






选择恰当的GPU卡来部署大语言模型至关重要。它不仅可以确保用户通过更快的生成速度获得最佳体验,还可以通过更高的 Token 生成率和资源利用率来降本增效。本文将讲述如何评估LLM的推理性能以及vLLM框架在不同主流GPU卡(4090/A800/H800/H20等)上进行推理性能测评。
目录
-
LLM推理过程
-
LLM推理服务的目标
-
常见LLM推理服务性能评估指标
-
LLM推理优化技术
-
LLM基准测试说明
-
LLM基准测试输入的选择
-
LLM基准测试并发请求的选择
-
LLM张量并行的选择
-
基于丹摩智算云进行推理环境构建
-
实例创建
-
环境搭建
-
LLM推理基准测试
-
LLM延迟基准测试
-
LLM吞吐量测试报表
-
结语
LLM推理过程
首先,我们来了解一下LLM的推理过程。对于目前 Decoder-only Transformer 架构的文本生成大模型而言,其推理过程分为两个阶段:
-
预填充阶段,这一阶段会以并行方式处理输入提示中的Token(词元);
-
解码阶段,这一阶段文本会以自回归的方式逐个生成词元。每个生成的词元都会被添加到输入中,并被重新喂入模型,以生成下一个词元。当LLM输出了特殊的停止词元或满足用户定义的条件(例如:生成了最大数量的词元)时,生成过程就会停止。
词元可以是单词或子词,将文本拆分为词元的确切规则因模型而异。例如,我们可以对比LLaMA模型和OpenAI模型对文本进行分词处理的方式。尽管LLM推理服务供应商经常以基于词元的指标(例如:每秒处理的词元数)来谈论性能,但由于模型分词规则的差异,这些数字在不同模型类型之间并不总是可比较的。例如,Anyscale 团队发现,与 ChatGPT 的分词长度相比,LLaMA 2的分词长度增加了19%(但整体成本要低得多)。HuggingFace 的研究人员也发现,与 GPT-4 相比,对于相同长度的文本,LLaMA 2训练所需的词元要多20%左右。
LLM推理服务的目标
