







超长的上下文窗口已经成为最新一代语言模型的标配,例如GLM-4-9B-1M,Gemini 1.5等,这种模型常常被广泛应用于长文档问答场景。
然而,当前的长文本模型并没有在其回答中标注出每句话在原文中的依据,而由于文档过长,用户很难去验证模型提供的信息。此外,模型的输出也常常会出现幻觉,并不忠于原文,这严重影响了模型的可信性。
针对这一问题,通常会通过RAG或者后处理的方式,让大模型在回复中加入引用信息。这种方式在开放域问答和智能搜索引擎(例如 New Bing,Perplexity AI)中被广泛应用。
但 RAG 在长文本问答中,往往会丢失文本信息,使得模型回复的正确性下降。而后处理方式会让pipeline变得特别复杂,用户需要等待很长时间。
我们不仅要问,我们是否可以让模型具备生成回答的同时直接生成引用,同时既不丢失文本信息,又不增加处理时间?
经过深入的思考和实验,我们找到了一种方案:用带有细粒度引用的标注数据,SFT微调模型。
效果如下:
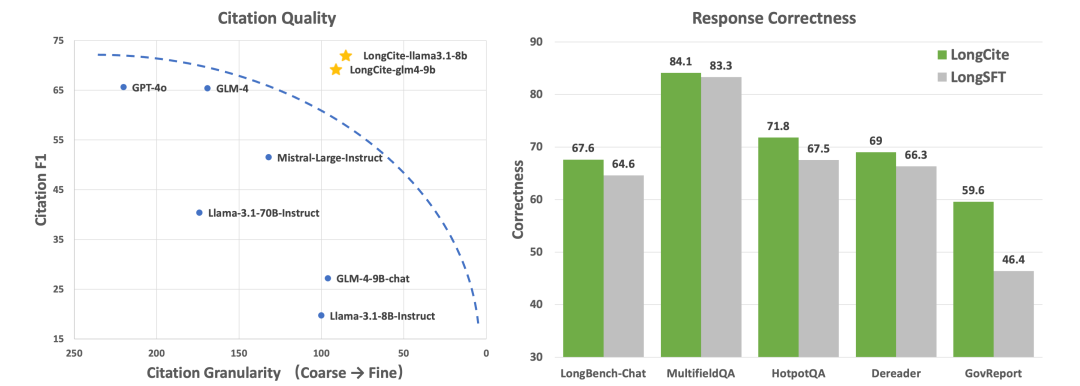
可以看到,训练的模型 LongCite 无论在引用质量,还是回复正确性都处于较高水平。
代码: https://github.com/THUDM/LongCite
数据:
-
HF:https://huggingface.co/datasets/THUDM/LongCite-45k
-
魔搭:https://modelscope.cn/datasets/AI-ModelScope/LongCite-45k
模型:
-
HF:https://huggingface.co/THUDM
-
魔搭:https://modelscope.cn/organization/ZhipuAI
Demo:https://huggingface.co/spaces/THUDM/LongCite
论文: https://arxiv.org/abs/2409.02897
视频: https://www.bilibili.com/video/BV1QD4zexEU2/
一、能力评测:LongBench-Cite
在训练模型之前,我们首先需要确定如何评测模型生成引用的能力。
