






持续学习全新突破,登顶Nature正刊!作者发现,标准深度学习方法在连续学习中,效果甚至不如浅层网络。因而提出持续反向传播算法,通过不断向网络中注入多样性来维持可塑性。
实际上,持续学习已然是当下AI领域的新热门!现实世界中的数据和环境是不断变化的。深度学习模型需要能够适应这些变化,而持续学习正是实现这一目标的关键。但其也面临灾难性遗忘、泛化性差、计算资源要求高等问题,对其的研究成为迫切需求。
目前CVPR、NeurIps、ACM等顶会也都涌现了不少成果!像是参数直降60%的高效持续学习框架MOE-Adapters4CL;在自监督任务中性能提升30.44%的HiDe-Prompt……
为了让大家能快速掌握该方向的主流研究方法,早点发出自己的顶会。我给大家准备了12种创新思路,原文和源码都有!
论文原文+开源代码需要的同学看文末
论文:[Nature正刊]Loss of plastisity in deep continual learning
内容
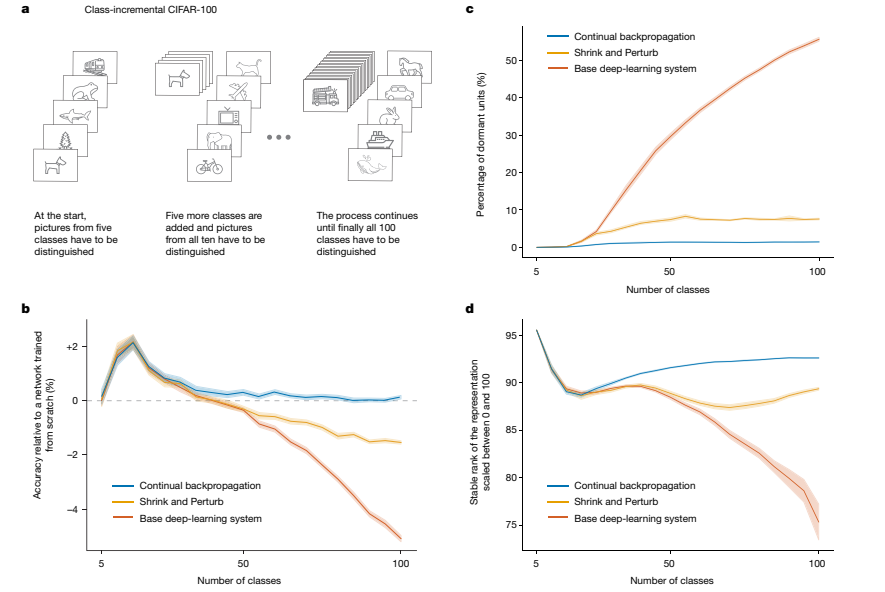
该论文探讨了深度连续学习中塑料性丧失的问题,即深度学习方法在连续学习新任务时逐渐失去学习能力。标准的深度学习方法在连续学习环境中会逐渐失去塑料性,直到它们的性能不再优于浅层网络。通过在ImageNet数据集和强化学习问题上的实验,他们展示了这种塑料性的丧失,并提出了一种名为“持续反向传播”的算法,该算法通过不断向网络中注入多样性来维持塑料性。
论文:Interactive Continual Learning: Fast and Slow Thinking
内容
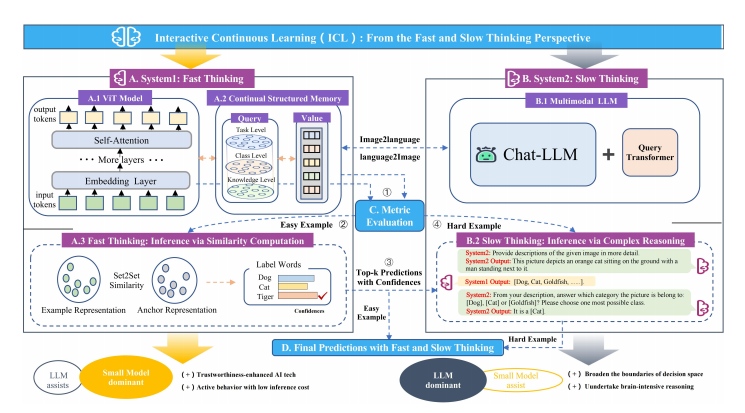
该论文介绍了一种名为交互式持续学习(ICL)的新型框架,该框架受神经认知科学中的互补学习系统理论启发,通过不同大小模型之间的协作交互来实现。ICL框架将ViT模型作为系统1,多模态大型语言模型(LLM)作为系统2,通过提出类知识任务多头注意力(CKT-MHA)模块和基于von Mises-Fisher分布的CL-vMF机制来增强记忆检索和几何表示,同时引入vMF-ODI策略来识别难样本,从而在系统1和系统2之间实现复杂推理的协作。
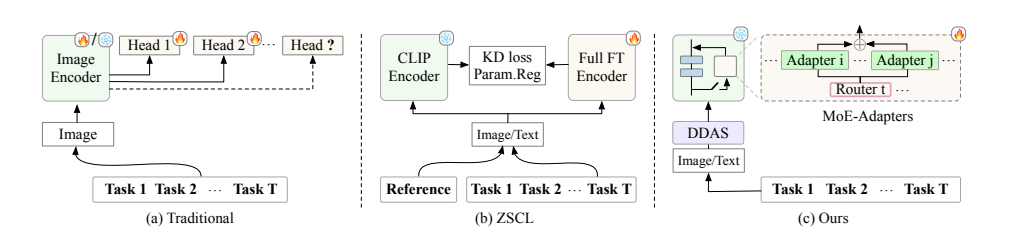
论文:Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters
内容
该论文提出了一个参数高效的持续学习框架,通过在预训练的CLIP模型上动态扩展Mixture-of-Experts(MoE)适配器来增强视觉-语言模型在增量学习中的适应性和效率,并引入了分布判别自动选择器(DDAS)来自动路由输入数据,以保持模型的零样本识别能力。
论文:RanPAC: Random Projections and Pre-trained Models for Continual Learning
内容
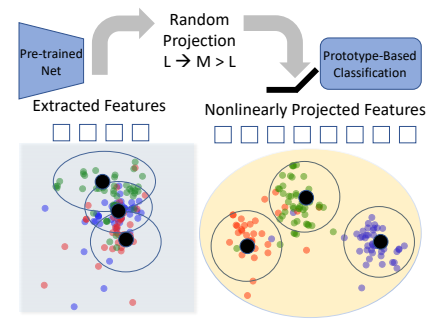
该论文介绍了一种名为RanPAC的持续学习方法,该方法通过在预训练模型(如ViT-B/16)的基础上动态扩展混合专家(MoE)适配器来增强视觉-语言模型在增量学习中的适应性和效率。RanPAC框架包括一个无需训练的随机投影层和类原型积累,旨在解决灾难性遗忘问题,同时保持对新任务的适应能力和对未见数据的零样本识别能力。
关注下方《人工智能学起来》
回复“12持续”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏

















 929
929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