通常情况下,LLM推理服务目标是首Token输出尽可能快、吞吐量尽可能高以及每个输出Token的时间尽可能短。换句话说,我们希望我们的模型服务能够尽可能快地支持我们尽可能多地为用户生成文本。
常见LLM推理服务性能评估指标
针对LLM推理服务的目标以及LLM推理的特点,对于大模型推理服务而言,应该如何准确衡量模型的推理速度呢?下面是一些常见的评估指标:
-
首Token生成时间(Time To First Token,简称TTFT):即用户输入提示后,模型生成第一个输出词元所需的时间。在实时交互中,低时延获取响应非常重要,但在离线工作任务中则不太重要。此指标受处理Prompt并生成首个输出词元所需的时间所驱动。通常,我们不仅对平均TTFT感兴趣,还包括其分布,如P50、P90、P95和P99等。
-
单个输出Token的生成时间(Time Per Output Token,简称TPOT):即为每个用户的查询生成一个输出词元所需的时间。例如,TPOT为100毫秒/词元表示每个用户每秒可处理10个词元,或者每分钟处理约450个词元,那么这一速度远超普通人的阅读速度。
-
端到端时延:模型为用户生成完整回答所需的总时间。整体响应时延可使用前两个指标计算得出:时延 = (TTFT)+ (TPOT)*(待生成的词元数)。
-
每分钟完成的请求数:通常情况下,我们都希望系统能够处理并发请求。可能是因为你正在处理来自多个用户的输入或者可能有一个批量推理任务。
-
生成Token吞吐量:推理服务在所有用户请求中每秒可生成的输出词元(Token)数。考虑到无法测量预加载时间,并且总推理时延所花时间更多地取决于生成的Token数量,而不是输入的Token数量,因此,将注意力集中在输出Token上通常是正确的抉择。
-
总吞吐量:包括输入的Token和生成的Token。
-
…
LLM推理优化技术
通常情况下,在上线到生产环境前,需要进行 LLM 推理优化。
在主流的大模型推理框架中,常见的 LLM 推理优化技术如下:
-
算子融合:将不同的相邻算子组合在一起通常会带来更低的延迟。
-
模型量化:将激活和权重进行压缩以使用更少的比特数,减少显存空间和提升推理速度。
