






1. Ollama 简介 https://ollama.com
Ollama 是一个本地运行的大语言模型(LLM)工具平台,允许用户在本地设备上运行和管理大模型,而无需依赖云服务。它支持多种开源模型,并提供了用户友好的接口,非常适合开发者和企业使用。
安装 Ollama
首先,从 Ollama 官网 下载安装包,并按照提示完成安装。
启动Ollama
Windows下搜索ollama,然后点击启动

Ollama 命令介绍
Ollama 提供了几个简单易用的命令,基本功能如下:
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve 启动 Ollama 服务
create 从 Modelfile 创建一个模型
show 查看模型详细信息
run 运行一个模型
stop 停止正在运行的模型
pull 从注册表拉取一个模型
push 将一个模型推送到注册表
list 列出所有可用的模型
ps 列出当前正在运行的模型
cp 复制一个模型
rm 删除一个模型
help 获取关于任何命令的帮助信息
Flags:
-h, --help helpfor ollama
-v, --version Show version information
拉取模型并运行
ollama pull 具体的模型,这里以deepseek为例
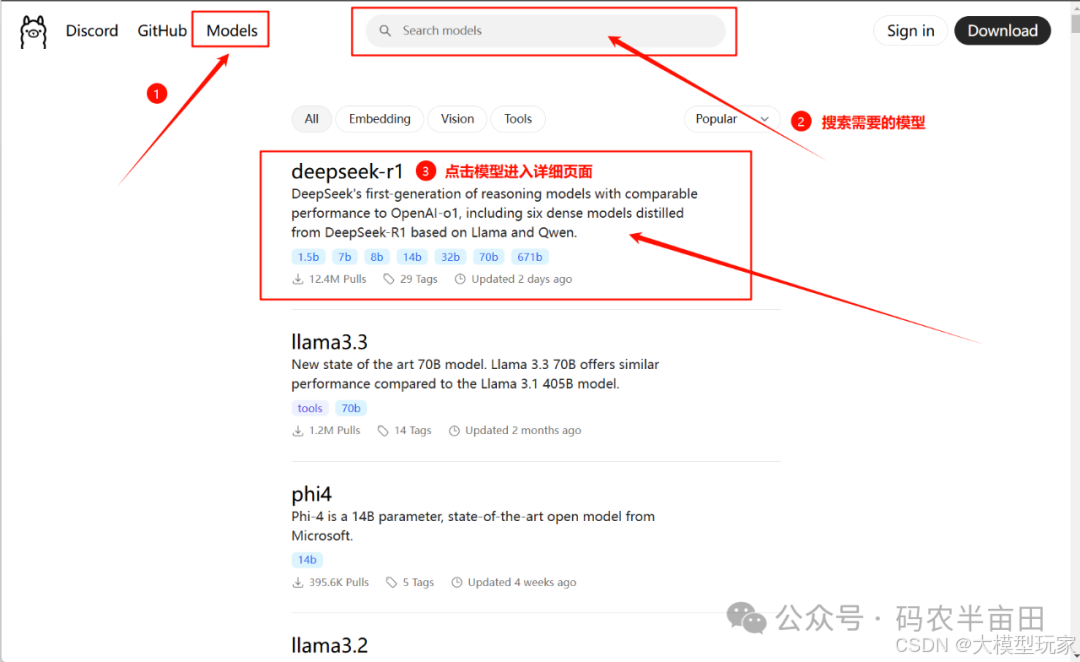
1. 选择模型
2. 搜索你想要的模型:比如 deepseek,qwen
3. 选择你的模型
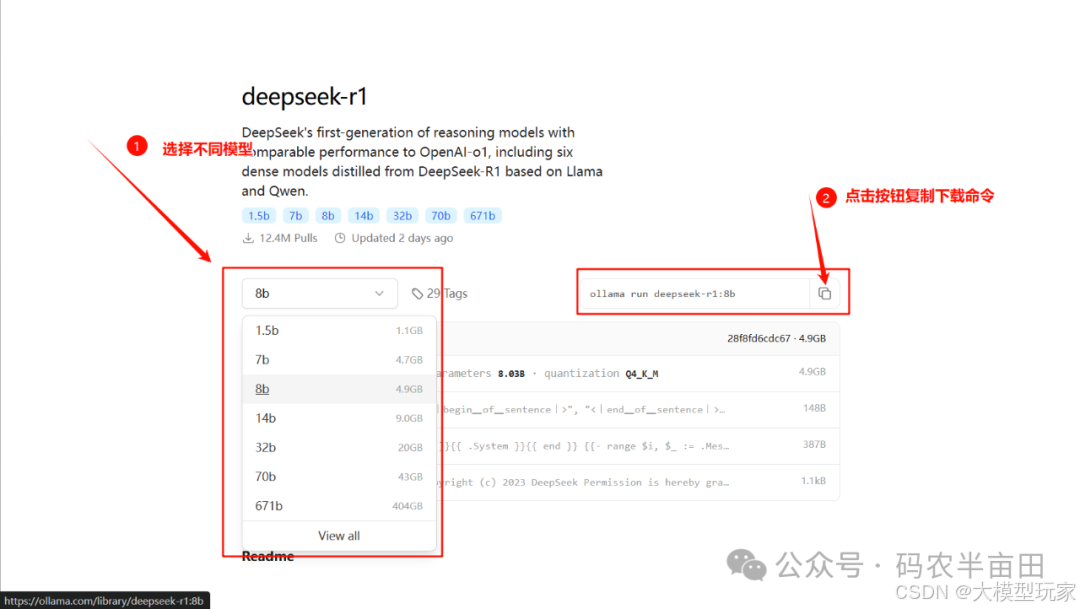
1. 选择模型大小
2. 复制下载指令,替换为下面,并在终端中执行
ollama pull deepseek-r1:14b
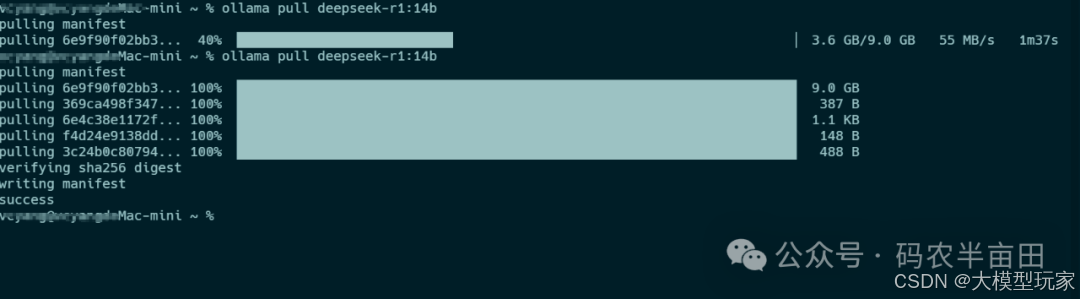
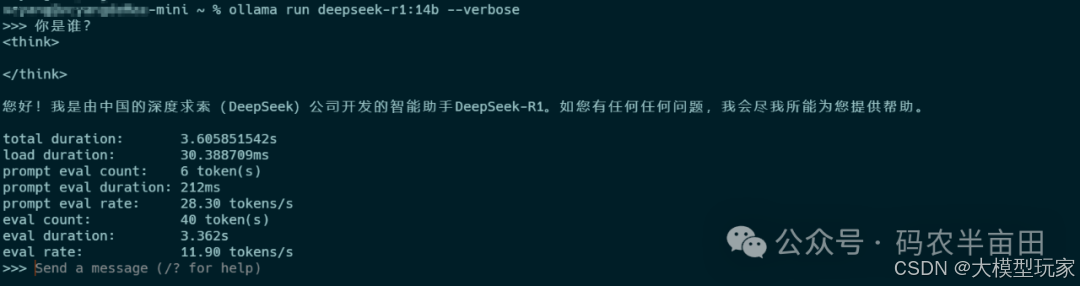
运行模型并对话,–verbose参数可以显示token信息
ollama run deepseek-r1:14b --verbose

信息如下:
资源占用情况:
退出对话
/bye
