







近日,无问芯穹与上交、清华联合研究团队共同提出的视频生成大模型推理IP工作FlightVGM获得了国际可重构计算领域顶级会议 FPGA 2025最佳论文奖。这是FPGA会议首次将该奖项授予完全由中国大陆科研团队主导的研究工作,同时也是亚太国家团队首次获此殊荣。

这项工作首次在FPGA上实现了视频生成模型(Video Generation Models, VGMs)的高效推理,也是该团队继去年在FPGA上加速大语言模型FlightLLM(FPGA’24)后的最新系列工作。与NVIDIA 3090 GPU相比,FlightVGM 在AMD V80 FPGA上实现了1.30倍的性能提升与4.49倍的能效提升(峰值算力差距超过21倍)。

论文第一作者刘军是上海交通大学博士生,共同一作曾书霖是清华大学博士后,通讯作者是汪玉和戴国浩。汪玉是 IEEE Fellow、清华大学电子工程系教授、系主任和无问芯穹发起人,戴国浩是上海交通大学副教授、无问芯穹联合创始人兼首席科学家。
无问芯穹长期坚持软硬件协同优化技术路线以实现硬件效能的数量级提升,而非单纯依赖硬件工艺的缓慢迭代。2024年,无问芯穹的FlightLLM工作就曾作为全球首个文生文大模型推理IP被FPGA会议录用,实现推理性能和性价比的双重跃升。上个月,无问芯穹以视频生成模型稀疏化加速器ViDA拿下ASP-DAC’25最佳论文奖。ViDA通过稀疏化加速注意力计算,突破了VDiT(视频扩散Transformer)的计算瓶颈。而此次FlightVGM关注到视频生成模型参数量持续增长的趋势(从OpenSora的0.7B增长到混元Video的12.8B),针对线性层计算提出帧间帧内稀疏化和DSP定浮点混合精度拓展架构等技术,进一步实现全球首个文生视频大模型推理IP,在FPGA上实现性能与能效超越GPU。
这一系列工作,是无问芯穹坚定行走在软硬件协同优化路线上的一步一脚印。大模型部署成本的核心制约在于运行效率,该指标由算法、软件及硬件效率共同决定。在算法与软件迭代速率边际递减的产业背景下,硬件效能突破将成为降低模型推理成本的重要“胜负手”。现包括FlightVGM在内,系列研究成果已被集成到无问芯穹自研大模型推理IP LPU(Large-model Processing Unit)之中,并已与合作伙伴开展合作验证。