-
模型并行化:跨多个设备进行张量并行或对于较大的模型进行流水线并行。
-
KV 缓存,即保存注意力层的中间key、value值,以供以后重用,避免重复计算。
-
KV 缓存量化,即减少 KV 缓存的内存空间。
-
Continuous batching: 通过服务调度优化提高总吞吐量。
-
PagedAttention:借助内存分页的概念,对Attention的key、value进行高效的内存管理,提高GPU显存利用率。
-
FlashAttention:对Attention计算的访存进行优化。
-
自动前缀缓存:通过缓存不同推理请求之间的重复计算来提高效率,这在具有重复提示的场景(包括多轮对话、长文档查询)中特别有用。
-
Chunked prefill:将预填充大块分成更小的块,并将它们与解码请求一起批处理。改进了token间生成延迟。同时,通过将计算受限(预填充)和内存受限(解码)请求放到同一批次来实现更好的 GPU 利用率。
-
Speculative decoding(推测解码/投机采样):它通过采用较小的语言模型(草稿模型)来生成候选文本样本来加速该过程。这些候选者通过更大的模型(目标模型)进行评估,并且仅采用核准的文本。它是一种加速文本生成的采样方法,可以改善内存密集型LLM推理中Token间延迟。
本文的性能测试应用到了模型并行推理、KV 缓存、Continuous Batching、PagedAttention、FlashAttention、算子融合等技术。
LLM基准测试说明
在进行LLM基准测试之前,需要根据测试的目标,选择合适输入提示、并发请求、模型并行策略等。
LLM基准测试输入的选择
有的人喜欢使用随机Token来生成固定大小的输入,然后在最大生成Token上使用强 制停止来控制输出Token大小。但这一做法不够理想,原因有以下两点:
-
随机Token并不代表真实数据。因此,某些依赖于真实数据分布的性能优化算法(如:投机采样)在随机数据上的表现可能不如真实数据。
-