运行ollama远程服务
ENV OLLAMA_HOST=0.0.0.0:11434 ollama serve
—
2 RAGFlowj简介 https://ragflow.io
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。它主要适用于需要动态生成内容且依赖外部知识库的场景,例如智能客服、文档生成、数据分析等。
RAGFlow的安装和部署
📝前置条件
-
CPU ≥ 4 cores (x86);
-
RAM ≥ 16 GB;
-
Disk ≥ 50 GB;
-
Docker ≥ 24.0.0 & Docker Compose ≥ v2.26.1.
如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。
🚀 启动服务器
-
确保
vm.max_map_count不小于 262144:如需确认
vm.max_map_count的大小:$ sysctl vm.max_map_count如果
vm.max_map_count的值小于 262144,可以进行重置:# 这里我们设为 262144: $ sudo sysctl -w vm.max_map_count=262144你的改动会在下次系统重启时被重置。如果希望做永久改动,还需要在 /etc/sysctl.conf 文件里把
vm.max_map_count的值再相应更新一遍:vm.max_map_count=262144 -
克隆仓库:
$ git clone https://github.com/infiniflow/ragflow.git -
进入 docker 文件夹,利用提前编译好的 Docker 镜像启动服务器:
请在运行
docker compose启动服务之前先更新 docker/.env 文件内的RAGFLOW_IMAGE变量。比如,你可以通过设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0来下载 RAGFlow 镜像的v0.16.0完整发行版。镜像比较大,需要留足磁盘空间,另外docker下载需要自备科学上网方式,否则有些镜像拉取不下来
$ cd ragflow
