在实践中,的值可以根据秩设置,无需进行大量的超参数调整。
与全量微调相比,LoRA 具有以下关键优势:(1)参数效率:LoRA 通过低秩分解引入了极少的可训练参数,通常将特定任务的参数数量减少几个数量级。在资源受限的环境和需要对基础模型进行多次适应的多任务场景中,这种方法特别有利。(2)增强的训练效率:与传统的全量微调不同,后者更新所有模型参数,LoRA 仅优化低秩适应矩阵。这种方法大大降低了计算成本和内存需求,尤其是对于具有数十亿参数的模型。减少的参数空间通常会导致训练期间更快的收敛。(3)无延迟推理:LoRA 不会引入额外的推理延迟,因为更新矩阵可以明确地合并到原始冻结权重中。这种集成确保了适应后的模型在部署和推理期间保持高效。(4)灵活的模块化适应:LoRA 能够创建轻量级的、特定任务的适配器,这些适配器可以在不修改基础模型架构的情况下进行互换。与为每个任务维护单独的模型实例相比,这种模块化有助于高效的多任务学习和任务切换,同时最小化存储需求。(5)稳健的知识保留:通过保留预训练权重,LoRA 有效地减轻了灾难性遗忘,这是传统微调中的一个常见挑战。这种方法在获取特定任务能力的同时保持了模型的基础知识。(6)通用部署:LoRA 适应的紧凑性便于高效部署和系统集成。可以在不同任务或领域中轻松组合或交替使用多种适应,与传统微调方法相比提供了更高的灵活性。
通过这些优势,LoRA 能够在保持模型性能的同时有效地适应基础模型,并显著降低计算需求。
3 基础
在本节中,我们从四个关键维度研究 LoRA 的基本技术方面:参数效率增强、秩适应策略、训练过程改进和理论基础。这些组件构成了 LoRA 有效性的技术基础。
3.1 参数效率增强
尽管 LoRA 通过其投影矩阵和实现了参数效率的提升,但该方法仍然需要大量的可训练参数。例如,将 LoRA 应用于 LLaMA-270B 模型[4]需要更新超过 1600 万个参数[34],超过了一些 BERT 架构的总参数数量[35]。当前研究主要通过四种方法来解决这一挑战:参数分解、剪枝、冻结与共享以及量化。图 4 展示了这些技术的示例。
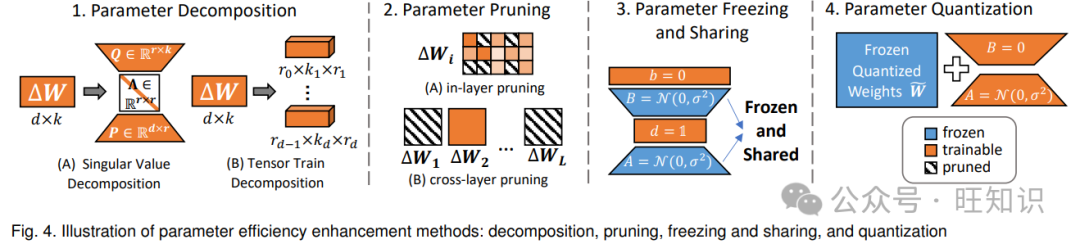
3.1.1 参数分解
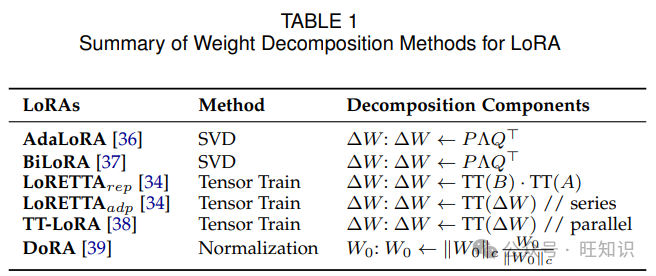
参数分解方法通过将矩阵分解为更紧凑的形式来提高参数效率,同时保持任务性能。除了减少可训练参数外,这些方法还能在微调期间实现更精细的控制。当前的方法可分为两类主要途径:更新矩阵分解[34,36,37,38]和预训练权重分解[39]。
更新矩阵分解:在更新矩阵分解方法中,出现了两种主要策略:基于奇异值分解(SVD)的方法和基于张量列(TT)的分解。
- 基于 SVD 的方法:AdaLoRA[36]以 SVD 形式对更新权重进行参数化[40]:
其中和分别表示的左奇异向量和右奇异向量,对角矩阵包含奇异值。AdaLoRA 根据重要性得分动态调整的秩,在微调期间实现自适应的参数效率。在此基础上,BiLoRA[37]通过双层优化扩展了该框架,在不同的数据子集上分离奇异向量和值的训练,以减轻过拟合。
- 基于 TT 的分解:LoRETTA[34]采用了不同的方法,使用 TT 分解[41],它将一个矩阵表示为一系列低秩、小的三维张量,通常称为核心。对于给定的矩阵,首先将其重塑为张量,其中。的 TT 表示可以公式化为:
其中
表示核心张量,表示 TT 秩,且。这种分解将参数数量从减少到。
LoRETTA 引入了两个变体:LoRETTAadp 和 LoRETTArep。LoRETTAadp 使用张量化适配器,在变压器块的每个注意力和前馈子层之后插入这些轻量级模块。另一方面,LoRETTArep 使用张量因子对权重矩阵进行重新参数化,提供了一种更紧凑的 PEFT 方法。它使用两个无偏的张量化层更新权重,在保持可比性能的同时进一步减少了可训练参数的数量。
TT-LoRA[38]将此概念直接应用于原始 LoRA 公式中的低秩矩阵。需要注意的是,TT-LoRA 作为并行适配器运行,直接修改原始 LoRA 公式中的更新矩阵。相比之下,LoRETTAadp 作为一系列插入到预训练模型架构中的适配器起作用。
预训练权重分解:DoRA[39]通过归一化方法将预训练权重分解为幅度和方向分量:
其中初始化为幅度向量,初始化为并保持冻结,表示矩阵每列的向量范数。在微调期间,权重调整为:
其中变为可训练的,表示对方向分量的 LoRA 更新。这种分解使得在微调期间能够独立优化幅度和方向,从而产生更接近全量微调的学习模式。
这两种方法在参数效率和微调灵活性方面都具有独特的优势。更新矩阵分解方法侧重于分解微调期间应用的增量更新,而预训练权重分解直接修改原始模型权重的结构,表 1 提供了这些方法的详细比较。
3.1.2 参数剪枝
参数剪枝技术侧重于评估 LoRA 矩阵中不同参数的重要性,并删除那些被认为不太重要的参数。这些方法可根据剪枝方式分为三类:基于重要性的剪枝、基于正则化的剪枝和基于输出的剪枝。
基于重要性的剪枝:这些方法使用多个指标评估参数重要性。SparseAdapter[42]将传统的网络剪枝技术应用于 LoRA 参数,通过参数幅度、梯度信息和敏感性分析来评估重要性。RoseLoRA[50]扩展了这一概念,通过基于敏感性的评分实现行/列剪枝,在保留低秩适应优势的同时实现选择性知识更新。
基于正则化的剪枝:基于正则化的剪枝技术通过优化约束诱导稀疏性。SoRA[43]在 LoRA 的下投影和上投影矩阵之间利用门控机制,采用近端梯度下降和 L1 正则化。这种方法在训练期间实现自动稀疏化,并在训练后消除零值元素。
基于输出的剪枝:基于输出的方法根据 LoRA 参数在层间的影响来评估它们。LoRA-drop[44]通过分析不同层中的分布来评估 LoRA 模块的重要性。该方法为最重要的层保留单独的 LoRA 模块,而在其他不太关键的层共享单个 LoRA。重要性得分计算使用,其中表示采样数据集。
3.1.3 参数冻结与共享
参数冻结和共享技术通过矩阵冻结和跨层参数共享减少可训练参数。
矩阵冻结:研究表明矩阵和在适应过程中具有不对称的作用。LoRA-FA[45]表明,冻结随机初始化的矩阵而仅更新可以保持模型性能。Asymmetric LoRA[46]为这种方法提供了理论基础,表明主要作为特征提取器,而作为特定任务的投影仪。这导致了一种增强设计,使用冻结的随机正交矩阵作为,在保持性能的同时进一步减少参数。
跨层参数共享:一些方法探索了跨网络层的参数共享。VeRA[47]跨层共享冻结的矩阵和,仅训练缩放向量进行适应。NOLA[48]扩展了这一概念,将和表示为共享冻结基矩阵的可训练线性组合。Tied-LoRA[49]实现了层间参数绑定,同时保持共享矩阵可训练,提供了一个灵活的框架,当共享矩阵被冻结时,VeRA 是其特殊情况。
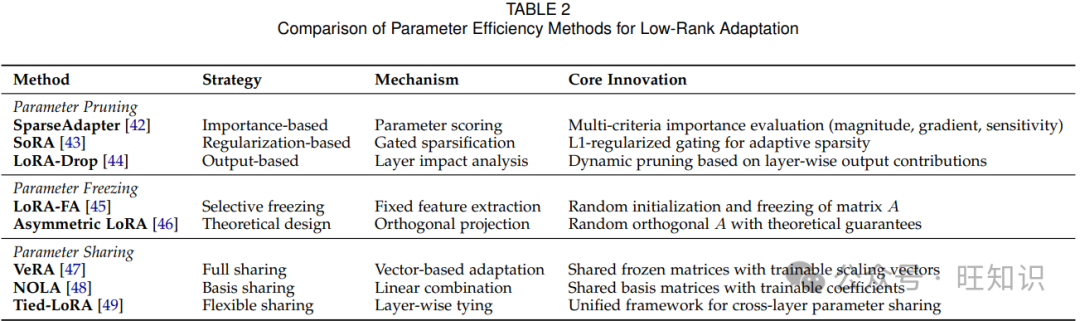
结合参数剪枝技术(第 3.1.2 节),这些方法能够在保持适应有效性的同时显著减少参数数量。表 2 提供了这些方法的全面比较。
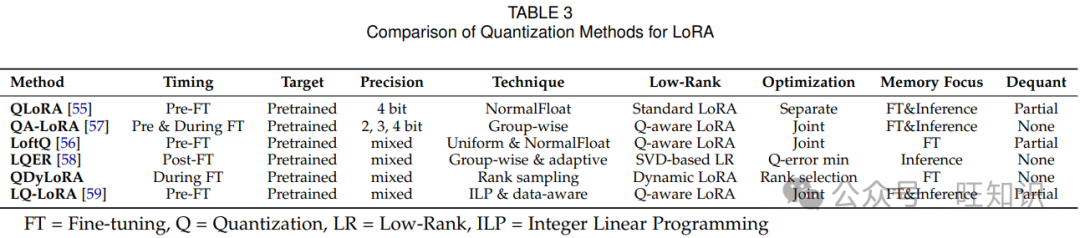
3.1.4 参数量化
量化[51,52,53]通过较低精度的数值表示优化神经网络复杂度,大大减少存储和计算需求。有关量化的全面背景知识,读者可参考[54]。在 LoRA 背景下,量化方法主要有两个维度:量化时机和量化技术。
量化时机:量化时机指的是在微调之前、期间或之后进行量化。
-
预微调量化:预微调量化是在进行任何基于 LoRA 的适应之前对预训练权重进行量化。例如,QLoRA[55]采用 4 位 NormalFloat(NF4)量化方法。类似地,LoftQ[56]通过解决量化高精度权重引入的差异对其进行了改进。LoftQ 使用迭代算法联合量化预训练模型并优化低秩初始化。
-
