






随着LLM应用的不断成熟,特别是在B端企业场景中的逐渐落地,其不再停留在原型与验证阶段,将面临着更高的工程化要求,无论是输出的稳定性、性能、以及成本控制等,都需要实现真正的“生产就绪”;但由于大量的应用基于LangChain、LlamaIndex等框架开发,更多的抽象与封装使得应用难以跟踪与调试。因此,借助一个独立且侵入性较小的工程化平台来捕获LLM应用内部细节,帮助排障、优化与测试是很有必要的。
本文将手把手教你使用一个开源的LLM应用工程化平台:Langfuse,与在线且收费的LangSmith不同,它支持完全本地化部署与使用,与应用集成也很简单。

-
**快速本地化部署
** -
与LangChain应用集成
-
与普通LLM应用集成

PART 1
快速本地化部署

WHAT HAPPENED IN MAY
Langfuse是一个开源的LLM应用的工程平台,可以帮助开发者及团队进行集中、在线、协作的LLM应用跟踪调试、分析与测试评估。
-
**跟踪调试:**跟踪应用执行过程、上下文、LLM调用与成本、用户反馈等
-
**提示管理:**集中的Prompt模板创建、维护与版本管理
-
**监控分析:**调用统计、模型使用、tokens成本、响应延迟、评分统计等
-
**测试评估:**基于LLM与用户反馈的评估,包括质量、风格、内容安全

基于LLM的自动化评估目前在开源版本暂不支持,云端商业版本可以内测。


方法一:docker compose快速启动

适合个人开发者、对数据保存要求不高的开发团队。这种模式下会自动启动postgres的独立docker,只需三步:
#下载代码
git clone https://github.com/langfuse/langfuse.git
#进入代码目录
cd langfuse
#一键获取并启动docker容器
docker compose up

方法二:独立数据库 + docker run

适合有更高数据保存要求的开发团队,或者有现成的Postgres数据库。这种模式下,需要首先自行安装并启动postgres数据库,如果还没有Postgres,可进入官网(https://www.postgresql.org/),下载、安装并配置启动。记录下数据库的连接URL。然后执行以下命令:
#拉取最新镜像
docker pull langfuse/langfuse:latest
#注意替换这里的DATABASE_URL为你的postgres url
docker run --name langfuse \
-e DATABASE_URL=postgresql://hello \
-e NEXTAUTH_URL=http://localhost:3000 \
-e NEXTAUTH_SECRET=mysecret \
-e SALT=mysalt \
-p 3000:3000 \
-a STDOUT \
langfuse/langfuse
方法三:本地开发部署

除非你需要对Langfuse做个性化定制,或者使用Langfuse展开商业运营,否则不建议采用这种方式。具体请参考项目中CONTRIBUTING.md文件说明。
健康检查与测试

完成部署后,运行如下命令进行健康检查:
#健康测试,在本机运行
curl http://localhost:3000/api/public/health
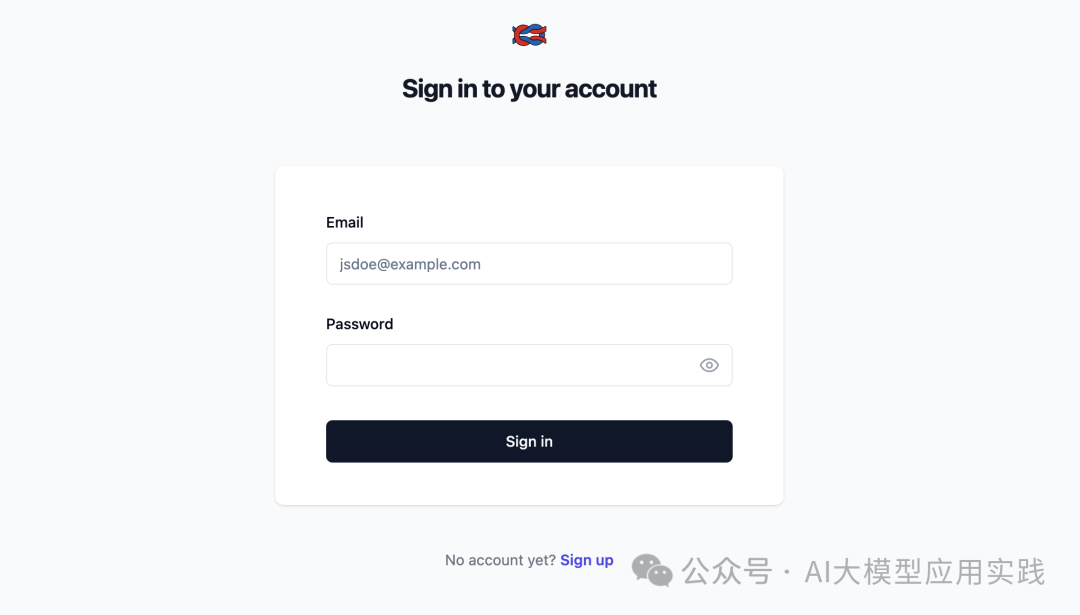
登录Langfuse UI使用

