 RAG系统评估与AI大模型学习指南
RAG系统评估与AI大模型学习指南




 在企业或者单位内部,我们搞了个RAG应用,塞进去一堆文档,想着能给团队提供又快又准的信息。刚开始,那感觉简直像变魔术一样神奇!但大家都知道,大模型总有穿帮的时候,现实总会给你当头一棒。
在企业或者单位内部,我们搞了个RAG应用,塞进去一堆文档,想着能给团队提供又快又准的信息。刚开始,那感觉简直像变魔术一样神奇!但大家都知道,大模型总有穿帮的时候,现实总会给你当头一棒。
今天这篇文章,我们通过几个指标来讲一讲:如何从一个反馈乱七八糟的RAG系统,到现在逐渐走向稳定的生产环境?
为什么要评估RAG系统?
刚开始,我们可能压根没想过要搞什么评估框架。我们就是把RAG应用丢给一小部分人用,然后坐等反馈。结果呢?反馈五花八门,有的说好用到飞起,有的说烂到不行。有些问题的答案堪称完美,有些则错得离谱。起初,我们还亲自上阵,手动测试一组问题,检查答案并打分。虽然在小规模测试中还行,但随着用户越来越多,数据量越来越大,我们很快就发现自己彻底迷失了。
直觉根本不够用!
没有系统的评估,我们就像在摸黑走路,全靠运气。很明显,我们得搞清楚为什么有些东西能成功,有些却会失败。这时候,指标的重要性就凸显出来了。
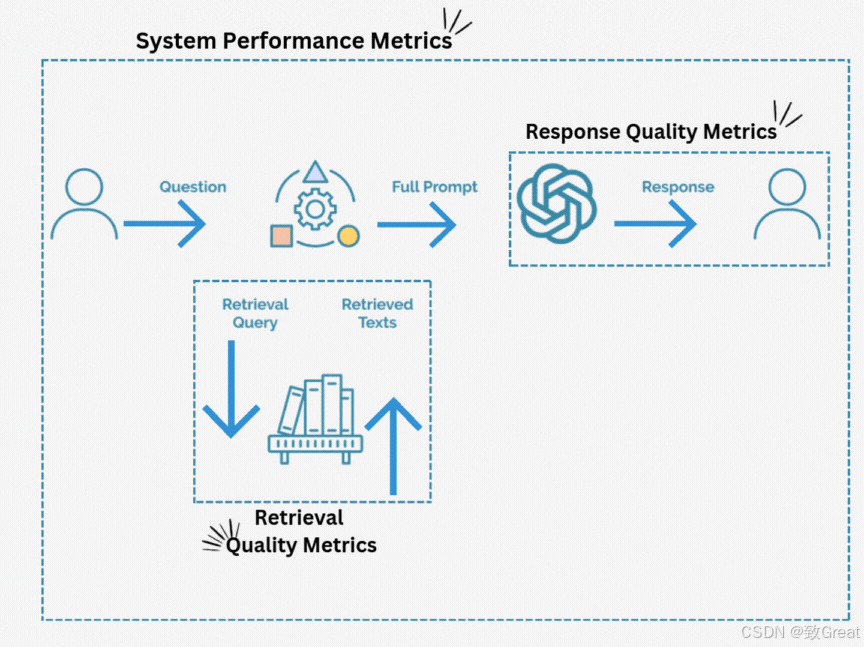
RAG系统的两大核心组件
一个典型的RAG系统主要由两部分组成:
-
检索器:这家伙负责响应用户的查询,从知识库(通常是矢量数据库)里找出相关信息。
-
生成器:它则利用检索到的上下文和用户的查询,生成连贯、相关且信息丰富的回答。
评估RAG系统,就得从这两个部分入手,同时还要关注系统整体的表现。
RAG评估的三大维度
评估RAG系统,通常得从以下几个关键领域入手:
-
检索质量:检索器能不能准确找到并抓取相关文档?
-
响应质量:生成器能不能用好检索到的上下文,给出准确且有用的回答?
-
系统性能:整个RAG系统在成本和响应速度上表现如何?
