






TL;DR
DeepSeek-R1-Zero 不需要SFT
DeepSeek-R1 需要SFT
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
发布模型:
-
DeepSeek-R1-Zero:疯狂的CoT推理机器,无SFT纯RL训练,不管输出格式,解答不做summarization,阅读性差无格式
-
DeepSeek-R1:带冷启动(Cold Start) SFT,然后做RL训练,控制输出格式,有summarization,是部署的版本。
-
DeepSeek-R1-Distill:基于Qwen和Llama作为Base从R1数据蒸馏成小模型
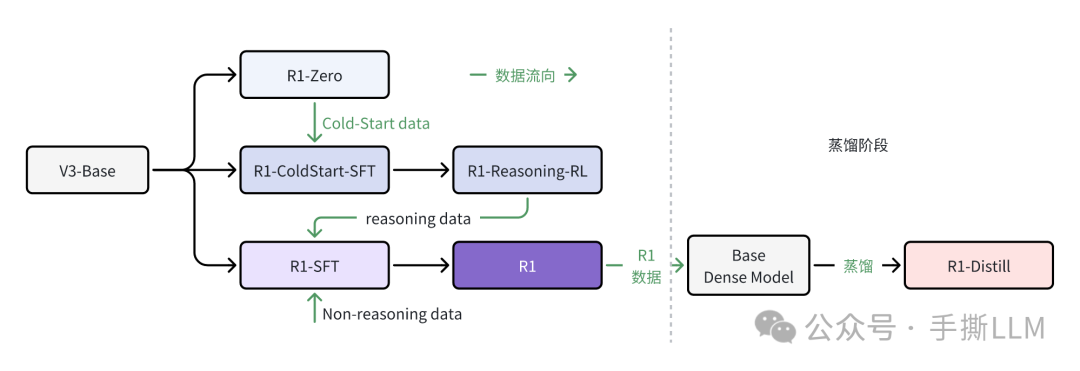
整体流程为
导读问题
-
DeepSeek-R1-Zero里的Zero含义? -
不做SFT和RM训练,纯RL训练的效果?
-
模型的Aha Moment 行为有什么意义
-
DeepSeek-R1-Zero存在什么问题?优劣势? -
DeepSeek-R1训练流程? -
什么是冷启动,R1训练的两个RL区别在哪?
-
蒸馏R1比从零RL训练是否更好?
-
在R1上PRM和MCTS是否有用?
1. DeepSeek-R1-Zero 纯RL训练
1.1 简介
However, these works heavily depended on supervised data, which are time-intensive to gather. In this section, we explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure reinforcement learning process.
Zero来自Alpha Zero,特指无需人类数据,即可从零实现模型自我迭代。
Deepseek-V3-base模型不做SFT就可以RL训练,“问题是RL的数据和reward如何获得?”
1.2 RL算法
(1) GRPO:对于一个prompt在线采样N条回答成组,根据(3)式得到优势,按照下式来优化。不需要value model,按照一组的相对分数作为优势。奖励都是Sentence-level的,但可以以同个advantage赋值到每个token上。
(2) KL散度:采用方差较小无偏的KL变种,KL项是Token-Level的
(3) 对于有多个奖励,做归一化,体现相对性。
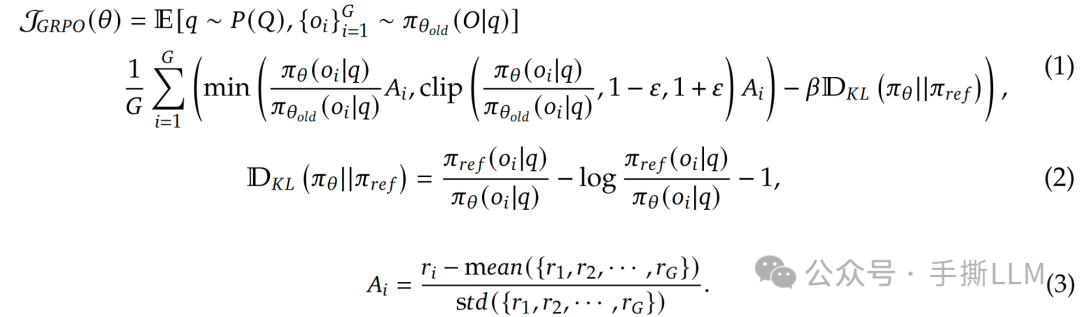
好处:1.不需要Value Model,2. 优势估计是无偏的
1.3 数据
以下为提示词模版,可以见到有特定的标签如<think> 和<answer>

在RL训练时,可以仅收集数学题和正确答案(作为Label),不需要解答(RL训练过程可以在线采样)
