







Windows 是全球范围内最流行的操作系统之一,许多企业和个人用户都在使用 Windows 系统。通过在 Windows 系统上支持 LLM 的推理,许多办公软件、聊天应用等都可以受益于 LLM 的技术,为用户提供更智能、更个性化的服务。LMDeploy 支持在 Windows 平台进行部署与使用,本文会从以下几个部分,介绍如何使用 LMDeploy 部署 internlm2-chat-1_8b 模型。
-
环境配置
-
LMDeploy Chat CLI 工具
-
LMDeploy pipeline (python)
-
LMDeploy serving
环境配置
安装显卡驱动 & CUDA Toolkit
https://developer.nvidia.com/cuda-12-1-1-download-archive?target_os=Windows&target_arch=x86_64
成功安装后,打开 Powershell 后,环境变量
CUDA_PATH不为空。

安装 LMDeploy
conda create -n lmdeploy python=3.10
conda activate lmdeploy
pip install lmdeploy --extra-index-url https://download.pytorch.org/whl/cu121需要注意的是,--extra-index-url 不能省略,不然会安装 CPU 版本的 PyTorch
下载模型
mkdir D:\workspace
cd D:\workspace
huggingface-cli download --resume-download --cache-dir cache --local-dir-use-symlinks False --local-dir internlm2-chat-1_8b internlm/internlm2-chat-1_8b命令行 CLI
LMDeploy 提供命令行工具,可以非常方便地在 Powershell 进行对话,相关命令是:
lmdeploy chat .\internlm2-chat-1_8b\LMDeploy 会根据 $env:CUDA_PATH 添加 CUDA Runtime 的目录,并在程序的开头会打印目录。如果没有下图红线的部分,需要检查显卡驱动以及 CUDA Toolkit 是否正确安装。
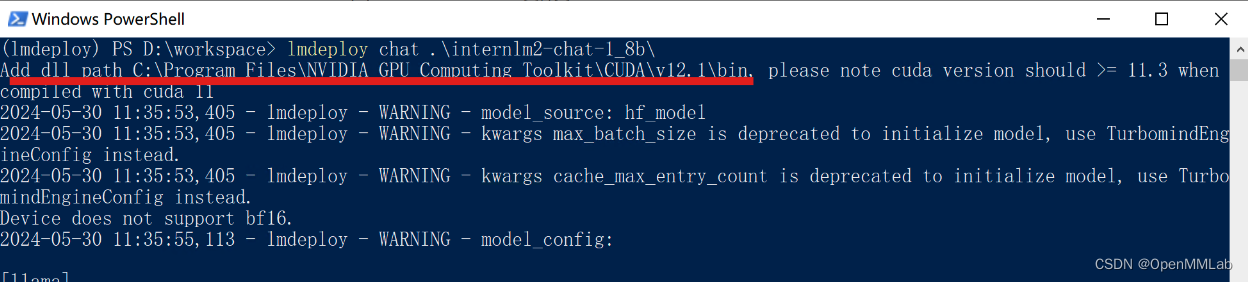
运行结果如下:

pipeline
LMDeploy 提供了 Python api,可以方便集成到其他的工具中,相关的用法如下。
from lmdeploy import pipeline
pipe = pipeline('internlm2-chat-1_8b')
pipe('上海有什么景点')运行结果如下:
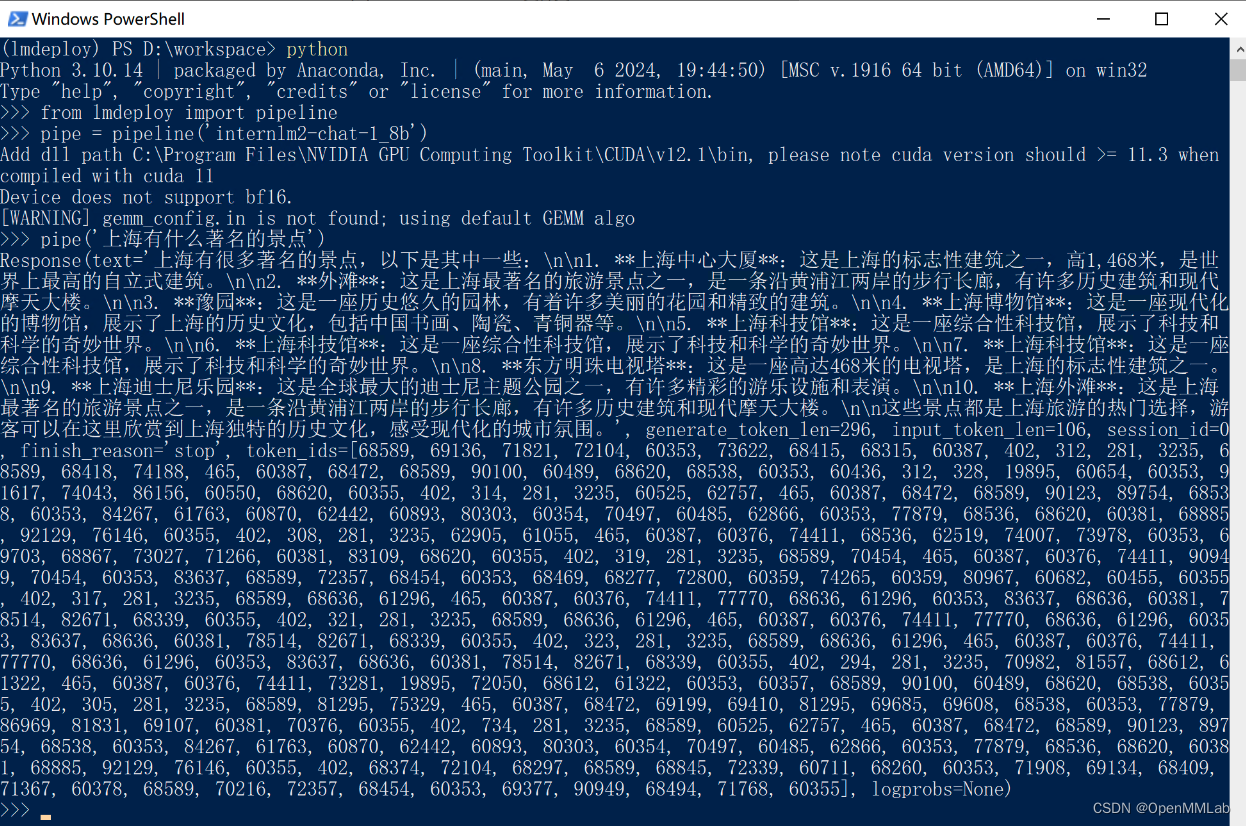
pipeline 启动时参数设置可参考 https://lmdeploy.readthedocs.io/zh-cn/latest/api/pipeline.html
服务化
LMDeploy 支持把模型一键封装为服务,对外提供的 RESTful API 兼容 openai 的接口。以下为使用方式:
服务端:
lmdeploy serve api_server .\internlm2-chat-1_8b\更多使用方式可参考 https://lmdeploy.readthedocs.io/en/latest/serving/api_server.html
客户端:
from openai import OpenAI
client = OpenAI(
api_key='YOUR_API_KEY',
base_url="http://127.0.0.1:23333/v1"
)
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "user", "content": "上海有什么著名景点"},
],
temperature=0.8,
top_p=0.8
)
print(response)FAQ:
Q: 如何使用 LMDeploy cuda11 的版本?
A: 安装 CUDA Toolkit >= 11.3 并确保显卡驱动的版本支持 CUDA Toolkit,之后可以从 LMDeploy Release 页面 找到使用 CUDA11 编译的 whl 包,以 python3.10, LMDeploy v0.4.2 为例,安装方式为:
pip install https://github.com/InternLM/lmdeploy/releases/download/v0.4.2/lmdeploy-0.4.2+cu118-cp310-cp310-win_amd64.whl --extra-index-url https://download.pytorch.org/whl/cu118Q:模型过大,显存不够加载模型怎么办?
A:可以考虑把模型权重量化为 4bit,然后再部署。模型大小的快速估算方式为,1B 大小的模型,其权重(16bit)大约需要 2G 的显存。量化为 4bit 后,大约只需 0.5G 显存。7B 模型,4bit 量化后,约 3.5 G。具体方法请参考文档:https://lmdeploy.readthedocs.io/en/latest/quantization/w4a16.html
Q:如何使用多卡推理?
A:对于在 Windows 宿主机上直接使用 LMDeploy 的方式,由于 NVIDIA 并未提供 Windows 平台的 NCCL 运行时,所以不支持多卡推理。

















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