微调期间量化:微调期间量化在微调之前和整个过程中都应用量化。方法如 QA-LoRA[57]利用分组量化在训练期间动态调整精度,确保低秩更新和量化权重之间更平衡的交互。
-
后微调量化:后微调量化,如 LQER[58],在微调完成后进行,主要关注用于推理的量化。LQER 利用基于低秩 SVD 的分解来最小化量化误差,确保量化后的权重与原始高精度权重紧密匹配。
量化技术:针对 LoRA,已经提出了不同的量化方法,包括均匀量化、非均匀量化和混合精度量化。
-
均匀量化:均匀量化为所有权重分配相同的位宽,而不考虑其分布。QA - LoRA[57]应用具有分组细化的均匀量化,通过平衡精度权衡来优化内存效率和适应性。然而,对于非均匀分布的权重,均匀量化可能效果不佳,此时非均匀量化更为有效。
-
非均匀量化:QLoRA[55]采用非均匀量化,专门针对具有高斯分布的权重进行设计,有助于在最需要的地方(靠近零)分配更多精度。这种方法能够更好地表示在预训练模型中占主导地位的较小权重。
-
混合精度量化:混合精度量化通过根据权重矩阵或层动态调整位宽提供了更大的灵活性。诸如 LoftQ[56]和 LQ - LoRA[59]等方法利用混合精度来优化模型不同组件的量化。例如,LoftQ 交替量化权重矩阵的残差并使用 SVD 细化低秩分量。通过迭代优化低秩参数和调整量化级别,LoftQ 能够最小化量化误差。LQ - LoRA 在此基础上进一步扩展,采用整数线性规划为每个权重矩阵动态配置位宽,并引入了一种数据感知机制,利用 Fisher 信息矩阵的近似值来指导量化过程。这使得 LQ - LoRA 能够以最小的量化损失实现更准确的权重矩阵分解。
总之,预微调量化方法(如 QLoRA 和 LoftQ)通常通过冻结预训练权重提供更大的内存节省,而后微调方法(如 LQER)则更侧重于优化推理精度。在量化技术方面,非均匀和混合精度方法(如 QLoRA、LoftQ 和 LQ - LoRA 中所见)在低比特场景下表现出优越的性能,能够根据权重分布提供更灵活的精度分配。量化的时机和具体的量化技术在决定内存效率和模型性能之间的平衡方面都起着关键作用。表 3 提供了所讨论的量化方法的全面总结。
总体而言,LoRA 中的参数效率增强技术通过分解、剪枝、冻结与共享以及量化这四种互补方法不断发展,每种方法在模型性能和资源利用之间提供了独特的权衡。在这些效率提升的基础上,我们接下来探讨秩适应策略如何进一步提升 LoRA 的能力。
3.2 秩适应
秩是 LoRA 中的一个关键参数,直接影响模型的适应性和可训练参数的数量。原始的 LoRA 方法在所有层中采用固定的低秩,这对于不同的下游任务和模型架构可能不是最优的。为了解决这些限制,最近的工作提出了各种方法来优化 LoRA 中的秩分配,大致可分为两个主要方面:秩细化和秩扩充。图 5 展示了这两种方法的示意图。
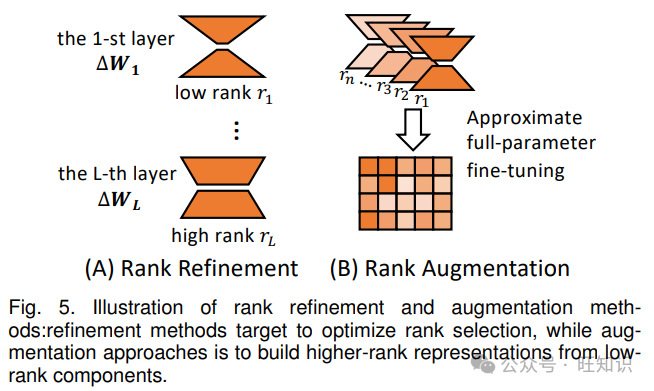
3.2.1 秩细化
秩细化方法旨在在微调期间自适应地选择 LoRA 模块的秩。关键的见解是不同的层可能需要不同程度的适应,因此受益于不同的秩。秩细化方法可分为三种主要类型:自适应分配、启发式策略和多秩训练。
自适应分配:自适应分配方法在训练期间根据从数据或模型参数导出的重要性指标动态调整 LoRA 模块的秩。AdaLoRA[36]通过使用 SVD 对 LoRA 更新进行参数化引入了一种自适应的秩分配机制。它根据奇异值的大小动态修剪奇异值,使每个层能够具有定制的秩,同时保持全局参数预算。类似地,SoRA[43]采用可学习的门控机制来控制每个 LoRA 模块的有效秩。这些门通过近端梯度下降和正则化进行优化,以促进稀疏性。这种方法能够自动发现适合不同层的秩,在无需手动调整的情况下提高参数效率。
启发式策略:启发式策略根据预定义的规则分配秩,这些规则可以来自先验知识或经验观察。PRILoRA[60]提出了一种确定性策略,其中 LoRA 模块的秩从较低层到较高层线性增加。基于在迁移学习中较高层通常需要更多适应的观察,这种启发式方法为上层分配更高的秩。
多秩训练:多秩训练方法使模型能够在一系列秩上表现良好,在推理时提供灵活性。DyLoRA[61]同时在多个秩上训练 LoRA 模块。在每个训练迭代中,它从预定义的分布中采样秩,使模型能够学习在多个秩上有效地执行。这种策略在推理时无需额外训练即可实现适应性,在具有不同计算约束的部署场景中非常有益。
3.2.2 秩扩充
秩扩充方法旨在通过一系列低秩修改实现高秩模型更新,弥合 LoRA 与全参数微调之间的性能差距。这些方法可分为两类:基于矩阵合并的方法和基于矩阵重采样的方法。
基于矩阵合并的方法:基于矩阵合并的方法通过合并低秩更新矩阵来增加秩。关键思想是多个低秩矩阵的和可以近似一个更高秩的矩阵,从而在不产生大量计算开销的情况下增强捕获复杂模式的能力。
ReLoRA[62]引入了一个迭代训练框架,其中低秩 LoRA 模块被训练并定期合并到预训练模型权重中。通过在每次合并后重置优化器并初始化新的 LoRA 模块,ReLoRA 有效地增加了整体秩,同时保持内存效率。
COLA[63]提出了一种类似的迭代优化策略,受 Frank - Wolfe 算法[64]的启发。它迭代地训练 LoRA 模块并将它们合并到模型中,逐步构建更高秩的适应。每个新的 LoRA 模块最小化来自先前适应的残差误差,使 COLA 能够在不增加每次迭代计算成本的情况下实现高秩表达能力。
MELoRA[65]引入了一种并行化的秩扩充方法。核心思想是同时训练多个小型 LoRA 模块,并连接它们的输出以形成更高秩的适应。通过组装一个低秩适配器的小型集成,MELoRA 构建了一个等效的块对角矩阵,其总体秩更高。
XGBLoRA[66]为 LoRA 引入了梯度提升(GB)框架。它通过组合一系列秩 - 1 助推器(LoRA 适应)来构建最终模型,逐步改进模型的预测。利用弱学习器的 GB 原则(即从一组弱预测器构建强集成模型),XGBLoRA 克服了极低秩适应和有效性之间的困境。
基于矩阵重采样的方法:基于矩阵重采样的方法通过在训练期间动态重采样投影矩阵来实现高秩适应。基本思想是在每个训练步骤使用低秩矩阵的同时,利用时间积累高秩更新的效果。
FLoRA[67]将 LoRA 重新解释为一种梯度压缩和解压缩机制。它在训练期间定期重采样 LoRA 模块中使用的投影矩阵。通过按预定间隔改变这些矩阵,该方法确保随着时间的推移探索不同的子空间,有效地积累更高秩的适应。
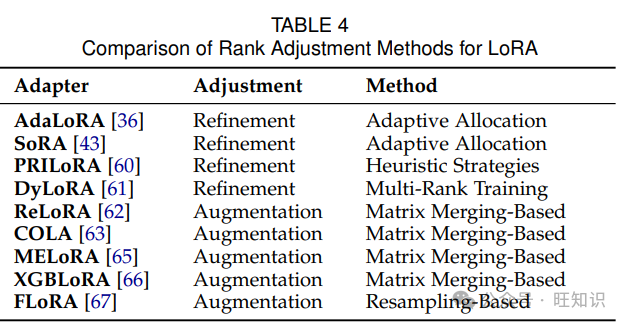
总之,秩适应策略通过根据不同层和任务的要求定制适应矩阵的秩来增强 LoRA 的适应性。表 4 提供了关于秩细化和扩充的详细总结。
3.3 训练过程改进
虽然 LoRA 在参数高效微调方面取得了显著成功,但优化其训练动态对于最大化适应性能仍然至关重要。在本节中,我们讨论旨在改进训练过程的最新进展,特别是学习率、随机失活策略和缩放因子。
学习率:在标准的 LoRA 微调中,通常对低秩矩阵和应用统一的学习率。然而,Hayou 等人[68]观察到这种做法会导致次优性能,尤其是当模型宽度增加时。问题在于和的更新对学习动态的贡献不同。为了解决这个限制,Hayou 等人[68]提出了 LoRA +,一种为矩阵和分配不同学习率的方法。他们在无限宽度极限下的理论分析表明,为了实现高效学习,来自和的特征更新的幅度应该为。这需要缩放学习率,使得和,其中表示模型宽度。在实践中,LoRA + 引入了一个固定比率,允许从业者调整一个学习率,同时自动调整另一个。
