







前言
本文将全面阐述yolov5目标检测使用教学,首先是配置yolov5的运行环境以及yolov5的代码下载,然后教学如何制作自己的目标检测数据集以及如何利用yolov5加载该数据集进行目标检测模型训练,最后教学如何通过yolov5加载训练好的模型进行目标检测以达到检测自己想要的目标功能!(本篇文章全程以花卉检测为例子进行讲解,对其他目标的检测基本一致!)
一、YOLOv5环境配置
首先在网上大家其实可以看见许多yolov5的环境配置教学,但其实很多时候大家在自己配置的时候还是会有一堆错误,这里博主给大家带来一个史上最简单最方便的免自己手动命令行配置环境的教学,大家可以直接看我这个视频按照视频进行环境配置即可,非常快就能配置好噢!
【全网最简单的YOLOv5环境搭建教程】包含:PyCharm、Anaconda、YOLOv5环境、PyQt5环境安装
二、数据集制作
首先如果你想使用yolov5对你自己想要检测的目标进行识别,那我们首先就需要制作自己的数据集,而最主要的就是需要收集大量包含你需要检查目标的图片,比如你要检测行人,检测猫狗或者是检测其他的一些目标,你就的收集大量包含对应目标的图片来做成训练用的数据集。
那想要的数据集该从哪里去收集呢,以下说明三个途径:
- 官网获取:去一些数据集开源网站搜索下载,例如有Kaggle、Roboflow、GitHub等,一般在这些地方的数据集都是以及标注好了的数据集,下载来用也就无需标注,很方便。但是对于小白来说去这些地方找还是挺难找的。
- 网友获取:在CSDN去搜索想要的数据集,去看看有没有网友分享对应的数据集获取地址或者自己的数据集分享。但是可能很多是付费资源。但是相比于上述网站去下载更加方便。(博主这有一百多种常见与不常见的已标注的目标检测数据集,有需要的直接dd我)
- 自己收集:有时候实在找不到怎么办,那就自己收集,自己收集的方式很简单,可以自己实拍,也可以网上搜索图片,但是这样收集的数据集是没有标注的,只能获取到图像,后续还需要进行数据标注才可以进行训练。
1.收集数据集图片
通过上述讲解了数据集获取的途径,这里我们直接以第三种方法自己收集数据集为例子进行讲解,因为这样才能讲数据集标注部分。
假如我现在想要能够对花卉中的玫瑰、牡丹、向日葵、郁金香进行检测,那我们就需要分别去收集对应的这些图片,首先我们去百度搜索玫瑰图片,如下图:
我们可以通过截图去保存相应的玫瑰花图像,然后顺便搜索一下其他的花卉图像,一起进行截图保存,最好保存的图像格式最好是.jpg、.png、.jpeg、.bmp的噢,其他格式的不常见,反正如果担心就直接去截图保存而不是通过网页里直接保存,最好把所有图像都放置在一个文件夹中,先命名为images吧。这里我主要是来演示实现检测,我这边就对四种花卉一共收集了351张图,用来做训练检测就差不多够了。如果你们自己去做最好还是图像越多越好!如下图:
2.进行数据集标注
我们收集好对应的图片之后呢,我们需要进行数据标注,简要的来说就是需要通过手动去对这些图片里面你需要检测的目标画框,然后标记出这个目标是什么!最后才能得到一个可以用来训练的目标检测的数据集!
这里我们标注使用labelimg进行图像的标注,还是那句话网上有很多教你配置下载labelimg的教程,但是说实话自己上手去配置还真没那么容易特别是小白,用命令行去装labelimg很容易出问题,所以我这里准备了可以直接运行的labelimg.exe程序,电脑直接双击打开就可以啦,免去你们去安装labelimg的麻烦!
labelimg:https://pan.baidu.com/s/15pQ6ILpuuKbaBg83yM56Cg
提取码:ppwq

有了labelimg之后呢,我们先再创一个文件夹,命名为txt即可,之后我们标注出来的标注文件都用老保存至这个txt文件夹中!如下图
这时候我们打开上述下载的labelimg软件,直接双击就打开了!
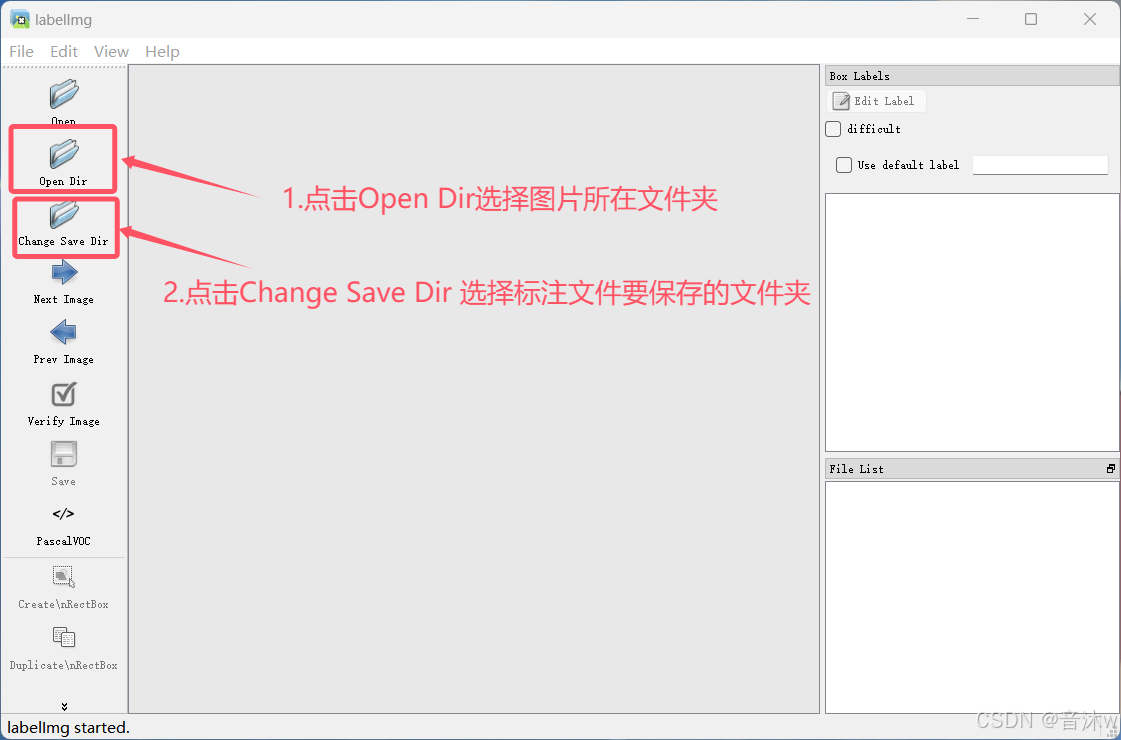
首先我们先点击左侧Open Dir去选择你的图像文件夹(如果是和我一样设置的文件夹名,这里就是选images文件夹),然后再点Change Save Dir去选择标注文件要保持的文件夹(如果是和我一样设置的文件夹名,这里就是选txt文件夹),如下图。
选择好之后我们就可以看见你的图片显示在这上面了,右下角会有你所有图像的列表!
