






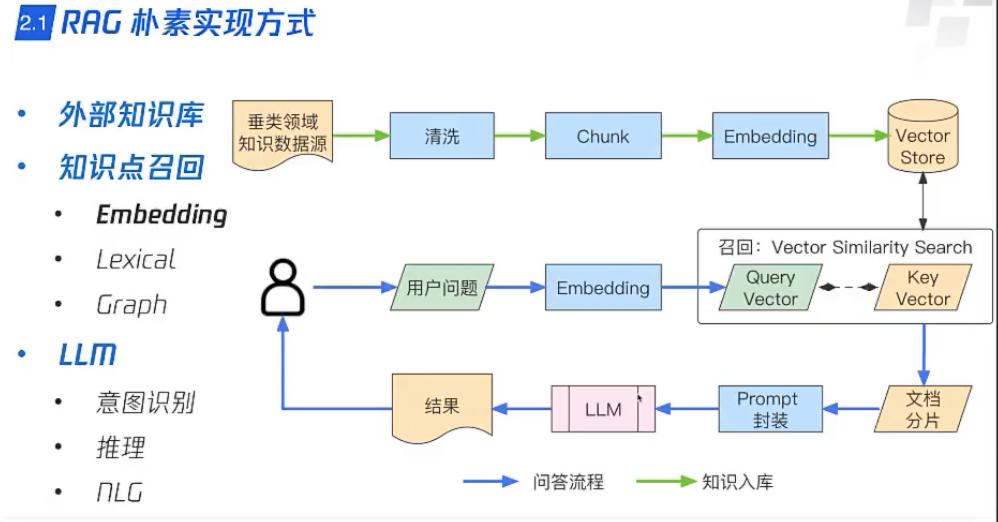
<!>什么是RAG
检索增强生成(RAG)是一种复杂的自然语言处理方法,它包括两个不同的步骤:信息检索和生成语言建模。这种方法旨在为语言模型提供访问外部数据源,来提高其在生成响应时的准确性和相关性,从而增强语言模型的能力。简单分为三步:
indexing,retrival,generation 【索引,检索,生成】
1)构建索引
embedding模型的选择
文档的分割:emebedding有上下文的限制,所以要切分文档,然后要使用embedding加上标记,也就是索引,来表示一段一段文本。
比如embedding模型的维度是n,就用n维向量来代表每段分割后的文本
索引向量库:chroma
2)检索
2)检索:用收到的query去库里查到最相关的文档或者上下文
)生成:把以上得到的内容输入给LLM,LLM通过理解和结合,整理回答出问题的答案。