随机失活策略:尽管基于 LoRA 的模型可训练参数数量减少,但过拟合仍然是一个问题,特别是在微调小型或专用数据集时。传统的随机失活技术可能不足以在这种情况下减轻过拟合。Wang 等人[69]强调了这个问题,并提出了一个全面的框架,通过三个维度的随机失活来解决它:失活位置、结构模式和补偿措施。失活位置指定了引入噪声的位置,例如在注意力 logits、权重或隐藏表示中。结构模式定义了单元失活的粒度,包括元素级、列级或跨度级模式。补偿措施旨在通过诸如归一化重缩放或 Kullback - Leibler 散度损失等技术最小化训练和推理阶段之间的差异。在此框架的基础上,作者提出了 HiddenKey[69],一种将注意力 logits 的列级随机失活与隐藏表示的元素级随机失活相结合,并辅以 KL 散度损失的随机失活方法。
缩放因子:在 LoRA 中,应用缩放因子。然而,正如 Kalajdzievski[70]指出的,当增加适配器秩时,这个缩放因子可能会导致梯度消失,从而导致高秩适配器的学习速度减慢和性能下降。为了克服这个限制,Kalajdzievski[70]提出了 rsLoRA,它将缩放因子重新定义为。这种调整确保了适配器的秩稳定性,这意味着前向和后向传播相对于秩保持稳定的幅度,即使秩变得很大。在无限宽度极限下理论推导得出,这个缩放因子防止了梯度消失,使得在不同的适配器秩上能够进行稳定的学习。
通过根据 LoRA 矩阵的不同作用调整学习率、通过结构化随机失活减轻过拟合以及通过秩稳定的缩放因子防止梯度消失,这些方法提高了 LoRA 微调的效率和有效性。接下来,我们研究 LoRA 性能的理论基础。
3.4 理论基础
虽然 LoRA 的实际优势显而易见,但从理论角度理解其潜在原理至关重要。本节解决了关于其有效性、最优秩选择、更新矩阵的作用以及在理论方面引起的行为变化的关键问题。
问题 1:为什么 LoRA 能有效工作? LoRA 在仅更新一小部分参数的情况下实现了与全量微调相当的性能。这种现象可以通过神经切线核(NTK)理论来理解[1]。Malladi 等人[71]表明,LoRA 在微调期间近似保留了原始模型的核。具体来说,大概率下[71],
其中和分别是由 LoRA 和全量微调诱导的核,是数据集中的示例数量,是梯度和输入的 L2 范数的上界,是近似误差,是由给出的概率界,其中是 LoRA 中使用的秩。
虽然 LoRA 将更新限制在低秩子空间,但它有效地针对了对网络行为的显著变化负责的梯度。根据公式(7),通过关注这些关键梯度,LoRA 保留了模型的泛化能力,确保网络对基本输入变化保持敏感,同时具有高度的参数效率。
Zeng 和 Lee[72]对 LoRA 在不同架构中的表达能力进行了全面研究。(i)对于全连接神经网络,如果 LoRA 秩满足:
则 LoRA 可以将任何模型适应为准确表示较小的目标模型。(ii)对于 Transformer 网络,他们表明可以使用秩为(嵌入大小/2)的 LoRA 适配器将任何模型适应为相同大小的目标模型。这些发现为确定不同架构中有效适应所需的最小秩提供了理论基础。
作为这项工作的补充,Jang 等人[73]在 NTK 体制下分析了 LoRA 训练,得出了几个关键见解:(i)他们证明了全量微调(无 LoRA)允许秩为的低秩解,其中是训练数据点的数量。(ii)使用秩的 LoRA 消除了虚假局部最小值,有助于高效发现全局最小值。这个结果表明了 LoRA 秩的一个下限,以确保优化稳定性。(iii)他们为 LoRA 适应的模型提供了泛化保证,证明泛化误差被界定。这个界为 LoRA 适应模型在未见过的数据上的性能提供了保证。
这些理论分析为 LoRA 应用中的超参数调整提供了有价值的指导。
问题 2:LoRA 微调需要多少秩才能达到最佳性能? LoRA 微调中的秩对于理解适应的表达能力和保持计算效率至关重要。
问题 3:更新矩阵和的作用是什么? Zhu 等人[46]对矩阵和在 LoRA 中所起的不同作用进行了全面分析。他们的工作揭示了这些矩阵中固有的不对称性,这对微调效率和模型泛化具有重要意义。
作者[46]表明,主要作为从输入中提取特征的功能,而将这些特征投影到期望的输出。这种不对称性表明,仅微调可能比微调更有效。值得注意的是,他们的分析表明,随机初始化的可以表现得几乎与微调后的一样好,这挑战了更新两个矩阵的传统做法。在此见解的基础上,Zhu 等人使用信息论框架推导了不同 LoRA 变体的泛化界。当仅微调时,泛化界具有以下形式:
其中是秩,是量化位,与损失的次高斯性相关,是样本大小,是第层的输出维度。与更新和相比,这个界更紧,这表明将冻结为随机正交矩阵并仅更新可能潜在地增强对未见过数据的泛化能力。
这些发现与之前的问题一致并扩展了相关见解,特别是关于最优秩选择的讨论。通过专注于仅更新,研究人员可能能够在进一步减少可训练参数数量的同时实现更好的泛化,从而提高 LoRA 微调的效率和有效性。
问题 4:LoRA 会在模型中引起哪些行为变化? Koubbi 等人[74]分析了注意力矩阵的动态,表明 LoRA 诱导的低秩修改在保持标记聚类的短期稳定性的同时,促进了学习表示的长期显著差异。
LoRA 使用低秩矩阵更新注意力矩阵为,引入了受控的扰动:
在 LoRA 下标记的动态由下式描述:
其中注意力权重基于 Query 和 Key 矩阵的 softmax。
LoRA 保持标记聚类的短期稳定性,扰动和未扰动标记分布之间的 Wasserstein 距离保持有界:
一个关键结果是识别出一个相变,其中标记在关键时间之后分叉为新的聚类,该时间由 Value 矩阵的特征值间隙控制。这展示了 LoRA 如何在不发生灾难性遗忘的情况下微调模型,在训练早期保留标记结构,同时允许受控的差异。
LoRA 的这些理论基础展示了其有效性,从 NTK 理论解释的竞争性能到通过受控标记动态防止灾难性遗忘。对最优秩选择和更新矩阵不对称性的见解为改进提供了实用指导。
4 前沿
在上述技术基础之上,这些基础确立了 LoRA 的核心组件和机制,本节探索前沿发展,这些发展在新的方向上扩展了 LoRA 的能力。这些前沿发展利用并结合其基本原理来实现新功能、处理更复杂的任务以及解决模型适应中的挑战。
4.1 先进架构
虽然原始的 LoRA 方法显著提高了微调效率,并展示出与全量微调相当的性能,但在灵活性、泛化性和同时处理多个不同任务方面存在局限性。为了解决这些局限性,研究人员开发了先进的 LoRA 架构,以进一步提高性能、参数效率和泛化能力。
4.1.1 LoRA 组合
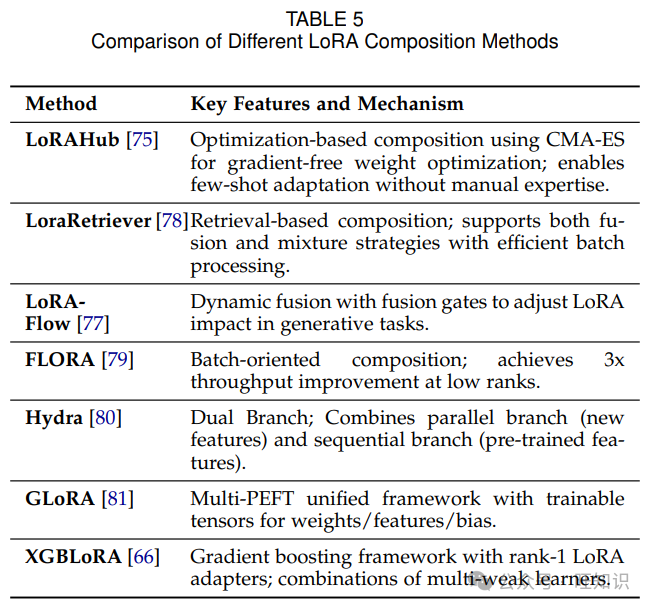
先进 LoRA 架构的一项重大创新是动态组合多个 LoRA 模块,以增强跨不同任务的适应性和泛化能力。
-
基于优化的组合:LoRAHub[75]利用 CMA - ES[76]无梯度优化来确定组合 LoRA 模块的最优系数。通过少样本学习,它能够自动为新任务选择和集成模块,而无需手动专家知识或梯度计算。类似地,LoRA - Flow[77]引入动态融合权重,通过具有极少参数的融合门在每个生成步骤调整不同 LoRA 的影响。这种方法在各种任务上优于具有静态任务级融合权重的基线方法。
-
基于检索的组合:LoraRetriever[78]根据输入提示实现 LoRA 模块的动态检索和组合。它首先使用在一部分任务上的指令微调将特定任务的 LoRA 嵌入到共享空间中,然后使用余弦相似度检索相关模块。该框架支持模块融合和混合策略,同时保持高效的批处理。
-
面向批处理的组合:FLORA[79]通过高效的矩阵运算使小批量中的每个示例能够利用独特的低秩适应权重。与传统的批处理方法相比,这种设计显著提高了吞吐量并降低了延迟,在生产环境中处理多样化用户请求时特别有益。
通过使模型能够根据任务或输入选择和组合多个 LoRA 模块,这些方法克服了标准 LoRA 在处理多样化任务方面的局限性,并提高了整体性能。
4.1.2 广义框架
另一项进展涉及扩展 LoRA 架构本身,以更有效地捕获特定任务和通用特征。
-
双分支框架:Hydra[80]提出了一种更广义的公式,通过在模型中集成并行和顺序 LoRA 分支。并行分支学习特定任务的特征,类似于标准 LoRA,而顺序分支线性组合预训练特征。这种双分支结构使 Hydra 能够捕获特定任务的适应并利用通用预训练知识,提供了一种全面的适应机制,提高了跨任务的性能。
