






最近DeepSeek很火啊,所以简单做了一个小测评。
先说结论:性能比其他国内大模型要强不少,与GPT属于同一梯队。
因为我的claude和GPT最近登不上去的原因,本次测试使用国内大模型中较为擅长数学推演的智谱清言GLM4PLUS与DeepSeekR1对决,以及国内大模型中较为擅长文学的文心一言3.5 与DeepSeek普通状态做对决。
需要注意的是,本测试中的所有大模型版本均使用了免费的主页提供版本,均非付费版本。
首先我们将进行文学对决,我们拟定两个题目,让两个大模型各写一首七言绝句。
接下来是文心一言3.5的表现。
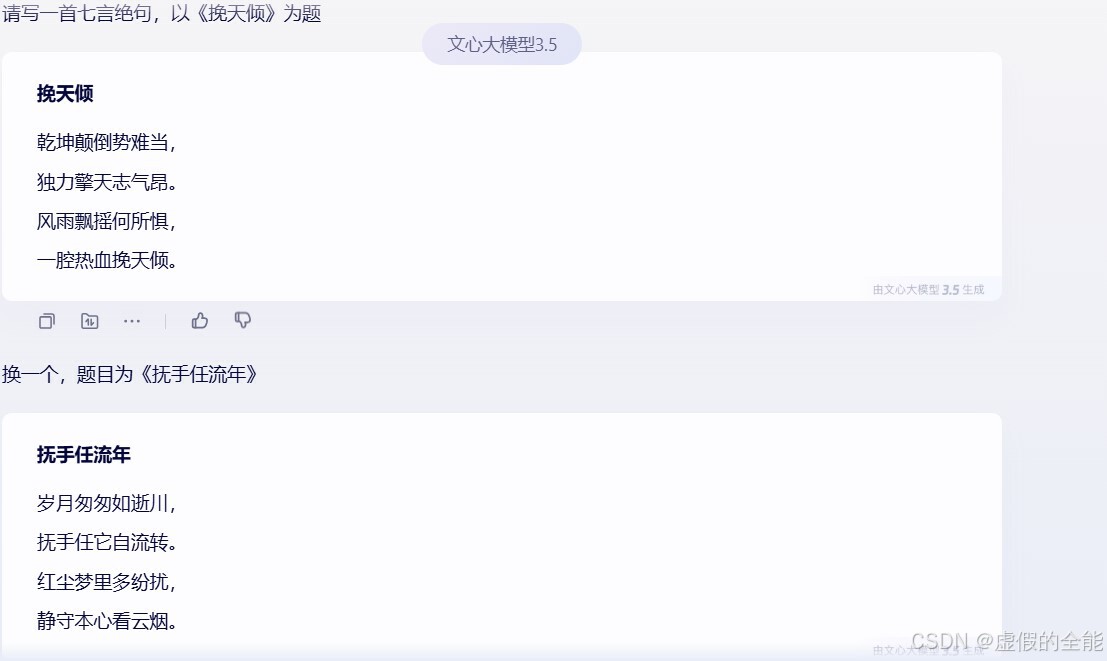
然后是DeepSeek普通状态的表现。