存在问题:base模型如何在RL初始阶段就能采样符合指令的推理CoT?论文并没有提及,这里会造成前期的训练稳定性差,毕竟没有提前做一次SFT。
1.4 奖励
对于数学题这种有确定答案的场景,那么通过匹配答案正确性就可以得到奖励,比如
question: find the minimal value of x^2 - 4x + 1 = 0
…
Answer: (
$\boxed{-3})
ground truth: , 那么可以通过规则匹配上就可以得到奖励1,匹配不上为奖励-1, 特别的要处理 和 这种同值不同形式的匹配
不需要训练奖励模型,因为容易reward hacking
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process
另外:要求模型在线采样的数据必须有<think> 和</think>标签, 也作为格式奖励。
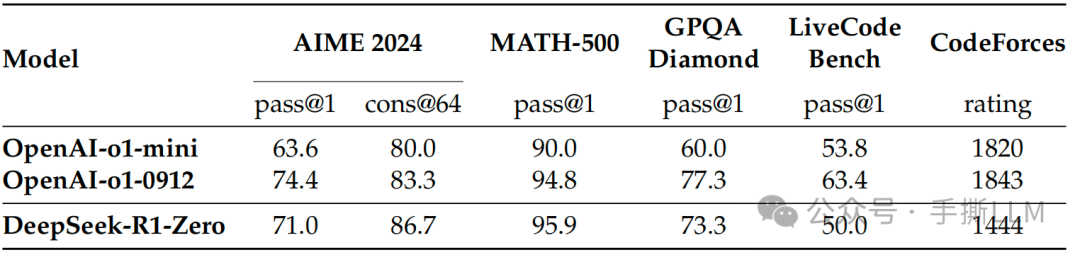
1.5 R1 效果分析
性能比肩DeepSeek-R1-Zero
在RL训练过程的在线采样中,可见输出长度逐渐增加,越来越多的CoT解答,另外自发的产生自省、revisits和revaluate行为
Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously
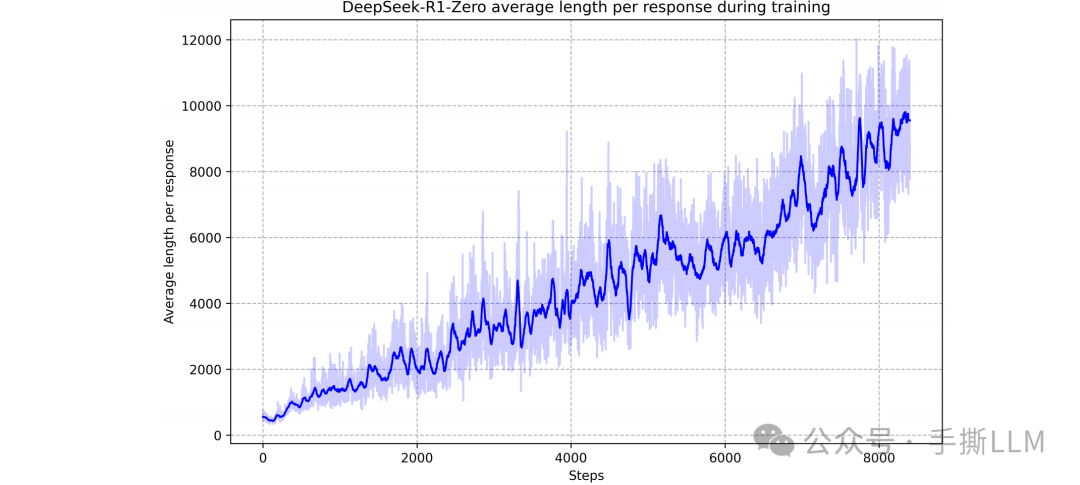
意味着不需要人为的数据教授模型CoT ,模型通过规则奖励和人工数据,就能产生思维类风格的输出。
1.6 Aha Moment
将RL过程中的Checkpoint 进行采样生成,发现一些有趣的“自言自语”式的文本,而这些思考的文本,是模型自己的采样输出。
It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies

1.7 DeepSeek-R1-Zero弊端
由于没有人工的指令微调,模型的输出并不会遵循输出格式, 另外复杂的CoT过程,实际上存在“语种混乱“和”可读性差“
For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing
在实际产品应用部署中并不合适用R1-Zero
那么为什么会出现CoT语种混乱?由于V3和R1预训练数据源主要是中英,有概率生成到其他语种。
2. DeepSeek-R1 训练
DeepSeek-R1-Zero在早期从Base训练存在不稳定问题,那么仍然需要冷启动做SFT,那么问题在于
Can reasoning performance be further improved or convergence accelerated by incorporating a small amount of high-quality data as a cold start?
