






本文基于A method of dense point cloud SLAM based on improved YOLOV8 and fused with ORB-SLAM3 to cope with dynamic environments文章总结
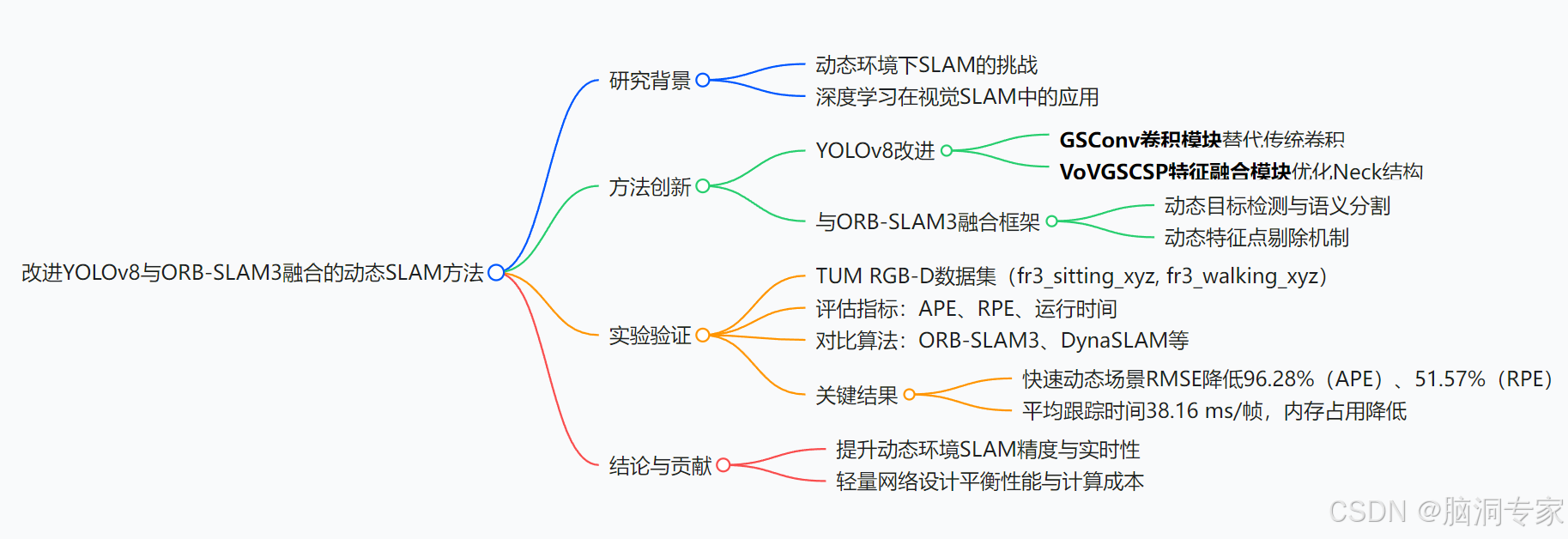
文章提出了一种基于改进 YOLOv8 与 ORB-SLAM3 融合的动态环境稠密点云 SLAM 方法,通过引入GSConv 卷积模块和VoVGSCSP 特征融合模块优化 YOLOv8 的轻量性,结合实时目标检测与语义分割技术去除动态特征点,显著提升了动态场景下的位姿估计精度。实验表明,在 TUM 数据集的快速动态场景中,该方法的绝对位姿误差(RMSE)较 ORB-SLAM3 降低96.28%,相对位姿误差(RMSE)降低51.57%,且运行时间仅为38.16 ms / 帧,实现了高效鲁棒的 SLAM 性能。
-
研究背景
智能机器人的发展依赖于 SLAM 技术,但传统视觉 SLAM 在动态环境中存在定位和建图误差大的问题。深度学习的引入为解决动态环境鲁棒性问题提供了新途径,但现有方法存在模型复杂、实时性不足的挑战。 -
提出方法
- 改进 YOLOv8:
- 引入 GSConv 卷积模块,平衡模型精度与计算负载。
- 采用 VoVGSCSP 特征融合模块优化 Neck 结构,实现轻量化。
- 融合 ORB-SLAM3:
将改进的 YOLOv8 实时目标检测与语义分割能力整合到 ORB-SLAM3 框架中,动态环境下过滤动态特征点,提升定位与建图精度。
- 改进 YOLOv8:
-
实验验证
- 数据集:使用 TUM RGB-D 数据集的动态序列(fr3_sitting_xyz 和 fr3_walking_xyz)。
- 指标:比较绝对位姿误差(APE)和相对位姿误差(RPE)。
- 结果:
- 在快速动态环境中,APE 的 RMSE 比 ORB-SLAM3 降低 96.28%,RPE 的 RMSE 降低 51.57%。
- 运行时间和资源占用优化显著,平均跟踪时间 38.16ms / 帧,分割时间 19.10ms / 帧。
-
创新点
- 首次将改进的 YOLOv8 与 ORB-SLAM3 结合,实现动态环境下的高精度 SLAM。
- 通过模块优化(GSConv 和 VoVGSCSP)实现模型轻量化,平衡性能与效率。
- 提出密集点云建图方法,提升环境描述的直观性。
-
结论
该方法在动态环境中显著优于传统 SLAM 算法,尤其在快速运动场景中表现突出,为智能机器人在复杂环境中的应用提供了有效解决方案。
1. GSConv 技术是什么?
GSConv(Group Shuffle Convolution,分组混洗卷积)是一种改进的卷积方法,旨在平衡模型精度与计算效率。其核心思想是将标准卷积(SC)与深度可分离卷积(DSC)结合,通过分组和通道重组优化特征提取过程。
技术细节:
- 结构:
- 标准卷积(SC):对输入特征图进行常规卷积,生成中间特征(通道数为原通道的一半)。
- 深度可分离卷积(DSC):对 SC 输出的每个通道独立进行卷积,减少计算量。
- 混洗模块(Shuffle):将 SC 和 DSC 的输出按通道拼接后重新排列,增强特征交互。
作用:
- 轻量化:通过 DSC 减少参数和计算量,适合实时性要求高的场景(如 SLAM)。
- 保留精度:SC 部分保留通道间的相关性,避免 DSC 导致的特征丢失。
- 平衡性能:在 YOLOv8 中替换部分传统卷积层,减少模型复杂度但维持检测精度。
2. Backbone 层和 Neck 层是什么?
Backbone 层:
- 定义: 模型的主干网络,负责从输入图像中提取多尺度特征(如浅层的边缘、纹理,深层的语义信息)。
- YOLOv8 中的 Backbone: 基于 CSPDarknet,包含多个卷积层和残差模块,通过下采样逐步压缩空间尺寸、扩展通道数。
- 改进点: 在 Backbone 的部分阶段引入 GSConv,替代传统卷积层,减少计算量同时保留特征表达能力。
Neck 层:
- 定义: 位于 Backbone 和 Head 之间,通过特征融合优化多尺度检测性能。
- YOLOv8 中的 Neck: 原结构为 C2f 模块(Cross Stage Partial Network),通过横向连接和通道拆分增强特征多样性。
- 改进点: 提出VoVGSCSP 模块,用 GSConv 替代部分 C2f 中的卷积层,进一步降低计算复杂度,同时通过 E-ELAN(高效通道注意力)抑制冗余背景特征。
3. 为何调整这些结构能提升动态环境 SLAM 性能?
- GSConv 的作用:
- 减少 YOLOv8 的模型参数量和计算耗时,使其更适合实时性要求高的 SLAM 系统。
- 保留关键特征(如动态物体的轮廓和运动模式),确保分割精度,避免误删静态特征点。
- Backbone 和 Neck 的改进:
- 轻量化:通过结构优化降低模型体积,减少 GPU 内存占用(如文中 YOLOv8 分割时间仅 19.10ms / 帧)。
- 增强动态特征感知:GSConv 和 VoVGSCSP 模块更关注动态物体的语义和几何特征,提升分割准确性。
- 平衡精度与速度: 保留部分传统卷积层(如在 Backbone 的关键阶段),避免因过度轻量化导致检测性能下降,确保 SLAM 的位姿估计精度(如快速动态环境中 APE 降低 96.28%)。
总结
GSConv 通过融合标准卷积与深度可分离卷积,在轻量化和精度间取得平衡;Backbone 和 Neck 的改进则通过结构优化进一步提升模型效率和动态特征处理能力。这些技术共同解决了传统视觉 SLAM 在动态环境下的实时性与精度矛盾,为复杂场景中的机器人导航提供了更可靠的解决方案。
需要注意的是该方法的动态特征点剔除是基于YOLOv8 的目标检测框而非语义分割的精细区域。具体实现逻辑如下:
1. 剔除策略的核心依据
-
YOLOv8 的目标检测框: 文档明确指出,改进的 YOLOv8 框架通过目标检测生成动态物体的边界框(Bounding Box),并基于此框判断特征点是否属于动态区域
-
未采用语义分割掩码: 尽管 YOLOv8 具备实例分割能力,但文档中未提及使用分割掩码(Mask)进行特征点筛选。推测原因是分割掩码的计算量较大,而检测框方法更高效,符合实时性需求。
2. 检测框剔除的局限性
- 误删静态特征点: 检测框可能包含动态物体周围的静态区域(如人物手持的静态物品),导致部分静态特征点被错误剔除。
- 精度损失: 与基于分割掩码的方法相比,检测框方法的位姿误差略高,但速度优势显著。
3. 平衡实时性与精度的设计
- 轻量化优先: 文档强调通过 GSConv 和 VoVGSCSP 模块优化 YOLOv8 的推理速度(段落 1-56 至 1-61),确保检测框处理时间仅 19.10ms / 帧,满足 SLAM 实时性要求。
- 动态场景适应性: 检测框方法在快速动态环境中仍能有效降低位姿误差(如 APE 的 RMSE 比 ORB-SLAM3 降低 96.28%),证明其对动态干扰的鲁棒性。
结论
该方法采用目标检测框进行动态特征点剔除,而非语义分割的精细区域。这一设计在实时性与精度间取得平衡,通过牺牲少量静态特征点保留率,确保了 SLAM 系统在动态环境中的实时运行能力。若需更高精度,可结合分割掩码,但需权衡计算成本。

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









