






1 什么是 MCP
2 MCP Server 开发
3 MCP Client 开发
4 MCP的工作原理
5 效果呈现
6 写在最后
本文系统介绍了MCP协议在大模型交互标准化中的创新应用,通过技术解析+实践案例的方式,阐述了MCP协议的架构设计、开发实现原理及实际应用效果。重点探讨了MCP如何解决AI工具调用碎片化问题,并通过企业微信机器人开发实例展示MCP服务端/客户端开发全流程,干货满满点赞收藏!
什么是 MCP
1.1 MCP 介绍
MCP(Model Context Protocol,模型上下文协议) 起源于 2024 年 11 月 25 日 Anthropic 发布的文章:Introducing the Model Context Protocol。
可以用“AI 扩展坞”来比喻 MCP 在 AI 领域的作用。就像现代扩展坞可以连接显示器、键盘、移动硬盘等多种外设,为笔记本电脑瞬间扩展功能一样,MCP Server 作为一个智能中枢平台,能够动态接入各类专业能力模块(如知识库、计算工具、领域模型等)。当 LLM 需要完成特定任务时,可以像"即插即用"般调用这些模块,实时获得精准的上下文支持,从而实现能力的弹性扩展。这种架构打破了传统 AI 模型的封闭性,让大语言模型像搭载了多功能扩展坞的超级工作站,随时都能获取最合适的专业工具。
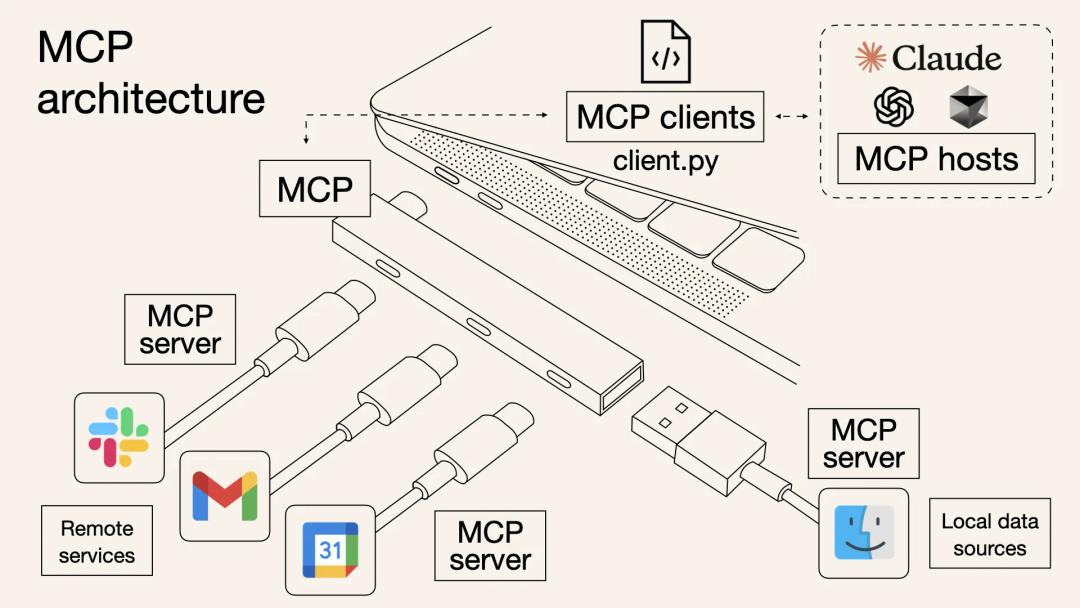
1.2 为什么要有 MCP
终结工具调用碎片化
不同模型在定义 Function Call(函数调用)时,采用的结构和参数格式各不相同,使得对多模型集成、统一管理和标准化接入变得复杂而繁琐。
| 属性维度 | OpenAI | Claude | Gemini | LLaMA |
|---|---|---|---|---|
| 调用结构名称 | tool_calls | tool_use | functionCall | function_call |
| 参数格式 | JSON字符串 | JSON对象 | JSON对象 | JSON对象 |
| 特殊字段 | finish_reason字段 | 包含id和<thinking> | args字段命名 | 与OpenAI结构相似 |
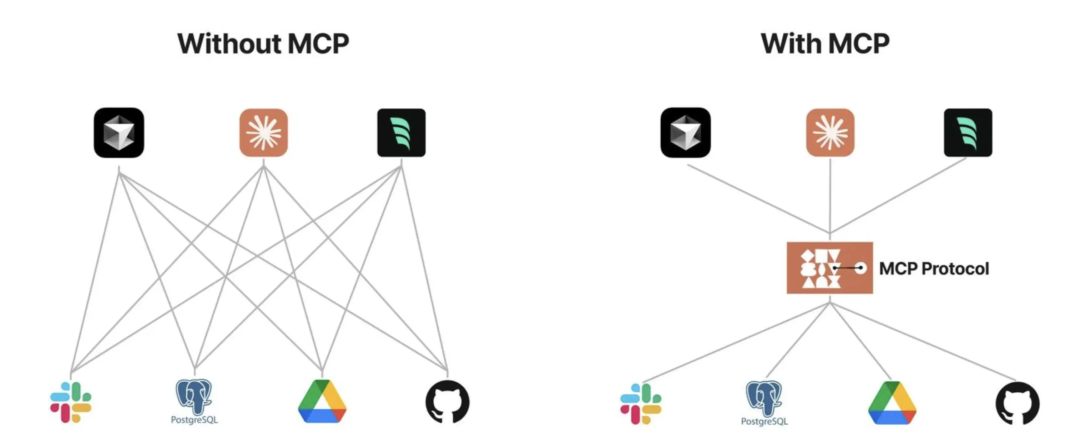
对于开发者来说,针对不同模型去实现不同的工具调用方法,所谓的定制化开发不仅消耗大量时间和资源,而且维护也变得困难。
而 MCP 作为一种 AI 模型的标准化接入协议,能够显著简化模型之间的集成。
实现多功能应用与创新体验的突破
MCP 的潜力不仅限于连接现有工具,它还在推动客户端应用向“万能应用”演进,并创造全新的用户体验。
以代码编辑器 Cursor 为例,作为 MCP 客户端,用户可以通过集成不同的 MCP 服务器,将其转变为具备 Slack 消息收发、邮件发送(Resend MCP)、甚至图像生成(Replicate MCP)等多种功能的综合工作站。
更具创造力的是,在单一客户端中组合多个 MCP 服务器可以解锁复杂的新流程。例如,AI 代理可以一边生成前端界面代码,一边调用图像生成服务器为主页创作视觉元素。这种模式超越了传统应用的单一功能限制,为用户带来多样化的操作体验。
MCP Server 开发
MCP server 是 MCP 架构中的关键组件,目前提供 3 种主要类型的功能,
- 资源(Resources):类似文件的数据,可以被客户端读取,如 文件内容。
- 工具(Tools):可以被 LLM 调用的函数。
- 提示(Prompts):预先编写的prompt模板,帮助用户完成特定任务。
还有其他两种(samping 和 roots)但是目前还没被很好的支持。
以开发一个企业微信机器人 mcp server 为例,用到的是社区sdk typescript-sdk 。(https://github.com/modelcontextprotocol/typescript-sdk)