下面是论文的核心内容解读,与各位读者共同饕览.
详细内容请参见论文原文:https://dl.acm.org/doi/10.1145/3706628.3708864
01
论文背景
在视频生成领域,扩散 Transformer(DiT)逐渐成为一种重要的框架。DiT 模型通过一个扩散过程生成视频,它将噪声图像逐步恢复为清晰的视频帧,从而展现了强大的生成能力。最初,DiT 被提出是为了探索在大规模数据处理中的可扩展性,随着技术的不断发展,DiT 的架构也不断被优化,逐步提高了生成视频的质量和分辨率,使得生成的视频更加清晰、精细。尽管如此,这种方法的计算需求非常高,尤其是在生成高分辨率和较长时长的视频时,所需的计算量和内存消耗大幅增加,因此如何提升生成效率并优化计算过程,成为该领域的关键问题之一。
02
核心见解:从视频压缩到视频生成
视频压缩技术(如 H.264、H.265)通过离散余弦变换(DCT)等技术,识别并消除视频帧间和帧内的冗余信息,从而实现高达 1000 倍的压缩率。这一思想的核心在于,视频数据在时间和空间维度上存在大量重复模式,例如相邻帧之间的背景几乎不变,或同一帧内的纹理具有高度相似性。通过检测并跳过这些冗余信息,压缩算法能够显著减少数据量,同时保持视频质量。
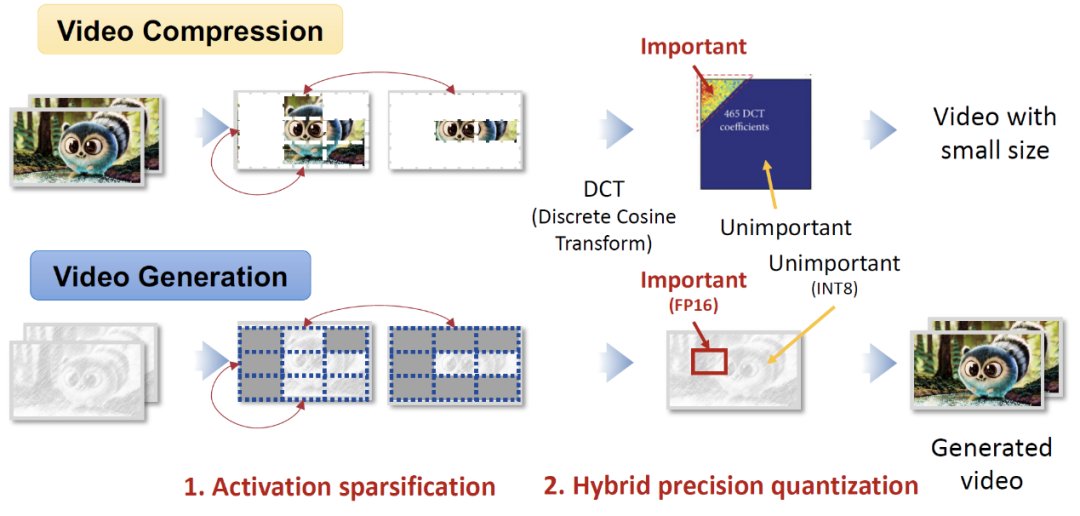
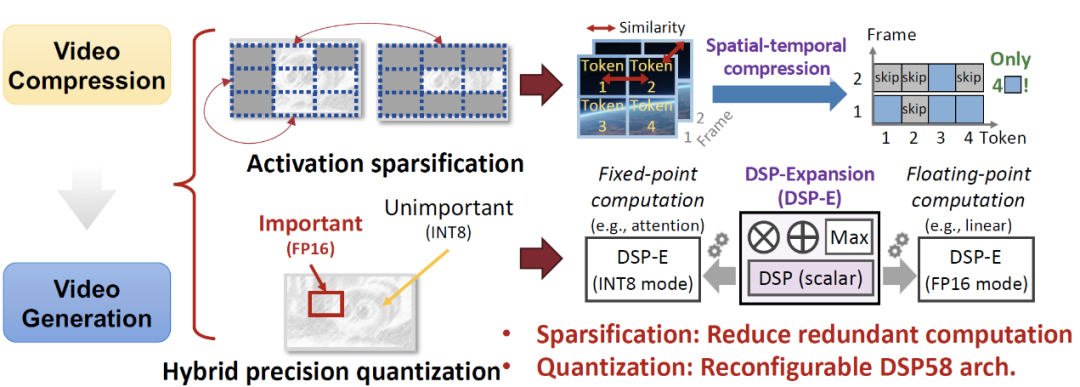
FlightVGM 创新性地将这一思想引入视频生成模型的加速中。视频生成模型(VGMs)在推理过程中同样表现出显著的时空冗余性。例如,相邻帧之间的 Token 在语义上高度相似,而同一帧内的不同区域也可能共享相同的视觉特征。然而,现有 GPU 架构无法充分利用这种冗余性。FPGA 虽然具备稀疏计算的优势,但其峰值算力远低于 GPU,且其计算单元(例如 V80 的 DSP58)的传统设计无法动态适配混合精度需求,限制了其在视频生成加速中的应用。FlightVGM 通过以下三项技术,解决上述挑战:
1.“时间 - 空间” 激活值在线稀疏化方法:基于视频压缩中的相似性检测思想,FlightVGM 设计了帧间和帧内的冗余激活稀疏机制。通过余弦相似度计算,动态跳过相似部分计算,显著降低了计算负载。
2.“浮点 - 定点” 混合精度 DSP58 拓展架构:借鉴视频压缩中的分块处理思想,FlightVGM 对视频生成模型的不同模块进行精度分层处理。关键模块(如注意力机制)保留 FP16 精度,非关键模块(如线性层)量化至 INT8,最大化硬件利用率。
3.“动态 - 静态” 自适应调度策略:针对激活值在线稀疏化导致的负载不均衡问题,FlightVGM 针对实际工作负载自适应调整不同操作负载的执行顺序,从而提高计算利用率。
03
技术要点
“时间 - 空间” 激活值在线稀疏方法
我们提出了一种 “时间 - 空间” 激活值在线稀疏化方法,同时考虑了帧间和帧内的相似性。激活稀疏化的核心思想是:如果两个 token 之间具有高度相似性,则可以只计算其中一个 token,并将结果共享给另一个 token。具体来说,输入激活是一个 3 维张量,由 tokenizer 从噪声视频中处理得到。因此,输入激活可以表示为![]() ,其中 F 表示帧数,T 表示每帧的 token 数,d 表示隐藏维度。为了简便起见,我们用 (
,其中 F 表示帧数,T 表示每帧的 token 数,d 表示隐藏维度。为了简便起见,我们用 (![]() ) 来表示第 1 帧的第 1 个 token。对于输入激活
) 来表示第 1 帧的第 1 个 token。对于输入激活![]() ,我们使用
,我们使用![]() 和
和![]() 来表示参考向量和输入向量。我们使用余弦相似度作为度量标准。
来表示参考向量和输入向量。我们使用余弦相似度作为度量标准。
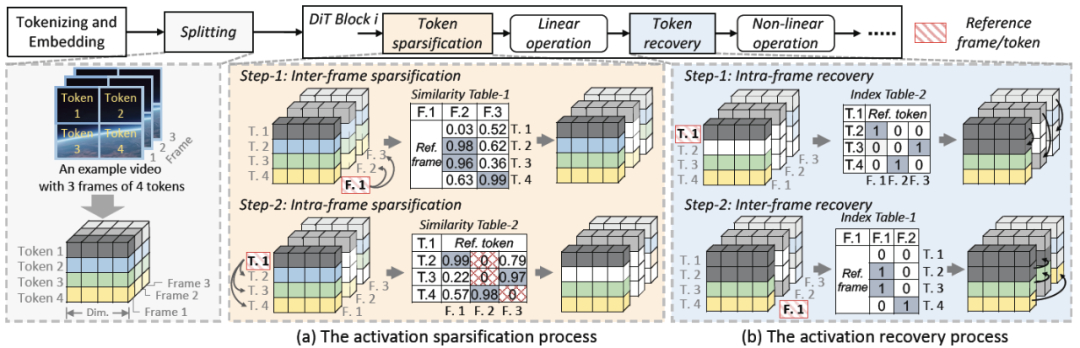
激活稀疏化包含两个步骤:帧间稀疏化和帧内稀疏化。
1. 帧间稀疏化:我们将输入激活分为 G 个连续的组,并选择中间帧作为参考帧。剩余帧的 token 与参考帧的 token 逐一计算相似度,若超过阈值,则使用参考帧的 token 计算结果替代当前 token。
