






想发高区论文,却头疼找不到创新点?那你不要错过这个顶会新热门:Mamba+Transformer!
它为提升模型在处理长序列数据时的效率和性能,提供了全新的解决方案。不仅克服了单一模型的局限性,还显著提高了计算效率和模型性能。比如代表模型Jamba,吞吐量是传统Transformer的3倍,且是同等参数规模中,唯一能够在单个GPU上容纳高达140K上下文的模型。此外,Mamba作为新技术,当下还在上升期,不像传统领域那样卷生卷死,把其与各种常规任务结合,便又是新的机会!
为了方便大家紧跟领域前沿,实现快速涨点,我给大家准备了14篇必读的高分论文,原文和源码都有,一起来看!
论文原文+开源代码需要的同学看文末
论文:looongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
内容
该论文介绍了一个名为LongLLaVA的新型混合架构多模态大型语言模型(MLLM),它专门针对视频理解和高分辨率图像理解等长文本情境进行了优化。LongLLaVA模型结合了Mamba和Transformer结构,采用高效的图像表示方法,并通过渐进式训练策略来处理多模态长文本。
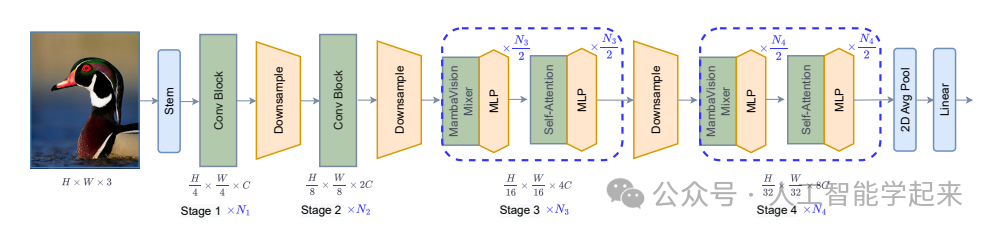
论文:MambaVision: A Hybrid Mamba-Transformer Vision Backbone
内容
该论文介绍了一种名为MambaVision的新型混合Mamba-Transformer视觉骨干网络,专门为视觉应用设计。研究者通过重新设计Mamba模型以增强其对视觉特征的高效建模能力,并进行了关于将视觉Transformer(ViT)与Mamba集成的全面消融研究。
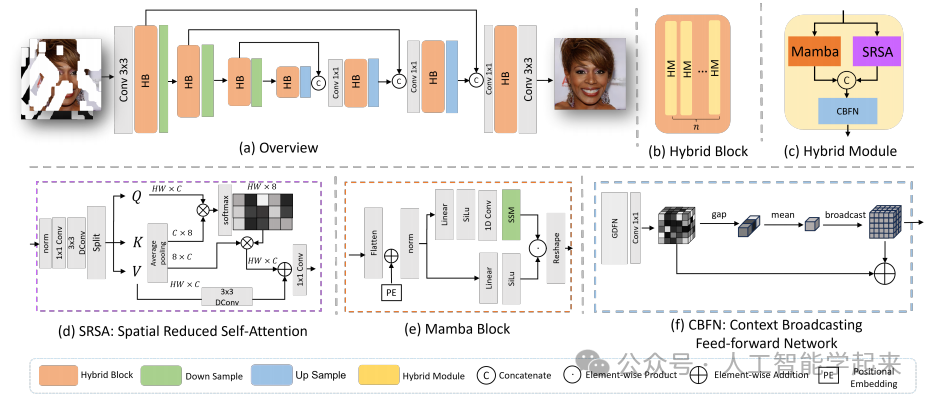