参考 https://mp.weixin.qq.com/s/mn0MilYoyV0Df_7SXnuY2g
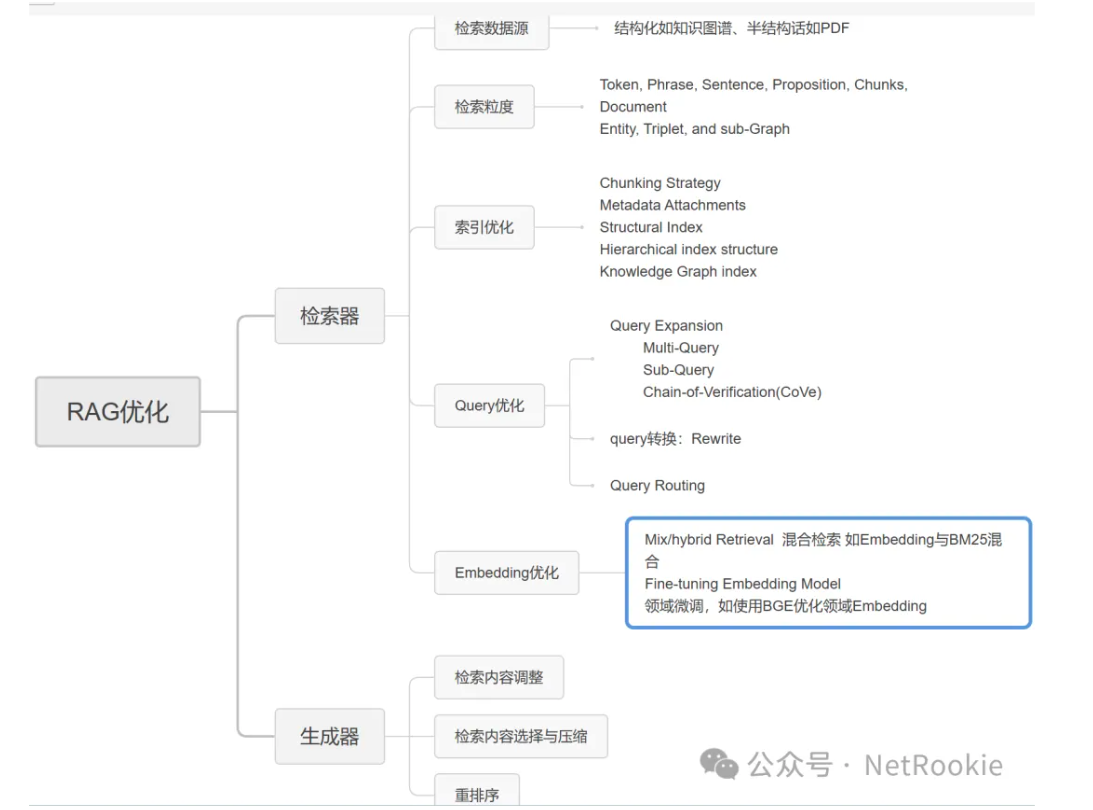
<!> RAG的一些优化方法<一>
RAG性能终极优化指南 https://zhuanlan.zhihu.com/p/687851153
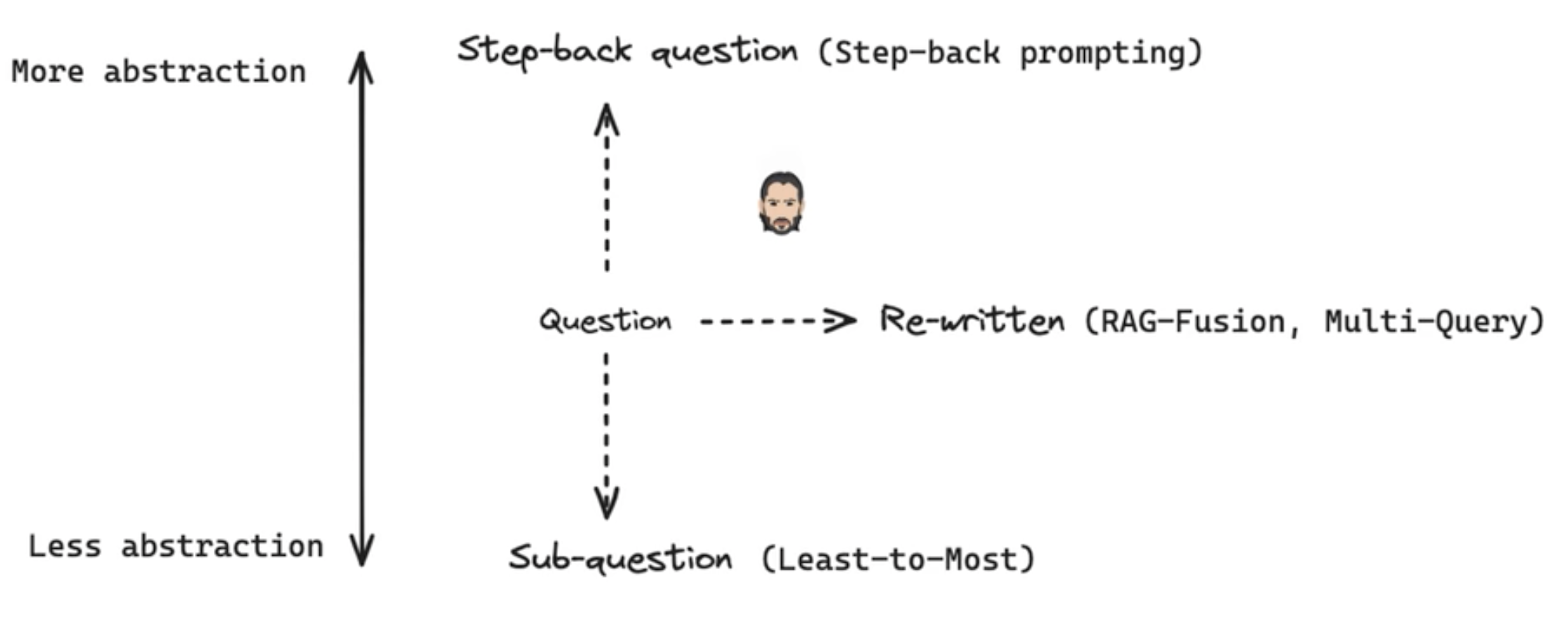
优化思想:横向优化和纵向优化
横向:对query做加工
纵向:进一步分解问题和退一步宏观问题
高级检索增强生成(Advanced RAG):对传统RAG增加复杂的 检索前 和检索后 过程。
手把手做高阶RAG!最牛五大知识检索!RAG性能直线提升! https://zhuanlan.zhihu.com/p/684604832
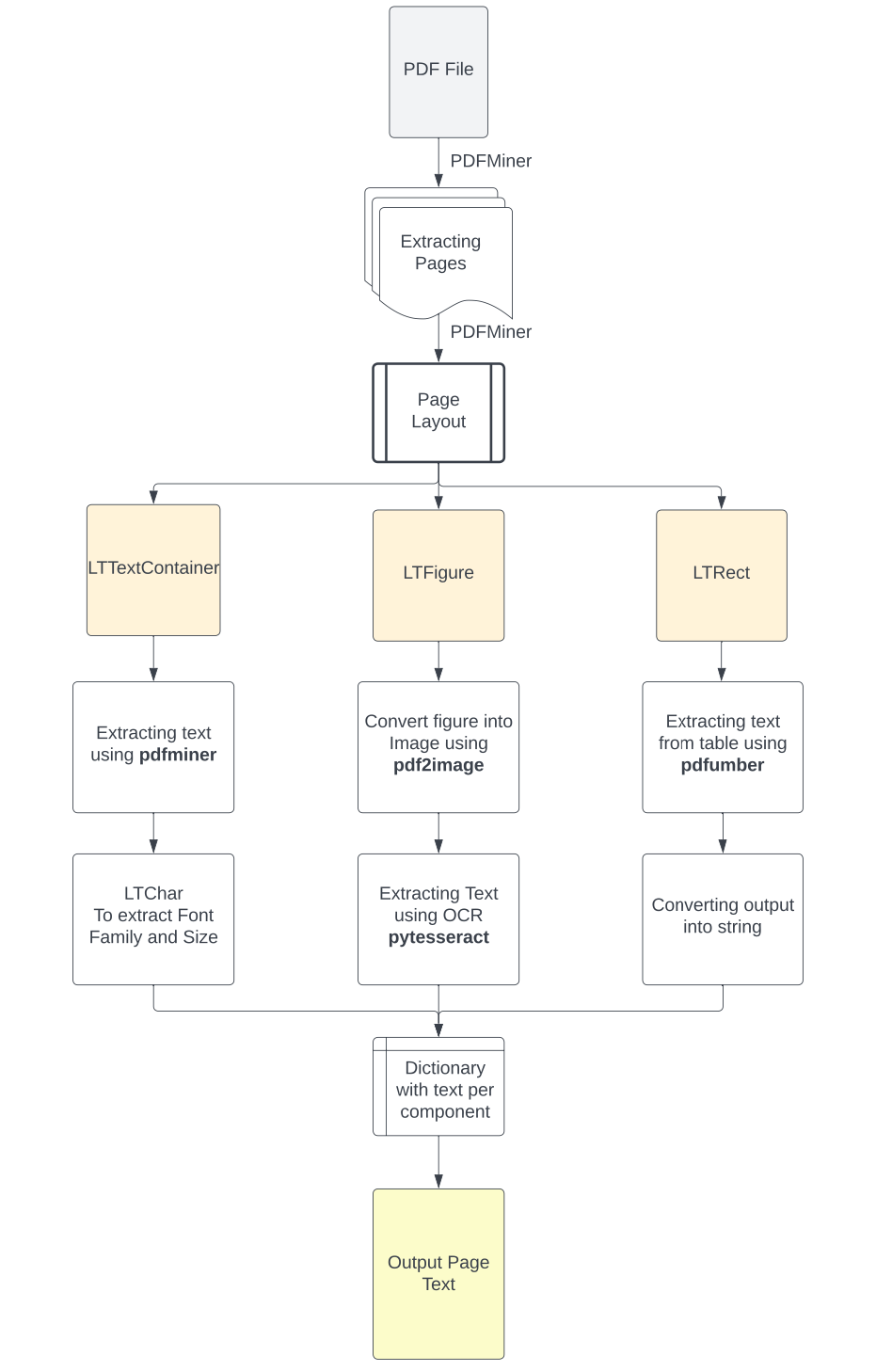
1,提取模块
 ```
```
优化内容的提取包括pdf提取,图片内容(OCR识别),表格内容的提取
全面指南———用python提取PDF中各类文本内容的方法 https://www.luxiangdong.com/2023/10/05/extract/
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)2.切割分片模块
.优化chunking。固定长度切分发,按句子切分,使用spacy分词等
**chunk的相关知识**
参考https://mp.weixin.qq.com/s/mn0MilYoyV0Df_7SXnuY2g
具体参考 :https://www.luxiangdong.com/2023/09/20/chunk/
要点: 分割后的文本块要尽量是语义独立的,没有对上下文很强的依赖。‘
###### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)**分块方式的选择:**
**(1)固定大小的分块方式: CharacterTextSplitter**
设置固定块的大小,并给出一定重叠,是最计算方便的分块方式
