






在大模型项目的研发过程中,模型训练 是最关键的一步。如何有效地设置训练参数、加载数据、计算损失并优化模型参数,是每个AI从业者都需要掌握的技能。对于新手来说,模型训练的各个环节可能显得复杂难懂,但只要掌握了每个步骤的核心原理和操作方法,整个过程其实并不难。本文将通过详细的讲解和代码示例,带你一步一步理解并实现模型训练。无论你是AI领域的初学者,还是有一定经验的从业者,都可以从本文中学习到宝贵的知识。
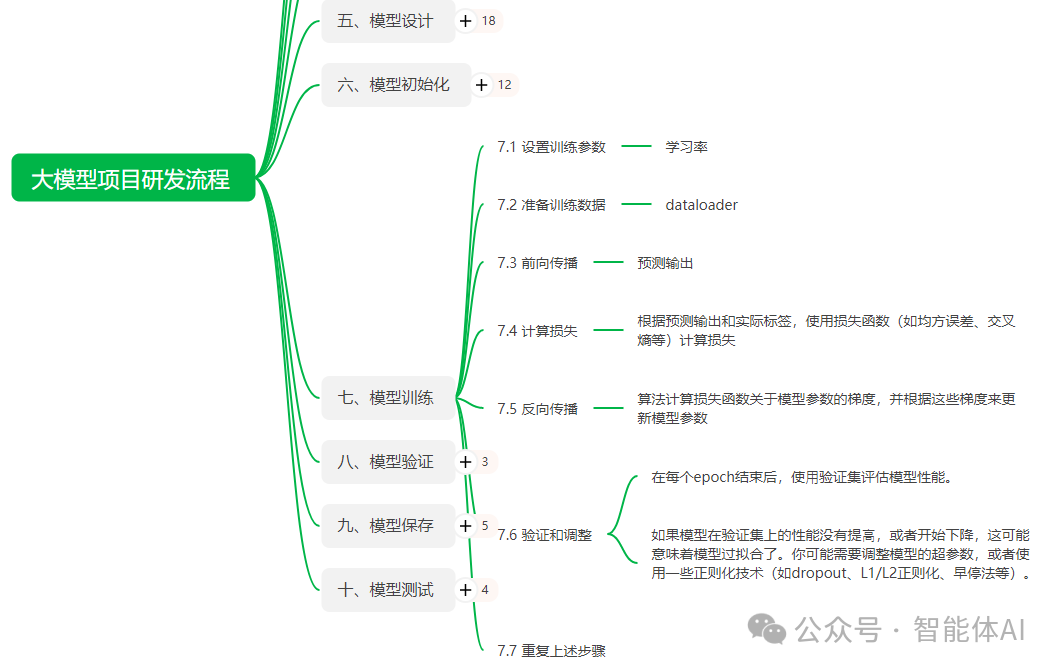
一、设置训练参数:学习率的重要性
1、什么是学习率?
在深度学习中,学习率(Learning Rate)是一个非常重要的参数,它决定了每次模型参数更新的步伐大小。学习率可以理解为模型“学习”的速度。如果学习率设置得太大,模型可能会在训练过程中跳过最优解,无法正确收敛;而如果学习率太小,模型的学习过程会非常缓慢,甚至可能陷入局部最优解,难以得到最佳效果。
2、如何选择合适的学习率?
选择合适的学习率是模型训练中的一个挑战。一般来说,可以从较小的值(例如 0.001 或 0.01)开始,然后根据训练效果逐步调整。此外,还可以使用学习率调度器,在训练过程中动态调整学习率,使模型在不同阶段有不同的学习速度。
3、代码示例:如何设置学习率
下面是一个简单的 PyTorch 代码示例,展示了如何设置学习率并使用学习率调度器动态调整它:
import torch
import torch.optim as optim
# 定义一个简单的线性模型
model = torch.nn.Linear(10, 2)
# 设置初始学习率
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 使用学习率调度器来动态调整学习率
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 在每个epoch结束后调整学习率
for epoch in range(50):
# 模型训练过程...
scheduler.step()
print(f'Epoch {epoch+1}: 当前学习率: {scheduler.get_last_lr()}')
在这个示例中,学习率调度器 StepLR 会每过10个 epoch 把学习率降低到原来的 0.1 倍,确保模型在训练后期学习得更为精细。
4、常见问题与解决方案
-
学习率过大:模型的损失值会在训练过程中剧烈波动,表现为训练不稳定,甚至无法收敛。解决方案:尝试减少学习率,或引入学习率调度器。
-
学习率过小:模型训练速度非常慢,可能需要很长时间才能收敛,或者最终只能达到局部最优解。解决方案:适当增大学习率,确保模型能够快速进入优化阶段。
二、准备训练数据:如何高效加载数据
1、什么是 DataLoader?
在深度学习的训练过程中,我们通常使用大量的数据来让模型从中学习。为了高效地处理这些数据,PyTorch 提供了 DataLoader,它可以将数据集分批次加载,并支持多线程处理,加快数据的加载速度。
DataLoader 可以自动将数据分成小批次(mini-batches),并在每次训练循环中将这些小批次逐一传递给模型。这样做的好处是,能够节省内存并且加快计算速度。
2、如何使用 DataLoader?