访问如下地址,登录langfuse的管理UI,出现登录界面就大功告成:
http://你的服务器地址:3000/
可能的问题

-
容器启动失败:检查网络是否连通;3000端口是否被占用;数据库是否正常
-
无法远程访问:检查安全端口是否放行;localhost修改为0.0.0.0试试
-
数据库无法连接:数据库端口是否放行;database_url是否有特殊字符
PART 2
与LangChain应用集成

WHAT HAPPENED IN MAY
平台已经就绪,现在需要让应用与Langfuse集成起来,以能够跟踪、评估与分析我们的应用。使用Langfuse的SDK/API,Langfuse能够与现有的任意应用做集成,但如果你的应用是基于LangChain、LlamaIndex这样的开发框架,那么使用起来会更加方便,这里先介绍与LangChain应用集成。
【准备工作】

在开始之前,首先登录到Langfuse UI,创建一个Project,然后在Settings中生成API Keys,参考下图**:**
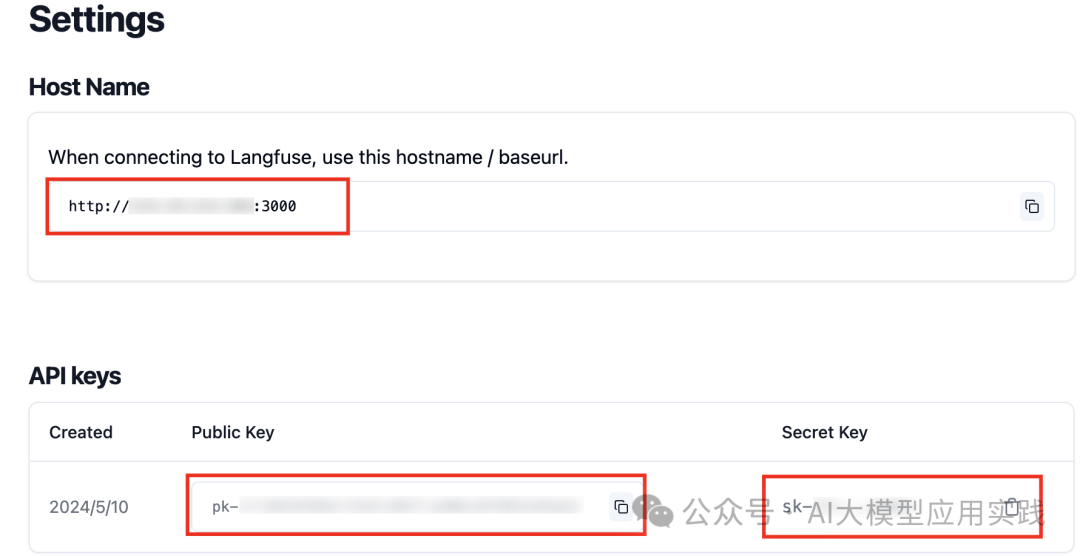
然后把图中三个参数设置到本地环境变量:
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-***"
os.environ["LANGFUSE_SECRET_KEY"] = "sk-***"
os.environ["LANGFUSE_HOST"] = "http://localhost:3000"
最后,安装Langfuse的SDK,以Python为例(也支持NodeJS):
pip install langfuse
【给应用增加Trace功能】