-
多 PEFT 统一框架:GLoRA[81]通过统一 LoRA 之外的各种参数高效微调方法进一步进行了推广。它引入可训练的支持张量来缩放和移动权重、特征和偏差,有效地将 LoRA、适配器调整和提示调整等方法纳入一个单一框架。GLoRA 采用进化搜索来确定这些张量的最优层配置,这些张量可以采用标量、向量或低秩矩阵形式。通过结构重参数化,GLoRA 在不增加额外推理成本的情况下,比以前的 PEFT 方法提供了更大的灵活性。
这些广义架构通过纳入捕获不同特征的额外机制和促进跨任务的更有效微调,增强了 LoRA 的表达能力。
4.1.3 LoRA 与梯度提升
LoRA 与梯度提升(GBLoRA)通过迭代训练 LoRA 模块来组合弱学习器,以最小化残差误差。在经过次提升迭代后,微调后的模型表示为:
具有累积模型更新:
其中控制每个 LoRA 助推器的贡献。弱学习器原则使 GBLoRA 能够通过低秩更新实现强大的性能。XGBLoRA[66]建立了收敛保证和表达能力界限,展示了增加提升迭代如何补偿较低的秩。这个框架在 GB 范式内统一了各种矩阵合并方法,如 ReLoRA[62]、COLA[63]和 MeLoRA[65]。
4.1.4 LoRA 与专家混合
先进 LoRA 架构发展的另一个重要分支是将 LoRA 与专家混合(MoE)相结合。MoE 是一种神经网络架构,其中多个“专家”子网络专门处理不同的输入模式[82]。一个门控机制将输入路由到最合适的专家,使模型能够高效地处理广泛的任务[83]。给定输入,MoE 模型计算:
其中是输出,是门控函数,是专家,是专家的数量。
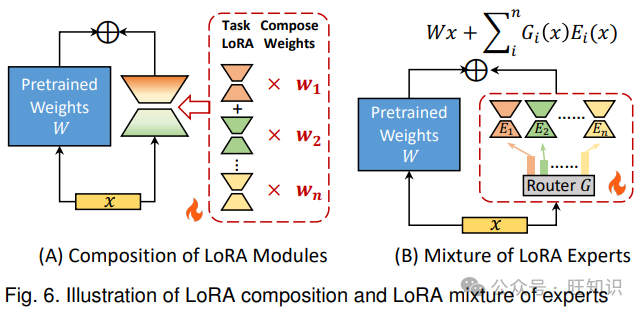
通过将 LoRA 与 MoE 集成,模型学习多个低秩矩阵对(LoRA 专家),而不是单个对,并且路由器根据输入确定专家的权重或选择。在微调期间,预训练的 LLM 权重保持固定,而 LoRA 专家和路由器进行训练,利用 LoRA 的参数效率和 MoE 的专业化能力。典型的框架如图 6(B)所示。
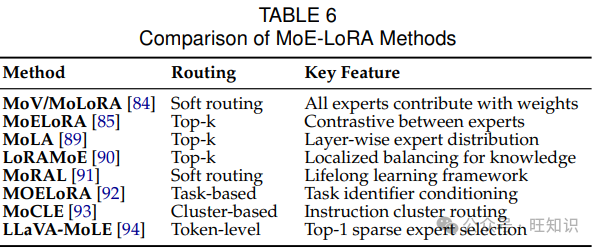
基于 LoRA - MoE 方法的研究可大致分为三类,主要目标分别为:(1)提高性能和参数效率,(2)在微调期间保留知识,(3)适应多任务学习。虽然这些类别突出了不同的重点,但许多方法同时解决了多个目标。
- 效率导向设计:此类方法旨在以最小的参数开销实现与全量微调相当的性能。Zadouri 等人[84]引入了 MoV 和 MoLoRA,旨在在更新不到 1%的参数的情况下实现全量微调性能,并提高对未见过任务的泛化能力。MoV 和 MoLoRA 分别使用向量和 LoRA 适配器作为专家,并采用软合并策略,其中所有专家根据路由器概率对输出做出贡献。
在此基础上,Luo 等人[85]提出了 MoELoRA,将 LoRA 模块视为 MoE 框架内的专家。MoELoRA 包含多个 LoRA 专家和一个门控网络,用于路由和负载平衡,以防止收敛到有限的专家集。在专家之间应用对比学习缓解了 MoE 模型中常见的随机路由问题[87]。
然而,固定数量的 LoRA 专家(例如 MoELoRA[85])缺乏灵活性,并且由于表示崩溃或学习到的路由策略过拟合可能会变得冗余[88]。为了解决这个问题,Gao 等人[89]引入了 MoLA,一种跨不同 Transformer 层灵活分配 LoRA 专家的层级专家分布方法。MoLA 采用 top - k 路由机制为每个输入选择相关专家。除了提高性能和参数效率外,MoLA 由于其稀疏专家激活而展示出有前途的持续学习能力,使模型能够在适应新领域的同时保留来自先前领域的知识。
- 基于记忆的适应:这些方法侧重于在适应过程中防止灾难性遗忘。两种值得注意的方法,LoRAMoE[90]和 MoRAL[91],解决了在将 LLM 适应到新任务或领域时知识保留的挑战。
LoRAMoE[90]引入了多个通过路由器网络集成的 LoRA 专家,使用局部平衡约束鼓励一些专家专注于利用世界知识进行下游任务。它采用 top - k 路由策略,使模型能够在提高多个任务性能的同时保持世界知识。MoRAL[91]使用来自非结构化文本的问答对,并将 MoE 的多任务处理能力与 LoRA 的参数效率相结合。它采用软路由机制,其中所有专家根据路由器概率对输出做出贡献。MoRAL 在适应新领域的同时保持对先前见过任务的性能,解决了灾难性遗忘问题。
- 基于任务的集成:这些方法解决了领域特异性和任务干扰挑战。领域特异性出现在基于通用数据训练的模型缺乏特定领域(如医学[92]或金融[95])所需的专业知识时。任务干扰发生在多个任务及其数据集在训练期间竞争时,导致跨任务性能下降[93,94,95]。
为了解决领域特异性问题,Liu 等人[92]提出了 MOELoRA 用于多任务医学应用。MOELoRA 引入了多个 LoRA 专家,每个专家由低秩矩阵组成,具有基于任务身份控制每个专家贡献的任务驱动门控函数。这种方法允许特定任务的学习,同时在任务之间维护共享知识库。Feng 等人[95]引入了 MOA,一种用于多任务学习的端到端参数高效调整方法。MOA 首先为不同任务训练单独的 LoRA 模块,然后使用基于域元数据的序列级路由机制将它们组合起来,允许灵活组合特定领域的 LoRA。Buehler 等人[96]提出了 XLoRA,采用深度层令牌级动态 MoE 策略。从预训练的 LoRA 适配器开始,X - LoRA 使用利用隐藏状态的门控策略动态混合适应层。这使模型能够创建新颖的组合来解决任务,在科学应用中表现出强大的性能。
为了解决任务干扰问题,Gou 等人[93]通过 MoCLE 解决了视觉语言指令调整中的任务冲突。该方法引入了一种 MoE 架构,根据指令簇激活任务定制参数,采用簇条件路由策略并纳入一个通用专家以提高对新指令的泛化能力。Chen 等人[94]提出了 LLaVAMoLE 以减轻多模态 LLM 指令微调中的数据冲突。它引入了一种稀疏 MoE 设计,包含多个 LoRA 专家,并采用令牌级路由策略,其中每个令牌被路由到 top - 1 专家。这允许对来自不同领域的令牌进行自适应选择,有效地解决了数据冲突。
此外,Tian 等人[97]提出了 HydraLoRA,一种不对称的 LoRA 架构,挑战了基于 MoE 的方法中的传统对称专家结构。通过实证分析,他们发现,在多任务设置中,来自不同 LoRA 头的矩阵参数趋于收敛,而矩阵参数保持不同。在此观察的基础上,HydraLoRA 引入了一种架构,其中所有任务共享矩阵,并具有多个特定任务的矩阵,采用可训练的 MoE 路由器自动识别训练数据中的内在组件。
通过采用各种路由策略和专家设计,这些方法能够有效地适应多个任务或领域,同时减轻干扰并保持特定任务的性能。LoRA 与 MoE 的集成在提高性能、保留知识和促进跨各种领域的多任务适应方面展示出了有前途的结果。
4.2 LoRA 用于持续学习
LoRA 的参数高效特性允许在新任务上增量更新模型,同时减轻灾难性遗忘[98,99]。有几个关键优势促使在持续学习(CL)中使用 LoRA:(1)与全量微调相比降低了计算成本,(2)自然隔离特定任务的知识,(3)灵活组合特定任务的适应。现有的基于 LoRA 的持续学习方法可大致分为三类:基于正则化的方法、基于任务算术的方法和基于集成的技术。
基于正则化的方法将 LoRA 更新的参数约束作为防止灾难性遗忘的主要机制,侧重于保留关键模型参数。O - LoRA[98]通过约束新任务更新与先前任务的子空间正交来解决灾难性遗忘问题。它利用了 LoRA 参数有效捕获任务梯度子空间的见解。O - LoRA 在正交子空间中增量学习新任务,同时保持先前的 LoRA 参数固定。这种方法允许有效的知识积累而无干扰。Online - LoRA[100]是一个用于视觉变压器的无任务在线持续学习框架,它在不依赖排练缓冲区的情况下解决灾难性遗忘问题。它结合权重正则化来保护重要参数和损失动态监测来检测分布转移,实现实时模型适应,同时在变化的数据流中保持性能。它不假设任何任务边界。