2.1 项目搭建开发
可以参考官方 quickstart(https://modelcontextprotocol.io/quickstart/server)
环境:nodejs > v16 (我用的是 v22.6)
npm init -y
# Install dependenciesnpm install @modelcontextprotocol/sdk zodnpm install -D @types/node typescriptmkdir srctouch src/index.ts
创建 mcp-server 实例
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";export const server = new McpServer({ name: "wechat-mcp-server", version: "0.0.1",});
可以直接使用 sdk 封装好的 McpServer 函数。
创建 tools 工具
定义 mcp 提供给 client 或者 llm 使用的工具,企业微信机器人主要就是 发送文本、发送 markdown、发送图片等等,这里我们举例一个发送文本的工具实现
text.ts
// Helper function for sending WeChat messagesexport async function sendWeChatTextMessage(webhookKey: string, content: string, chatid: string = "@all_group", mentioned_list?: string[], mentioned_mobile_list?: string[], visible_to_user?: string): Promise<boolean> { const WECHAT_API_BASE = ` http://in.qyapi.wbin/webhook/send?key=${ webhookKey}`; const headers = { "Content-Type": "application/json", }; const body = JSON.stringify({ "msgtype": "text", "text": { "content": content, "mentioned_list": mentioned_list, "mentioned_mobile_list": mentioned_mobile_list }, "chatid": chatid, "visible_to_user": visible_to_user ? visible_to_user.split('|') : undefined }); try { const response = await fetch(WECHAT_API_BASE, { headers, method: "POST", body }); if (!response.ok) { throw new Error(`HTTP error! status: ${response.status}`); } return true; } catch (error) { console.error("Error sending WeChat message:", error); return false; } }
通过 server.tool 注册发送文本工具,注册工具有四个函数,比如有些可以加描述,有些是0参数调用等等,选一个合适自己的即可。我们这里必须需要知道回调的 webhook key 和 content 。
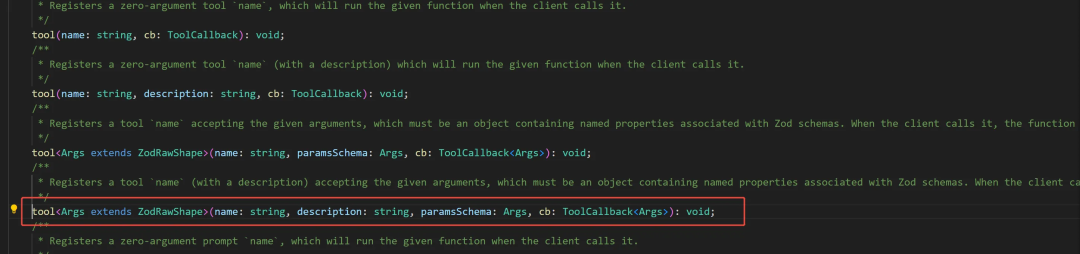