$ docker compose -f docker/docker-compose-CN.yml up -d
服务器启动成功后再次确认服务器状态:
$ docker logs -f ragflow-server
出现以下界面提示说明服务器启动成功:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
如果您跳过这一步系统确认步骤就登录 RAGFlow,你的浏览器有可能会提示
network anormal或网络异常,因为 RAGFlow 可能并未完全启动成功。
-
在你的浏览器中输入你的服务器对应的 IP 地址并登录 RAGFlow。
上面这个例子中,您只需输入 http://IP_OF_YOUR_MACHINE 即可:未改动过配置则无需输入端口(默认的 HTTP 服务端口 80)。
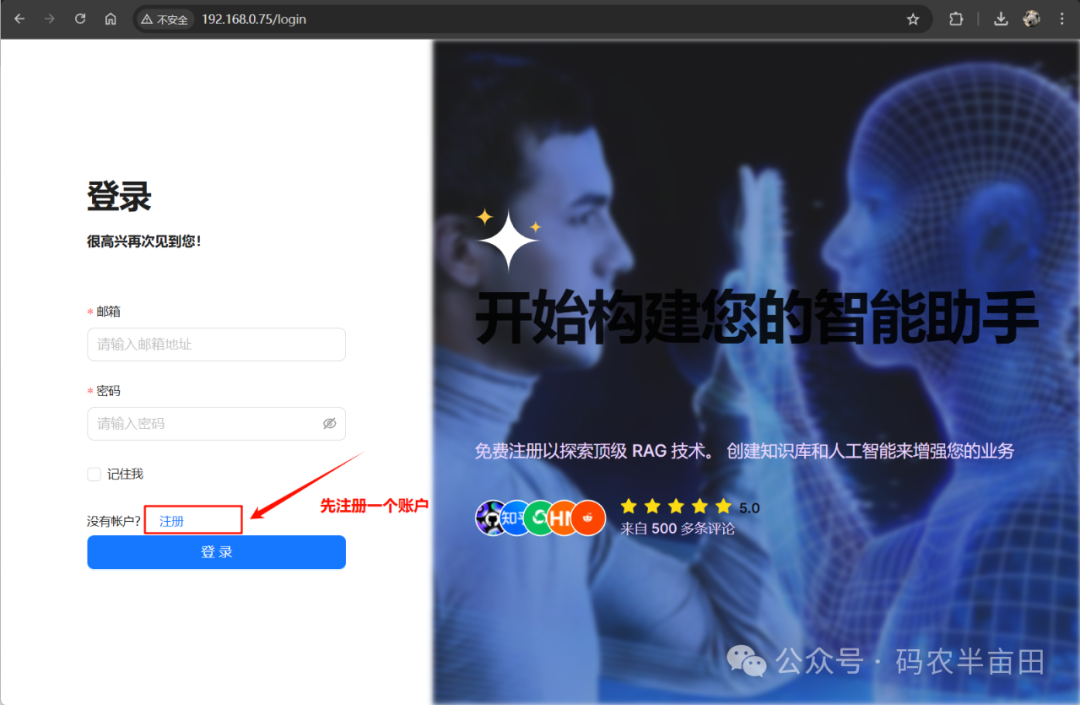
注册登录
在上图的界面中注册,然后登录就来到下面这个页面了
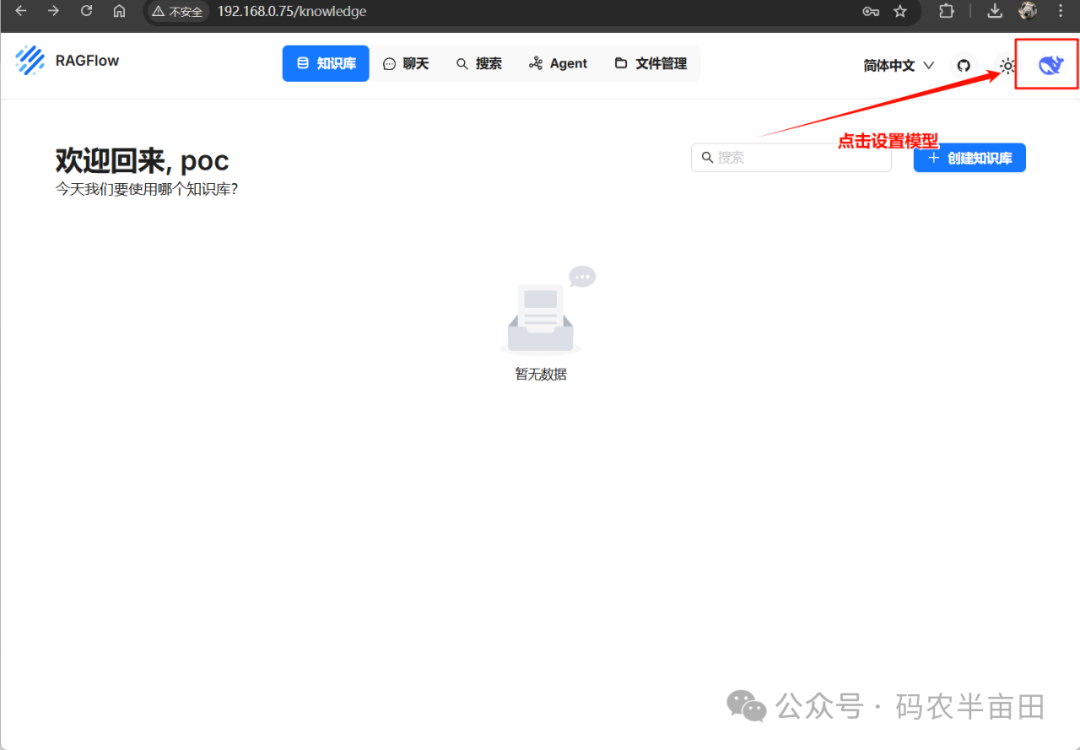