基于任务算术的方法利用 LoRA 参数上的任务向量算术[101]。Chitale 等人[101]对 LoRA 参数应用算术运算以组合来自多个任务的知识。这种方法为每个任务训练单独的 LoRA 模块,然后使用任务向量加法创建一个与任务无关的模型。一个关键见解是 LoRA 参数在权重空间中创建语义“任务向量”,可以进行代数操作。
基于集成的工作维护和组合多个特定任务的 LoRA 模块。CoLoR[99]为每个任务维护单独的 LoRA 模块,并在推理时使用无监督方法选择适当的模块。CoLoR 顺序训练特定任务的 LoRA 模块,并使用基于原型的任务识别将它们组合起来。这允许隔离任务知识,同时实现灵活组合。AM - LoRA[102]使用多个特定任务的 LoRA 模块与注意力机制相结合,集成来自不同任务的知识。基于注意力的混合策略实现自适应知识集成,同时防止任务之间的灾难性遗忘。
虽然这些方法展示了 LoRA 在持续学习中的潜力,但仍存在一些挑战。O - LoRA 中的正交性约束对于具有重叠知识的任务可能过于严格。任务算术假设任务可以线性组合,但这可能并非在所有情况下都成立。集成方法在任务识别和扩展到许多任务方面面临挑战。
4.3 LoRA 用于遗忘学习
LoRA 便于从基础模型中有针对性地删除特定知识,而无需进行大量的重新训练。本节对采用 LoRA 进行遗忘学习的方法进行分类和研究,重点关注三个主要类别:模块化分解方法、基于优化的方法和渐进式遗忘学习管道。
模块化分解方法侧重于分解和模块化模型组件以支持遗忘学习。Gao 等人[103]引入了一种正交 LoRA 机制,确保在连续的遗忘过程中参数解耦。这种设计确保遗忘请求可以连续处理,而不会干扰保留的知识。Chen 和 Yang[104]提出添加高效的遗忘 LoRA 层,采用选择性教师 - 学生目标来引导模型“忘记”特定数据。此外,Lizzo 和 Heck[105]引入了 UNLEARN,其中 LoRA 层被适应以在低维子空间中识别和隔离目标知识。
基于优化的方法主要依赖于优化方法来定位和删除特定知识。Cha 等人[106]提出了一种 LoRA 初始化技术,根据数据调整低秩矩阵,通过 Fisher 信息加权优先考虑对删除目标知识至关重要的参数调整。在不同的方法中,Gundavarapu 等人[107]探索了一种基于梯度的微调方法与 LoRA 相结合,以选择性地遗忘有害或不需要的信息。利用梯度上升与低秩 LoRA 更新相结合,这种方法细化模型知识的特定部分。
顺序管道策略实施结构化的多步骤程序以进行系统的遗忘学习。Liu 等人[108]利用 LoRA 在一个结构化的两阶段过程中否定特定的有害知识。第一阶段专注于识别有害内容,而第二阶段应用 LoRA 抑制和中和此类知识,而不影响其他学习到的信息。这种有条不紊的方法确保系统地删除不需要的信息,同时保留模型的一般能力。
4.4 LoRA 用于联邦学习
在数据隐私关注度日益提高的时代,联邦学习(FL)提供了一种有前途的方法,在保护个人数据的同时利用集体知识。将 LoRA 集成到联邦基础模型(FFM)中使基础模型更易于在资源受限的设备上使用,特别是在边缘计算场景中,可能会彻底改变物联网和移动应用。联邦指令调整和价值对齐与 LoRA 的结合创造了一种强大的协同作用,解决了分布式机器学习中的几个关键挑战。
隐私和安全:在联邦学习中,隐私和安全保护至关重要。FedIT[109]和 FFA - LoRA[110]建立了将联邦学习与 LLM 指令调整相结合的基本框架。这些框架实施 FedAvg 隐私保护机制,确保指令数据保留在本地设备上,只有加密的 LoRA 参数在中央服务器上传输和聚合。采取不同的方法,PrivateLoRA[111]仅在中央云和边缘设备之间传输激活,以确保数据本地性。为了进一步提高安全性,Huang 等人[112]将模型切片与可信执行环境(TEE)集成,以防范恶意攻击,在服务器端使用 TEE 处理后层,并使用 LoRA 进行稀疏化参数微调(SPF),在不需要客户端 TEE 的情况下实现安全性和性能。
计算效率:尽管在隐私和安全方面取得了重大进展,但 FL 在模型表达能力和计算效率之间面临着基本的权衡。研究表明,为了保证能够拟合任何目标模型,LoRA 的秩必须满足一个随嵌入大小缩放的下限[113],如第 3.4 节所讨论的。然而,在实践中实现这样的高秩会导致高昂的通信和计算成本,对于资源受限的设备尤其具有挑战性[114,115,116]。为了解决这个挑战,FedGBA[66]将集成学习与秩 - 1 适应相结合,实现了高效且表达能力强的 FFM 联邦微调。类似地,FFA - LoRA[110]通过固定随机初始化的非零矩阵并仅微调零初始化的矩阵来降低计算开销。
异质性处理:FL 中的另一个重大挑战是管理跨客户端的异构数据、设备和模型。当客户端之间的数据不是独立同分布(non - IID)时,FL 模型的性能通常会下降。SLoRA[117]通过数据驱动的初始化解决了这个问题,而 FedLoRA[118]实施了一种基于堆叠的聚合方法,能够聚合跨异构客户端的不同秩的 LoRA 适配器。此外,pFedLoRA[119]引入了一个同质的小适配器,通过迭代训练促进联邦客户端的异构本地模型训练,实现全球 - 本地知识交换。Wagner 等人[120]引入了信任加权梯度聚合方案,用于在数据有限的情况下对大型语言模型进行设备上的微调,利用 LoRA 减少通信并在多样化数据场景中优于 FedAvg 和本地调优方法,有效地解决了本地数据集中的数据异质性和稀缺性问题。Cho 等人[121]提出了异构 LoRA,通过在客户端之间结合高秩和低秩适应,在资源受限设备上实现了小型基础模型的高效联邦微调,以最小的通信实现最佳性能并防止过拟合。
个性化:FL 中的个性化涉及通过各种技术(如本地微调、LoRA 适应或混合方法)将全局模型适应到单个客户端。这个过程需要在考虑每个客户端独特的数据分布和资源约束的同时,仔细平衡模型性能、隐私保护和系统效率。FedHLT[122]和 FedLFC[123]在个性化多语言建模中体现了这种方法,将低秩适应与语言家族聚类相结合,解决了 FFM 的高通信成本和参数干扰挑战,与基线模型相比,在降低开销的同时提高了性能。PER - PCS[124]是一个框架,允许用户安全地共享和协作组装个性化的 LoRA 模块用于大型语言模型,在显著降低计算成本和存储要求的同时实现与单独微调相当的性能。
LoRA 与 FFM 的集成代表了分布式机器学习的重大进步,为隐私保护的模型适应提供了创新解决方案,同时平衡了效率、异质性和个性化要求。通过各种结合隐私机制、高效参数传输和自适应技术的框架,LoRA 使 FL 在资源受限环境中更实用,同时保持模型的表达能力和安全性。随着边缘计算和物联网应用的不断发展,LoRA 与 FFM 的协同作用有望通过在隐私敏感领域实现高效、安全和个性化的模型大规模部署来改变分布式机器学习。
4.5 LoRA 用于长序列建模
处理长序列的能力对于基础模型在各个领域处理的许多任务至关重要[125,126,127]。然而,由于自注意力相对于序列长度的二次计算复杂度,标准基础模型通常受到其最大上下文长度的限制。为了解决这个限制,已经提出了几种基于 LoRA 的方法来扩展基础模型的上下文窗口。
移位稀疏注意力方法:LongLoRA[125]通过将位置插值[128]与 LoRA 集成来应对这一挑战,实现了对长上下文的大型语言模型的高效微调。与标准 LoRA 应用不同,LongLoRA 除了注意力层之外,还将可训练的低秩适应扩展到嵌入和归一化层。一个关键创新是移位稀疏注意力(S2 - Attn)机制,它在训练期间通过将输入序列分组并在每个组内应用注意力来近似全注意力。为了增强组间的信息流,一半的注意力头被移位半个组大小。这种方法便于在扩展序列上进行高效训练,同时在推理时保留原始模型架构。