7个你必须关注的指标
根据我的经验,要想打造一个成功的RAG应用,你得盯紧以下7个关键指标:
-
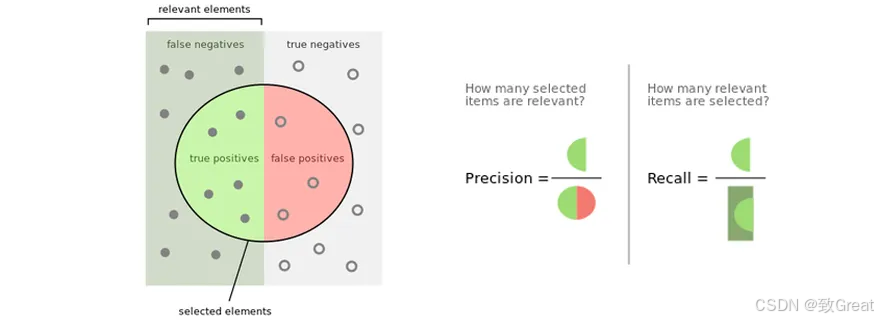
Precision@k(我们拿到的是相关内容吗?):这个指标告诉我,在检索器给出的前k个结果里,有多少是真正和查询相关的。质量永远比数量重要!
-
Recall@k(我们漏掉了什么?):我得知道系统有没有漏掉相关文档。召回率就是衡量在前k个结果里,我们抓到了多少真正相关的文档。
-
Faithfulness/Groundedness(忠实度/真实性)(我们有没有在瞎编?):这个指标检查生成的回答是不是真的基于检索到的文档。如果系统开始“脑补”事实,那信任可就崩塌了。方法可以是人工评估、自动事实核查工具,或者一致性检查。
-
答案相关性(我们真的在回答问题吗?):答案光有事实还不够,还得真正解决用户的疑问。这个指标就是看生成的回答和用户的问题是不是对得上。
-
幻觉检测(我们是不是在编造事实?):这个指标帮你盯紧系统,看它有没有在捏造事实,或者做出数据里根本没有的断言。
-
延迟(是不是太慢了?):系统响应需要多长时间?如果太慢,用户可没耐心等你。
-
Token消耗(成本效益如何?):这个指标估算每个请求的成本,帮我们优化资源使用,避免浪费。
还有哪些指标值得关注?
虽然前面提到的7个指标是认为必不可少的,但RAG系统的评估远不止这些。根据你的具体需求,还有很多其他指标可能会派上用场。咱们一起来看看:
-
F1@k:这个指标是精度和召回率的“和事佬”,帮你平衡两者,给出一个综合的评估结果。
-
平均倒数等级(MRR):如果你只关心第一个相关文档的位置,这个指标就特别有用。
-
平均精度(AP):当检索到的相关文档的顺序很重要时,这个指标能派上大用场。
-
累积收益(DCG@k):这个指标会根据文档的位置来衡量它们的有用性,位置越靠前,得分越高。
-
标准化累积增益(NDCG@k):这是DCG的标准化版本,方便你在不同结果集之间进行比较。
-
上下文精确度/召回率/相关性:这些指标特别适合用来评估你的检索步骤,看看上下文抓取得准不准。
-
BLEU、ROUGE、METEOR:如果你在搞大量文本摘要或生成,这些指标能帮你分析生成的内容质量。
-
语义相似性:这个指标衡量生成的回答和参考文本在语义上是否接近,确保回答的意思没跑偏。
-
正确性、安全性:当你的应用对正确性和安全性要求极高时,这些指标就是你的“守护神”。
RAG评估的核心要素
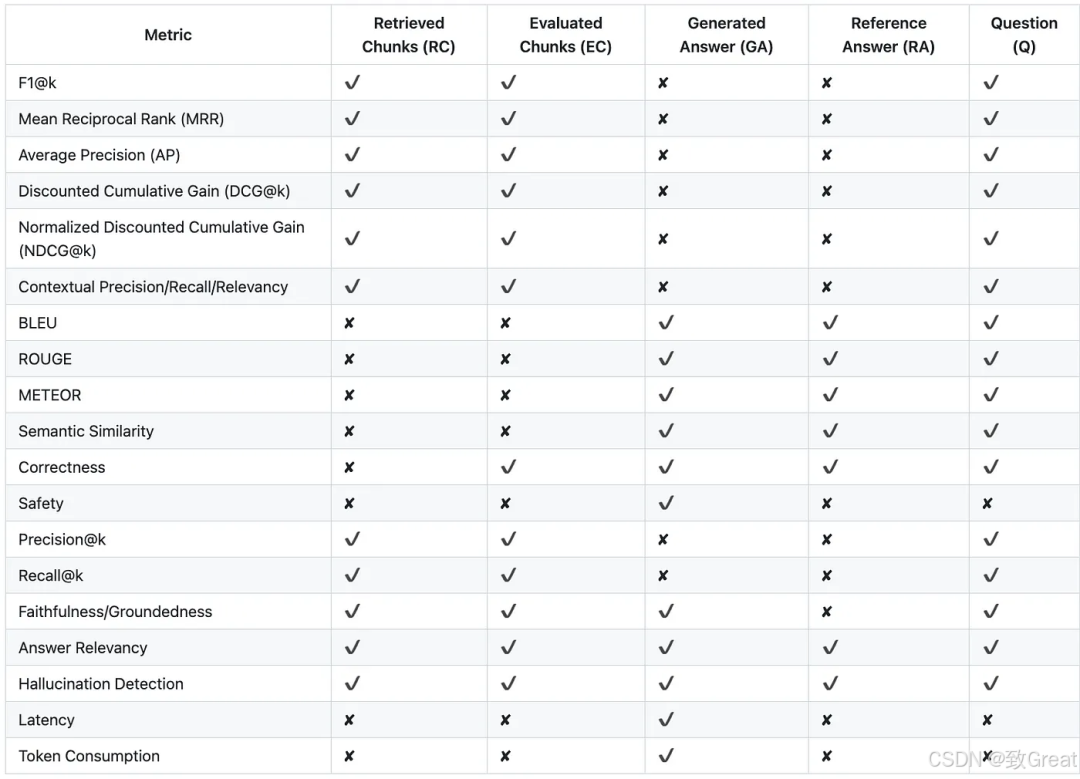
在评估RAG系统时,有几个关键要素你得时刻关注:
-
已检索到的块 (RC):这是检索器从知识库里抓出来的内容块。
-
已评估块 (EC):这些是经过人工或LLM评估,确认与问题相关的块。