How can we train a user-friendly model that not only produces clear and coherent Chains of Thought (CoT) but also demonstrates strong general capabilities?
-
并入少量的人工SFT数据是否会加速推理性能的收敛?
-
如何能够产生简洁的CoT和保持通用能力?
我们根据原文实现重绘流程图帮助理解
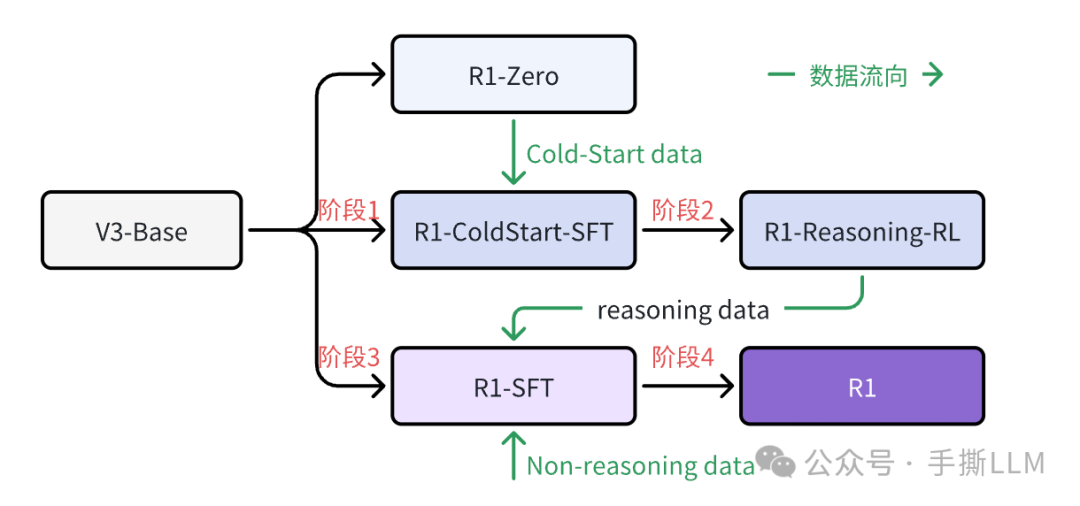
2.1 Cold Start
什么是冷启动?为什么要冷启动?
-
指的是RL前先对模型进行有监督对齐
-
冷启动数据有人类先验,但是原文解释比较直觉
By carefully designing the pattern for cold-start data with human priors, we observe better performance against DeepSeek-R1-Zero. We believe the iterative training is a better way for reasoning models.
冷启动数据收集, 从DeepSeek-R1-Zero few-shot prompt 采样再人工后处理修改千条数据。
few-shot prompting with a long CoT as an example, directly prompting models to generate detailed answers with reflection and verification, gathering DeepSeek-R1-Zero outputs in a readable format, and refining the results through post-processing by human annotators.
为了解决Deepseek-R1-Zero问题,那么收集cold-start保证回答模式“可阅读性”和“总结”性非常有必要
-
增加
<reasoning_process>特殊token -
增加
<summary>提高阅读性,所以R1并不需要额外的摘要模型
we design a readable pattern that includes a summary at the end of each response and filters out responses that are not reader-friendly. Here, we define the output format as |special_token|<reasoning_process>|special_token|
<summary>, 增加摘要提升可读性
2.2 Reasoning-oriented Reinforcement Learning
在Cold-start SFT后,进入到类似Deepseek-R1-Zero 类的RL训练,不同的是增加“语言一致性奖励”, 减轻输出混合。
To mitigate the issue of language mixing, we introduce a language consistency reward during RL training, which is calculated as the proportion of target language words in the CoT
2.3 Rejection Sampling and Supervised Fine-Tuning
是否仍需要CoT, 为了提高通用能力,仍需要收集数据做SFT
which primarily focuses on reasoning, this stage incorporates data from other domains to enhance the model’s capabilities in writing, role-playing, and other general-purpose tasks.
重点在于数据收集
Reasoning Data:
-
可以根据rule-based来采集数据
-
增加额外的数据
-
过滤long-cot里的混合语种、难于阅读和代码块的数据
总共收集200K
Non-Reasoning data
收集常规的指令数据600K,另外由于存在回答模式切换场景,可以用提示词工程来判别是否进入到reasoning模式:
we call DeepSeek-V3 to generate a potential chain-of-thought before answering the question by prompting. However, for simpler queries, such as “hello” we do not provide a CoT in response.