汇固定注意力方法:在 LongLoRA 的基础上,SinkLoRA[126]引入了汇固定注意力(SF - Attn)机制来解决特定限制。SF - Attn 将分割和重组算法与聚焦于有限数量的“汇注意力标记”的全局注意力相结合。这种方法有效地重新分配注意力分数,减轻了在自回归模型中经常观察到的对初始标记的过度强调。
另一个进展是 LongQLoRA[127],它将 QLoRA[55]与位置插值[128]和移位短注意力相结合。通过在微调期间将基础模型量化到 4 位精度,LongQLoRA 能够在比 LongLoRA 更低的计算资源下扩展上下文长度。
这些基于 LoRA 的长序列建模技术在不产生大量计算开销或需要对整个模型进行微调的情况下,展示了扩展基础模型上下文窗口的巨大潜力。
4.6 LoRA 服务系统
高效服务多个 LoRA 模型也至关重要。最近的进展包括改进的 GPU 内存管理[129]、高效的批处理技术[130]、CPU 辅助策略以减少冷启动延迟[131]以及适用于资源受限个人设备的适应方法[132]。
S - LoRA[129]引入了一种统一的分页机制来管理 GPU 内存中的 KV 缓存和 LoRA 权重,能够并发服务数千个 LoRA 适配器。Punica[130]开发了一个自定义的 CUDA 内核,分段聚集矩阵 - 向量乘法(SGMV),便于在单个 GPU 上对不同 LoRA 模型的请求进行高效批处理。CARASERVE[131]采用了 CPU 辅助策略,在 GPU 加载期间为新请求的适配器启动预填充计算,以减少冷启动延迟。此外,CARASERVE 引入了一种秩感知调度算法,用于在多 GPU 集群中优化请求路由。CA - LoRA[132]纳入了 LoRA 知识继承和模型知识恢复机制,以在个人设备上保持性能。这些创新提高了在不同计算环境中多个 LoRA 服务的可扩展性和效率。
5 应用
LoRA 在微调基础模型方面的有效性和效率使其在各个领域得到了广泛应用,包括语言处理、计算机视觉、语音识别、多模态、代码工程、科学发现、推荐系统、图学习、时空预测等。
5.1 LoRA 在语言任务中的应用
语言基础模型,如 LLaMA[4]、RoBERTa[21]和 DeBERTa[133],是 LoRA 研究中的重要基础模型,并在不同的语言任务中得到了广泛研究,包括自然语言理解[45,47,48]、问答[36,134]、机器翻译[45,49]、推理[49,56,75,135]和自然语言生成[55,61,62],从表中也可以看出这一点。本节探讨其在特定 NLP 领域的应用。
多语言和方言处理:LoRA 通过最小的参数更新实现了高效的多语言适应,同时保留了基础模型的能力。FedLFC[123]引入了一个通信高效的联邦学习框架,使用 LoRA 进行多语言建模,同时保持基础模型的权重,仅在语言家族之间更新轻量级 LoRA 参数。类似地,FedHLT[122]采用 LoRA 与分层语言树策略,在联邦学习设置中最小化通信开销的同时,实现了跨方言的高效适应。LAMPAT[136]利用 LoRA 通过对抗训练进行无监督多语言释义,在跨语言保留语义的同时生成多样化的输出。HyperLoRA[137]开发了一种新颖的方法,使用语言特征向量生成特定方言的 LoRA 适配器,实现了对未见过的英语方言的零样本适应,而无需方言训练数据。
医学和临床文本处理:医学和临床文本处理由于数据可用性有限和敏感性而面临独特的挑战,特别是在临床数据集中。LoRA 已成为解决这些限制的有前途的解决方案。Ji 等人[138]利用 LoRA 增强了临床环境中的断言检测,在最小的数据量下有效提高了分类准确性。Le 等人[139]也证明了 LoRA 可以有效地将预训练模型适应于临床 NLP 任务,特别是在数据有限的环境中。Liu 等人[92]引入了一个结合 LoRA 和 MoE 的多任务框架,以解决临床多任务场景中的数据不平衡问题。Shi 等人[140]在他们的 MedAdapter 框架中利用 LoRA 进行有效的测试时适应,从而避免了大量的计算资源或与第三方共享数据。Christophe 等人[141]对他们提出的 Med42 模型进行了比较研究,其中 LoRA 微调在关键医学基准测试(如 USMLE)上优于传统方法。
此外,LoRA 还应用于其他语言任务,包括对话中的情感理解[142]、多模态关系提取[143]和个性化文本处理[144]。
5.2 LoRA 在计算机视觉中的应用
LoRA 已有效地应用于各种视觉基础模型,如 ViTs[145]、DinoV2[146]、MAE[6]、SAM[7]和 Florence[147],增强了它们在多个视觉任务中的适应性,包括视觉理解和视觉生成。
5.2.1 视觉理解
视觉理解包含广泛的任务,包括域适应、语义分割和内容真实性检查。
- 域适应和迁移学习:将在大量自然图像数据集上训练的基础模型适应到特定领域,如医学成像或卫星数据,由于特定领域数据有限和计算约束,通常具有挑战性。为了解决这些挑战,几项研究探索了 LoRA 在各种视觉任务中的高效域适应和迁移学习应用。
ExPLoRA[148]通过在自注意力机制内纳入 LoRA 模块扩展了预训练的 ViTs,有效地在低维空间中建模特定领域的风格变化,如卫星图像中的风格变化。类似地,MeLo[149]展示了基于 LoRA 的微调在医学成像应用中的有效性,包括胸部疾病分类任务。此外,Kong 等人[150]将 LoRA 应用于增强视觉变压器在不同操作技术和数据集上的人脸伪造检测的泛化能力。
在这个方向上的一个显著进展是 ConvLoRA[151],它将 LoRA 范式扩展到卷积神经网络,用于医学图像的无监督域适应。该架构将可训练的低秩分解矩阵与自适应批量归一化相结合,建立了一个更强大的域转移框架。
-
语义分割:视觉基础模型的适应,特别是 Segment Anything Model(SAM)[7],通过 LoRA 集成在语义分割方面取得了显著进展。ConvLoRA[151]增强了 SAM[7]在遥感、医学和农业图像中的语义分割能力。在此基础上,SAMed[152]展示了基于 LoRA 的微调在多器官分割任务中的有效性。SurgicalSAM[153]将类似的技术应用于机器人手术器械分割领域。
-
内容真实性检查:随着生成模型的进步,检测合成内容变得越来越重要。CLIPMoLE[154]提出了一种架构,通过在 MoE 框架内结合共享和单独的 LoRA 模块,对 ViT 块进行混合方法的适应。这种设计使 CLIP ViT 模型能够针对不同生成技术进行高效的可转移图像检测微调。类似地,MoEFFD[155]将 LoRA 与卷积适配器模块集成,同时保持冻结的 ViT 骨干网络,专门用于人脸伪造检测。
除了上述应用,LoRA 还在增强模型鲁棒性[156]、视觉跟踪任务[157]等方面显示出潜力。
5.2.2 视觉生成
通过训练额外的小网络,LoRA 使原始预训练模型,如扩散模型[10,158],能够适应个性化风格和任务,而无需重新训练整个基础模型。
-
图像风格化:LoRA 已成为图像风格化任务的关键技术,因为它能够快速将扩散模型适应到特定艺术风格,同时保留基础模型的多样化生成能力。[159]利用 LoRA 有效地微调 Stable Diffusion[10]以实现漫画风格转移,特别是将其适应到 Calvin 和 Hobbes 漫画的风格。Frenkel 等人[160]引入了 B - LoRA,它利用 Stable Diffusion XL[161]的架构隐式地分离单个图像的风格和内容组件。B - LoRA 实现了风格 - 内容分离,使各种图像风格化任务成为可能,包括图像风格转移和基于文本的图像风格化。Borse 等人[162]提出了 FouRA,它在频域而不是直接在模型权重上进行低秩适应。FouRA 解决了在使用标准 LoRA 微调扩散模型时可能出现的分布崩溃和数据复制问题。