然后这时候我们要打开自动保存功能,这样你每次标注完一张图像,都会自动把数据保存在标注文件中并且保存,否则你每次标注完一张都会显示弹窗手动点击保存,太麻烦了。点击菜单栏的View,然后勾选上Auto Save mode即可,如下图。
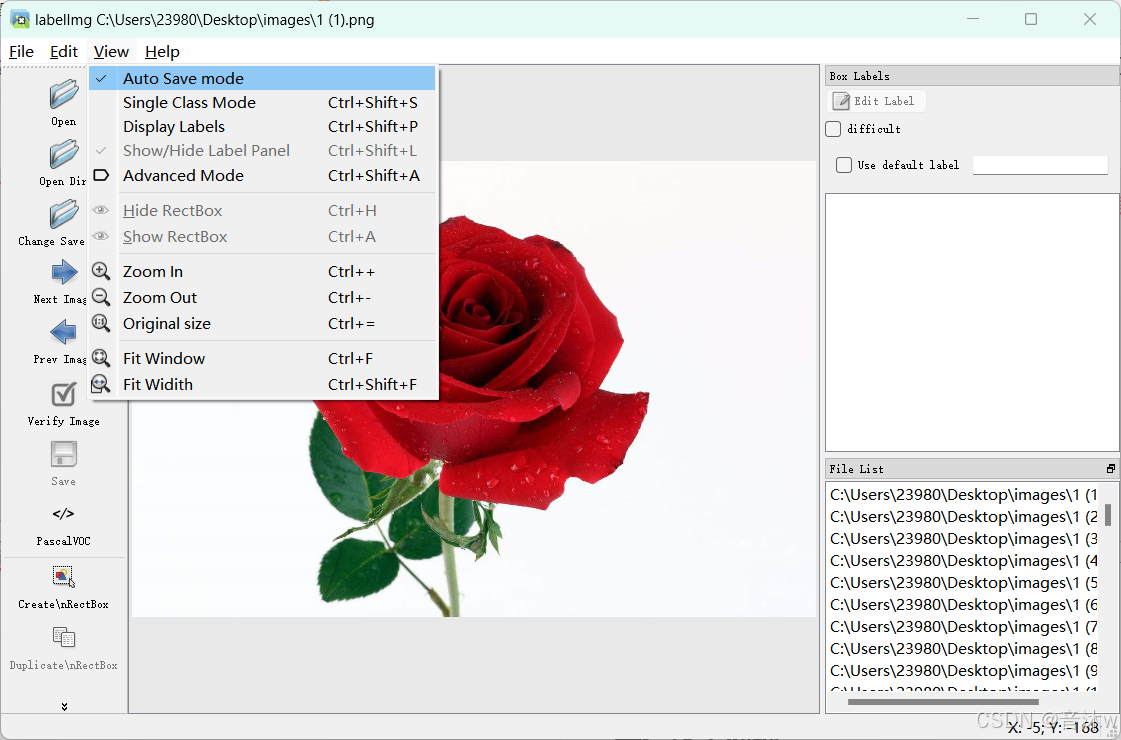
最后一步就是点击左边保存的标注文件格式,由于我们是要标注yolov5的标注文件,是属于保存的标注文件是txt文本类型的,一般打开labelimg他默认是PascalVOC的,也就是yaml类型的,这不是我们需要的标注文件类型,我们点击一下切换成显示yolo即可。
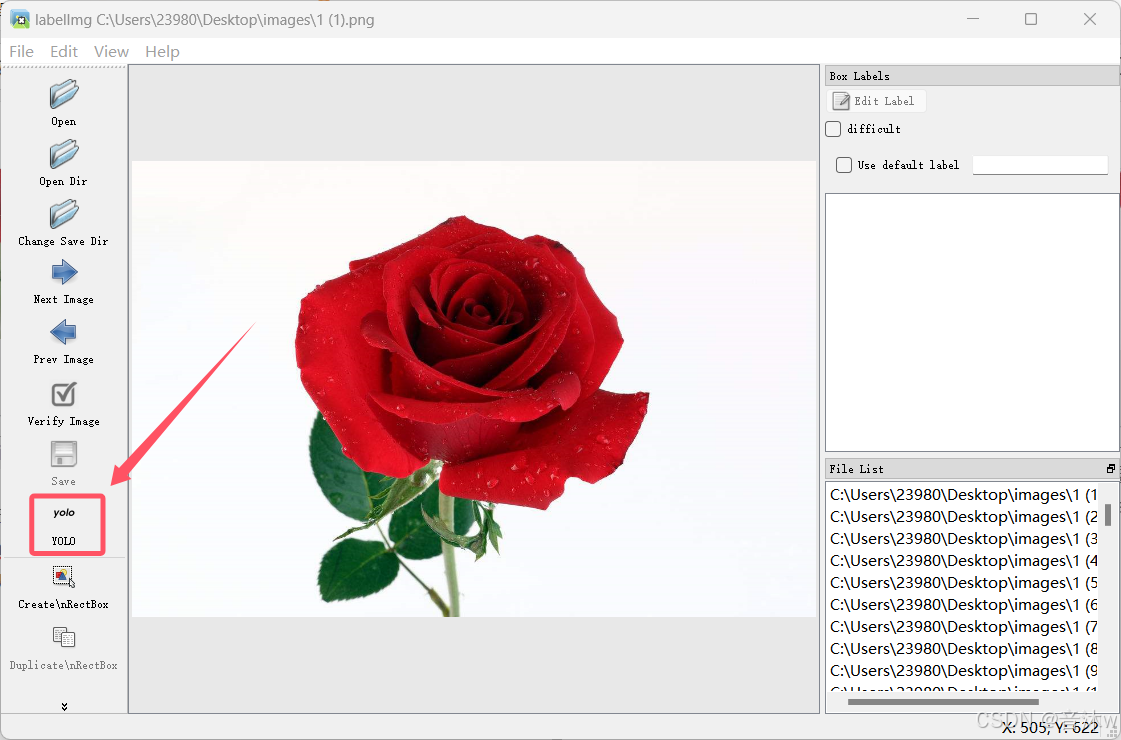
