






零、abstract
可以看到作者想要提出RankCoT (Chain of Thought)这种知识精炼方法,来解决查询到的上下文的噪声问题。
一、intro
首先,作者介绍了RAG,提到了一个RAG中存在的固有知识与检测到的知识产生冲突的问题。作者提到了之前的modularRAG的工作:https://arxiv.org/pdf/2407.21059,认为这种方法虽然对文档进行了重排序,但是仍然没有完全剔除不相关的内容。也提到了一些RAG试图对检索到的内容进行总结,但是仍然会引入噪音。
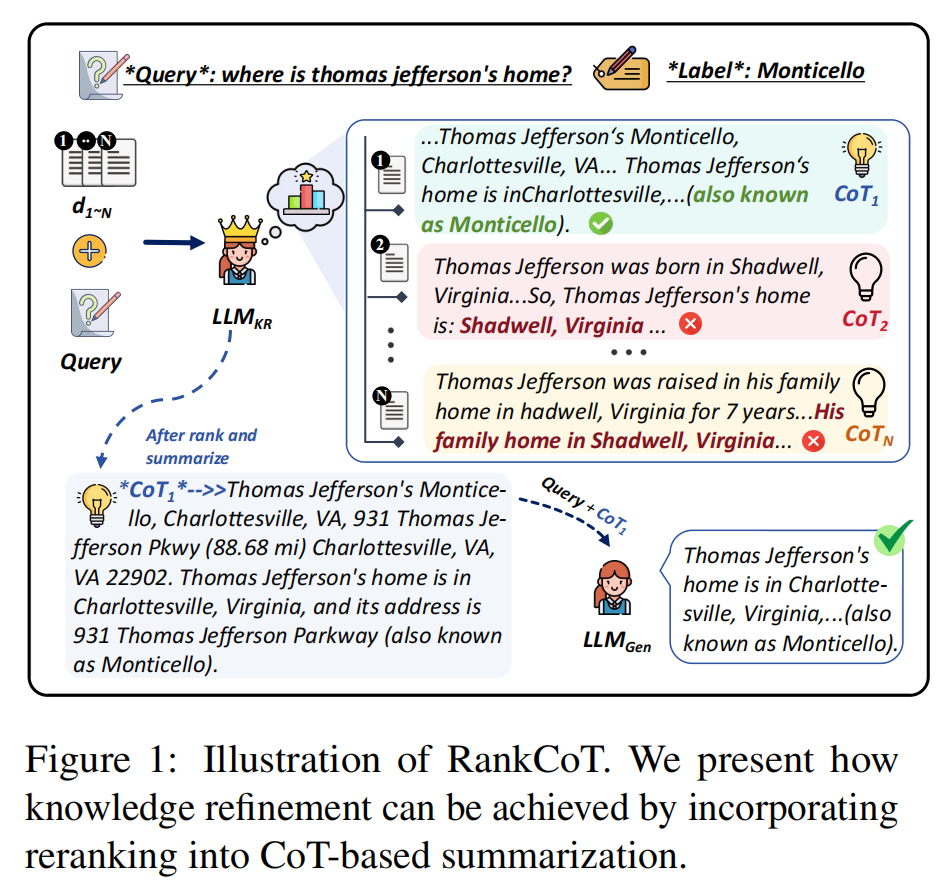
接着大致说了一下提出的CoT模型的训练流程。将查询和检索到的文档分别输入到大语言模型中,要求它生成多个思维链(CoT)回答来回答问题,这些回答可视为总结结果。然后,设计了自我优化模型,促使大语言模型根据这些抽样得到的思维链来回答问题,有助于优化思维链结果,以进行更有效的训练。如果优化后的思维链包含正确答案,则被视为正向精炼结果,而那些不包含正确答案的则被视为负向精炼结果。这样的模型可以用来refine信息。
二、related work
略
三、methodology
首先,作者讲基础的RAG knowledge refinement。不同于直接的RAG,经过refine的RAG模型应该经历以下过程:首先将q(query)和检索到的D(document)一起输入refine模型,生成精炼知识y,然后将y和q一起整合,作为新的query输入LLM生成答案。
在Intro部分提到,有些模型通过rerank的方式“去噪”,有些通过summary的方式“去噪”,也就是除去无关信息。但是rerank除去无关信息的颗粒度较大,是以整篇document为单位的;summary有时也会对无关信息进行总结。但是抛开这些缺点,作者先对它们进行了一些介绍。
![]()
![]()
这些是rerank的公式化流程。 KR的意思是knowledge refinement.
![]()
这些是summarization的。
接着才是重头戏,RankCoT模型的训练过程和推理过程:
首先,我们的目标是训练出一个这样的模型,输入原始查询和和所有文档,输出CoT形式的基于查询和所有检索文档生成的知识精炼结果,即包含推理过程和关键信息的思维链。这个思维链作为精炼后的知识,被输入到大语言模型中用于生成最终的回答。这就是推理过程。
然后是训练过程。训练的时候,模型对于每个文档(一共k个)都会生成一条CoT精炼结果,最终生成k个精炼结果的集合Y。对于Y中的每一个元素,如果包含了正确的答案,那么标记为正样本,否则标记为负。然后定义loss函数:
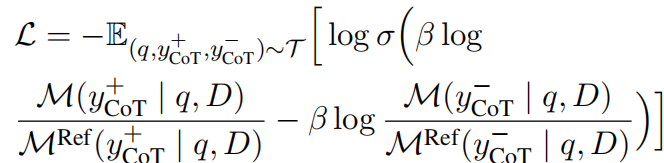
依据这个loss函数去训练。这么训练能达到的效果是,有更高的概率去生成符合ground-truth answer的CoT, 由于每一个CoT都是基于单独的document,所以这会指导模型去排序文档。这也就是为什么作者会说这种算法融合了排序的思想。生成CoT的过程本身就是进行了总结,以及后面会用自反思机制再精炼,所以说融合了summarize的思想。
RankCoT 的自反思机制会对初始生成的 CoT 进行评估和优化。如果初始生成的 CoT 质量不高,或者来自于无关文档,自反思机制会尝试通过再次输入相关信息来生成更优质的 CoT。在这个过程中,模型会进一步判断生成的 CoT 是否符合要求,对于不符合要求的 CoT(如来自无关文档生成的不正确或不相关的 CoT),会进行修正或重新生成。通过这种方式,进一步筛选掉了由无关文档生成的不符合要求的 CoT,提高了最终生成结果的准确性和相关性。
我的理解是,RankCoT通过两个阶段实现了“排序”和“总结”方法的融合。第一阶段,将指令和文档输入一个我们微调好的生成CoT的模型,以生成尽可能准确的CoT形式的总结。这里微调的目的是,让生成的CoT形式的总结更加契合query的内容和文档中牵扯到的客观事实。第二阶段就是自反思机制,对结果根据相关性再进行一次处理,使得筛选出来的结果既包含正确结果,又是总结性的。