配置 Ollama 连接大模型
-
如下图我们先配置模型,点击右上角头像,再点击模型提供商
-
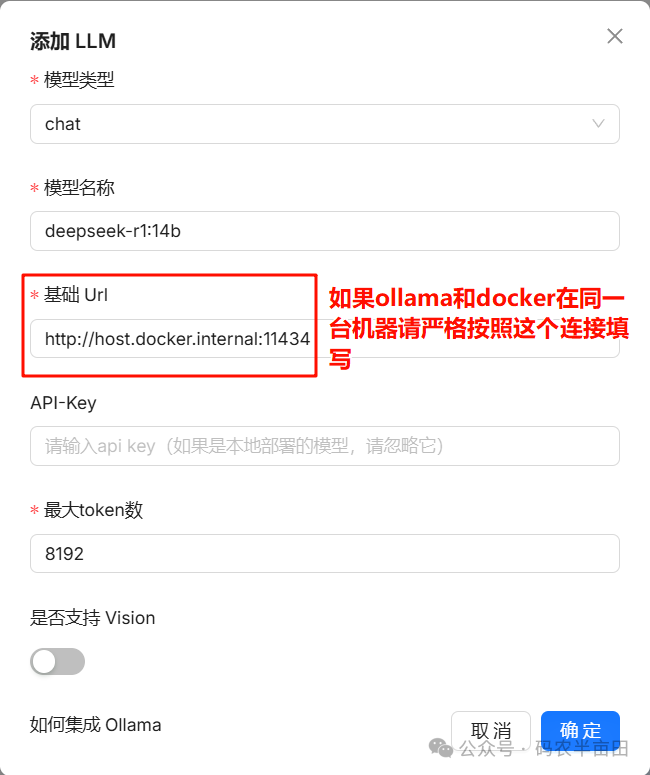
接着我们在 RagFlow 中配置模型,注意由于 RagFlow 是在 docker 中安装的,所以请求本地部署的 Ollama 地址要用 :host.docker.internal:11434,如果docker在局域网其他服务器上,则直接填写局域网http://局域网ip:11434
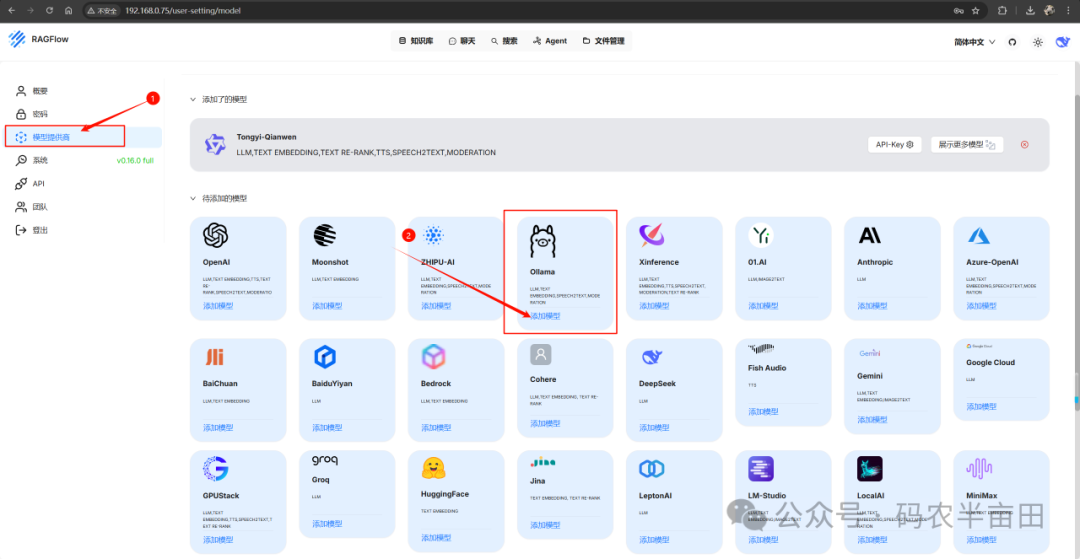
1. 选择模型提供商
2. 选择ollama
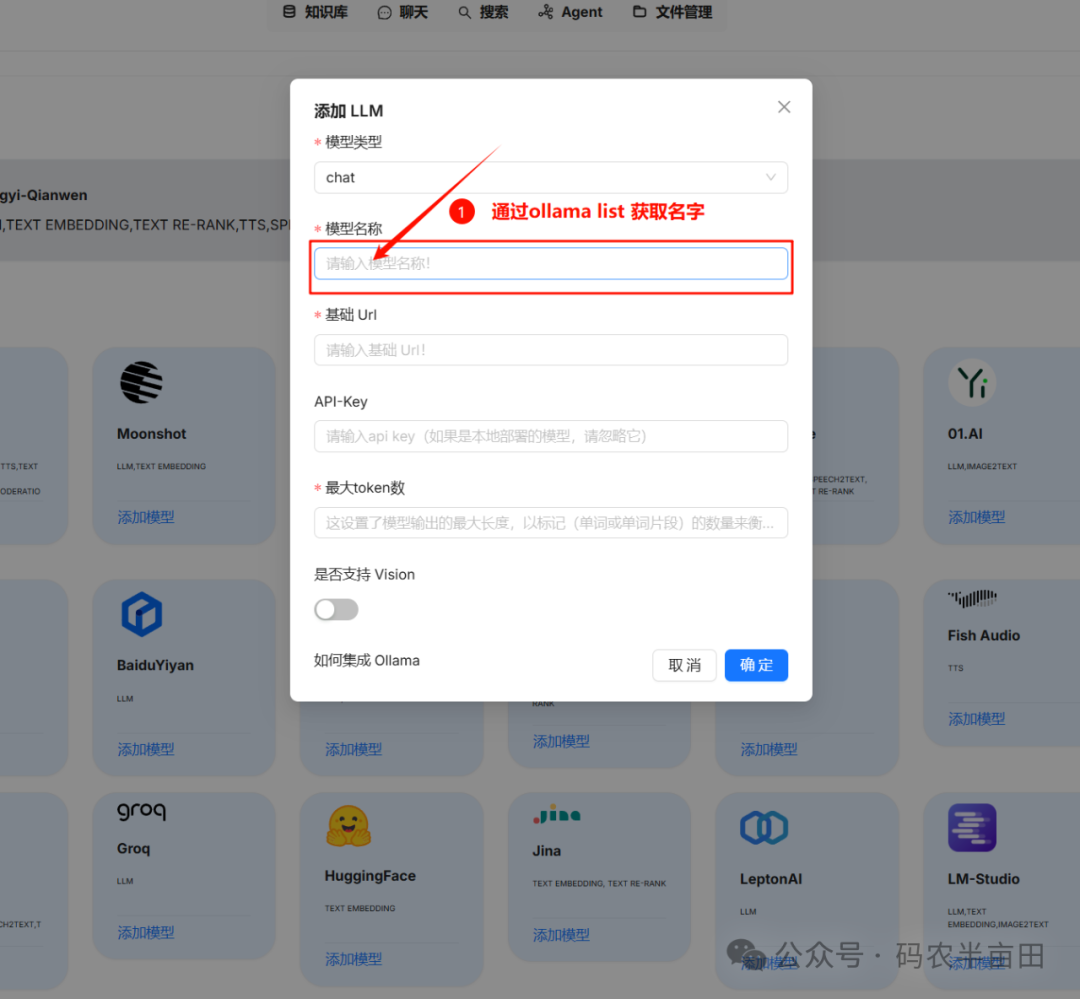
通过命令获取ollama模型列表
ollama list

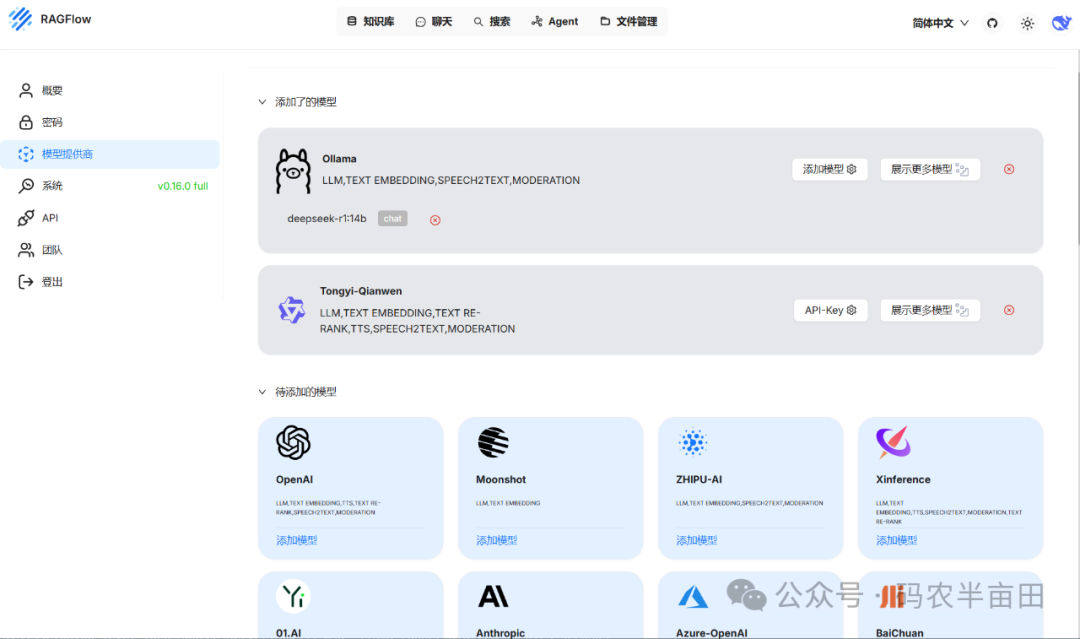
最终信息填写如下:
创建知识库
接下来我们就可以创建知识库了
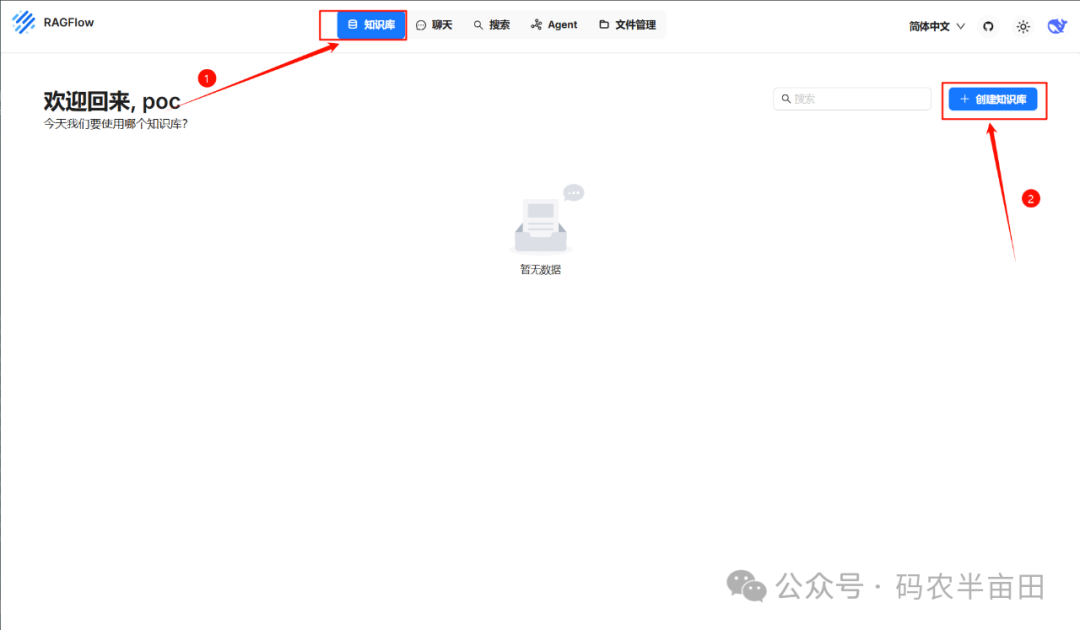