import { sendWeChatTextMessage } from "./text.js";// Register WeChat message toolserver.tool( "sendWeChatTextMessage", "send WeChat text message", { webhookKey: z.string().describe("WeChat webhook key"), // 必填 content: z.string().describe("WeChat message content"),// 必填 chatid: z.string().describe("WeChat message chatid").optional(), // optional 选填 mentioned_list: z.array(z.string()).describe("WeChat message mentioned list").optional(), mentioned_mobile_list: z.array(z.string()).describe("WeChat message mentioned mobile list").optional(), }, async ({ webhookKey, content, chatid, mentioned_list, mentioned_mobile_list }) => { const success = await sendWeChatTextMessage(webhookKey, content, chatid, mentioned_list, mentioned_mobile_list); if (!success) { return { content: [ { type: "text", text: "Failed to send WeChat message", }, ], }; } return { content: [ { type: "text", text: "WeChat message sent successfully", }, ], }; }, );
发送文本工具就注册好了,其他功能工具开发类似。
创建resource资源
这里我们放一个企业微信机器人的文档。
server.resource( "api", "file:///api.md", async (uri) => { try { console.info(uri) const __filename = fileURLToPath(import.meta.url); const __dirname = path.dirname(__filename); const filePath = path.join(__dirname.replace('build', 'assets'), 'api.md'); const content = await fs.promises.readFile(filePath, 'utf-8');
return { contents: [{ uri: uri.href, text: content }] }; } catch (error) { return { contents: [{ uri: uri.href, text: "读取文件失败" }] }; } });
创建prompt
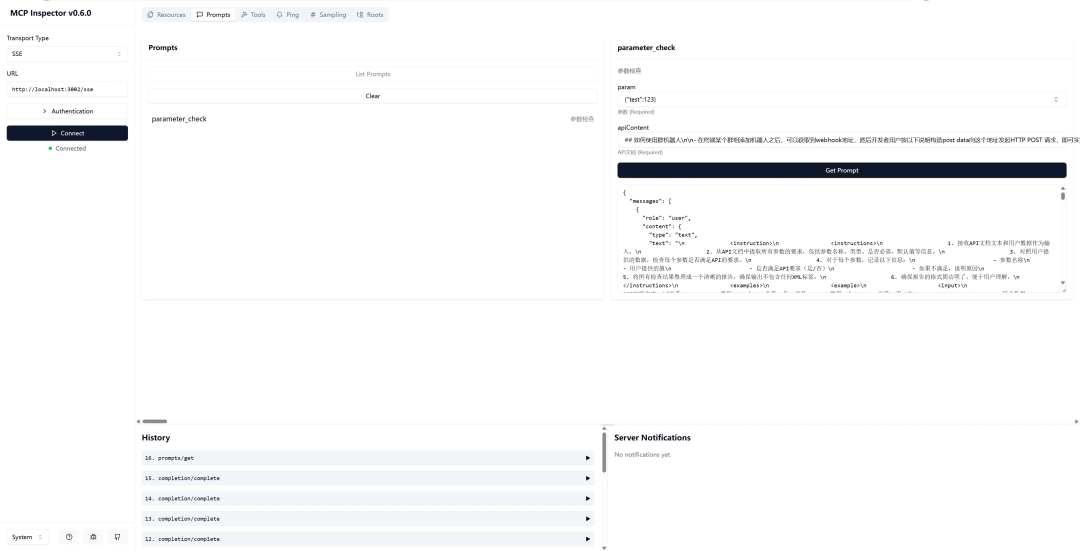
提示符是可重用的模板,可以帮助LLMs有效地与服务器交互。这里我们可以做一个参数检查的prompt。
server.prompt( "parameter_check", "参数检查", { param: z.string().describe("参数"), apiContent: z.string().describe("API文档") }, ({ param,apiContent }) => ({ messages: [{ role: "user", content: { type: "text", text: ` <instruction> <instructions> 1. 接收API文档文本和用户数据作为输入。 