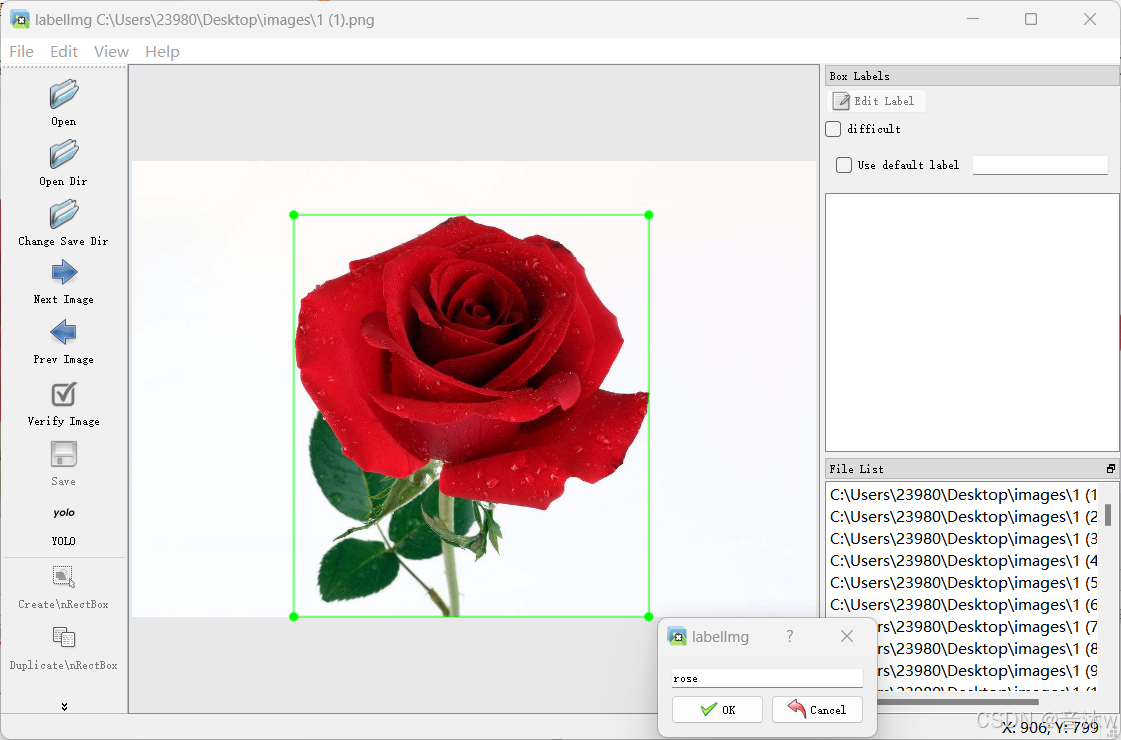
这时候选择我们就可以开始标注了,从第一张开始标注,我们把鼠标移动到图像上然后按下w键,就能出现一个十字架,然后这时候我们就需要通过长按鼠标左键,对目标物体进行框,这个框就是要框成你目标的外接矩形就行了,不要标歪也不要标大和标小,都会影响数据集质量的!然后标注完一个目标会弹出一个窗口让你填写这个目标的名称,你就填对应的名称即可,我这里标注的是玫瑰,所以我填的rose,然后点确定就好啦,这样这个第一张图就标注好了!(tips:如果你一张图出现多个目标那就每个目标都要去标注然后填写该目标的名称,如果你已经标注过同类型的目标,弹窗那里就可以不用手动输入目标标签了,输入框下面会有已标注过的目标标签供你选择,只需点击对应的标签名字就可以啦!)