1. 选择知识库
2. 创建知识库
输入知识库名字
配置知识库属性
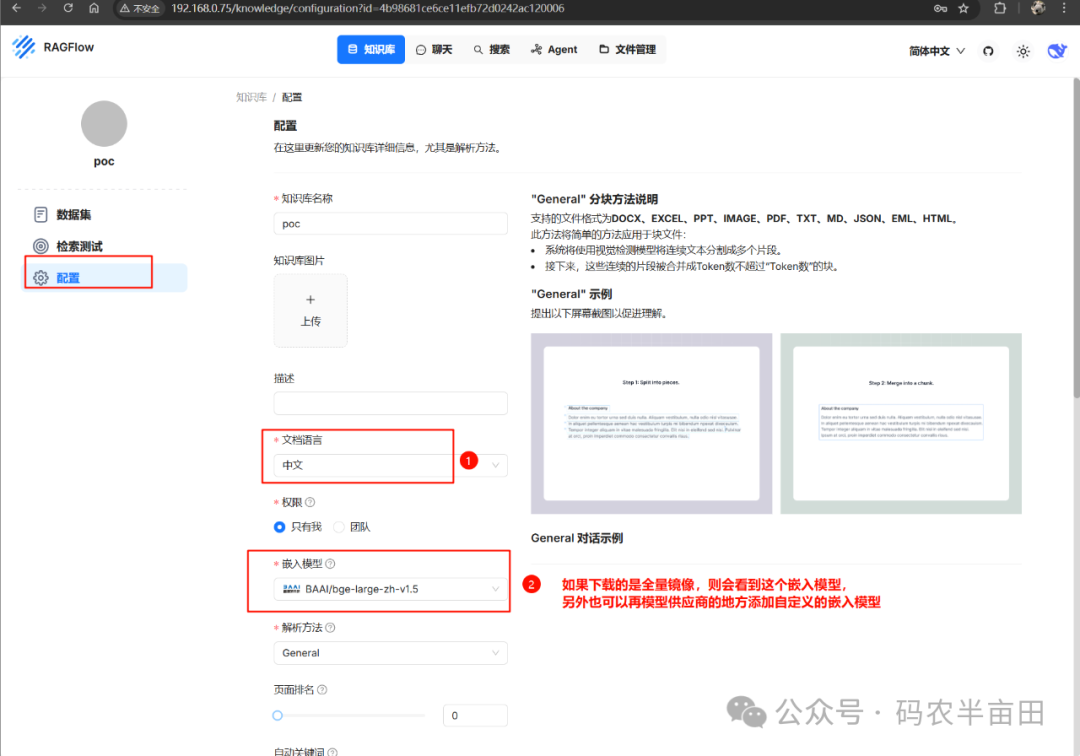
1 选择文档语言
2 如果下载是全量的RAGFlow镜像,会带有嵌入模型,可以按图中选择;另外也可以添加自定的嵌入模型,方法同前面的模型提供商设置
其他的选项,根据你的情况自行设置就好,很简单
添加私有文档
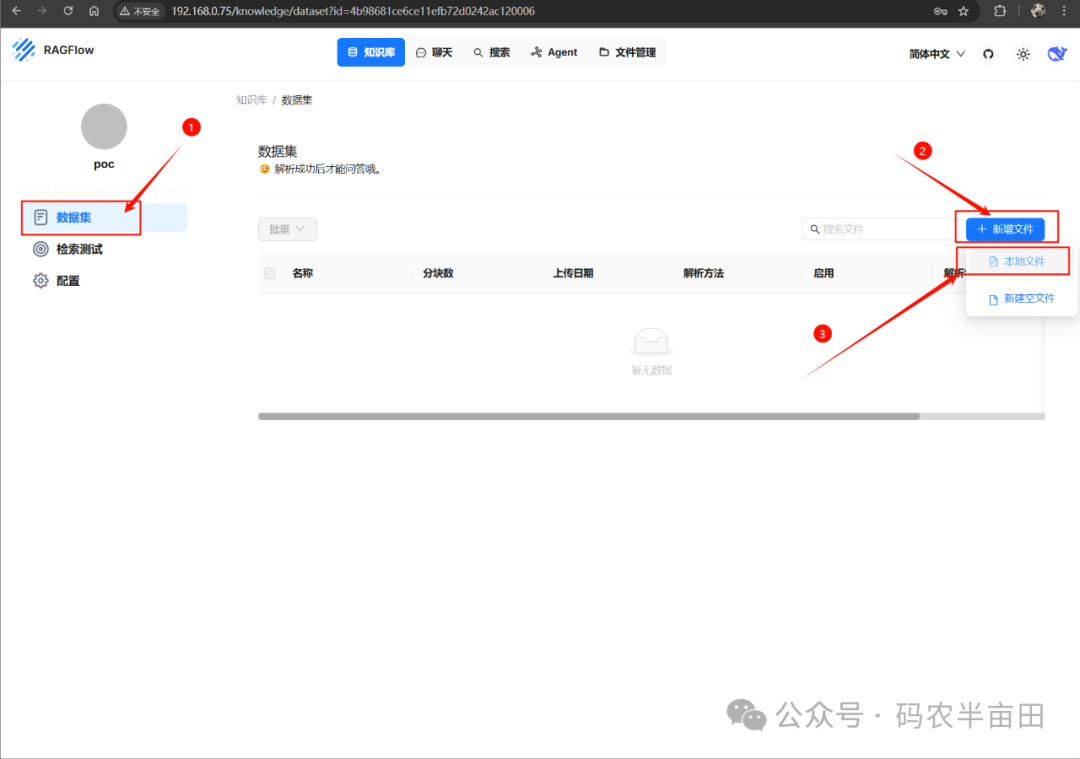
1. 选择数据集
2. 点击新建文件
3. 上传本地文档
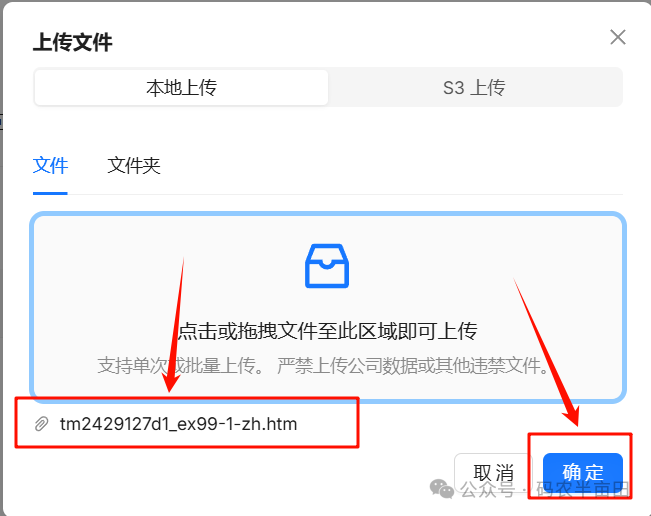
解析文档
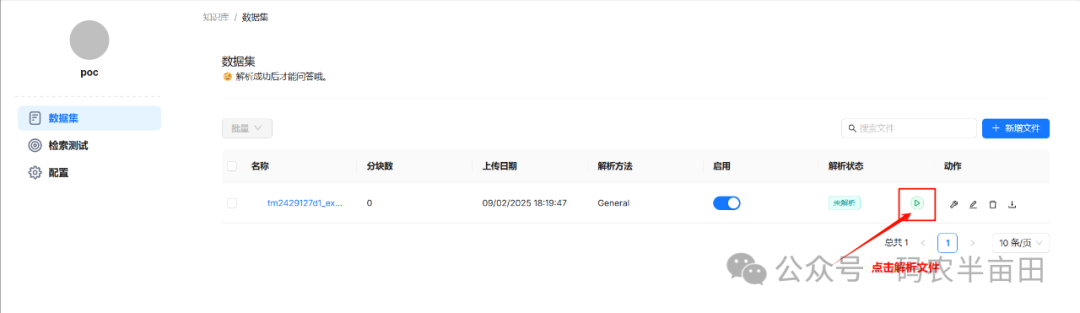
看下下面状态,说明文档解析完成
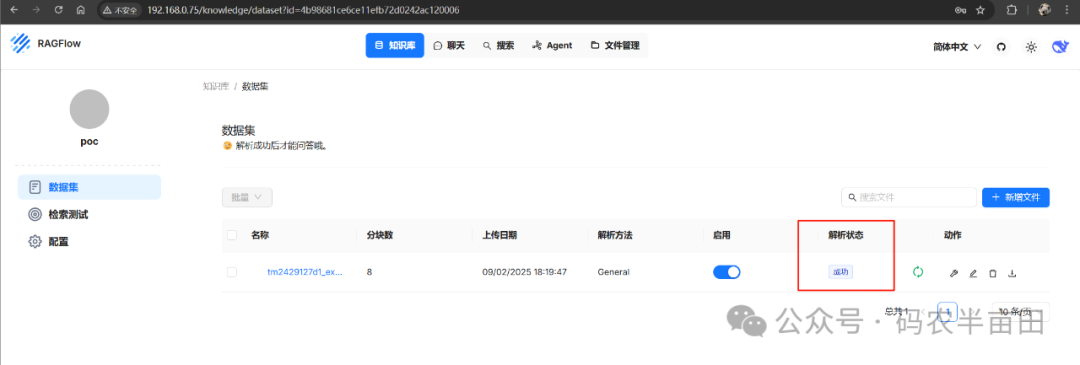
开启聊天
接着就到了展示成果的时候了,我们可以根据自己的知识库与模型进行自然语言交互了。
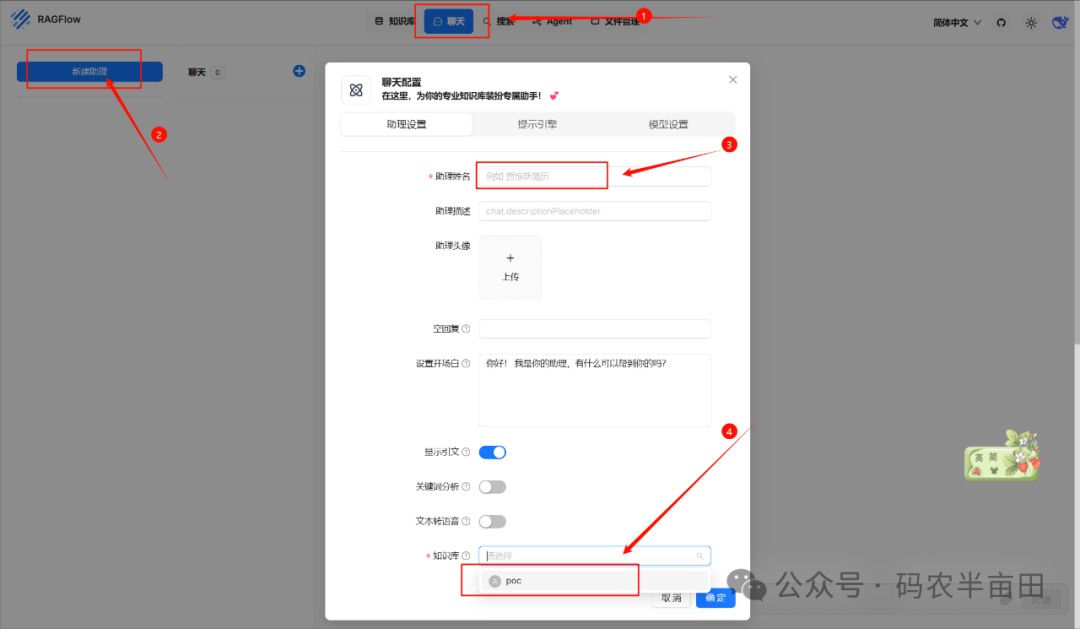