混合数据有800K对Base 模型做SFT, 注意,阶段1和2的训练过程,只是为了给真正的R1模型训练收集数据,真正微调的仍是DeepSeek-V3-Base,而非训练阶段1和2的中间模型
We fine-tune DeepSeek-V3-Base for two epochs using the above curated dataset of about 800k samples.
2.4. Reinforcement Learning for all Scenarios
最后真正的通用RL训练, 混合了rule-based reward和preference reward。在GRPO算法里可以采样group回复
但是没有透露这两种reward如何混合?
For reasoning data, we adhere to the methodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in math, code, and logical reasoning domains. For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios.
所以Preference Leanring 仍是需要的。
3. 蒸馏
先说方法,基于dense模型从R1蒸馏,8B左右效果就已经很好,纯sft蒸馏。
For distilled models, we apply only SFT and do not include an RL stage, even though incorporating RL could substantially boost model performance.
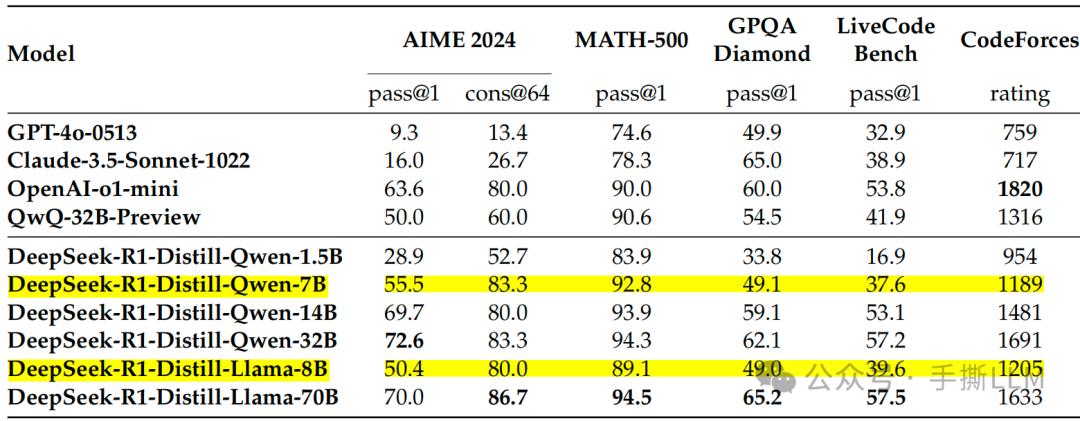
问题:从零R1训练小模型 VS 蒸馏R1到小模型,哪个推理能力更强

结论:
-
使用R1蒸馏比纯RL效果好
-
蒸馏虽好可不要贪杯,base模型要求仍要好(看1.5B和7B的对比)
4. 不成功的尝试
结论:PRM和MCTS都没达到预期效果
4.1 PRM
-
在reasoning任务中如何显式定义step,比如以
\n还是以推理逻辑来划分step -
如何定义step正确性,将影响step labeler来高效标注
-
PRM容易reward hacking
另外PRM在搜索作用怎么样?
In conclusion, while PRM demonstrates a good ability to rerank the top-N responses generated by the model or assist in guided search, its advantages are limited compared to the additional computational overhead it introduces during large-scale reinforcement learning process in our experiments
4.2 MCTS
-
LLM比象棋搜索空间大太多
-
MCTS价值影响模型生成质量(不如纯CoT采样)
First,unlike chess, where the search space is relatively well-defined, token generation presents an exponentially larger search space.
Second, the value model directly influences the quality of generation since it guides each step of the search process.
MCTS仍有非常大的挑战,并不能否定这一条路
In conclusion, while MCTS can improve performance during inference when paired with a pre-trained value model, iteratively boosting model performance through self-search remains a significant challenge.
总结
-
DeepSeek-R1-Zero是纯RL训练,不需要SFT,不需要reward model和value model,RL硬训,缺点在于生成数据可读性差。
-
DeepSeek-R1主要分为4个阶段,前两个阶段cold start和reasoning-oriented RL训练是为了给第3阶段产生SFT数据,在第四阶段混合rule-reward和peference reward做RL训练,解决R1-Zero问题,具有格式化、语言统一、推理模式判别、cot摘要功能。相较R1-Zero最大的特点是R1增加了对齐
-
R1方案里没有step、prm、MCTS、树推理,一路做SFT和RL训练就够了;并不用精心设计提示词来加入推理技巧如:self-reflection、revisit和self-evaluate等,模型CoT能探索到"Aha-moment"
-
另外R1缺少大量合成数据细节,将会增加复现难度;总的来说,越简单的处理流程越能scaling;
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 2556
2556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