固定大小并不代表真实数据。这意味着某些算法的优势无法得到体现,比如:PagedAttention和Continuous Batching等,因为它们很大一部分的创新点在于处理输入和输出的大小变化。
因此,最好使用“真实”数据。但“真实”的定义因具体应用而异,本文使用羊驼中文数据集进行基准测试。
LLM基准测试并发请求的选择
对于一个典型的LLM推理服务,通常需要接收多个用户的请求。但更多的并发请求会使固定资源集的输出速度变慢。在本文的测试中,测量延迟时,只使用一个用户,保证最佳的推理时延。而测试吞吐量时,由于希望测试一个LLM服务能够处理最大的Token,我们将设置不同大小的峰值用户。
LLM张量并行的选择
随着输入提示变长,生成第一个token的时间占用总延迟的的比例开始变大。跨多个 GPU 的张量并行有助于减少这种延迟。与模型训练不同,将模型推理扩展到更多的 GPU 会显著降低推理延迟的回报。例如,对于 Llama2-70B,在批量大小较小的情况下,从 4x GPU 增加到 8x GPU 仅将延迟降低了 0.7 倍。一个原因是模型并行度越高,模型带宽利用率(MBU,系统实际内存带宽与峰值内存带宽的比例) 越低。另一个原因是张量并行引入了跨 GPU 节点的通信开销。
而在批量大小较大的情况下,较高的张量并行度会将token延迟相对显著地减少。之前有关于 MPT-7B 每个输出token的时间变化情况的研究。在批量大小为 1 时,从 2x GPU到 4x GPU 仅将token延迟减少约 12%。在批量大小为 16 时,4x 的延迟比 2x 的延迟低 33%。
本文针对不同模型参数规格,选择了不同的模型并行度进行测试。
基于丹摩智算云进行推理环境构建
DAMODEL(丹摩智算)是专为AI打造的智算云,致力于提供丰富的算力资源与基础设施助力AI应用的开发、训练、部署,并且平台为AI训练/推理、高性能计算(HPC)和图像/视频渲染等3大高算力应用场景均提供了最佳的解决方案。基于多年的研发及运营经验,平台在硬件适配、软件配置和资源调度方面都进行了不断的迭代和优化,既可满足用户高效/高性能的需求,也为用户尽可能地优化使用成本。本次推理性能测试将在丹摩智算云上面进行。