1. 选择聊天
2. 创建聊天助理
3. 填写助理名字:比如 张三
4. 选择刚才创建的知识库
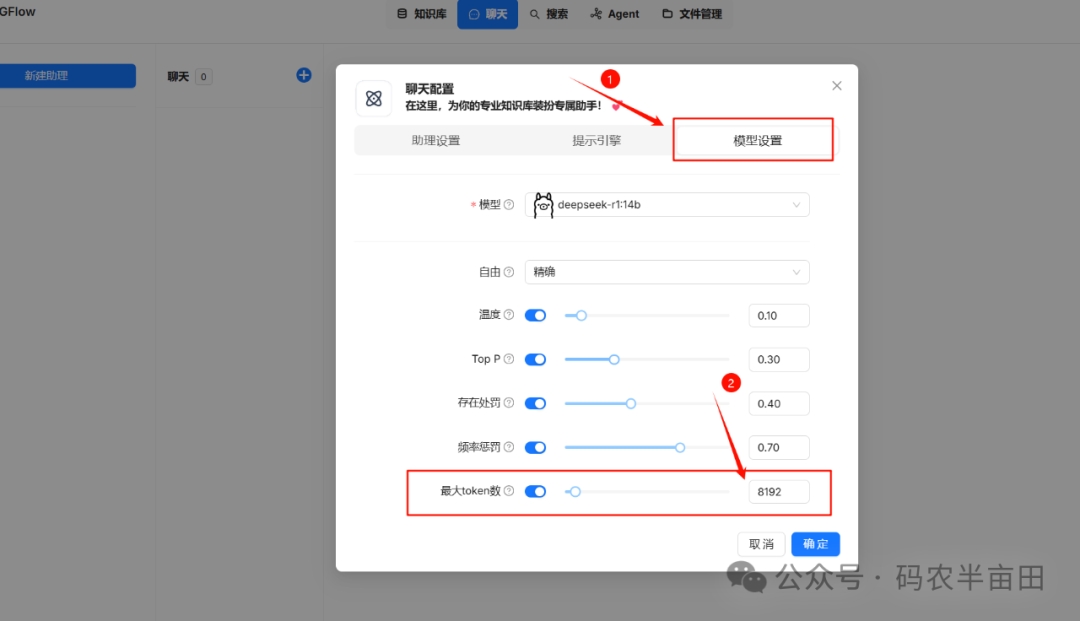
配置聊天模型,如下:
首先注意,在聊天配置中要把 token 设置大一些,不然回复的内容会很少!我这里把它拉到最大值了。
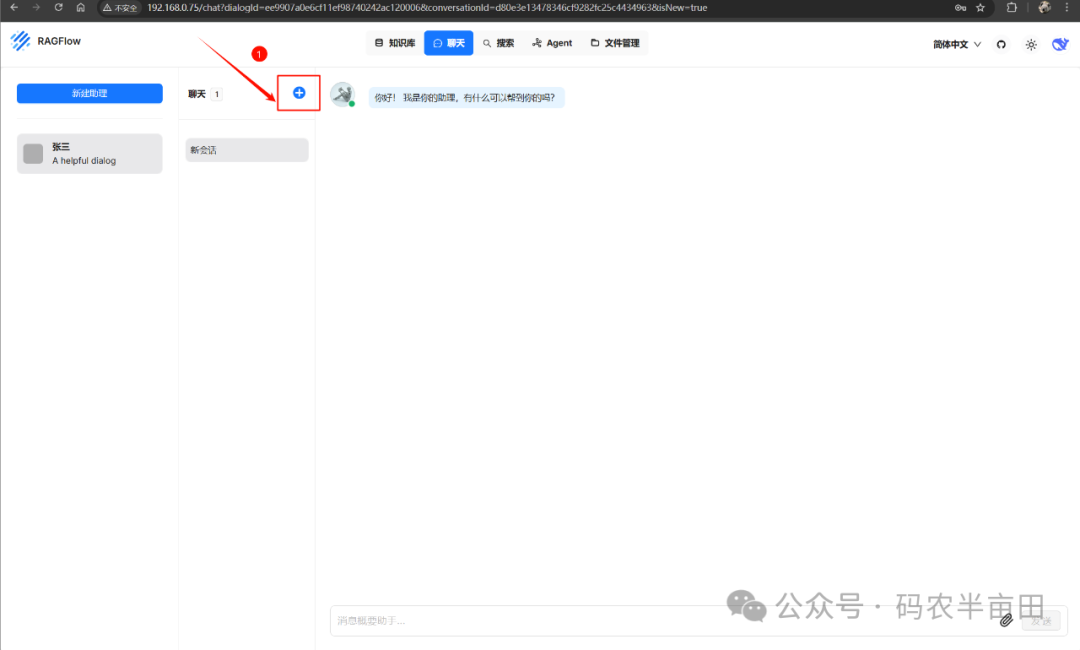
新建一个对话
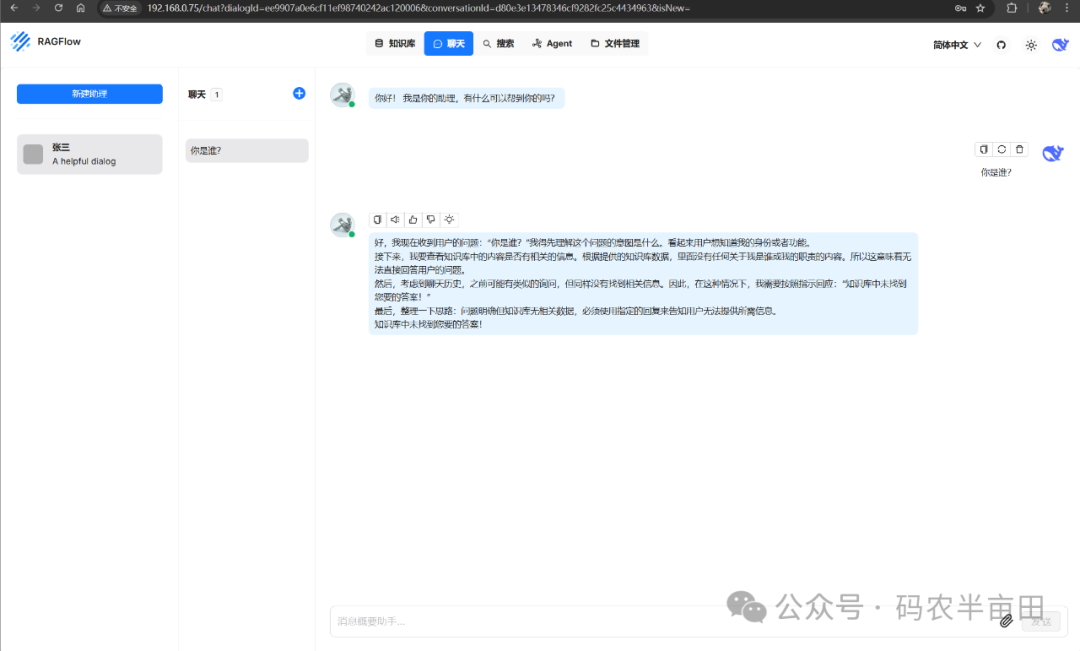
数据验证
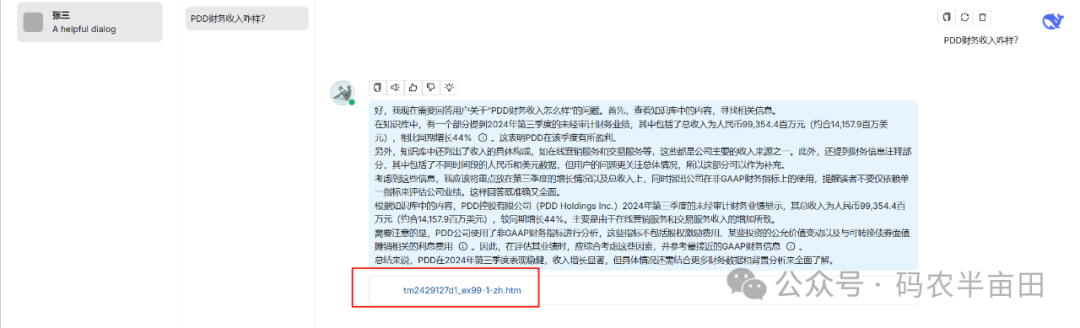

上面上传的文档是PDD的财务报表,截图中可以看到聊天内容召回了文档中的内容。
Agent功能
RAGFlow也支持agent功能,后面再进行探索
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 8805
8805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