DataLoader 的使用非常简单,下面是一个典型的代码示例:
from torch.utils.data import DataLoader, TensorDataset
# 假设我们有一些数据和标签
data = torch.randn(100, 10) # 随机生成100条数据,每条数据有10个特征
labels = torch.randn(100, 2) # 随机生成100条对应的标签,每个标签有2个值
# 创建数据集
dataset = TensorDataset(data, labels)
# 使用 DataLoader 加载数据,设置每批次数据大小为32
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 在训练过程中使用
for batch_data, batch_labels in dataloader:
# 在这里你可以对 batch_data 和 batch_labels 进行操作
output = model(batch_data)
loss = criterion(output, batch_labels)
3、常见问题与解决方案
-
数据加载过慢:默认情况下,DataLoader 是单线程的。为了提高数据加载速度,可以通过设置 num_workers 参数来启用多线程加速数据加载,例如 DataLoader(dataset, batch_size=32, num_workers=4)。
-
数据不平衡:如果你的数据集存在类别不平衡问题,模型可能会对某些类别的样本表现得更好,而忽略了其他类别。解决方法是使用加权损失函数或采样技术,以确保每个类别在训练中得到合理的权重。
三、前向传播:模型如何生成预测结果
1、什么是前向传播?
前向传播 是模型训练中的关键步骤,它描述了如何从输入数据中生成预测结果。在这个阶段,模型会根据当前的参数,逐层计算每个神经元的激活值,最终得到输出结果。前向传播是一个单向的计算过程,不涉及参数更新。
2、代码示例:如何进行前向传播
# 选择损失函数,这里使用均方误差(MSELoss)
criterion = torch.nn.MSELoss()
# 计算损失
loss = criterion(output, batch_labels)
3、前向传播的计算流程如下:
-
将输入数据传入第一层神经网络。
-
经过激活函数的处理,传递到下一层。
-
依次传递,直到最后一层生成最终的输出结果。
4、常见问题与解决方案
- 输出不稳定:如果模型输出的结果不稳定,可能是因为模型初始化不当或者学习率设置不合适。解决方案是使用标准的初始化方法(如 He 初始化或 Xavier 初始化),并调试学习率。
四、计算损失:衡量模型的预测效果
1、什么是损失函数?
损失函数 是用于衡量模型预测结果与真实标签之间差距的函数。损失函数的值越小,说明模型的预测结果越接近真实值。常见的损失函数有均方误差(MSE,适用于回归问题)和交叉熵损失(Cross-Entropy,适用于分类问题)。
2、代码示例:如何计算损失
# 选择损失函数,这里使用均方误差(MSELoss)
criterion = torch.nn.MSELoss()
# 计算损失
loss = criterion(output, batch_labels)
在这个示例中,我们使用了均方误差损失函数 MSELoss,它计算模型输出 output 和真实标签 batch_labels 之间的差距,返回一个损失值 loss。这个损失值反映了模型的预测误差。
3、常见问题与解决方案
-
损失值过高:如果损失值过高,说明模型的预测效果较差。可以尝试调低学习率,或者增大模型的容量(增加神经网络的层数或宽度)。
-
损失值震荡:如果损失值在训练过程中剧烈波动,可能是学习率过大,尝试使用更小的学习率,或采用学习率调度器。
五、反向传播:更新模型参数
1、什么是反向传播?
反向传播 是深度学习中的核心算法,它通过计算损失函数对每个模型参数的偏导数,进而更新模型的参数。反向传播使用的是链式法则,将误差逐层传播回去,以指导每一层的参数更新。
2、如何进行反向传播?
在反向传播中,模型首先计算损失函数的梯度,然后根据这些梯度更新模型参数。我们通常使用优化器(如 SGD 或 Adam)来完成这个过程。
3、代码示例:如何进行反向传播
# 清除之前的梯度
optimizer.zero_grad()
# 反向传播:计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
六、验证与调整:避免过拟合与欠拟合
1、什么是过拟合与欠拟合?
-
过拟合:模型在训练集上表现很好,但在验证集上表现较差,说明模型过于“记住”了训练集的数据,无法推广到新的数据。
-
欠拟合:模型在训练集和验证集上都表现不佳,说明模型的容量不足,无法很好地拟合数据。
2、如何避免过拟合?
-
增加数据:通过数据增强(如随机裁剪、旋转等)增加数据集的多样性。
-
正则化:使用正则化技术(如 L2 正则化或 Dropout)来防止模型过于复杂。
3、代码示例:如何使用 Dropout
# 在模型的某一层添加 Dropout
dropout_layer = torch.nn.Dropout(p=0.5)
# 在前向传播时,应用 Dropout
output = dropout_layer(model(batch_data))
4、常见问题与解决方案
-
过拟合严重:可以尝试增加数据集的规模,或者减少模型的复杂度(如减少层数或神经元数量)。
-
欠拟合:增加模型的复杂度,或者训练更长时间。
七、重复上述步骤,直到模型收敛
模型训练是一个反复迭代的过程,我们会多次执行前面的步骤,直到模型在验证集上表现稳定为止。
for epoch in range(num_epochs):
model.train() # 切换到训练模式
for batch_data, batch_labels in dataloader:
output = model(batch_data)
loss = criterion(output, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 进行验证
model.eval()
with torch.no_grad():
val_output = model(validation_data)
val_loss = criterion(val_output, validation_target)
print(f'Epoch {epoch+1}, 验证损失: {val_loss.item()}')
scheduler.step()
八、总结
通过本文,我们详细解析了模型训练的各个环节,包括学习率的选择、数据的加载、前向传播与反向传播、损失计算、验证与调整等。希望通过这些详尽的讲解,能够帮助你更好地掌握模型训练的全流程。
核心要点:
-
学习率调优 是训练模型的重要一环,可以通过调度器动态调整。
-
DataLoader 提供了高效的数据加载方式,加快训练速度。
-
损失计算和反向传播 是模型学习的核心,通过优化器进行参数更新。
-
验证集 可以帮助我们监控模型的性能并避免过拟合。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









