






模型:
有趣的是,当参数规模超过一定水平时,这个更大的语言模型实现了显著的性能提升,并出现了小模型中不存在的能力,比如上下文学习。为了区别于 PLM(预训练语言模型),这类模型被称为大型语言模型(LLMs)。
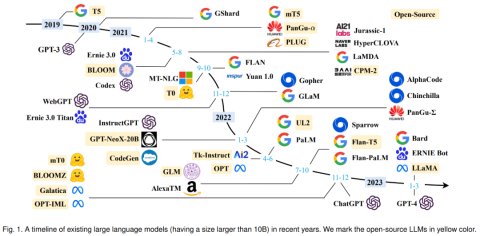
模型
LLM 的涌现能力被正式定义为「在小型模型中不存在但在大型模型中出现的能力」,这是 LLM 与以前的 PLM 区分开来的最显著特征之一。当出现这种新的能力时,它还引入了一个显著的特征:当规模达到一定水平时,性能显著高于随机的状态。以此类推,这种新模式与物理学中的相变现象密切相关。原则上,这种能力也可以与一些复杂的任务有关,而人们更关心可以应用于解决多个任务的通用能力。这里简要介绍了 LLM 的三种代表性的涌现能力:
上下文学习。GPT-3 正式引入了上下文学习能力:假设语言模型已经提供了自然语言指令和多个任务描述,它可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新。
指令遵循。通过对自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在微小的任务上表现良好,这些任务也以指令的形式所描述。这种能力下,指令调优使 LLM 能够在不使用显式样本的情况下通过理解任务指令来执行新任务,这可以大大提高泛化能力。
循序渐进的推理。对于小语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学学科单词问题。同时,通过思维链推理策略,LLM 可以通过利用涉及中间推理步骤的 prompt 机制来解决此类任务得出最终答案。据推测,这种能力可能是通过代码训练获得的。
数据
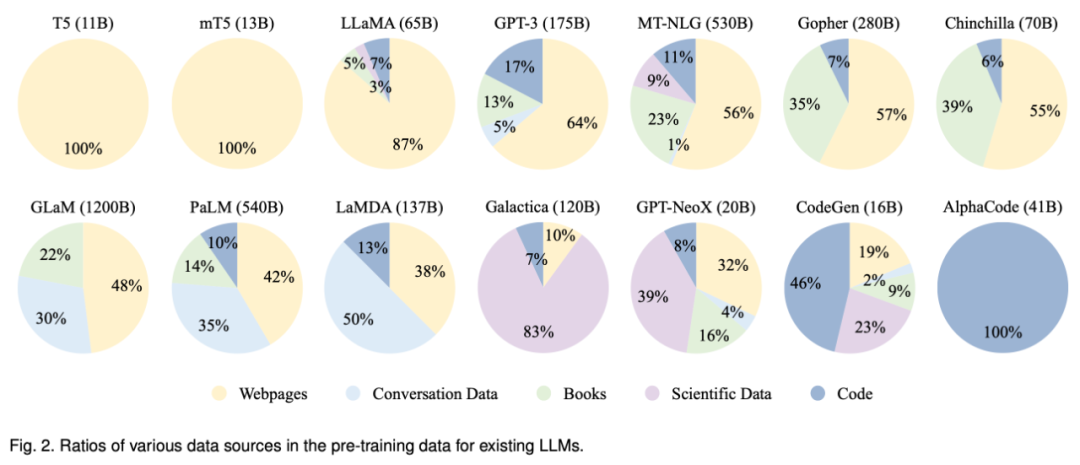
数据分布
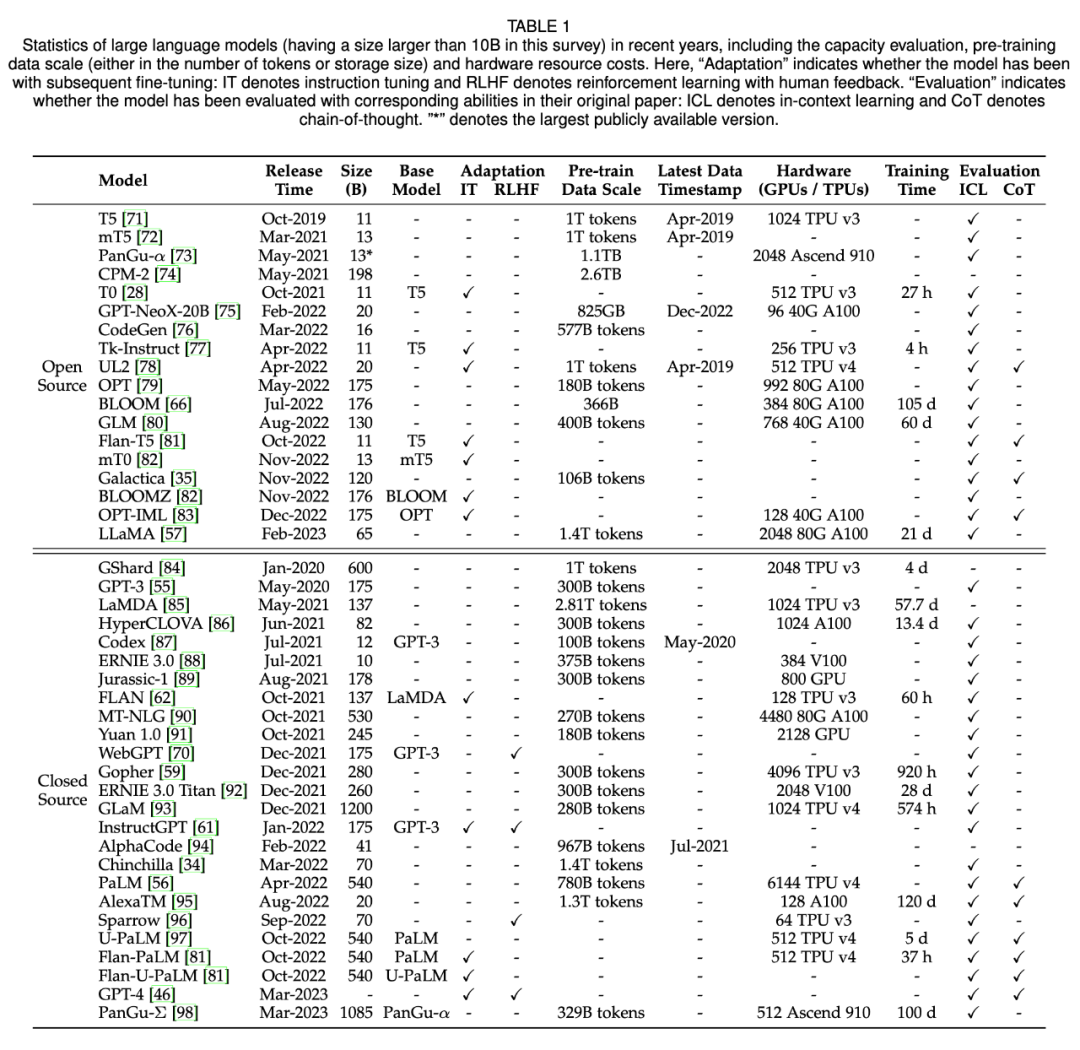