from langchain.text_splitter import CharacterTextSplitter
**(2)基于spacy的分块:SpaCyTextSplitter**
它能提供复杂的句子分割功能, 可以将spacy和langchain结合使用
from langchain.text_splitter import SpacyTextSplitter
**(3)递归分割:RecursiveCharacterTextSplitter**
使用分层和迭代的方式分块
**(4)small2big,或者父文档检索方式切块**
在检索过程中,首先获取小块数据,然后查找这些块的父ID,将更大的相关文本块进行处理。
步骤如下:
1.将原始文档分成大块(父文档),每个父文档再细切分为更小块(子文档)
2.为每个子文档创建embedding。这些embeding比整个父块的embedding更丰富更详细。
3.对输入query,查询最相关的子文档的embedding
4.关联找出已检索的最相关的子文档对应的父文档。
5.用父文档给LLM作为上下文,回答问题。
###### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)**分块大小的选择:**
如果块太小,则可能不能完全包含LLM需要回答用户查询的信息;如果块太大,则可能包含太多无关信息,会使LLM混淆,或者可能太大而无法适应上下文大小。
可以比较探索各种块大小的效果,比如较小的块(例如,128或256个tokens)用于捕获更细粒度的语义信息,较大的块(例如,512或1024个tokens)用于保留更多上下文。
**高层次的任务,比如摘要,需要较大的块大小。而低层次的任务,比如编码,需要较小的块。**
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)3.embedding模块
embedding模型的选择。有bge,m3e,还有收费的通义千问的embedding模型
要点:
**embedding对句子做嵌入还是对段落文档做嵌入呢?**
当嵌入一个句子时,生成的向量集中在句子的特定含义上。当与其他句子Embedding进行比较时,自然会在这个层次上进行比较。这也意味着Embedding可能会错过在段落或文档中找到的更广泛的上下文信息。