我们用Langchain构建了一个简单的RAG应用,使用了本地的Ollama模型和OpenAI的嵌入模型。现在只需要增加红色的三行代码即可:
...此处省略import必要的模块....
from langfuse.callback import CallbackHandler
langfuse\_handler = CallbackHandler(session\_id=str(uuid.uuid4()))
#模型
llm = Ollama(model="qwen:14b")
embed\_model = OpenAIEmbeddings(model="text-embedding-3-small")
#构建向量索引
documents = DirectoryLoader('./data/', glob="\*.txt",loader\_cls=TextLoader).load()
splits = RecursiveCharacterTextSplitter(chunk\_size=200, chunk\_overlap=0).split\_documents(documents)
db = FAISS.from\_documents(splits, embed\_model)
retriever = db.as\_retriever()
#prompt
prompt = ChatPromptTemplate.from\_template("基于如下上下文:\\n\\n{context}\\n\\n请回答以下问题:\\n\\n{question}")
#chain
rag\_chain = (
{"context": retriever | (lambda docs: "\\n\\n".join(doc.page\_content for doc in docs)), "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
#对话
while True:
user\_input = input("问题:")
if user\_input.lower() == "exit":
break
if user\_input.lower() == "":
continue
response = rag\_chain.invoke(user\_input,
config={"callbacks":\[langfuse\_handler\]})
print("AI:", response)
注意这里在每次运行时生成一个session_id,是用来将多次trace组织到一次session中(Langfuse跟踪的基本单位是Session->Trace->Observation,而调用LLM就是Observation的一种类型)。
现在我们来运行程序,做3次对话,然后回到Langfuse UI观察Tracing菜单下的跟踪记录,可以看到3条trace记录,且有相同的session_id:
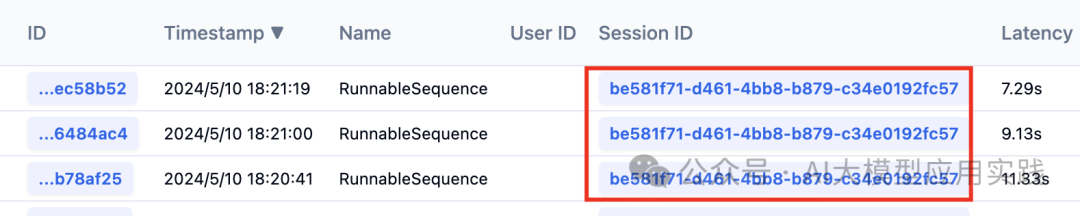
点击一条trace记录,就可以追踪到详细的RAG运行过程,从检索到组装的Prompt、LLM生成,多个步骤的关系以及输入输出、延时、model使用、tokens等:

由于使用了session来组织多个trace,我们可以在session菜单中查看这次session的完整会话过程:
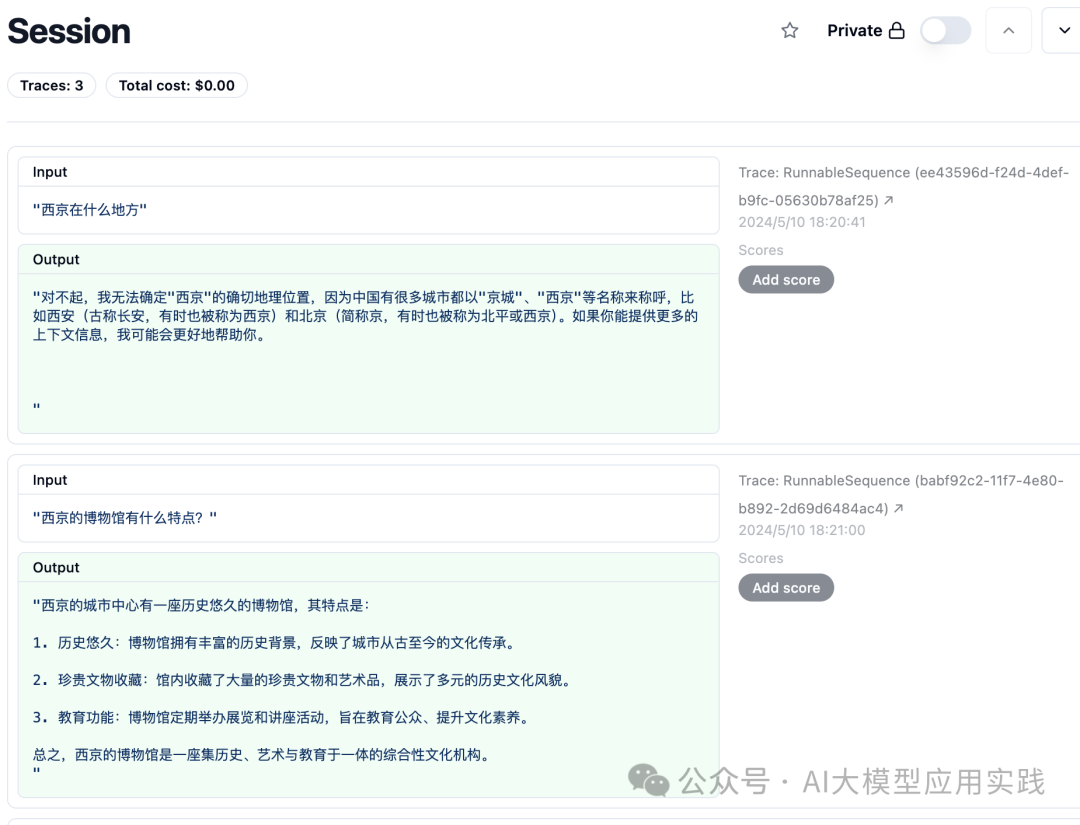
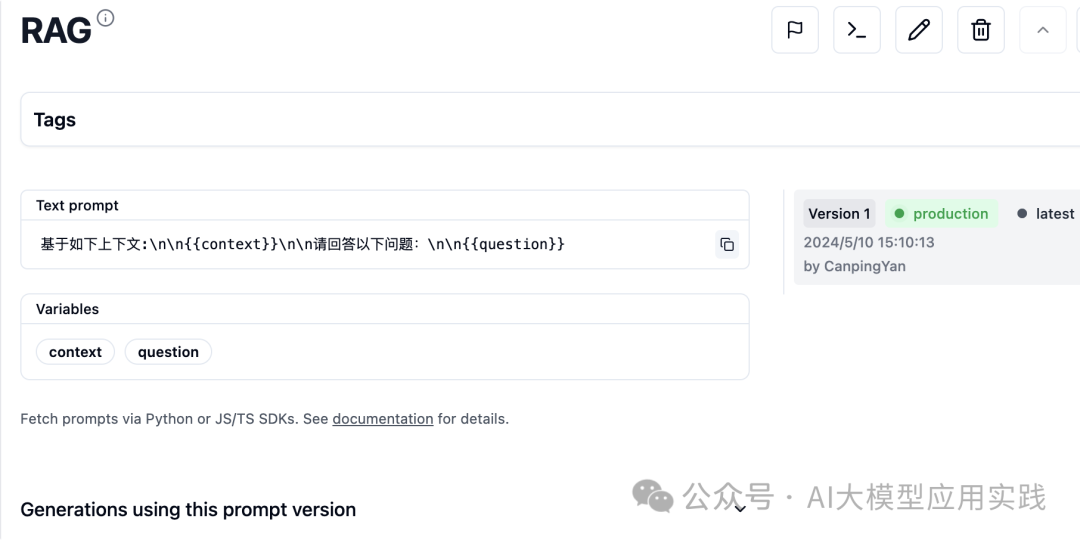
【使用Prompts管理功能】
如果在一个团队开发中,需要对所有的Prompt进行集中管理与维护,可以利用Langfuse的Pormpts管理功能。这里我们通过Langfuse UI的Prompts菜单新增一个RAG的简单提示模板:
现在可以在应用中使用这个模版,只需要把上述代码中的创建prompt的部分修改为用以下方式从Langfuse获取模板即可:
#prompt
from langfuse import Langfuse
langfuse=Langfuse()
prompt_str = langfuse.get_prompt("RAG").get_langchain_prompt()
prompt = PromptTemplate(template=prompt_str, input_variables=["context","question"])
Prompts管理支持设置变量、版本管理与标签,可实现灵活控制。