-
生成的答案 (GA):这是LLM根据检索到的内容生成的最终回答。
-
参考答案 (RA):这是人类或另一个LLM提供的理想答案,用来做对比。
-
问题(Q):这是用户实际提出的问题,评估的起点。
评估方法:从人工检查到LLM评审
如何全面衡量RAG系统?
评估RAG系统,主要有两种方法:
-
确定性测量:这些指标可以直接从系统日志里算出来,比如延迟、令牌使用情况,还有召回率(前提是你有数据)。这类指标计算起来相对简单直接。
-
LLM评判式评估:这种方法让另一个LLM充当“评委”,来评估相关性、忠实性和正确性等因素。虽然需要仔细设计提示词和调整评委LLM,但效果绝对值得你花这个功夫。
这两种方法各有千秋,结合起来用才能做到全面评估。
分层评估法:分步流程
分步组织评估:
-
初始检索测试:首先用精度、召回率和MRR等指标,确保检索到的文档质量过关。
-
回答质量检查:一旦确认检索没问题就开始关注回答质量,用自动评估和LLM评委来检查忠实度、幻觉检测和答案相关性。
-
系统性能分析:接着检查延迟和令牌消耗,优化系统性能,降低成本。
-
迭代改进:最后根据指标不断调整系统,跟踪超参数的变化,持续评估和优化。
工具和框架推荐
在评估RAG系统时,有几个工具和框架挺不错:
-
RAGAS:简化评估流程,强调平均精度和忠实度等自定义指标。
-
ARES:利用合成数据和LLM评委,重点关注MRR和NDCG。
-
DeepEval:一个开源框架,提供一系列LLM评估指标,覆盖检索和生成。
-
TruLens:专注于特定领域的优化,强调领域内的准确性和精确度。
-
Galileo:集成先进见解和指标,提升性能和透明度。
-
Tonic Validate:专门测量RAG LLM系统的性能。
-
G-Eval:使用带有思路链(CoT)的LLM,根据自定义标准评估LLM输出。
经验分享:RAG实践
在这段RAG系统构建的过程中,我们学到了不少干货:
-
多样化数据:评估集里得有各种各样的问题,才能全面覆盖系统的表现。
-
明确目标:优先关注那些真正重要的指标,别被次要的东西分散注意力。
-
别跳过人工审核:LLM虽然强大,但人工审核依然不可或缺。
-
迭代和自动化:持续测试,自动化评估流程,及时跟踪变化。
-
平衡评估成本:如果系统用的人少,搞太详细的指标可能不划算;但如果用的人多,没有合适的指标,成本反而更高。
-
跟踪超参数和指标的变化:记录实验配置,了解不同参数对指标的影响。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 7537
7537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