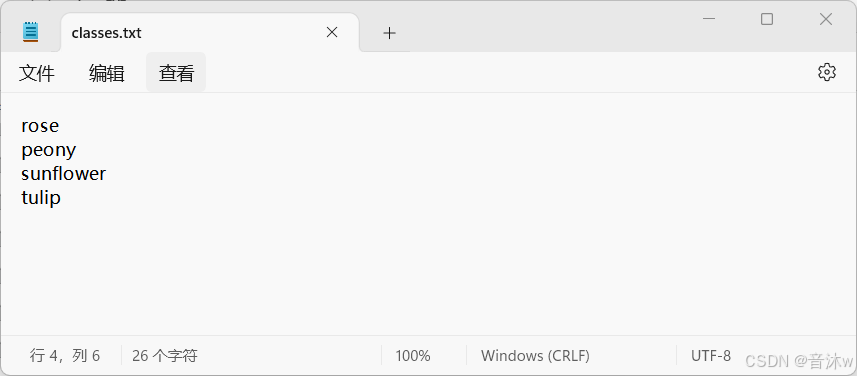
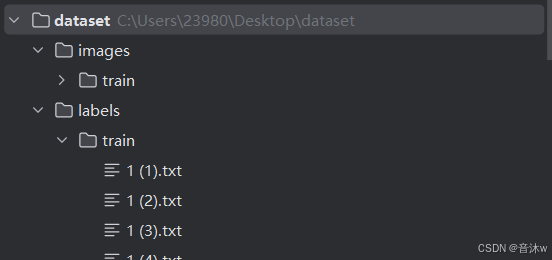
我们就这样从第一张开始一直标注,标注完你所有的图像即可!最后你标注的所有标注文件都会保存在你选择的输出文件夹中(也就是txt文件夹中),并且你会发现标注文件会比你的图像数量多一,可以看见我们图像时351张,但是这里的txt文件有352张,这是因为文件夹中还会有一个标签的txt文件,也就是下图中的classes.txt文件。里面会保存你所标注的所有标签,而且他的顺序是按0,1,2,3这样对应的,如下图。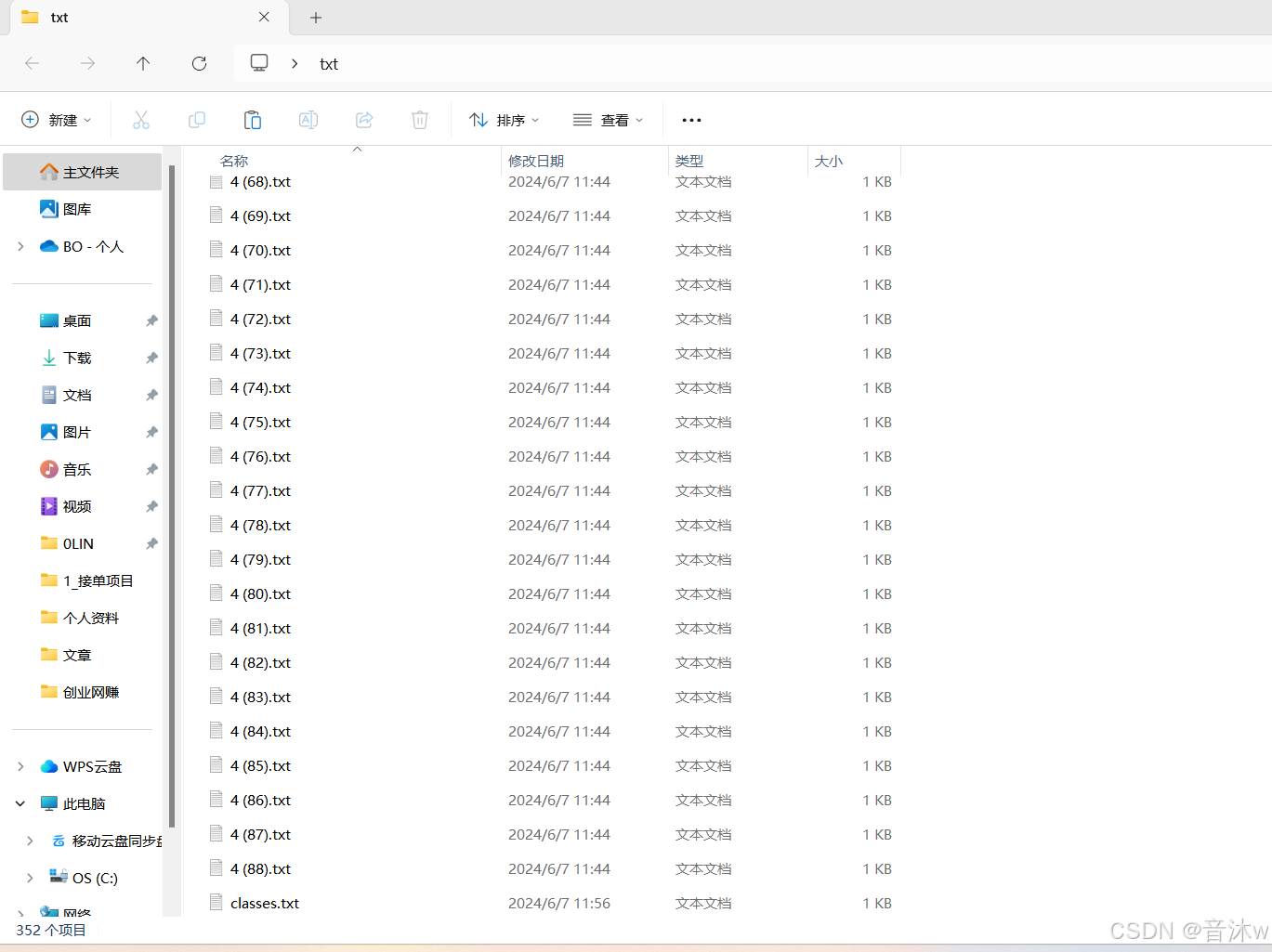
3.数据集划分
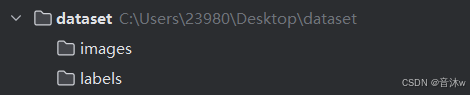
对图像标注完之后,就要开始很关键的一步了,要制作yolov5能够读取的数据集文件夹目录,你们可以直接根据我的来,首先创建一个名为dataset的文件夹,在里面创建一个images的文件夹和一个labels的文件夹,images文件夹是用来放图像的,而labels文件夹里面是用来放对应的标注文件的,如下图。
创完之后其实我们的数据集需要分为训练集、验证集以及测试集。
训练集(Train)的图像数据是用来训练检测模型用的
验证集(Val)的图像数据是用来在模型训练过程中评估模型性能和调整模型超参数的
测试集(Test)的图像数据是用来最终评估训练好的模型在真实场景下的泛化能力的,也就是看看训练出来的模型在这些测试集图像上的检测效果
当然,也不是什么时候都需要划分的,你可以根据你们自己需要来,一般来说是有三种训练。
1. 不进行划分,只用训练集train训练
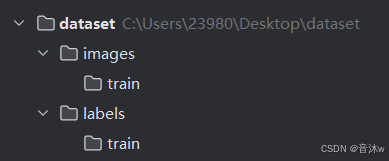
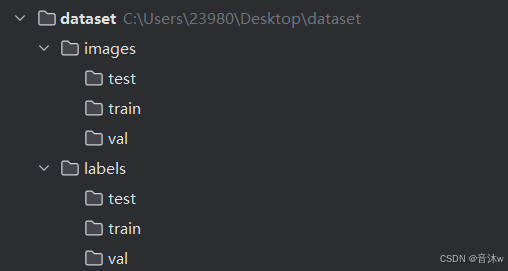
用这种方式训练,我们则可以不要去划分图像,我们只需要分别再images文件夹和labels文件夹中分别创建一个train文件夹,然后直接把所有图像放进images文件夹里的train文件夹中,然后对应的所有标签文件都放进labels文件夹里的train文件夹中。如下图
2. 用训练集train和验证集val,不用测试集test
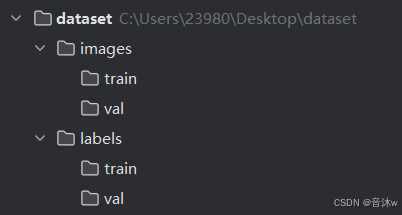