-
多概念定制:在视觉生成中使用 LoRA 的另一个常见动机是解决生成涉及多个主题或风格的复杂图像的挑战。Shah 等人[163]提出了 ZipLoRA,采用嵌入分解的 LoRA 和梯度融合来合并独立训练的 LoRAs,而无需权重操作,保留了概念身份。Gu 等人[164]引入了 Mix - of - Show,它在扩散过程中利用 LoRA 切换和组合。类似地,Zhong 等人[165]研究了 LoRA 切换和组合方法,在去噪过程中交替或集成 LoRAs 以提高多元素生成。Yang 等人[166]提出了 LoRA - Composer,一种无需训练的方法,将多个 LoRAs 与概念注入和隔离约束相结合,以减轻概念消失和混淆等问题。Po 等人[167]提出了正交适应,鼓励不同概念的定制权重正交,使独立微调的模型能够有效合并,而不影响保真度。
LoRA 还应用于无分辨率生成任务,Cheng 等人[168]的 ResAdapter 利用 LoRA 解决了生成任意分辨率图像同时保持其原始风格域的挑战。Wang 等人[169]通过 FiTv2 进一步推进了这一领域,引入了增强的模型架构和训练策略,用于无分辨率图像生成。
无论是解决多概念合成、高分辨率任务、风格转移还是持续学习,LoRA 都提供了一种轻量级解决方案,使 Stable Diffusion 和 CLIP 等模型能够在适应新的和复杂任务的同时保持高性能。
5.3 LoRA 在语音识别中的应用
LoRA 在语音识别任务中得到了广泛应用,特别是在高效微调基础模型如 Wav2vec2[8]和 Whisper[170]方面。
在假音频检测中,Wang 等人[171]应用 LoRA 微调 Wav2vec2 模型[8],在减少可训练参数 198 倍的情况下,实现了与全量微调相当的性能。对于多语言自动语音识别(ASR),Xu 等人[172]提出了 O - LoRA 和 O - AdaLoRA 来适应 Whisper 模型[170]以适应低资源语言,如维吾尔语和藏语。类似地,Song 等人[173]提出了 LoRA - Whisper,将 LoRA 纳入 Whisper,有效地减轻了语言干扰,并便于添加新语言而不降低现有性能。Liu 等人[174]引入了 LoRA - Whisper,通过与瓶颈适配器比较,将 LoRA 扩展到低资源 ASR,在七种低资源语言上微调 Whisper。
5.4 LoRA 在代码工程中的应用
在代码工程领域,LoRA 已成为增强代码审查、修复和生成等过程的变革性方法。
对于代码审查和分析,Lu 等人[175]引入了 LLaMA - Reviewer,它使用不到 1%的可训练参数微调 LLaMA 以进行审查预测、评论生成和代码优化任务。Silva 等人[176]开发了 RepairLLaMA,它采用轻量级修复适配器进行自动程序修复,能够在资源受限环境中有效部署。
对于代码生成和总结,Kumar 等人[177]开发了基于 LoRA 的联邦学习方法用于代码总结,在不直接访问源代码的情况下保护数据隐私。Cui 等人[178]引入了 OriGen,它利用代码到代码增强和自反思技术生成高质量的寄存器传输级(RTL)代码。
5.5 LoRA 在科学发现中的应用
LoRA 已在广泛的科学领域中得到应用,包括分子任务[96,179,180,181,182]和材料科学[96]。
在蛋白质分析领域,Zeng 等人[179]开发了 PEFT - SP,一个利用 LoRA 微调大型蛋白质语言模型(PLMs)如 ESM - 2[183]以进行信号肽预测的框架。这种方法显著提高了性能,特别是对于罕见肽类型,同时减轻了过拟合并保持了低计算成本。类似地,Schmirler 等人[180]将 LoRA 应用于 PLMs,如 ProtT5[184]和 ESM - 2,在各种蛋白质相关任务中,展示了加速训练和改进下游预测,同时防止灾难性遗忘。在另一个分子应用中,Schreiber[181]在 ESMBind 和 QBind 模型中采用了 LoRA 及其量化版本 QLoRA[55],用于蛋白质结合位点和翻译后修饰预测。这些模型在不依赖结构数据或多序列比对的情况下,在未见过的蛋白质序列上实现了增强的泛化能力。Lv 等人[185]引入了 ProLLaMA,展示了一种具有不同秩的两阶段 LoRA 方法能够实现有效的蛋白质语言学习,同时保持自然语言能力。
在更一般的科学领域,Buehler 等人[96]开发了 X - LoRA,一个动态组合多个专门的 LoRA 适配器的框架。这种方法在解决蛋白质力学和材料设计中的逆向和正向问题方面表现出卓越的能力,说明了 LoRA 在复杂多学科应用中的潜力。
5.6 LoRA 在推荐系统中的应用
在推荐系统中,LoRA 有效地微调大型语言模型以进行点击率(CTR)预测和顺序推荐任务。
对于 CTR 预测,Yang 等人[186]提出了 MLoRA,实施特定领域的低秩矩阵以捕获域间变化并增强个性化,已在阿里巴巴成功部署。Zhu 等人[187]引入了 RecLoRA,用元 LoRA 结构替换单个 LoRA 矩阵,使用软路由为每个用户不断变化的兴趣选择个性化的矩阵组合。
对于顺序推荐,Qin 等人[188]引入了 ATFLRec,它通过独立优化每个模态的 LoRA 模块集成音频和文本数据。Zheng 等人[189]开发了 LLM - TRSR 用于文本丰富的推荐场景,利用 LoRA 的高效微调来处理大规模文本数据,同时保持实时性。Kong 等人[190]开发了 iLoRA,采用 MoE 框架,为不同的用户行为模式创建专门的 LoRA 模块,根据个人交互序列动态调用相关专家。最近,Ji 等人[191]提出了 GenRec,这是一种纯文本的 LLM,使用项目名称作为 ID,并利用 LoRA 微调 LLaMA,在大规模数据集上表现出优异的性能,其中 LLM 可以直接从文本表示中学习协作信息。
5.7 LoRA 在图学习中的应用
最近,研究人员也探索了 LoRA 在非欧几里得数据(即图)上的应用,微调图神经网络(GNN)[192]以适应新图或现有图的结构更新。
对于跨域图神经网络适应,Yang 等人[193]引入了 GraphLoRA,它构建了一个小型可训练的 GNN 与预训练的 GNN 一起,以弥合不同图之间的结构和特征分布差距。通过对可训练的 GNN 参数应用低秩分解,并结合基于图结构的正则化,GraphLora 可以通过仅微调 20%的参数有效地将预训练的 GNN 适应到不同的图域。
对于动态知识图学习,Liu 等人[194]开发了 IncLoRA,它使实体和关系嵌入适应连续的图更新。IncLoRA 根据新的知识嵌入与保留图的距离将它们分组到显式的 LoRA 层中,并使用图的结构属性自适应地分配秩尺度。
5.8 LoRA 在时空预测中的应用
多元时间序列数据在现实世界的场景中非常普遍,如交通、天气预报和经济学[195]。最近的研究探索了使用 LoRA 来解决这个领域的特定挑战,如节点特定适应、多通道建模和域外预测。
对于节点特定适应,Ruan 等人[196]提出了 ST - LoRA,它实现了节点自适应的 LoRA 层,为每个节点添加额外的可学习参数。通过在 LoRA 层之间引入残差结构以避免过参数化,ST - LoRA 有效地捕捉了交通数据集中不同节点的独特模式和动态。
对于多通道建模,Nie 等人[197]引入了 C - LoRA,它在通道依赖和通道独立策略之间取得平衡。C - LoRA 用低秩因子化适配器参数化每个通道,以形成身份感知嵌入,然后将这些嵌入输入到全局共享的预测器中,用于建模跨通道依赖关系。