当嵌入一个完整的段落或文档时,Embedding过程既要考虑整个上下文,也要考虑文本中句子和短语之间的关系。这可以产生更全面的向量表示,从而捕获文本的更广泛的含义和主题。然而,较大的输入文本大小可能会引入噪声或淡化单个句子或短语的重要性,从而在查询索引时更难以找到精确的匹配。
**使用的时候技巧**: 较短的查询,如单个句子或短语,将专注于细节,可能更适合与句子级Embedding进行匹配。较长的查询:跨越多个句子或段落的,更适合段落或文档级别的Embedding,因为它可能会寻找更广泛的上下文或主题。
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)4.向量存储模块
一些prompt的优化,元数据存储等
向量检索服务:阿里向量检索服务DashVector,llama-index,langchain中都有对datavector的集成。
datavector介绍 https://cloud.tencent.com/developer/article/2415209
代码:langchain/libs/community/langchain_community/vectorstores/dashvector.py
#### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)<!>RAG中query改写的一些优化方法
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)1.混合检索
向量检索的优势:
相近语义理解(如谷歌/百度/必应/搜索引擎),
多模态理解(支持文本、图像、音视频等的相似匹配)
容错性(处理拼写错误、模糊的描述)
向量检索的不足:
搜索确定的一个名称,搜索缩写词,搜索ID等,需要精确匹配的场景时候,效果不佳
**将稀疏检索器(如BM25)与密集检索器(如嵌入相似度)结合起来,实现优势互补**。
**稀疏检索器擅长根据关键词找到相关文档,而密集检索器擅长基于语义相似性找到相关文档。**