平台地址:https://damodel.com/register?source=80D8B310
实例创建
注册账号之后,进入DAMODEL控制台,点击资源-GPU云实例,点击创建实例。
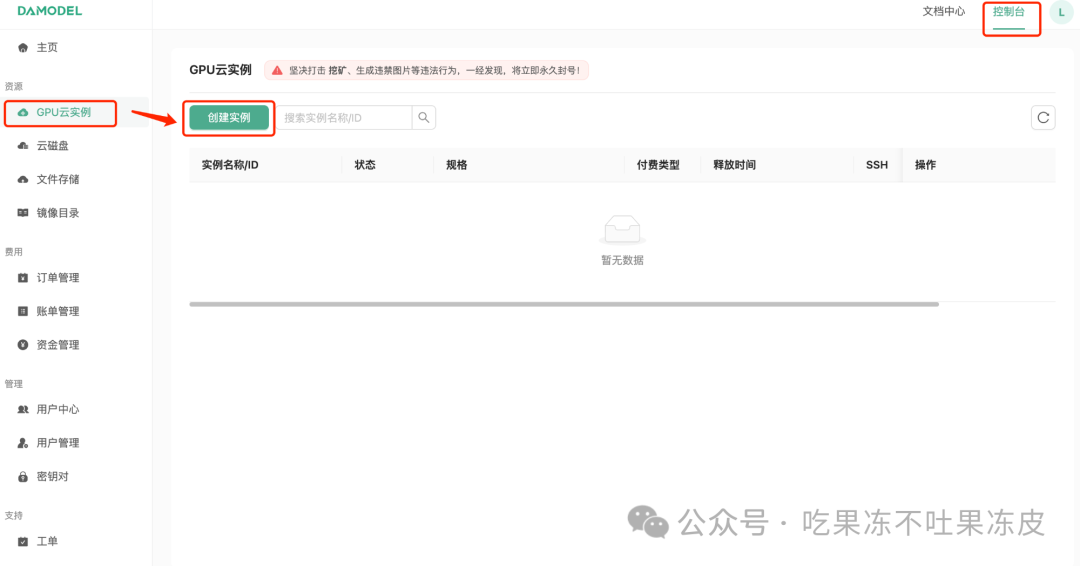
进入创建页面后,在实例配置中选择付费类型为按量付费,其次选择单卡启动,然后选择需要的GPU型号。本次演示选择选择:按量付费–GPU数量1–NVIDIA-GeForc-RTX-4090,该配置为60GB内存,24GB的显存。
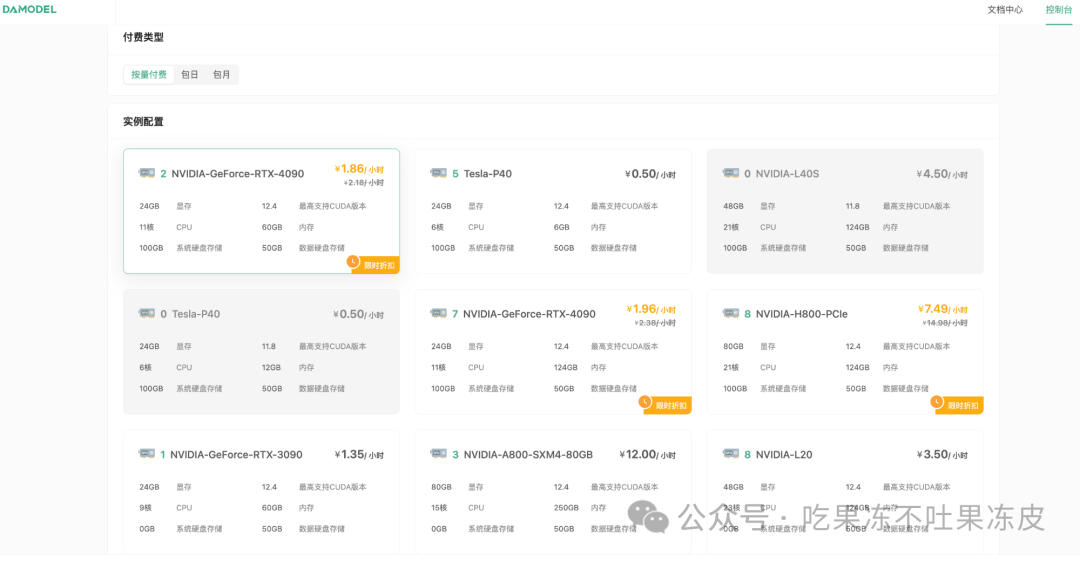
继续往下翻,配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,本次创建可以就选择默认大小50GB,可以看到,平台提供了一些基础镜像供快速启动,镜像中安装了对应的基础环境和框架,这里选择PyTorch2.3.0的框架启动。
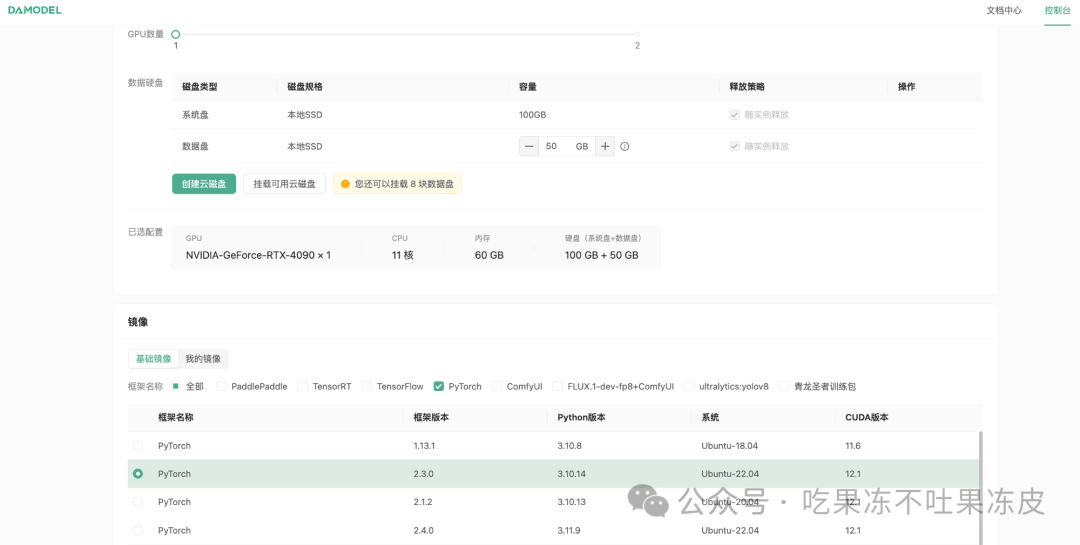
接着创建秘钥对,输入秘钥对名称,选择自动创建,点击“确认”即可。
创建成功之后,然后选择秘钥对,点击“立即创建”即可。
创建之后即可看到具体实例。现在可以通过两种方式使用实例。
方式1:通过jupyterlab方式直接使用。
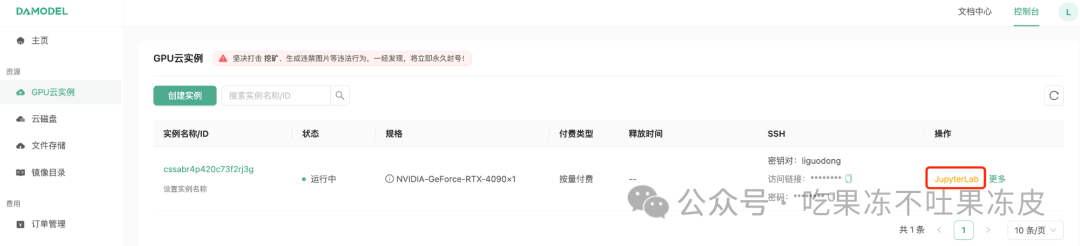

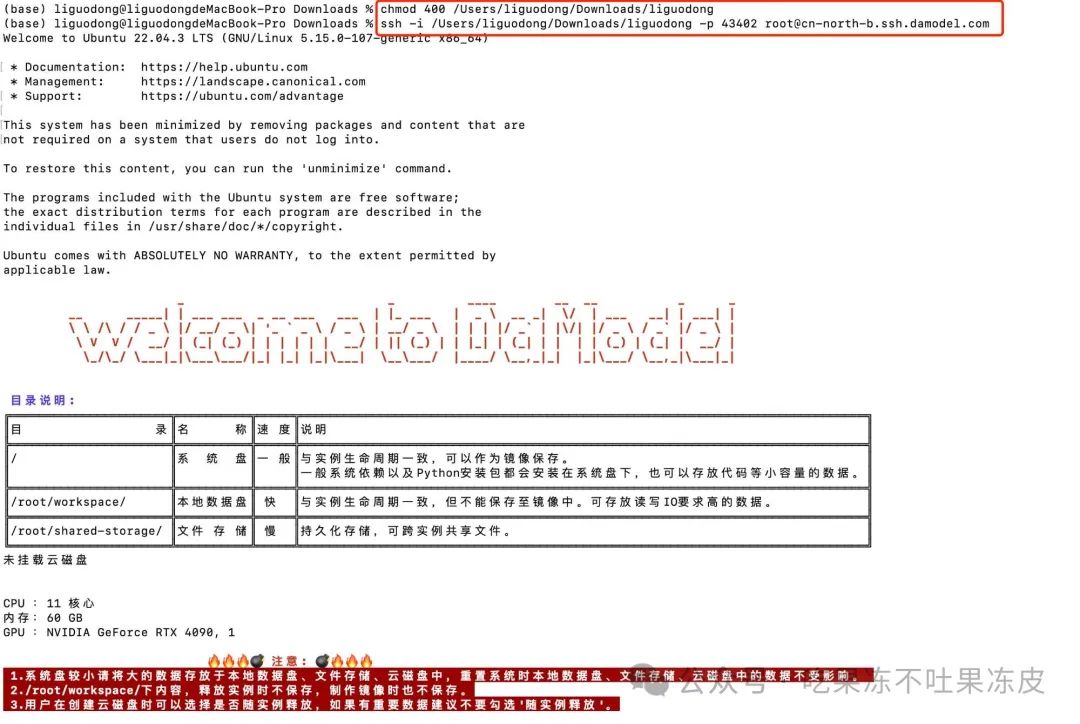
方式2:通过ssh远程连接使用。首先找到刚刚创建的秘钥对并下载的公钥,然后复制访问链接,参考如下方式链接即可。

chmod 400 /Users/liguodong/Downloads/liguodong ssh -i /Users/liguodong/Downloads/liguodong -p 43402 root@cn-north-b.ssh.damodel.com
