






爱丁堡大学的研究人员开发了一个并发编程框架,用于定量分析在有限的 GPU 高带宽内存 (HBM) 条件下服务多个长上下文请求时的效率问题,旨在通过压缩 KV 缓存、优化预填充和解码过程等手段,最终使处理百万级词元长度的模型与处理四千词元模型一样高效。
论文介绍
大型语言模型 (LLMs) 已经获得了显著的能力,达到了 GPT-4 级别的性能。然而,将这些模型部署到需要广泛上下文(例如代码库级编码和长达一小时的视频理解)的应用中,带来了巨大的挑战。这些任务需要 100K 到 10M 个词元范围的输入上下文,这与标准的 4K 词元限制相比是一个巨大的飞跃。研究人员正在努力实现一个雄心勃勃的目标:如何使 1M 上下文生产级 transformers 的部署与 4K transformers 一样具有成本效益?服务长上下文 transformers 的主要障碍是 KV 缓存的大小。例如,一个具有 100K 上下文的 30+B 参数模型需要惊人的 22.8GB 的 KV 缓存,而 4K 上下文仅需要 0.91GB,这突显了随着上下文长度的增长,内存需求呈指数级增长。
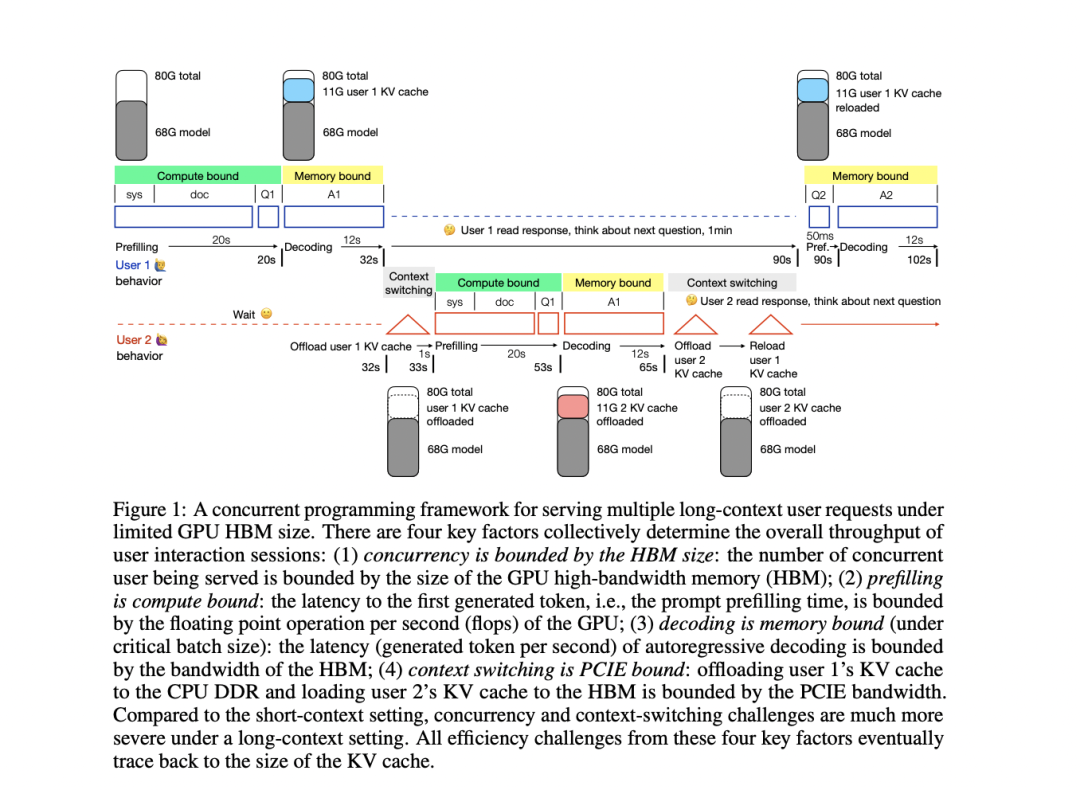
为了克服部署长上下文 transformers 的挑战,爱丁堡大学的研究人员开发了一个并发编程框架,用于在有限的 GPU 高带宽内存 (HBM) 下,对服务多个长上下文请求时的效率问题进行定量分析。该框架以 A100 NVLink GPU 上具有 50K 上下文的 34B GPT-3.5 级模型为代表性示例。分析揭示了大型 KV 缓存带来的四个关键部署挑战:长输入的预填充时间和内存使用量增加、HBM 占用导致并发用户容量受限、频繁的 KV 缓存访问导致解码延迟增加,以及在 HBM 和 DDR 内存之间交换 KV 缓存时上下文切换延迟显著。这个全面的框架使研究人员能够评估现有解决方案,并探索开发能够有效处理长上下文语言模型的端到端系统的潜在组合。
该研究的重点是在层、头、词元和隐藏四个维度上压缩 KV 缓存。研究人员假设,某些任务可能不需要层维度的全深度计算,从而允许在预填充期间跳过层。这种方法有可能将 KV 缓存减少到只有一层,实现 1/60 的压缩率。在头维度上,研究表明某些头专门用于检索和长上下文能力。通过只保留这些关键的头并修剪其他头,可以实现显著的压缩。例如,一些研究表明,对于检索任务,1024 个头中可能只需要 20 个就足够了。
词元维度压缩基于以下假设:如果一个词元的信息可以从其上下文中推断出来,则可以通过删除该词元或将其与相邻词元合并来对其进行压缩。然而,这个维度似乎不如层或头更容易压缩,大多数工作表明压缩率低于 50%。隐藏维度已经很小,只有 128,除了量化技术之外,对其探索有限。研究人员建议,将 LoRA 等降维技术应用于 KV 缓存可能会带来进一步的改进。该框架还考虑了预填充和解码之间的相对成本,指出随着模型规模的增大和上下文长度的增加,成本从解码转移到预填充,强调了为了高效部署长上下文,需要对这两个方面进行优化。
该研究全面分析了部署长上下文 transformers 面临的挑战,旨在使 1M 上下文服务的成本效益与 4K 相当。这一目标将使视频理解和生成式代理等先进的 AI 应用民主化。该研究引入了一个并发编程框架,将用户交互吞吐量分解为四个关键指标:并发性、预填充、解码和上下文切换。通过研究各种因素如何影响这些指标,并回顾现有的优化工作,该研究强调了整合当前方法以开发强大的端到端长上下文服务系统的重大机遇。这项工作为长上下文推理的全栈优化奠定了基础。
论文下载
- 论文地址:https://arxiv.org/abs/2405.08944
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