用这种方式进行训练,我们需要分别再images文件夹和labels文件夹中分别创建一个train文件夹和一个val文件夹,然后需要将图像数据分成两份,对应的标注文件也要分成两份,一般来说是按8:2进行划分, 将占比为8的图像放进images文件夹里的train文件夹中,剩下占比为2的图像放进images文件夹里的val文件夹中,然后要将占比为8的图像对应的标注文件放进labels文件夹里的train文件夹中,将占比为2的图像对应的标注文件放进labels文件夹里的val文件夹中即可。如下图
3. 用训练集train、验证集val以及测试集test进行训练
用这种方式进行训练,我们需要分别再images文件夹和labels文件夹中分别创建一个train文件夹、一个val文件夹以及一个test文件夹,然后需要将图像数据分成三份,对应的标注文件也要分成三份,一般来说是按7:2:1进行划分, 将占比为7的图像放进images文件夹里的train文件夹中,占比为2的图像放进images文件夹里的val文件夹中,剩下占比为1的图像放进images文件夹里的test文件夹中。然后要将占比为7的图像对应的标注文件放进labels文件夹里的train文件夹中,将占比为2的图像对应的标注文件放进labels文件夹里的val文件夹中,剩下占比为1的图像对应的标注文件放进labels文件夹里的test文件夹中即可。如下图
然后本文就不进行划分了,因为我的图像也没有很多,就300多张,如果划分一下训练的图像就太少了,一般里面如果数据集多的话还是划分训练比较好!好啦到这里我们的目标检测数据集就制作完成啦!!!
三、模型训练
1.准备工作
首先需要准备yolov5的代码,如果你是看我上面配环境教学配置的环境的话,是会有yolov5的代码滴,如果不是看上面教学配置环境的,这边也给你们准备好了yolov5的代码噢,这个代码是7.0版本的,也是yolov5最后的一个版本代码,然后还有一个官方预训练权重yolov5s.pt,也要下载下来放进代码里!
yolov5-v7.0: https://pan.baidu.com/s/1o4sBQV4tQ4iTg-oMN9L_VA
yolov5s.pt:https://pan.baidu.com/s/1QhkWLmSbkdAflbmGigkSeA
提取码:ppwq
解压上方链接下载的yolov5-v7.0的压缩包,然后将上方第二个链接下载的yolov5s.pt官方预训练权重放仅yolov5-v7.0文件夹就好啦!

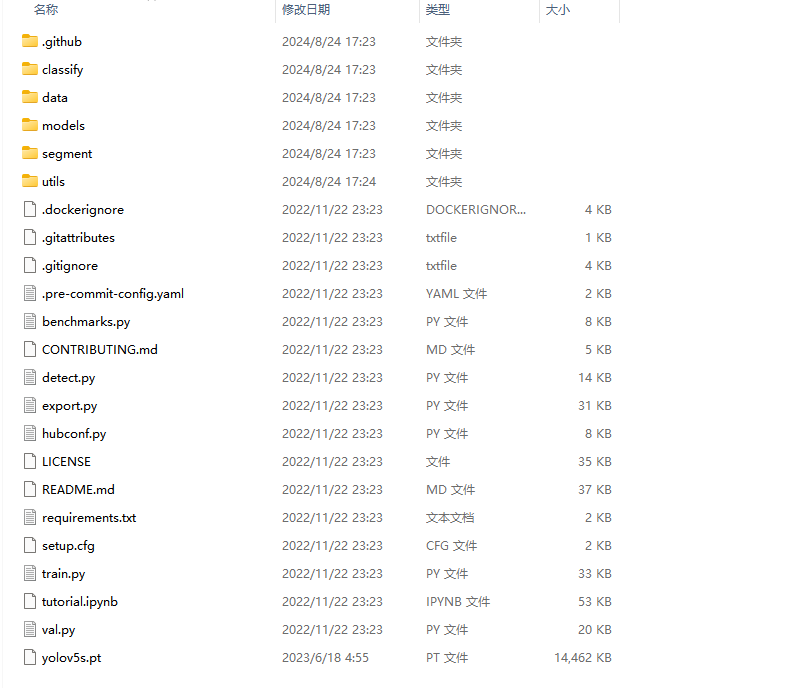
然后这个项目就是yolov5官方上面的一个7.0版本的源代码项目,项目文件夹里面的目录长这个样子,如下图!