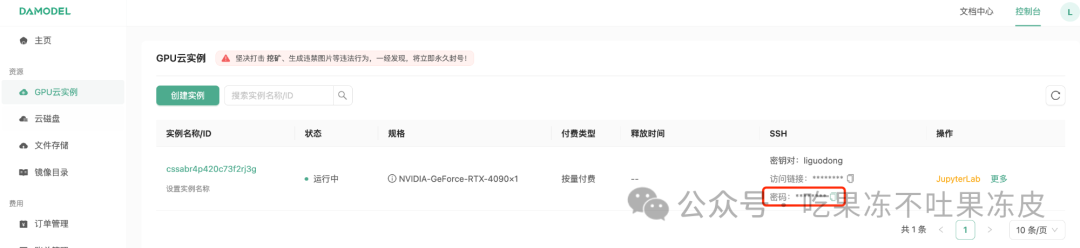
或者ssh远程连接时,通过密码登录。

环境搭建
然后就是准备推理环境,安装vllm。
pip install vllm==0.5.5
然后,根据需要自行下载需要测试的模型。
apt update && apt install git-lfs # git lfs clone https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
之后,启动vllm,这里根据场景需要自行根据启动参数配置。
python -m vllm.entrypoints.openai.api_server \ --port 9009 \ --disable-custom-all-reduce \ --gpu-memory-utilization 0.9 \ --dtype auto \ --model /root/workspace/Qwen2.5-0.5B-Instruct \ --tensor-parallel-size 1 \ --max-model-len 10000 \ --served-model-name qwen1.5 \ --max-num-seqs 256 \ --max-num-batched-tokens 10000
启动成功之后,使用兼容OpenAI接口访问即可。
curl "http://127.0.0.1:9009/v1/chat/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "qwen1.5", "messages": [ { "role": "user", "content": "你好,我叫李聪明。请问你是谁?" } ], "max_tokens":256, "top_p": 0.85, "logprobs": false }'
请求成功之后,整个环境就准备完成,接下来就可以进行LLM推理基准测试了。