论文:MxT: Mamba x Transformer for Image Inpainting
内容
该论文介绍了一个名为M×T的图像修复模型,它结合了Mamba和Transformer的优势,用于高效地处理图像中的缺失或损坏区域。M×T通过提出的混合模块(Hybrid Module)在像素级和块级上实现双重交互学习,从而在保持计算效率的同时增强了图像修复的质量和上下文准确性。
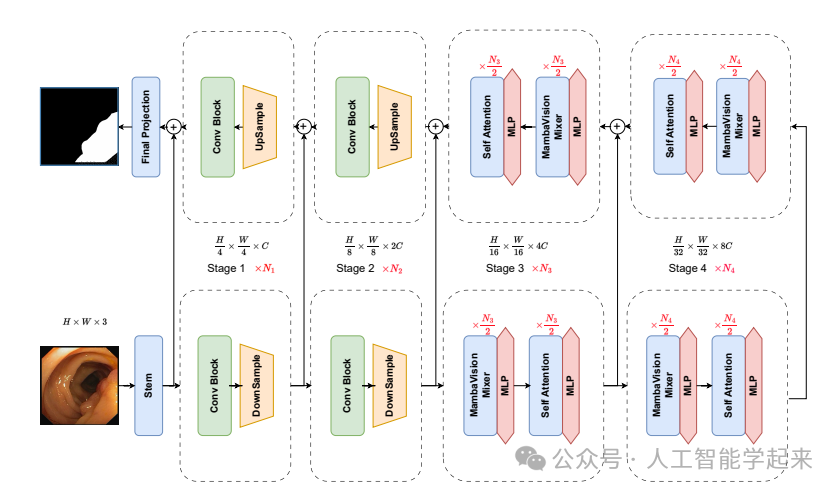
论文:HMT-UNet: A hybird Mamba-Transformer Vision UNet for Medical Image Segmentation
内容
该论文提出了一个名为HMT-UNet的混合Mamba-Transformer视觉U型网络,用于医学图像分割任务。该模型结合了Mamba(一种状态空间模型,SSM)和Transformer的优势,通过精心设计的混合机制,提高了捕捉长距离空间依赖的建模能力。
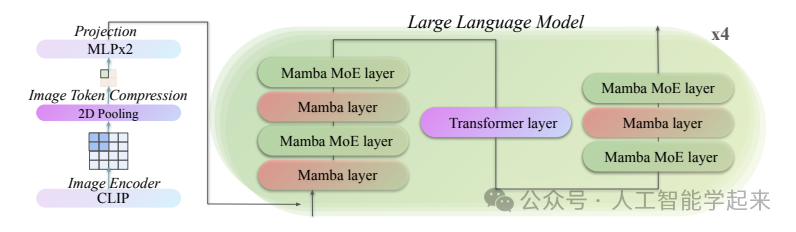
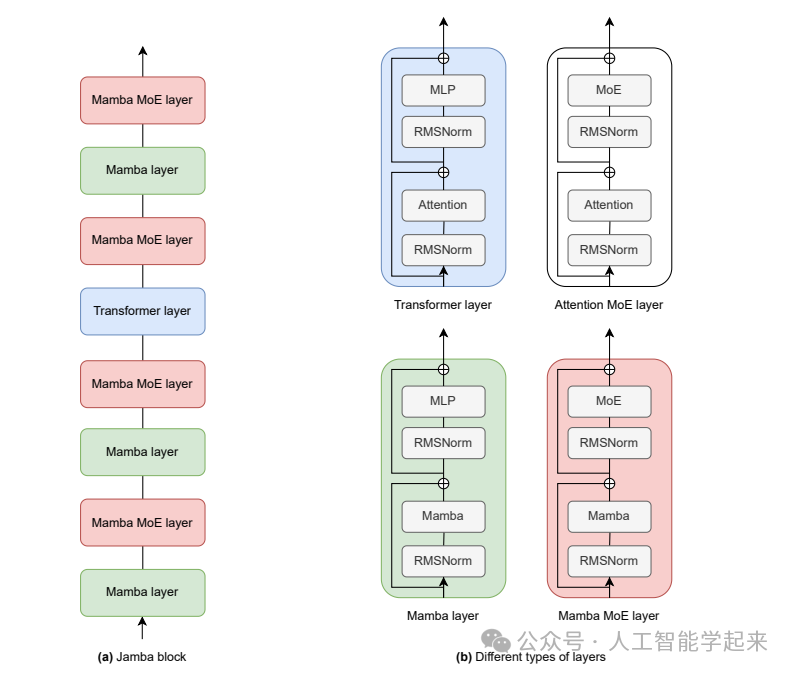
论文:Jamba: A Hybrid Transformer-Mamba Language Model
内容
该论文介绍了Jamba,这是一个新颖的混合Transformer-Mamba大型语言模型,它结合了Transformer和Mamba(一种状态空间模型)的优点,并通过混合专家(MoE)架构提高了模型容量,在保持较小内存占用的同时,提供了高吞吐量和最前沿的性能。
关注下方《AI科研圈圈》
回复“14MT”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