我们提出了LongBench-Cite 的评测方法。这个评测集包含了来自LongBench-Chat 和 LongBench的共计 1000 条长文本问答数据,涉及单文档问答、多文档问答、文档总结等常见任务。
与以往的工作不同,我们在 LongBench-Cite 中会更加注重评测细粒度的句子级引用 —— 把引用的内容定位到句子级别。
LongBench-Cite从两个维度上,由GPT-4o进行自动判断:
-
正确性:
-
Correctness:回答是否正确,与标准答案契合;
-
Correctness Ratio: 与普通长文本问答相比,加入引用后Correctness是否受损。
-
引用质量:
-
Citation Recall: 回答中的每个事实性陈述 (statement) 是否被对应的citation所支持;
-
Citation Precision:每个citation是否包含了对应的statement的信息,不是无关的;
-
Citation F1: 2 * (R * P) / (R + P),综合考虑recall和precision;
-
Citation Length: 每个citation对应文本的长度(token数)。长度越短,说明粒度越细、定位越精准。
那么现有的这些长文本模型在 LongBench-Cite 上表现如何呢?我们采用 in-context learning的设定,即给一个示例的方式,进行测试。
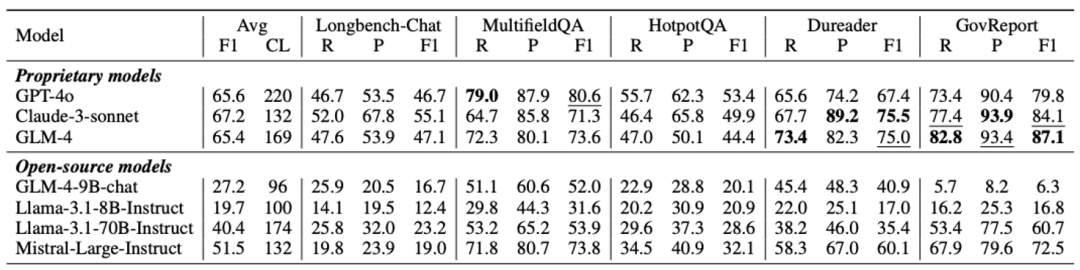
从上图可以看出
-
开源模型citation f1很低,经常生成错误的或是不符合格式的引用;
-
闭源模型citation length普遍很高,引用粒度甚至比chunk-level citation还粗,需要进一步精准定位。例如,GPT-4o平均每个引用包含了原文中的6句话
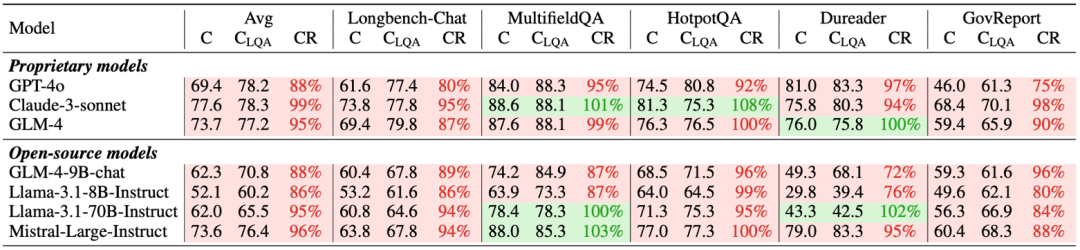
此外,In-context learning 也使得模型长文本回答能力受损,correctness ratio (CR) 普遍小于100%。
二、数据构造:CoF