步骤1:BM25快速获取带有搜索关键词的文档。
步骤2:VectorDB更深入地寻找与上下文有关的文档。
步骤3:合并两种检索结果,并重新排序结果
代码如下
from langchain.retrievers import BM25Retriever, EnsembleRetriever
initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever],
weights=[0.5, 0.5])
docs = ensemble_retriever.get_relevant_documents(“A green fruit”)
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)2.查询扩展
在原始查询的基础上增加同义词或者相关词的扩充来优化搜索结果。

将原始查询传递给LM的同时,原查询扩展出来的语句也走一遍检索,查询到相关的内容,作为上下文一起交给LM,让LM在这些背景资料下,对原始查询的问题给出更完整的答案。
实现:
langchain中自带函数 MultiQueryRetriever
其核心机制是配备一个基础检索器,能够自动产生最多三个定制化的查询。这一过程中,检索操作的安全性和封装性得到了保障。
from langchain.retrievers.multi_query import MultiQueryRetriever
。。。。
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectordb.as_retriever(),llm=llm)
unique_docs = retriever_from_llm.get_relevant_documents(question=“What does the course say about regression?”)
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)3.两种序列分解思想multi-query
**使用场景:用户想问问题,但是不知道该怎么表达,给出的问题比较模糊。这种情况下怎么办?**
**思路:对于复杂问题,可以把复杂问题分解为多个简单问题,一步步求解的方式最终给出问题。**
**步骤:将用户的问题,进行扩展,展开之后,抓去更多的文档,再整合这些文档,一起交给大模型,得到更准确的答案。**
https://zhuanlan.zhihu.com/p/685746861
**两个方案:**
(1)序列求解,将上一个子问题的答案与当前问题一并扔给LLM生成答案,再把当前生成答案与下一个子问题一起给LLM生成答案,直到最后一个子问题生成最终答案;
例子:介绍一下马斯克
分解后问题:1.马斯克出生于哪里 2.马斯克的公司是什么 3.马斯克有什么成就
再一步一步获得问题的答案后,把上一步的问题和答案+本轮问题扔进去,获得答案
详细解释参考: https://www.bilibili.com/video/BV1cH4y1M7Ck/?spm_id_from=333.788&vd_source=c4e1d9d645f9a1554bc220274b5b24a8