LLM推理基准测试
本文主要测试LLM延迟和吞吐量相关指标。由于使用应用时,根据推理场景的不同,采用的各种推理优化参数各不相同,对性能差异的影响还是挺大的。本文LLM推理性能测试数据仅供参考,具体性能实测为准。
LLM延迟基准测试
下面使用vLLM框架对不同模型的推理时延进行测试。
-
数据集:羊驼中文数据集 1k
-
服务器配置:RTX 4090、A800、H800、H20
-
框架:vLLM
-
指标:端到端时延、首Token时延、Token间时延
下图为在vLLM推理框架下在不同GPU卡在QWen模型上推理时延汇总:
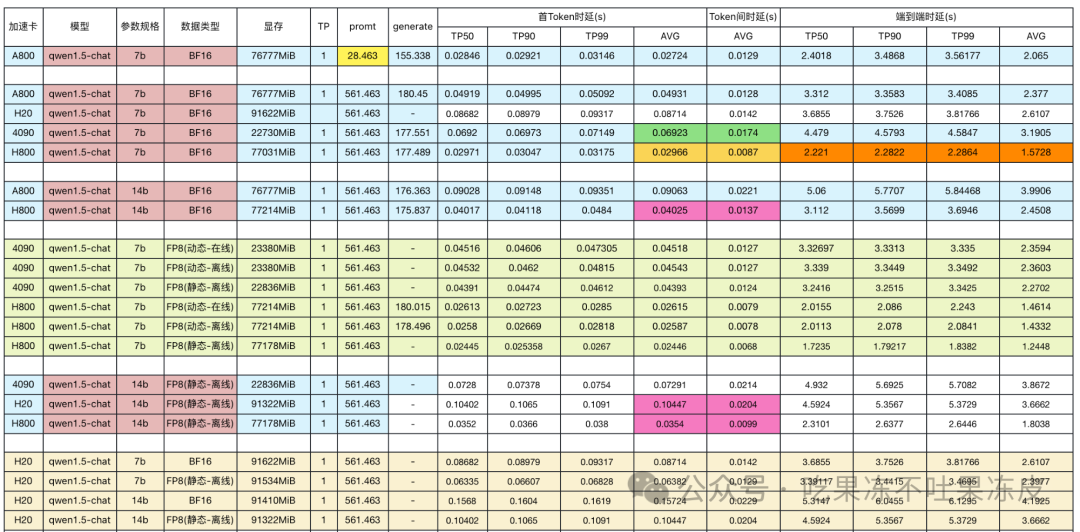
首Token时延(TTFT):H800 > A800 > 4090 > H20 (compute bound)
每Token生成时延(TPOT):H800 > A800 > H20 > 4090 (memory bound)
LLM吞吐量测试报表
下面使用vLLM框架对不同模型的推理吞吐量和端到端时延进行测试。
-
压测工具:Locust
-
数据集:羊驼中文数据集 0.5k(随机抽取)
-
服务器配置:RTX 4090、A800、H800、H20
-
框架:vLLM
-
指标:吞吐量(每秒处理的Token数)、端到端时延
-
压测时长:10m
下图为在vLLM推理框架下,针对不同GPU卡,在Qwen模型上,不同峰值用户下,推理吞吐量和端到端时延汇总:
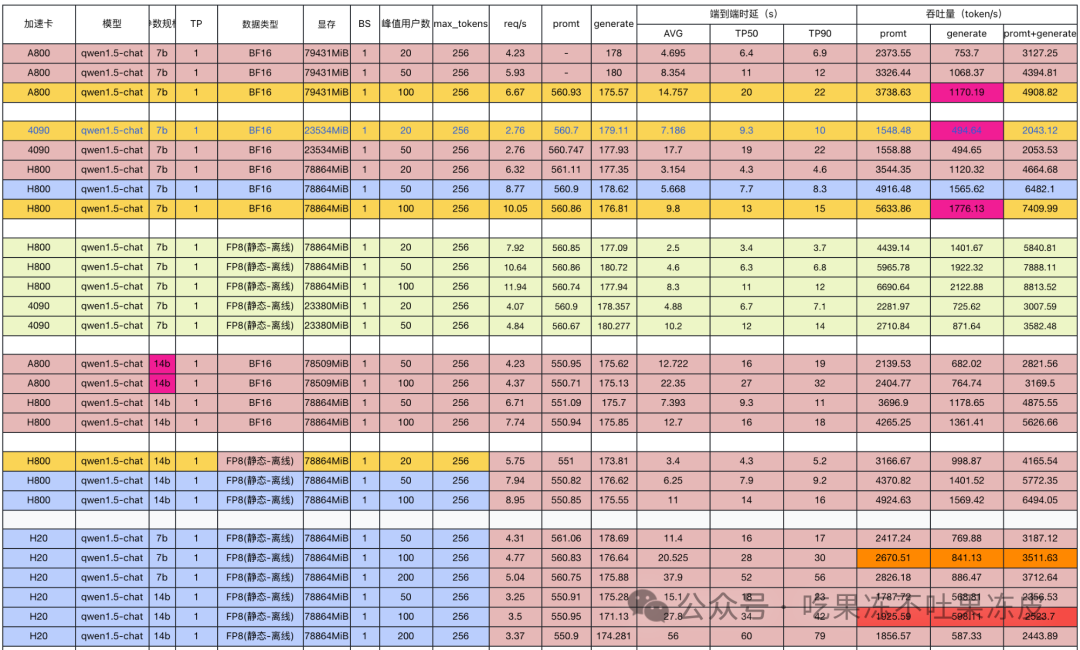
吞吐量和每个输出Token时延之间存在权衡,在某些应用中,如聊天机器人,低延迟地响应用户是最优先的。在其他应用中,如批量处理非结构化PDF文件,我们可能愿意牺牲处理单个文档的延迟,以便并行快速处理所有文档。因此,应根据实际业务需求,考虑模型部署服务器配置、模型并行度、模型服务实例数等。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