模型参数
算力
美国市场研究机构TrendForce在3月1日的报告中测算称,处理1800亿个参数的GPT-3.5大模型,需要的GPU芯片数量高达2万枚,未来GPT大模型商业化所需的GPU 芯片数量甚至超过3万枚。
自然语言处理发展到大型语言模型的历程分为五个阶段:规则、统计机器学习、深度学习、预训练、大型语言模型。
机器翻译是NLP中难度最高、综合性最强的任务。因此张俊林以机器翻译任务为例来对比不同阶段的特点以及技术栈、数据的变化,以此展示NLP如何一步步演进。
规则阶段大致从1956年到1992年,基于规则的机器翻译系统是在内部把各种功能的模块串到一起,由人先从数据中获取知识,归纳出规则,写出来教给机器,然后机器来执行这套规则,从而完成特定任务。
统计机器学习阶段大致从1993年到2012年,机器翻译系统可拆成语言模型和翻译模型,这里的语言模型与现在的GPT-3/3.5的技术手段一模一样。该阶段相比上一阶段突变性较高,由人转述知识变成机器自动从数据中学习知识,主流技术包括SVM、HMM、MaxEnt、CRF、LM等,当时人工标注数据量在百万级左右。
预训练阶段是从2018年到2022年,相比之前的最大变化是加入自监督学习,张俊林认为这是NLP领域最杰出的贡献,将可利用数据从标注数据拓展到了非标注数据。该阶段系统可分为预训练和微调两个阶段,将预训练数据量扩大3到5倍,典型技术栈包括Encoder-Decoder、Transformer、Attention等。
大型语言模型阶段从2023年起,目的是让机器能听懂人的命令、遵循人的价值观。其特性是在第一个阶段把过去的两个阶段缩成一个预训练阶段,第二阶段转换成与人的价值观对齐,而不是向领域迁移。这个阶段的突变性是很高的,已经从专用任务转向通用任务,或是以自然语言人机接口的方式呈现。















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