根据我们的深入分析和实验,我们发现若想让模型本身拥有较强的细粒度的引用能力,只需要用较好的带有细粒度引用的长文本问答数据,对模型做 SFT 即可。
那么问题是,如何构造这样的数据?
我们提出了 CoF(Coarse to Fine)的方法,并利用现有长文本模型来自动构造数据。构造方法遵循两个原则:
-
原则一:充分利用现有模型的长文本能力,保证问答的质量。采用后处理的方式,先用普通的长文本问答得到答案,再往里加引用。
-
原则二:生成的citiation质量要高,粒度也要细。先生成粗粒度的chunk-level citation,再从中抽取出细粒度的sentence-level citation。
整个pipeline共分为 4步:
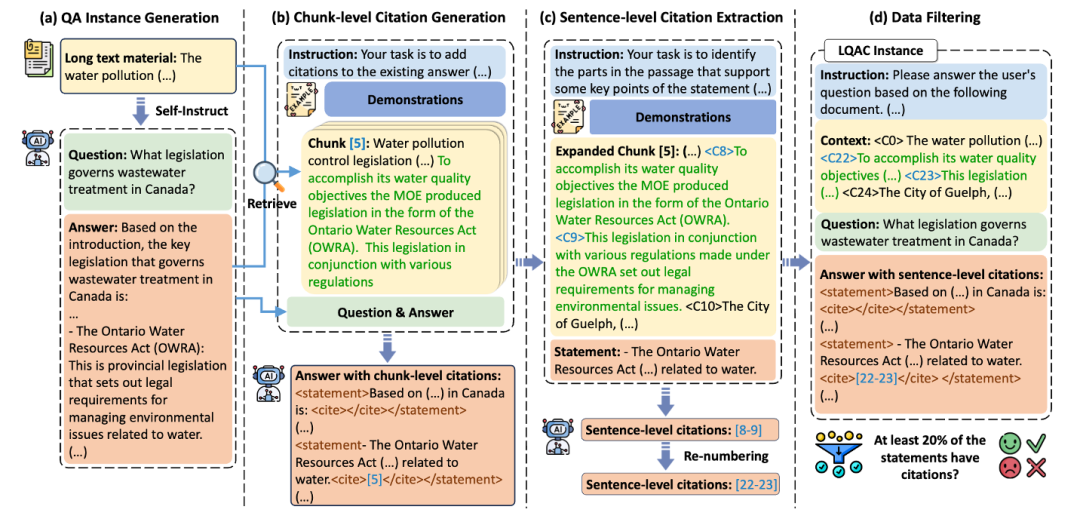
第一步,问题生成。使用self-instruction的方法,自问自答生成长文本问答对。
第二步,生成chunk-level citation。使用答案中的句子从原文检索出相关片段。再通过 in-context learning 的方式让大模型把原有答案分成statements并加入chunk-level citation。
第三步,抽取sentence-level citation:对于每个statement,将其对应的chunk-level citation中的句子补充完整,并将每个句子编号。再让大模型通过in-context learning从chunk中抽取出支持该statement的句子编号。最后根据句子在原文中的位置重新标号,得到最终的sentence-level citation。
第四步,数据筛选。将前几步的数据整理,得到最后的带有sentence-level citation的长文本问答数据。筛去引用过少的数据。这些数据可能没有忠于原文,包含有幻觉。
我们在 LongBench-Cite 上对 CoF 框架进行了验证,
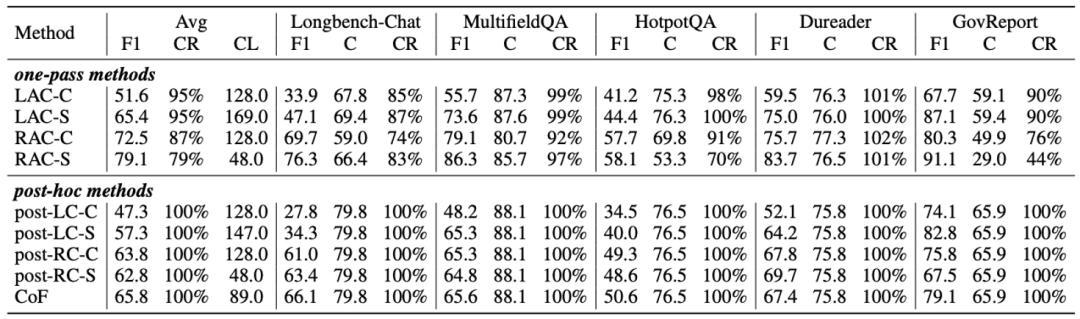
可以看到,CoF在所有post-hoc方法中取得了最高的citation F1,粒度也较细;与one-pass方法(同时生成答案和引用),CoF可以保证答案的正确性不下降。