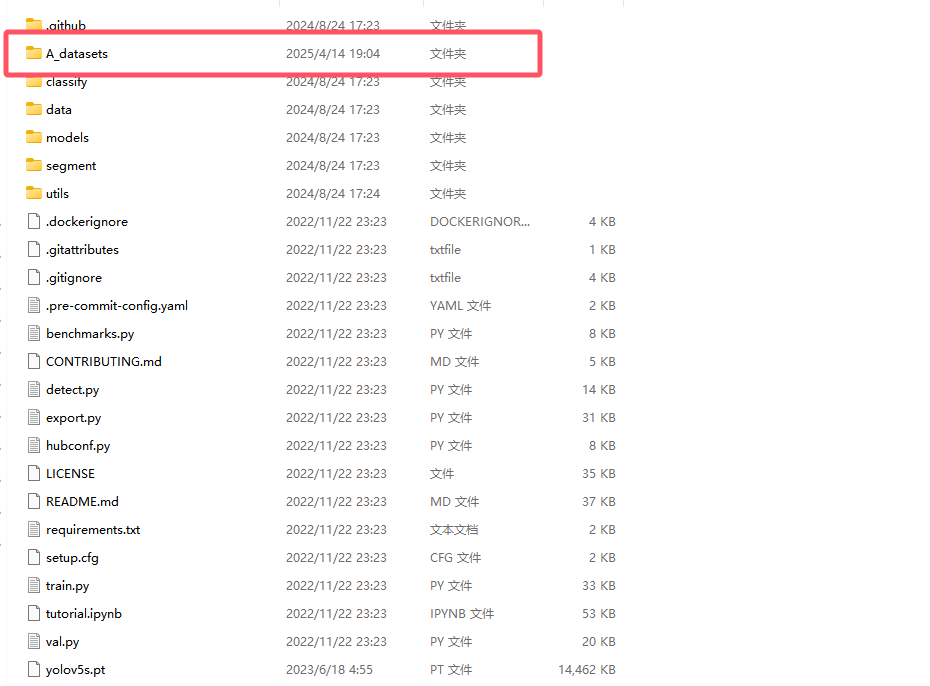
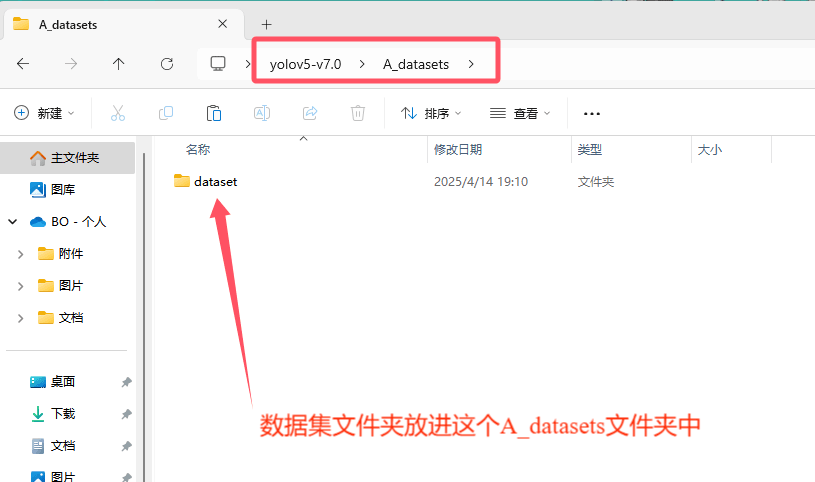
现在我们可以在这个yolov5-v7.0的代码文件夹里面创建一个A_datasets的文件夹,如下图!
然后我们把我们的数据集文件夹放到这个A_datasets文件夹里!
这样我们就完成了训练训练数据集的准备工作了!
2.训练配置
2.1 用pycharm打开yolov5代码
我们通过鼠标拖动将yolov5-v7.0的代码移至pycharm即可打开yolov5的项目,然后去选择对应anaconda里面的yolov5环境加载到pycharm即可!(详细可以看我上方环境配置教学视频的最后一节!)
2.2 配置数据集配置文件dataset.yaml
我们要训练数据集首先需要让yolov5的代码读取到我们数据集的位置,以及知道我们数据集需要检测什么类别的目标,所以我们需要进行数据集的配置文件的配置!我们打开yolov5代码项目里的data文件夹里面的coco128.yaml,这个yaml是官方coco128数据集的数据集配置文件,我们可以利用他的来改写即可!