2. 帧内稀疏化:我们将每帧的 token 分为 K 个块,选择中间 token 作为参考 token,计算其他 token 与参考 token 的相似度,若超过阈值则用参考 token 替代计算。如果某 token 已在帧间稀疏化中被裁剪,其相似度为 0。
从计算角度来看,相似度计算需要进行一次内积和两次模长计算,因此其计算量为 3d,其中 d 为隐藏维度。以一个线性操作为例,假设输入激活![]() 的大小为
的大小为![]() ,权重矩阵 W 的大小为
,权重矩阵 W 的大小为![]() ,则原始操作的计算量为
,则原始操作的计算量为![]() 。对于稀疏操作,考虑帧间和帧内稀疏化带来的额外计算,假设稀疏度为 s,则稀疏操作的总计算量为:
。对于稀疏操作,考虑帧间和帧内稀疏化带来的额外计算,假设稀疏度为 s,则稀疏操作的总计算量为:
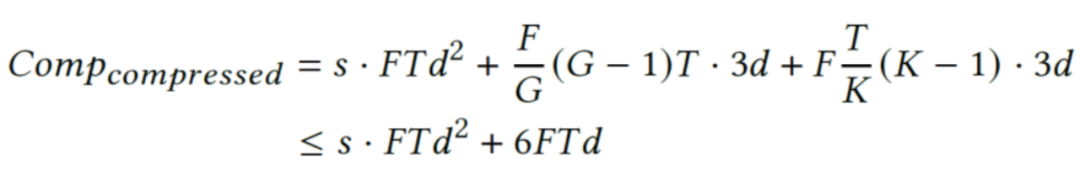
由于原始计算量包含了 d 的二次项,而稀疏化带来的额外计算只是 d 的线性项(典型值 d=1152),因此稀疏化引入的额外开销几乎可以忽略不计。
“浮点 - 定点” 混合精度 DSP58 拓展架构
AMD V80 FPGA 配备了硬件 IP DSP58,支持多种计算模式,如标量、向量和浮点配置。然而,由于这些配置之间无法在运行时进行动态切换,这与视频生成模型对数据的混合精度的需求存在冲突,导致我们无法充分利用 DSP58 的计算潜力。
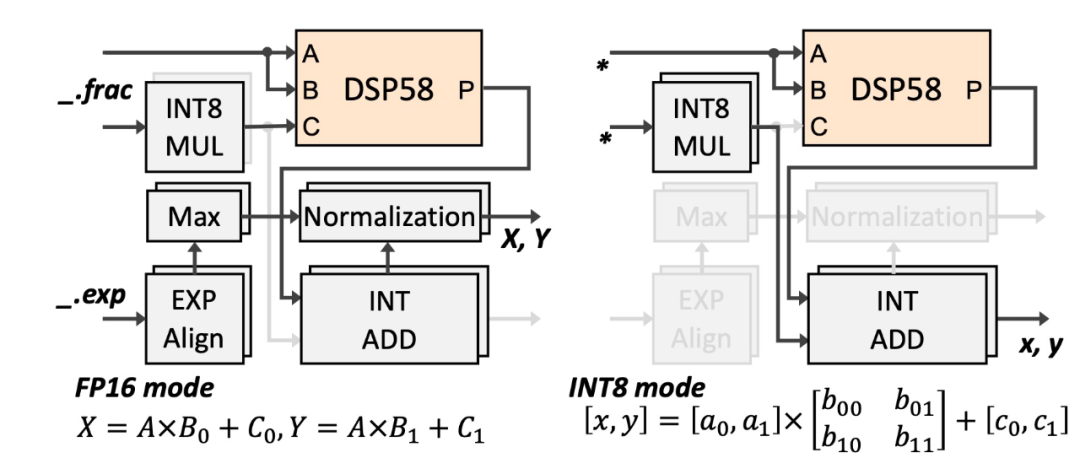
为了解决这一问题,我们提出了基于 DSP58 的创新性 FP16-INT8 混合精度硬件架构 ——DSP-Expansion (DSP-E)。该架构允许在运行时配置,支持两个 FP16 乘加单元(MAC)或四个 INT8 乘加单元。我们的核心思路是通过引入额外的乘法器来解决当一个 DSP58 执行两个 FP16 分数乘法时的数据混淆问题,这些乘法器在 INT8 模式下也可以复用。在 FP16 模式下,DSP58 执行两个 MAC 的分数乘法,并通过减去 INT8 乘法器的结果来获得正确的中间计算结果。中间结果的指数部分通过 INT 加法器计算,并通过指数对齐和调整单元对齐小数点位置,最终通过加法、归一化和四舍五入得到最终结果。在 INT8 模式下,DSP-E 通过复用 DSP58、两个 INT8 乘法器和两个 INT 加法器,最大化计算性能。通过将相关数据输入到不同的端口,额外的逻辑单元可以复用硬件资源,从而有效地提高了计算吞吐量。