通过收集GLM-4预训练语料中的长文档和CoF框架,我们构造了一个大规模的SFT数据集LongCite-45k。数据集包含了 44,600条带有句子级引用的高质量问答数据,其中最长可达128k token。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

三、模型训练:LongCite
我们基于支持 128k 上下文的开源模型 GLM-4-9B和 Llama-3.1-8B,并使用 LongCite-45k 和 ShareGPT 数据集进行 SFT 微调,分别得到 LongCite-9B 和 LongCite-8B。
我们在 LongBench-Cite 评测集上对两个模型进行验证。
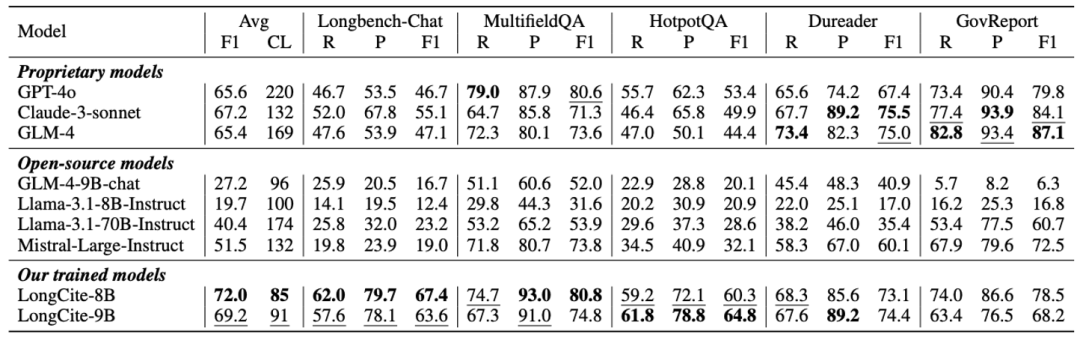
可以看到LongCite 模型的引用质量明显超过现有的长文本模型:Citation F1最高,且 Citation Length 相比原模型也有明显缩短,在同等F1的情况下,LongCite 模型的Citation Length 比 GPT-4o缩短了一倍还多,能够实现精准的定位。
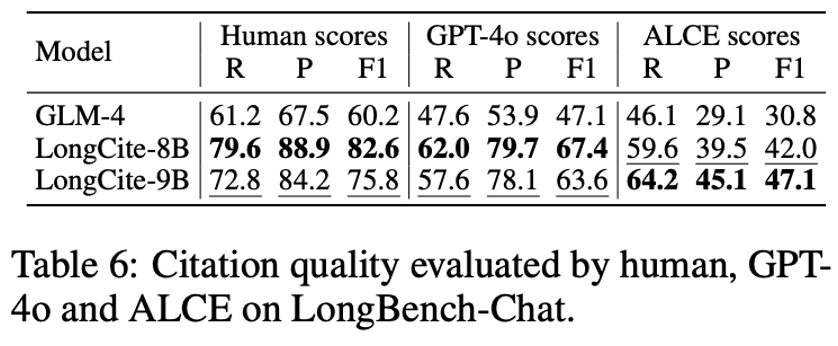
我们在 LongBench-Chat 上的人类评估,也证明 LongCite模型的引用质量更高。
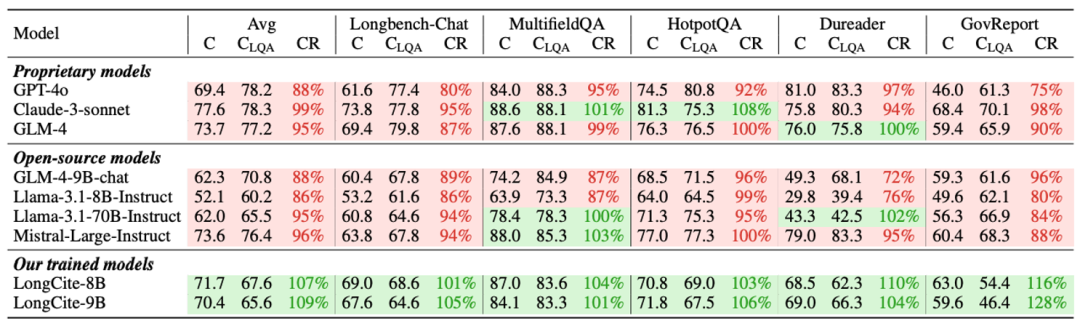
另一方面,在回答正确性上,LongCite模型也超越了 GPT-4o和Llama-3.1-70B。且相较于普通长文本 SFT 模型,带有引用信息的 SFT 模型可以进一步提高长文本问答的正确性。
从下面的示例中,可以看到,相较于普通长文本 SFT 模型, 1)LongCite模型的幻觉会更少:

2)LongCite 模型可以更均匀地利用上下文信息:


我们也进行了消融实验
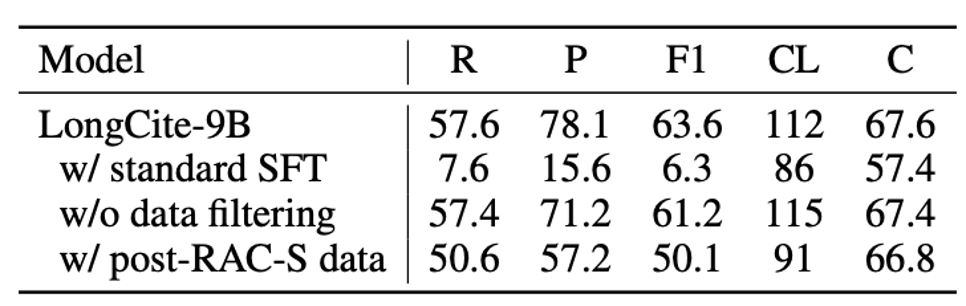
LongCite模型的引用能力来源于LongCite-45k数据集而非普通的长文本SFT。CoF中的数据筛选可以显著提高引用质量。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}