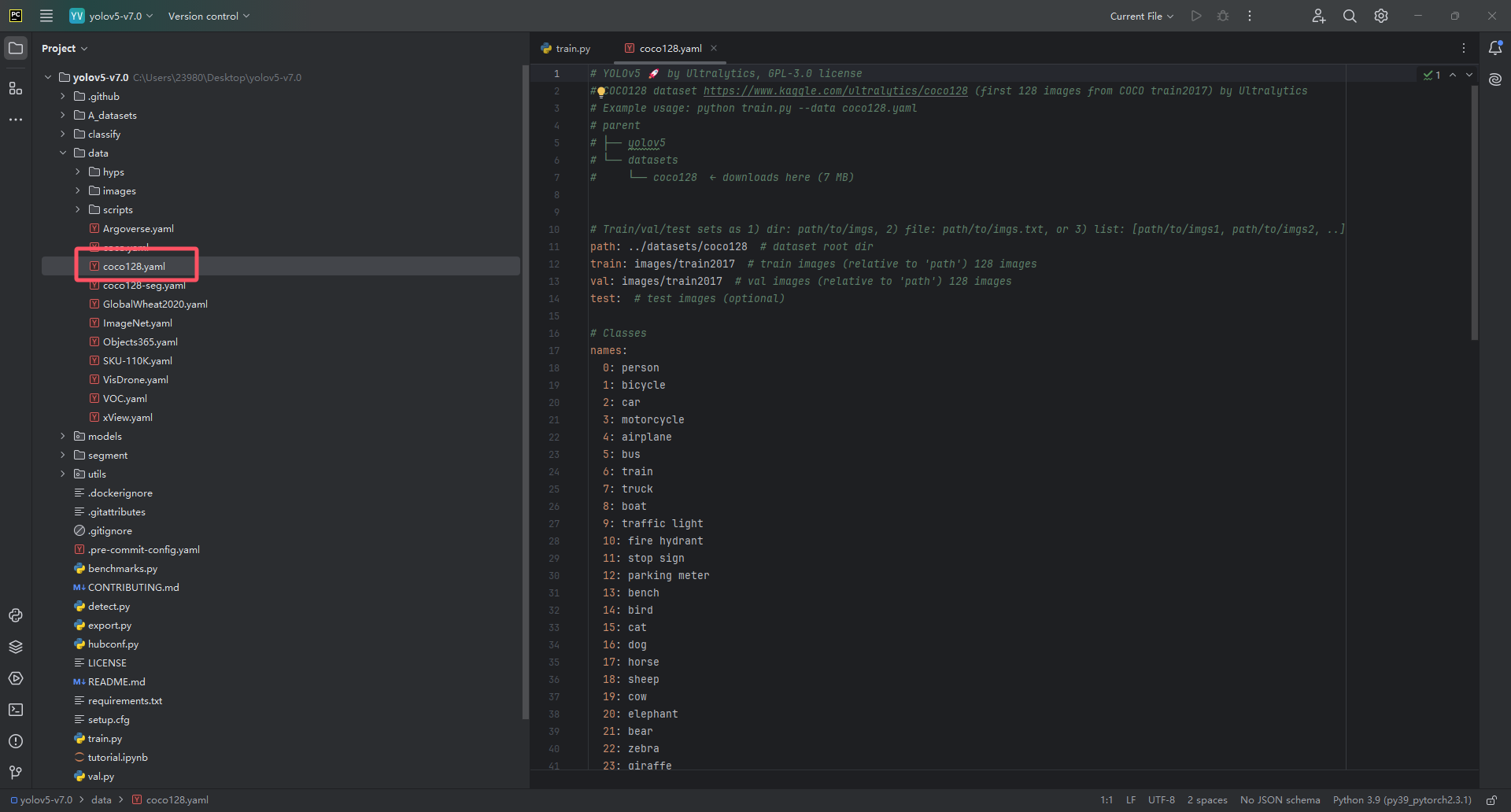
我们将他这个coco128.yaml赋值到我们在代码里创的那个A_datasets文件夹中,并且重命名为dataset.yaml,然后我们需要修改两处地方,如下图!
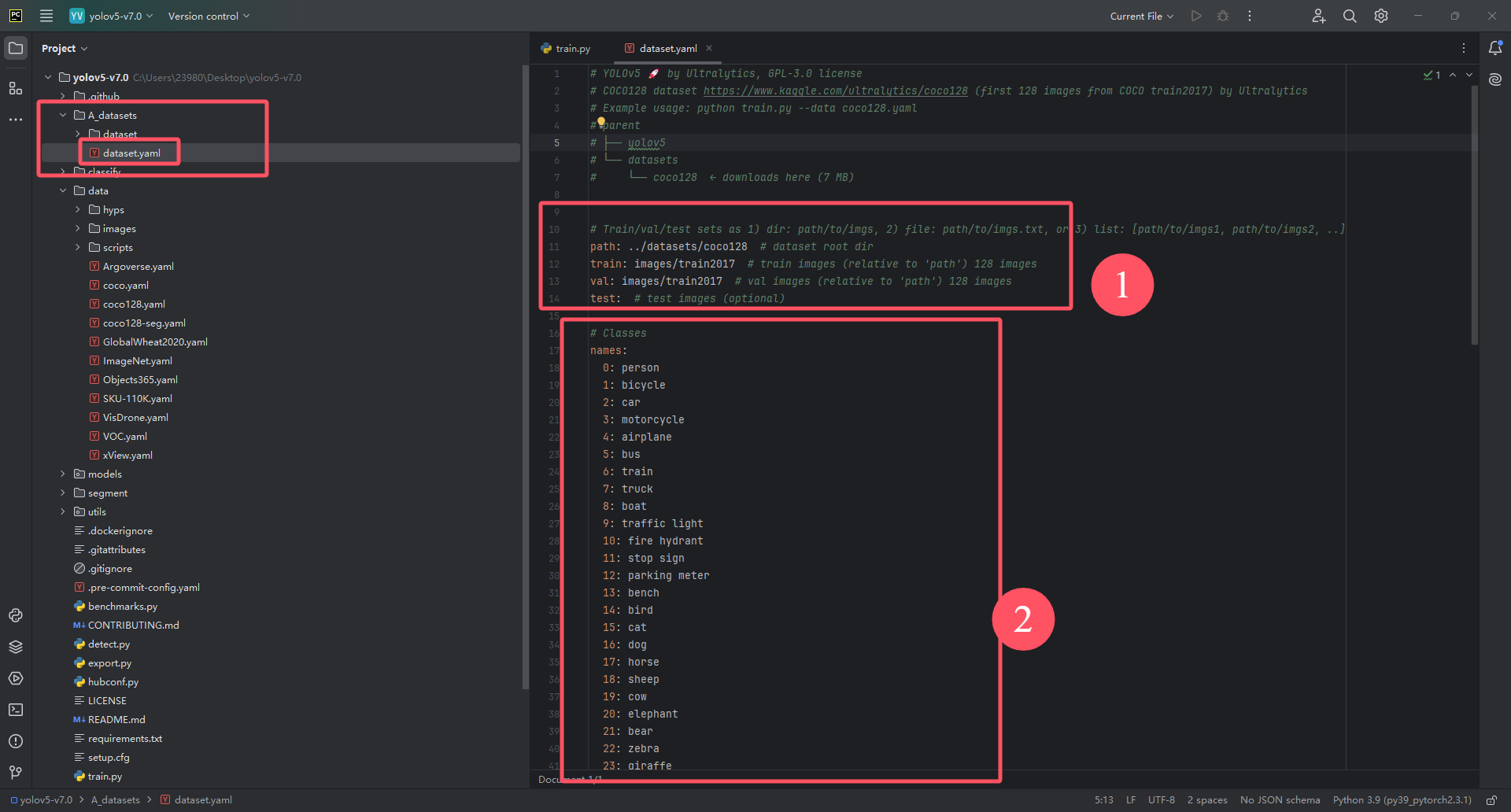
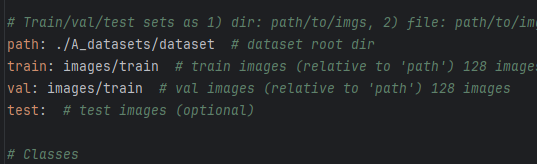
填写①处
- path: 这里需要改成我们数据集文件夹的路径,这里我们可以使用相对路径去直接读取到数据集文件夹,这也是为什么我让在项目文件夹里创一个A_datasets文件夹,然后把数据集文件夹放进去的原因,因为我们训练是用train.py进行训练的(后面我会讲这部分)。然后这里填的路径就是数据集相对于train.py的相对路径。因为数据集现在在A_datasets文件夹里,而A_datasets文件夹和train.py是在同一个文件夹中的,所以我们可以直接改成./A_datasets/dataset。(./代表访问当前当前所在的文件夹路径,因为trian.py所在文件夹和A_datasets文件夹的所在文件夹是一样的,所以通过./A_datasets就能访问到A_datasets文件夹里,然后我们的数据集文件夹是在A_datasets文件夹里,所以后面再跟上我们数据集文件夹的名字即可)。如果实在不懂这里的,你就直接改成数据集dataset文件夹的绝对路径,就是你这个文件夹在你电脑里的路径!