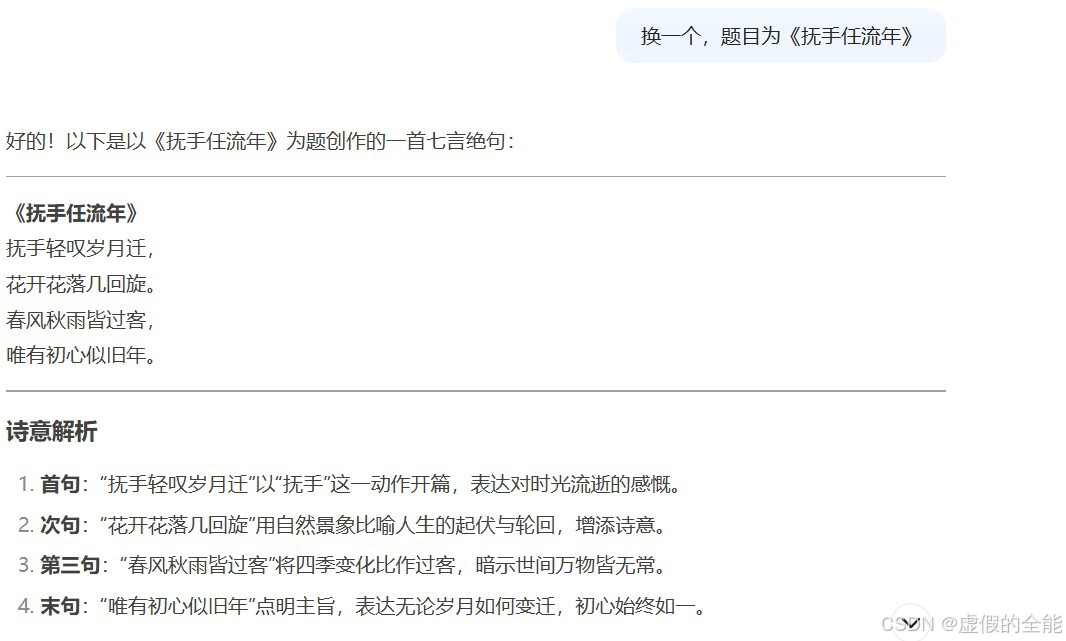
可以清晰地看出DeepSeek普通状态的文学水平明显要高出一截。
接下来是数学推理能力,这里使用的是考研数学一2023年的两道真题,让我们看看智谱清言的GLM4PLUS与DeepSeek之间的对决吧。
首先是GLM4PLUS。


可以看到GLM4PLUS似乎并不愿意长篇大论地讲自己的推理过程,这与后面的DeepSeekR1形成了鲜明的对比,不过我们还是要求GLM4PLUS计算并给出答案了,值得一提的是,GLM4普通版本难以胜任解题需求,会出现乱码。
这里是GLM4PLUS给出的最终答案。
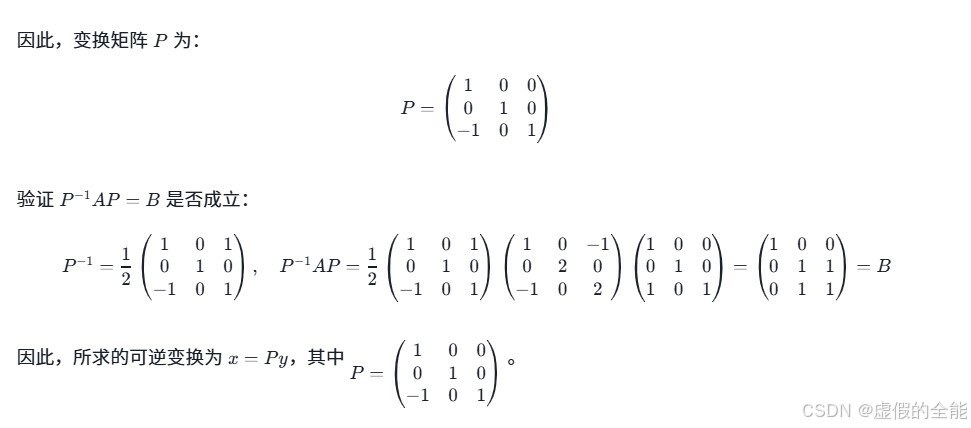

而这里则是DeepSeekR1给出的答案


这里则是这两道题的正确答案,作为考研数学一的大题,难度还是颇高的,我们可以看出DeepSeekR1的表现更好。


DeepSeekR1的深度思考过程也颇为有意思,或者说,颇为有用,这个思考过程能让人审视自己的问题是否正确和准确,明白自己想问的到底是什么,是极好的一个功能,就是推算中不停对自己纠错的过程有点太长了,如果推算能力提升的话应该就不用推算那么长了。(看看这长度)

我国的诸多大模型各有所长,而它们的长处都被压下去一头了,这足以说明DeepSeek的强悍程度,已经接近GPT的水平了,DeepSeek的使用性价比和方便程度(毕竟是国内自研)又远超GPT,希望未来DeepSeek能发挥其远比GPT成本低的优势,继续扩大其用户规模,获取更多的数据,争取早日超越GPT。

















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