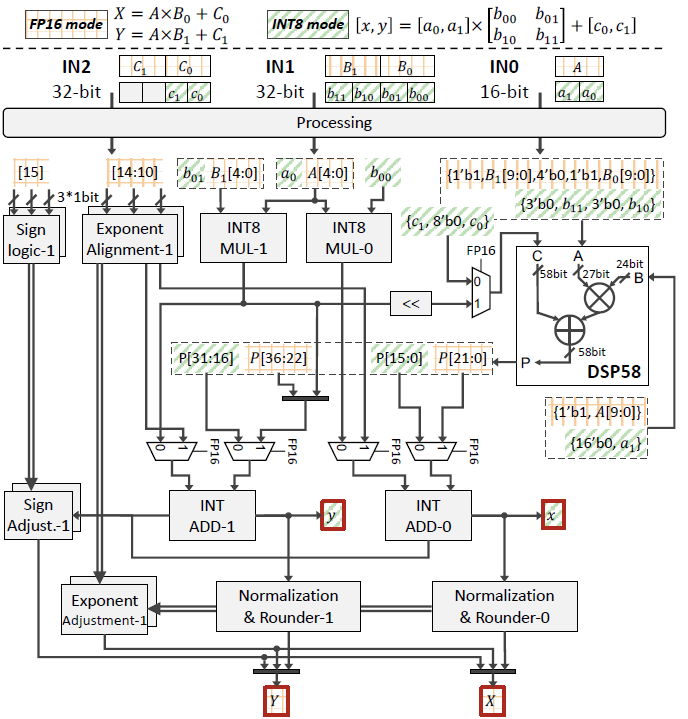
为了在计算精度和硬件资源的约束下实现最大吞吐量,我们提出了一个异构的 DSP58 阵列设计,以适应不同的计算需求。我们根据不同设计的资源消耗(包括 DSP、LUT、REG、RAM 等)进行评估,并通过资源约束来确保最优计算性能。此外,我们还考虑了 INT8 与 FP16 计算性能的比值,以衡量计算能力的提升。
04
实验结果
算法评估
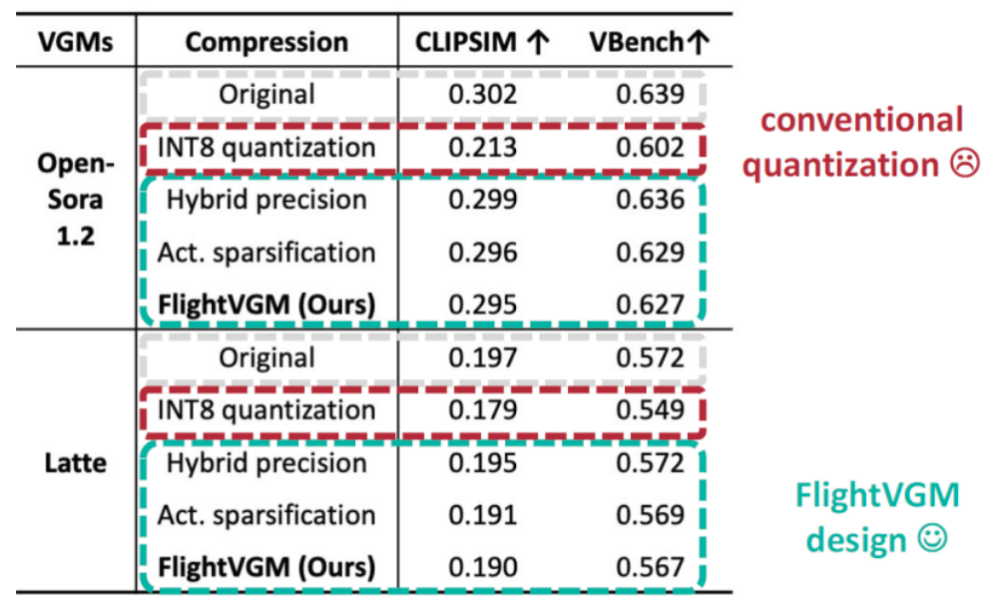
与基准模型相比,FlightVGM 对于模型精度的影响几乎可以忽略(仅平均损失为 0.008),而使用全 INT8 量化时,平均损失为 0.042。同时,在实际视频生成效果上,FlightVGM 生成的视频与原始模型仍有较好的保持。
性能评估
对于 NVIDIA 3090 GPU,在 FP16 精度下,AMD V80 FPGA 的峰值算力差距超过了 21 倍。然而,基于 V80 FPGA 实现的 FlightVGM 仍在性能和能效上超过了 GPU。这是因为 FlightVGM 充分利用了 VGM 固有的稀疏相似性和混合精度数据分布特性,并通过软硬件协同开辟了 “算法 - 软件 - 硬件” 的全新优化空间并成功在其中找到了一个足够好的解。而 GPU 由于硬件架构的限制,难以达到相同的加速效果,且缺乏稀疏化和定制化计算数据流优化的支持。

05
展望和未来工作
随着 VGM 计算需求的增长,FlightVGM 展示了如何通过 FPGA 的软硬件协同创新,实现更高能效的文生视频大模型推理。未来,通过探索 AIE(AI Engine)+ HBM(High Bandwidth Memory)的全新 FPGA 架构,FPGA 有望为视频生成任务提供更高效的计算支持,成为未来计算平台的重要选择。

















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