2. 从API文档中提取所有参数的要求,包括参数名称、类型、是否必需、默认值等信息。 3. 对照用户提供的数据,检查每个参数是否满足API的要求。 4. 对于每个参数,记录以下信息: - 参数名称 - 用户提供的值 - 是否满足API要求(是/否) - 如果不满足,说明原因 5. 将所有检查结果整理成一个清晰的报告,确保输出不包含任何XML标签。 6. 确保报告的格式简洁明了,便于用户理解。 </instructions> <examples> <example> <input> API文档文本: "参数: username, 类型: string, 必需: 是; 参数: age, 类型: integer, 必需: 否;" 用户数据: "{\"username\": john_doe, \"age\": 25}" </input> <output> "参数: username, 用户提供的值: john_doe, 满足要求: 是; 参数: age, 用户提供的值: 25, 满足要求: 是;" </output> </example> </examples> </instruction> API文档文本:${apiContent} 用户数据:${param} ` } }] }));
2.2 运行调试
可以使用社区Inspector工具来调试我们的mcp。我使用的版本是v0.6.0,如果是用devcloud开发的同学可能会无法调试使用,因为代理地址写死了是localhost,导致连接失败,已经给社区提了PR #201并合并,远程开发的同学可以直接拉源码或者等待工具发布新版本。(写完的时候发现已经发布v0.7.0,大家可以直接用最新版本了https://github.com/modelcontextprotocol/inspector)
调试tools
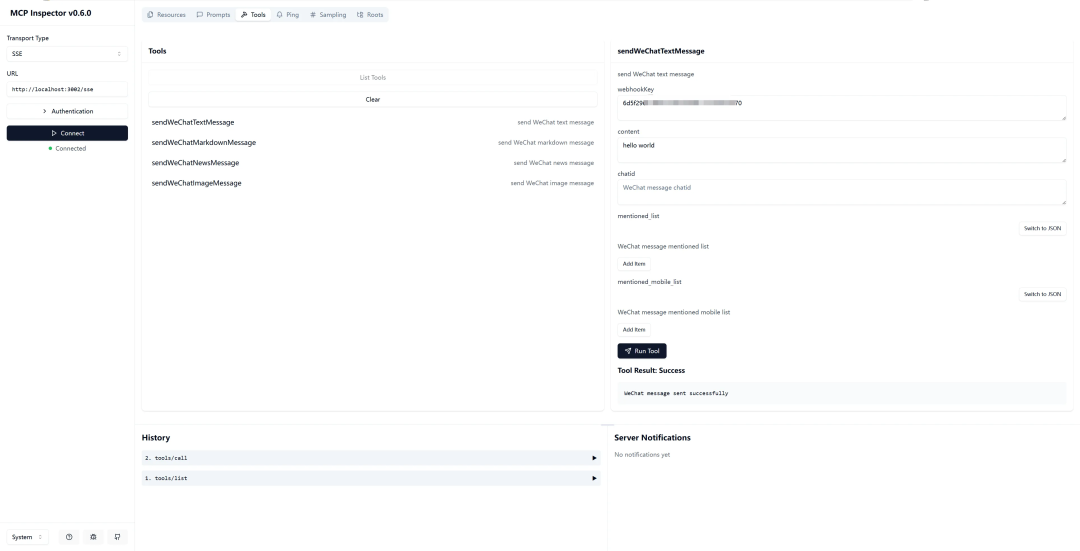
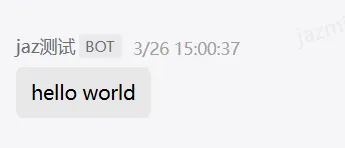
调试resource
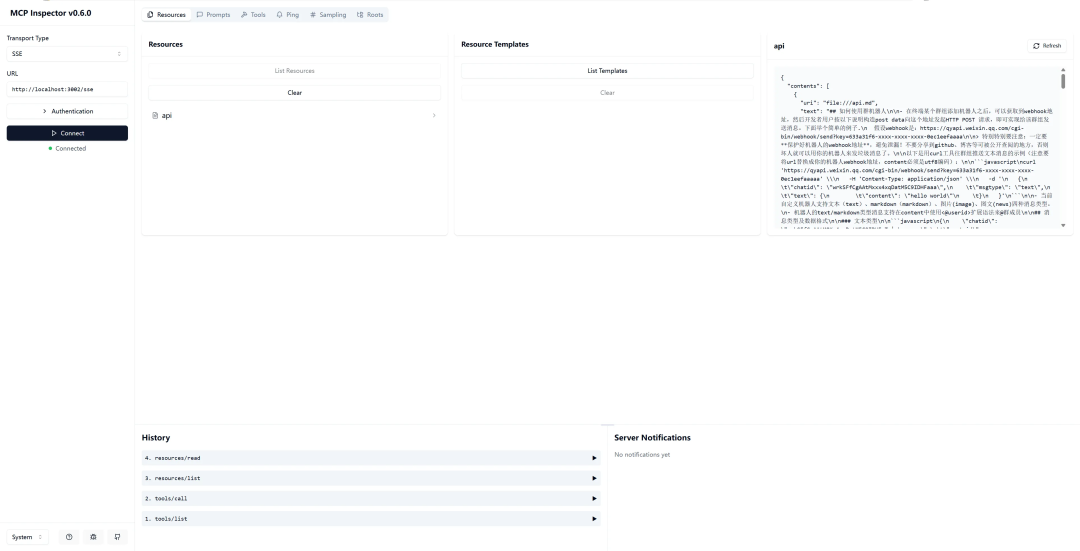
调试prompt

MCP Client 开发
MCP Client的主要任务是连接到MCP Server,可以通过标准输入/输出或 SSE (Server-Sent Events) 与 MCP 服务器进行通信。
3.1 实现步骤
初始化客户端和会话对象
class MCPClient: def __init__(self): # 初始化 session 和 client 对象 self.session: Optional[ClientSession] = None self._streams_context: Optional[sse_client] = None self._session_context: Optional[ClientSession] = None self.exit_stack = AsyncExitStack() # 初始化异步退出栈
连接到MCP服务
async def connect_to_sse_server(self, server_url: str): """连接到使用 SSE 传输的 MCP 服务器""" if not server_url.startswith(" http://" ) and not server_url.startswith(" https://" ): raise ValueError("服务器 URL 必须以 ' http://' 或 'https://' 开头")