(2)并行独立回答问题,然后将多路答案合并为最终答案。合并的过程中,可能会有一些重复召回的片段,使用union的函数,来提取出不重复的独立片段,交给大模型。
详解参考 https://www.bilibili.com/video/BV1Xz421o7NH/?spm_id_from=333.788&vd_source=c4e1d9d645f9a1554bc220274b5b24a8

实现:
在llamaindex中自带一个分解问题为子问题的类
SubQuestionQueryEngine。工作原理是将复杂的原始查询拆分成多个子问题,每个子问题都针对特定的数据源。这些子问题的答案不仅提供了必要的上下文信息,还为构建最终答案做出了贡献。每个子问题专门设计用来从相应的数据源中抽取关键信息。综合这些子问题的答案,可以得到对原始查询的完整回应。实现方法类似上图中的独立求解图
query_engine = SubQuestionQueryEngine.from_defaults(
query_engine_tools=query_engine_tools,
use_async=True,
)
response = query_engine.query(
“How was Paul Grahams life different before, during, and after YC?”
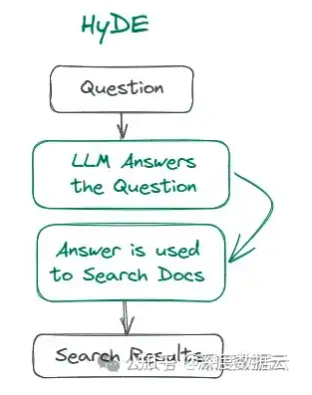
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)4.虚拟文档嵌入HyDE
**适用场景:搜索查询很短,句子模糊,缺乏背景信息的查询**
**思路:用LLM把一个问题扩展成一篇文章。**
**理由:文档和文档中之间检索的准确性可能比句子和文章之间检索的准确性更高。**
b站详解 https://www.bilibili.com/video/BV1Vx421U7a4/?spm_id_from=pageDriver&vd_source=c4e1d9d645f9a1554bc220274b5b24a8
通过LLM根据用户查询生成假设性文档,然后利用该假设性文档的向量表示去寻找知识库中相似度高的N个向量,作为context。其核心理念在于,这种生成的假设文档在嵌入空间中与实际的查询内容相比,具有更接近的关联度。可以直接调用Langchain的HypotheticalDocumentEmbedder\[7\]。
langchain中代码如下:
from langchain.chains.hyde.base import HypotheticalDocumentEmbedder
class HypotheticalDocumentEmbedder(Chain, Embeddings):
“”"Generate hypothetical document for query, and then embed that.
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)5.压缩上下文
**效果:压缩无关上下文,突出关键段落,减少总体上下文长度,提高LLM推理效率。**
通过使用LangChain的**Contextual Compression** \[19\] 去做信息过滤,该上下文压缩检索器是在你检索结果返回后,用LLM专门判断检索结果和问题的相关性,然后将检索结果中真正与问题相关的部分留下来,冗余丢弃
class ContextualCompressionRetriever(BaseRetriever):
“”“Retriever that wraps a base retriever and compresses the results.”“”
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)6.后退一步方法
从提问问题中提出一个后退一步的问题,相当于对所提问题整理出宏观的概念,原则等理论问题。再给出后退一步的答案。再将所有都传入LLM,给出最终答案。

#### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)<!>RAG的重排序是如何做的
**理由:对检索召回的K个文本块,根据与query之间的相关性(根据rerank模型给的相关性分数),重新从高到低排序**
**评估用户问题与每个候选文档之间的关联程度,并基于这种相关性给文档排序,使得与用户问题更为相关的文档排在更前的位置**
**效果:减少召回的冗余,限制传入LLM的文档数,提高检索效率,减⼩LLM推理开销,提高准确度**

##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)**1.重排序应用的地方:**
1.混合排序后,对不同检索结果合并时
2.将检索结果传递给大模型之前,用重排序限制topk传入大模型窗口,减少相关性低的内容引入。
可以研究的代码:
https://github.com/netease-youdao/QAnything/blob/master/README_zh.md Qanything
##### [](https://blog.csdn.net/qq_29837229/article/details/140359990?spm=1001.2014.3001.5501)2.Rerank方法
* 使用重排序模型,比如bge-reranker-large(可本地下载,也可以部署输出api), 或者cohere reranker的对外api服务。
* 对查询和上下文计算得分,代码如下
```
#引入flagEmbeding包
from FlagEmbedding import FlagReranker
#loading reranker模型
reranker = FlagReranker('/data_2/bge-reranker-base', use_fp16=True)
#给出rerank模型对query和每个召回片段的得分,
scores = reranker.compute_score([[query_suite.query, passage] for passage in query_suite.passages])
similarity_dict = {passage: scores[i] for i, passage in enumerate(query_suite.passages)}
#对得分从高到低排序
sorted_similarity_dict = sorted(similarity_dict.items(), key=itemgetter(1), reverse=True)
#排序第一的作为最终答案输出
result[sorted_similarity_dict[j][0]] = sorted_similarity_dict[j][1]
```
# [](https://blog.csdn.net/weixin_49892805/article/details/139955142?spm=1001.2014.3001.5501)零基础如何学习大模型 AI
==领取方式在文末==
## 为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
## 大模型典型应用场景
①**AI+教育**:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②**AI+医疗**:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③**AI+金融**:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④**AI+制造**:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
⑤**AI+零售**:智能推荐系统和库存管理优化了用户体验和运营成本。AI可以分析用户行为,提供个性化商品推荐,同时优化库存,减少浪费。
⑥**AI+交通**:自动驾驶和智能交通管理提升了交通安全和效率。AI技术可以实现车辆自动驾驶,并优化交通信号控制,减少拥堵。
......
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
## 学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,***==无偿分享!!!==***
*==vx扫描下方二维码即可==
==加上后会一个个给大家发==*

## 部分资料展示
### 一、 AI大模型学习路线图
整个学习分为7个阶段

### 二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

### 三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


### 四、LLM面试题

如果二维码失效,可以点击下方链接,一样的哦
[【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!](http://b.mrw.so/2mb0XO)
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