下面这段话是我让豆包描述的工作流程:
假设我们有一个问题 “Who was the first president of the United States?”,以下是 RankCoT 的具体工作流程示例:
- 检索文档:首先,系统会根据问题从知识库或文档集合中检索出一系列相关文档。例如,可能会检索到关于美国历史、美国总统介绍等方面的文档。
- 生成 CoT 候选:基于每个检索到的文档,模型会生成思维链(CoT)候选。比如,对于一篇介绍美国建国历史的文档,模型生成的 CoT 可能是:“The United States was founded in 1776. After the founding, there was a need for a leader. George Washington was a prominent figure during that time. He had significant influence and played a crucial role in the early days of the nation.”;对于另一篇关于美国总统列表的文档,生成的 CoT 可能是:“The list of US presidents starts with George Washington. He served as the first president. He was elected in 1789. ”。
- 定义正负面结果:将包含正确答案 “George Washington” 的 CoT 结果定义为正面结果,不包含的则为负面结果。在上述例子中,第二篇文档生成的 CoT 包含正确答案,是正面结果;第一篇文档生成的 CoT 虽然包含一些相关信息,但没有明确指出 “George Washington” 是第一任总统,属于负面结果。
- DPO 训练:使用直接偏好优化(DPO)算法对模型进行训练。在训练过程中,模型会学习为正面结果分配更高的生成概率,为负面结果分配较低的生成概率。通过不断调整模型的参数,使其逐渐掌握根据文档内容生成与问题相关且包含正确答案的 CoT 的能力。例如,模型会学习到在处理关于美国总统的问题时,更关注文档中直接提及总统姓名和顺序的信息,而不是一些间接相关的内容。
- 自反思机制优化:模型可能会对初始生成的 CoT 进行自反思和优化。如果初始生成的 CoT 质量不高,或者存在一些模糊不清的地方,自反思机制可能会促使模型再次生成一个新的 CoT,以消除可能存在的固定模式或不明确的表述,增加多样性和准确性。比如,对于第一篇文档生成的 CoT,自反思机制可能会发现其中没有明确回答问题,然后尝试重新生成一个更准确的 CoT,如 “Considering the history of the United States, George Washington was the first president. He was elected due to his leadership and contributions during the revolutionary war.”。
- 生成最终结果:经过训练和优化后,当再次遇到类似问题时,模型会根据检索到的文档生成更有可能包含正确答案的 CoT,从而为用户提供准确的回答。例如,对于 “Who was the first president of the United States?” 这个问题,模型会更倾向于生成包含 “George Washington” 的 CoT,如 “The first president of the United States was George Washington. He was a great leader who laid the foundation for the nation. ”。
以上就是我对本论文算法介绍部分的笔记,欢迎大家讨论和指正~

















 53
53

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