【使用评分功能】

为了对生产级的LLM应用做持续改进与优化,通过评分(score)来对应用输出质量作评估是有必要的。在Langfuse中支持多种评分途径:
-
在Langfuse UI中手工评分
-
在Langfuse UI中借助LLM做自动评估
-
通过SDK做自定义评分或搜集用户评分
这里的方式1应用场景有限,方式2目前仅在cloud版本中内测,因此这里介绍第3种,其最常见的场景是在应用端搜集用户反馈评分,然后上报Langfuse平台。为了实现评分上报,需要对上述代码中的invoke部分做如下改造:
from langfuse.decorators import langfuse_context, observe #测试代码 @observe() def invoke(query): langfuse_context.update_current_trace(session_id=session_id) langfuse_handler = langfuse_context.get_current_langchain_handler() response = chain.invoke(query,config={"callbacks":[langfuse_handler]}) ` `#此处模拟搜集到用户评分,如0.8 langfuse_context.score_current_trace( name="feedback-on-trace", value=0.8, comment="用户反馈", ) return response["result"]
这里把上述代码中的invoke包装成独立函数,然后增加observe()装饰器,以获得对trace控制的langfuse_context对象;再通过score_current_trace方法上报本次评分。成功后,用户的每次反馈评分都可以在LangfuseUI的scores菜单中看到,并且可以在dashboard看到相关统计指标,后续可以根据这些指标进行针对性优化:
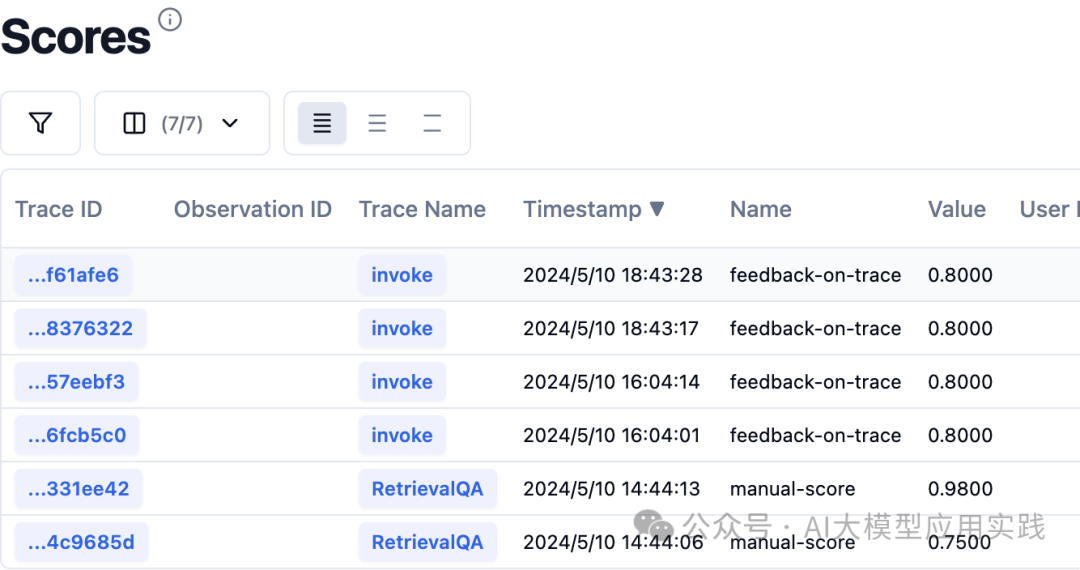
【分析仪表盘】