# 存储上下文管理器以保持其存活 self._streams_context = sse_client(url=server_url) streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams) self.session: ClientSession = await self._session_context.__aenter__()
# 初始化 await self.session.initialize() async def connect_to_server(self, server_script_path: str): """ 连接到通过标准输入/输出通信的 MCP 服务器 参数: server_script_path: 服务器脚本路径(.py 或 .js 文件) 示例: "server.py" 或 "server.js" """ is_python = server_script_path.endswith('.py') is_js = server_script_path.endswith('.js') if not (is_python or is_js): raise ValueError("Server script must be a .py or .js file")
command = "python" if is_python else "node" server_params = StdioServerParameters( command=command, args=[server_script_path], env=None )
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params)) self.stdio, self.write = stdio_transport self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
有两种连接方式,分别是:
- stdio(标准输入输出通信)。
- HTTP with Server-Sent Events (SSE)(HTTP 服务端发送事件)。
清理资源
class MCPClient: def __init__(self): # 初始化 session 和 client 对象 self.session: Optional[ClientSession] = None
async def connect_to_sse_server(self, server_url: str): """连接到使用 SSE 传输的 MCP 服务器""" if not server_url.startswith(" http://" ) and not server_url.startswith(" https://" ): raise ValueError("服务器 URL 必须以 ' http://' 或 'https://' 开头")
# 存储上下文管理器以保持其存活 self._streams_context = sse_client(url=server_url) streams = await self._streams_context.__aenter__()
self._session_context = ClientSession(*streams) self.session: ClientSession = await self._session_context.__aenter__()
# 初始化 await self.session.initialize()
async def cleanup(self): """清理 session 和 streams""" if self._session_context: await self._session_context.__aexit__(None, None, None) if self._streams_context: await self._streams_context.__aexit__(None, None, None)
3.2 调用