对于域外预测,Gupta 等人[198]分析了基于 LoRA 的微调在领先的时间序列基础模型(如 Lag - Llama[199]、MOIRAI[200]和 Chronos[201])上的有效性,显示在降低计算成本的同时,提高了重症监护病房中脓毒症患者生命体征的预测。Ren 等人[202]引入了 TPLLM,它将可训练的秩分解矩阵注入到 GPT - 2 变压器块中用于交通预测,有效地使模型适应处理有限历史交通数据的时空表示。
5.9 LoRA 在多模态中的应用
多模态基础模型(MFMs)在共享表示空间中结合了不同的数据模态,包括文本、音频、图像、视频等,实现了跨模态推理和理解。LoRA 通过优化训练效率和加强模态间的对齐来增强这些模型。语言 - 视觉和语言 - 音频学习是 LoRA 广泛应用于适应 MFMs 的两个主要领域。
5.9.1 语言 - 视觉学习
在语言 - 视觉学习任务中,LoRA 已被应用于特别是增强视觉 - 语言能力和定制扩散模型。
-
基于语言 - 视觉模型的适应:Sung 等人[203]通过微调 CLIP - BART 来适应视觉 - 语言模型,用于视觉问答和图像字幕。Ji 等人[204]通过基于聚类的 LoRA 增强了视觉 - 语言模型在跨模态检索中的对抗鲁棒性。此外,Zong 等人[205]提出了 MoVA,通过粗到细的适配器机制有效地路由和融合多个视觉基础模型(CLIP[15]、DINOv2[146]、SAM[7])。
-
基于扩散模型的定制:各种方法利用 LoRA 有效地适应 Stable Diffusion(SD)模型。对于概念定制,Kumari 等人[206]引入了带有 LoRA 的域适配器层的自定义扩散,用于少样本概念学习,而 Li 等人[207]开发了 SELMA,用于训练和合并多个特定技能的 LoRA 专家而无干扰。Lu 等人[208]通过带有交叉注意力细化的 LoRA 模块推进了概念操作,用于选择性概念擦除。其他应用包括用于 360 度全景生成的 StitchDiffusion[209]、中国园林图像合成[210]、用于提高生成保真度的 DreamSync[211]、用于细粒度控制的 Block - wise LoRA[212]和用于运动适应的 AnimateDiff[213]。
在视觉 - 语言模型适应中,LoRA 通过诸如 CLIP - BART 微调[203]、基于聚类的方法[204]和多模型融合[205]等技术增强了跨模态理解。对于扩散模型定制,LoRA 实现了高效的概念学习[206]、选择性操作[208]和从全景创建[209]到运动适应[213]等专门的生成任务。
5.9.2 语言 - 音频学习
在语言 - 音频学习任务中,LoRA 已成为解决基础模型中音频和文本表示之间模态差距这一基本挑战的关键技术。应用主要分为两类:语音识别和音频内容理解与生成。
-
语音识别:Fathullah 等人[214]引入了一种直接音频嵌入方法,其中 LoRA 专门适应自注意力层以实现音频 - 文本对齐,使大型语言模型能够有效地处理音频输入。Fathullah 等人[214]证明了 LLM 可以通过在文本标记前添加音频嵌入来执行多语言 ASR,通过 LoRA 仅调整关键模型参数,同时在与专门的 ASR 系统竞争中表现出色。Yusuf 等人[215]提出了推测性语音识别,通过将基于 RNN - Transducer 的 ASR 系统[216]与使用 LoRA 适应的音频前缀语言模型相结合,允许模型生成推测性预测。Palaskar 等人[217]进一步引入了 FLoRA,具有特定模态的适配器,可以选择性地启用,为多模态集成提供了一个强大的框架。
-
语音内容理解与生成:Liu 等人[218]提出了 LOAE 用于自动音频字幕(AAC),它将基于 CED 的音频编码[219]与 LLaMA 用于文本解码相结合,通过 Q - Former[220]桥接,并通过基于 LoRA 的适应进行优化。Qin 等人[188]引入了 ATFLRec,一个多模态推荐系统,利用单独的 LoRA 模块有效地微调 LLM 中的音频和文本模态,通过其融合方法展示了优异的性能。
这些在语言 - 音频学习中的发展确立了在多模态背景下应用 LoRA 的几个关键原则:(1)特定模态适应路径的重要性[214,217],(2)选择性参数更新对于跨模态对齐的有效性[215,218],以及(3)在融合之前通过专门的 LoRA 模块保持不同表示空间的价值[188,217]。
6 挑战与讨论
虽然 LoRA 在有效地适应不同领域的基础模型方面取得了显著成功,但仍有几个关键挑战和进一步研究的机会。
理论理解:当前的理论框架主要关注简化的设置或特定的架构[72],在理解 LoRA 在更复杂场景中的行为方面存在差距。例如,LoRA 适应与预训练模型知识之间的相互作用尚未完全理解,特别是在 LoRA 如何在修改特定任务特征的同时保留有用特征方面。开发能够解释 LoRA 在不同架构和任务中的有效性的更全面的理论框架对于指导未来的改进将是有价值的。
架构设计原则:当前的 LoRA 实现通常依赖于经验观察,而不是系统的设计方法[17,221]。关于最优适配器放置策略、跨网络深度的秩确定以及适应空间的几何性质等关键问题仍然存在。最近对非欧几里得几何(如双曲空间[222])的探索表明,在捕获模型适应中的层次关系方面可能具有潜在优势。一个用于分析这些设计选择的统一框架可以显著推进我们对参数效率与模型容量权衡的理解。
计算效率:随着大型语言模型的不断扩展,LoRA 的可扩展性变得越来越关键。在处理可变长度序列时管理并发适应在内存利用和计算开销方面带来了重大挑战。适配器模块和 KV 缓存张量的动态管理可能导致内存碎片化和增加的 I/O 成本[129]。先进的服务架构和优化技术对于在生产环境中保持低延迟至关重要,特别是在处理多个并发适应请求时。
鲁棒性和验证:在关键应用中部署 LoRA 适应的模型需要强大的验证方法。当前的研究在分布转移和对抗条件下对模型行为的研究不足[223]。开发严格的不确定性量化方法和形式验证技术变得至关重要,特别是对于医疗保健和自主系统等高风险应用,其中模型可靠性直接影响人类安全。
隐私和安全:随着 LoRA 的广泛应用,特别是在联邦学习设置中,隐私和安全考虑变得越来越重要。这包括保护 LoRA 适应中的敏感信息,防止未经授权访问或操纵适应的模型,并确保 LoRA 更新不会无意中泄露私人信息[110,224]。需要研究隐私保护的 LoRA 适应技术和安全的方法来共享和组合 LoRA 模块。
未来的研究方向应侧重于:建立统一 LoRA 各种设计方面的综合理论框架;开发用于最优适配器配置的自动架构搜索方法;创建用于大规模部署的高效服务基础设施;实施用于可靠性评估的标准化评估协议;以及将先进的隐私保护机制集成到适应过程中。
此外,随着新型架构的出现,如 Mamba[225],研究 LoRA 对这些新范式的适用性变得至关重要。将 LoRA 集成到边缘计算和实时系统[226]中提出了与硬件优化和系统设计相交的额外挑战,需要跨学科的研究努力。
7 结论
在本综述中,我们对 LoRA 进行了系统分析,研究了其理论基础、技术进步以及在适应基础模型方面的各种应用。LoRA 在从自然语言处理和计算机视觉到语音识别和科学计算等不同领域的广泛应用凸显了其通用性和有效性。它在保持模型性能的同时显著降低计算和存储要求的成功,使其在资源受限环境和特定领域适应中特别有价值。
尽管取得了这些成就,但仍存在几个关键挑战。支撑 LoRA 有效性的理论框架需要进一步发展,特别是在理解低秩适应与模型能力之间的相互作用方面。此外,关于可扩展性、鲁棒性和在生产环境中的安全部署等问题仍然是持续研究的机会。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 2210
2210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