Langfuse的Dashboard默认展示很多有用的分析与统计指标,包括Trace的统计、模型成本分析、评分统计、不同类型环节的响应延迟等,非常适合用来帮助应用优化(为了能正确统计商业模型成本,注意在models菜单中做模型价格对齐):
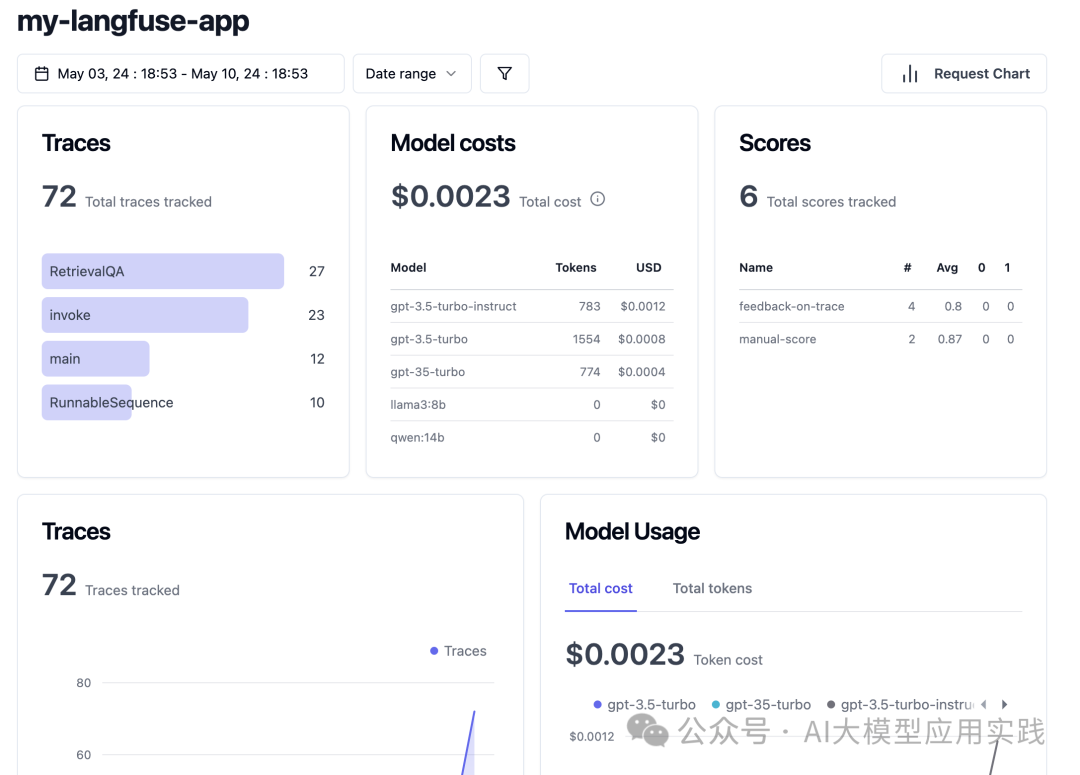
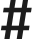
PART 3
与普通LLM应用的集成

WHAT HAPPENED IN MAY
除了Langchain框架以外,Langfuse还支持与另外一种常用框架LlamaIndex的快速集成。但如果你的应用直接基于大模型的SDK开发,并且有着较复杂的控制流程,也能采用Langfuse的低层SDK来实现集成。这里用一个简单的与本地Ollama模型对话的小应用来展示集成方式:
# ....省略import模块.... session_id = str(uuid.uuid4()) #LLM调用采用generation的type,不会产生新的trace,只会产生observation @observe(as_type="generation") def call_llm(query):` `response = ollama.chat(model='qwen:14b', messages=[ { 'role': 'user', 'content': query, }, ]) return response['message']['content']` `#这里不指定type,每次调用产生一个trace;不直接放llm调用逻辑是为了把LLM调用的observation分离``@observe() def invoke(query):` `#用session_id把多次trace组织起来 langfuse_context.update_current_trace( session_id=session_id) return call_llm(query) def main(): while True: user_input = input("问题:") if user_input.lower() == "exit": break if user_input.lower() == "": continue print("AI:", invoke(user_input))` `#结束前flush缓存,防止漏上报 langfuse_context.flush() main()
这里使用@observe装饰器来实现函数输入输出与LLM生成的跟踪,实际使用时,也可以使用langfuse.trace自行创建trace,并上报自定义的跟踪信息,虽然较为繁琐,但控制会更灵活。具体可以参考官方SDK文档。
【结束语】
整体使用下来Langfuse功能与LangSmith类似,但胜在开源可本地化部署,集成简单,且对应用性能影响很小(数据上报都是异步)。更多功能大家可自行部署并探索,有任何问题,欢迎关注与交流。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