async def main(): if len(sys.argv) < 2: print("用法: uv run client.py <SSE MCP 服务器的 URL (例如 " "=""> http://localhost:8080/sse)>" ) print("或: uv run client.py <MCP 服务器脚本路径 (例如 server.py)>") sys.exit(1)
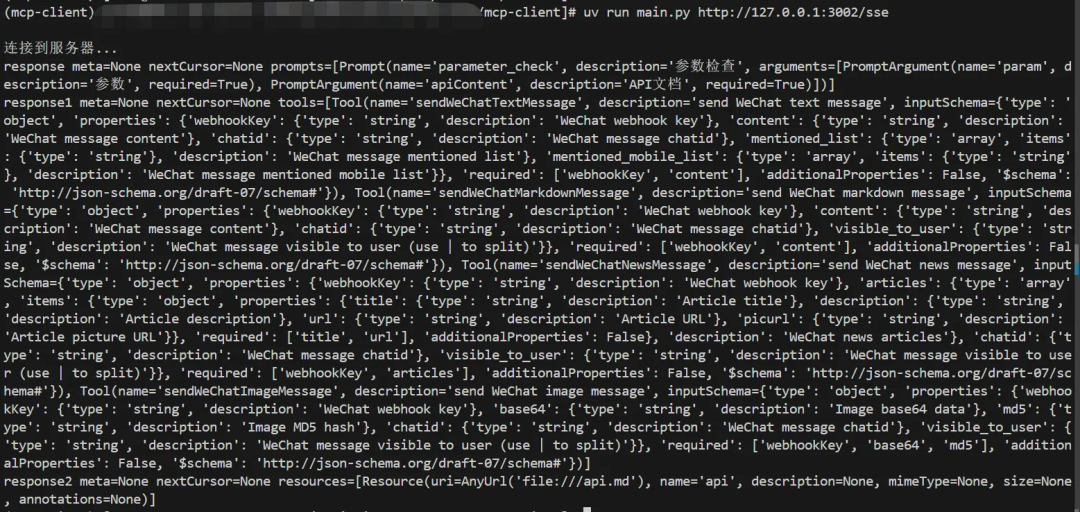
client = MCPClient() try: # stdio 连接方式 # await client.connect_to_server(server_script_path=sys.argv[1]) # sse 连接方式 await client.connect_to_sse_server(server_url=sys.argv[1]) print("\n连接到服务器...") response = await client.session.list_prompts() response1 = await client.session.list_tools() response2 = await client.session.list_resources() print("response", response) print("response1", response1) print("response2", response2)
finally: try: await client.cleanup() except Exception as e: print(f"清理错误: {e}")
MCP的工作原理
4.1 MCP架构
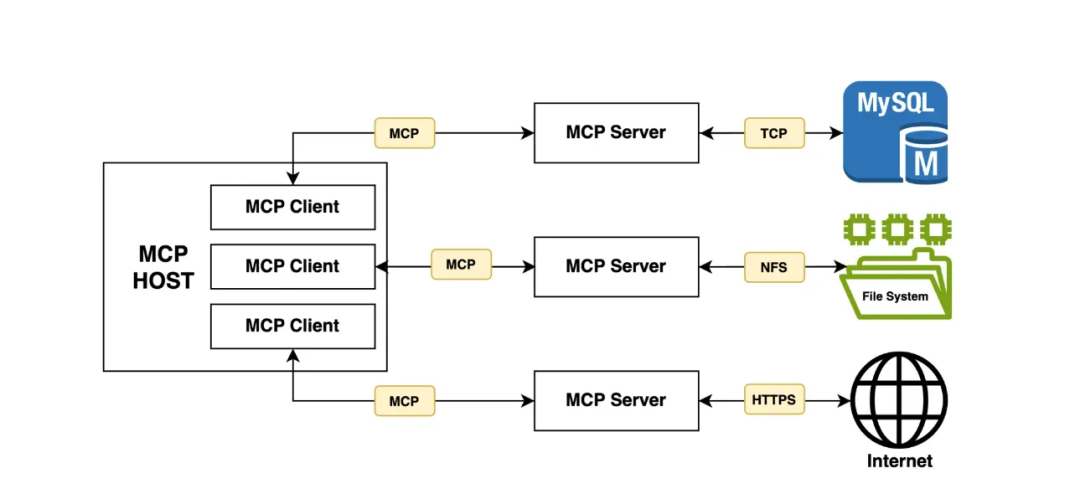
MCP采用的是C/S结构,一个MCP host应用可以链接多个MCP servers。
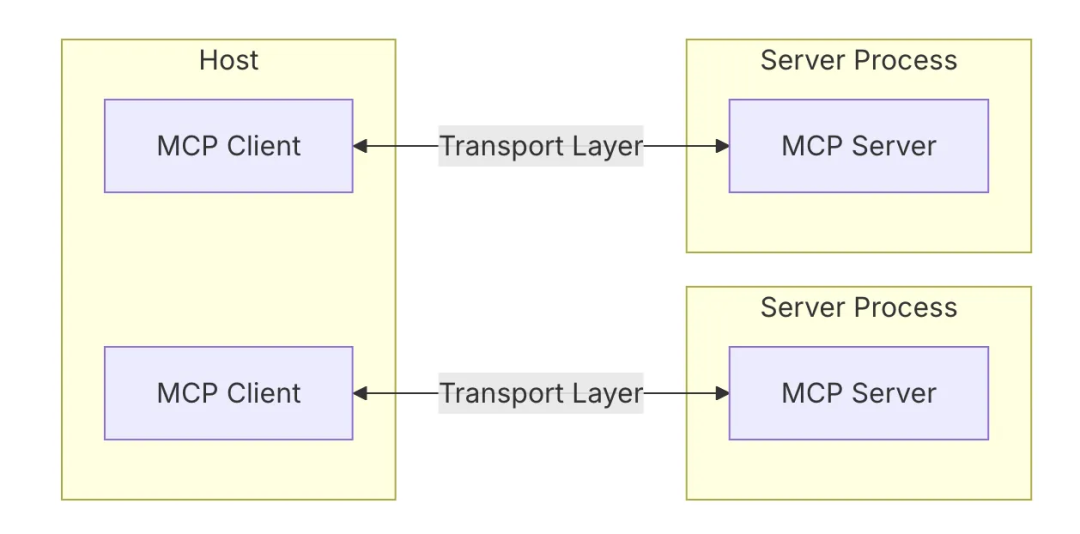
- Host(主机):例如cursor、cline,负责接收你的提问并与模型交互。
- Client(客户端):运行在Host内,mcp client 与 mcp server保持 1:1 连接,当用户在交互界面输入问题时,模型来决定使用1个或者多个工具,通过client来调用server执行具体操作。
- Server(服务):在这个例子中,文件系统 MCP Server 会被调用。它负责执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
4.2 json-rpc
在我们用inspector调试我们的mcp-server时,请求参数里会有jsonrpc字段,在mcp中 client 和 server 之间的传输均采用了JSON-RPC 2.0 来交换消息。
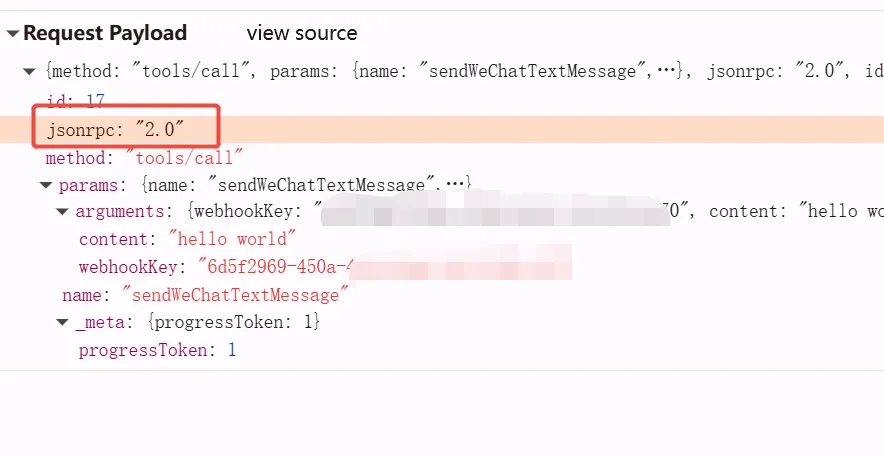
主要特点包括:
- 简单易用: 相比于其他 XML-RPC 协议,JSON-RPC 使用 JSON 格式更容易理解和处理,因为 JSON 是一种人类可读的文本格式,同时被多种编程语言广泛支持。
- 轻量级: JSON-RPC 没有复杂的格式和规则,是一种轻量级的协议,非常适合嵌入式系统和网络环境不理想的情况下使用。
- 无状态: JSON-RPC 是无状态的协议,每次请求都是独立的,不依赖于之前的通信。
- 语言中立: 不限于某一种编程语言,被各种编程语言广泛支持。
- 支持批处理: JSON-RPC 还支持批处理模式,即在一个请求中发送多个 RPC 调用,以提高效率。
4.3 模型如何选择工具
有了MCP Server 提供的众多工具,模型如何确定该使用哪些工具?
这里可以参考 官方 python-sdk 给的一个example示例:mcp_simple_chatbot(https://github.com/modelcontextprotocol/python-sdk/tree/main/examples/clients/simple-chatbot/mcp_simple_chatbot)
#... 省略了无关紧要的代码 async def start(self) -> None: """Main chat session handler.""" try: #... 省略了无关紧要的代码 all_tools = [] # 获取现在所有的工具列表 for server in self.servers: tools = await server.list_tools() all_tools.extend(tools)
tools_description = "\n".join([tool.format_for_llm() for tool in all_tools]) # 定义一个善于调用各种工具的助手prompt system_message = ( "You are a helpful assistant with access to these tools:\n\n" f"{tools_description}\n" "Choose the appropriate tool based on the user's question. " "If no tool is needed, reply directly.\n\n" "IMPORTANT: When you need to use a tool, you must ONLY respond with " "the exact JSON object format below, nothing else:\n" "{\n" ' "tool": "tool-name",\n' ' "arguments": {\n' ' "argument-name": "value"\n' " }\n" "}\n\n" "After receiving a tool's response:\n" "1. Transform the raw data into a natural, conversational response\n" "2. Keep responses concise but informative\n" "3. Focus on the most relevant information\n" "4. Use appropriate context from the user's question\n" "5. Avoid simply repeating the raw data\n\n" "Please use only the tools that are explicitly defined above." )
messages = [{"role": "system", "content": system_message}]
while True: try: user_input = input("You: ").strip().lower() #... 省略了无关紧要的代码 messages.append({"role": "user", "content": user_input}) #问模型我现在应该执行哪些工具 llm_response = self.llm_client.get_response(messages) # 执行工具 result = await self.process_llm_response(llm_response) #... 省略了无关紧要的代码 except KeyboardInterrupt: #... 省略了无关紧要的代码 finally: await self.cleanup_servers()
4.4 模型如何执行工具
async def process_llm_response(self, llm_response: str) -> str: """Process the LLM response and execute tools if needed.
Args: llm_response: The response from the LLM.
Returns: The result of tool execution or the original response. """ import json
try: tool_call = json.loads(llm_response) #如果有工具被选中,开始执行工具 if "tool" in tool_call and "arguments" in tool_call: logging.info(f"Executing tool: {tool_call['tool']}") logging.info(f"With arguments: {tool_call['arguments']}") #这里的server是通过mcp client 发现的 for server in self.servers: tools = await server.list_tools() if any(tool.name == tool_call["tool"] for tool in tools): try: # 执行工具 result = await server.execute_tool( tool_call["tool"], tool_call["arguments"] )
#... 省略了无关紧要的代码 return f"Tool execution result: {result}" except Exception as e: error_msg = f"Error executing tool: {str(e)}" logging.error(error_msg) return error_msg
return f"No server found with tool: {tool_call['tool']}" # 没有工具执行就直接输出模型的回答 return llm_response except json.JSONDecodeError: return llm_response
4.5 总结
Host应用(如Cursor)作为交互入口,通过内置的Client模块与多个专用Server建立一对一连接。当用户提问时,Host借助大模型分析请求并选择工具:首先获取所有Server注册的工具列表,通过结构化提示词引导模型生成JSON格式的调用指令,再通过JSON-RPC 2.0协议将指令路由到对应Server执行具体操作(如文件扫描)。执行结果经Host处理后转化为自然语言响应返回用户,实现模型决策与工具执行的解耦,通过轻量级通信协议完成分布式任务处理。
效果呈现
结合我们的mcp server 和 mcp client的示例,实现一个通过查询知识库数据后将结果通过企业微信机器人群聊内。
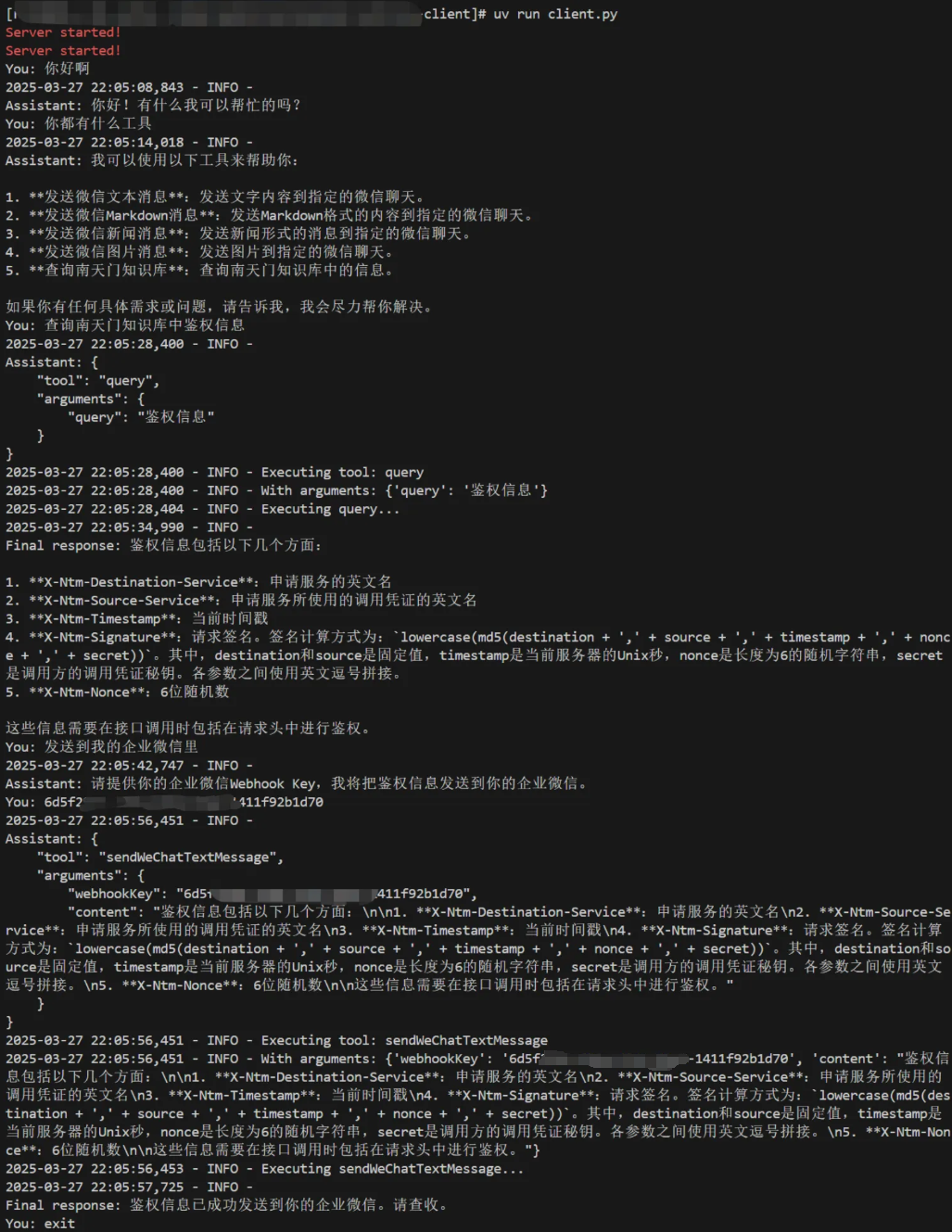

写在最后
这篇文章是记录自己在学习MCP过程中的一些感受和想法,可能存在疏漏和不准确的地方。如果有不对的地方,还请各位批评指正。同时,也欢迎大家一起交流讨论,共同探索MCP及其应用的更多可能性。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