- train: 这里需要改成相对于上面path路径之后,我们数据集的训练集图像路径,所以直接改成images/train即可。(因为子在dataset里面,训练集图像实在images文件夹里的train文件夹里面)
- val: 如果数据集划分了训练集和验证集的话,这里则需要改成相对于上面path路径之后,我们数据集的验证集图像路径,所以直接改成images/val即可,如果数据集没有进行划分,只有训练集的话,这里就改成images/train,意味着用训练集图像也用来当测试集使用。
- test: 如果数据集划分了训练集、验证集和测试集的话,这里则需要填上相对于上面path路径之后,我们数据集的测试集图像路径,所以直接改成images/test即可。如果没用测试集则留空不填。
所以根据上述填写好的第一部分如下图所示:
填写②处
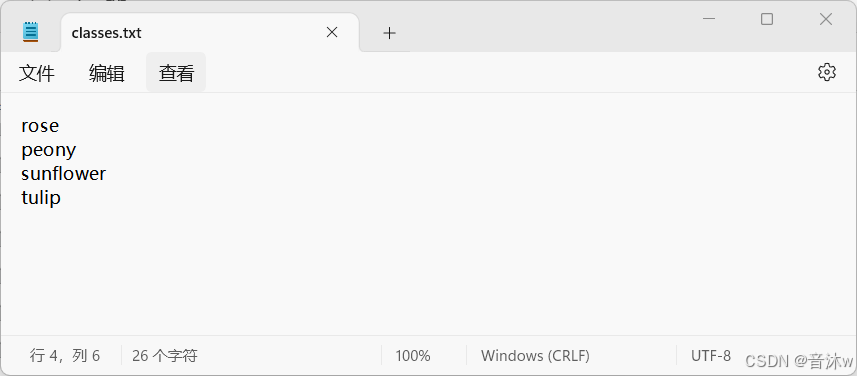
这里是需要填写上我们的标签名称,由上述制作数据集部分,我这里是做了一个花卉数据集,一共有4个种类,并且从0-3的顺序是在classes.txt里面可以看见,如下图。
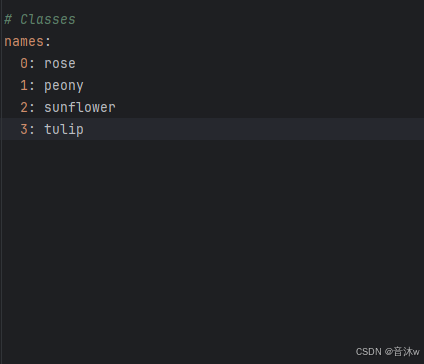
所以我们需要把这里的names里的类别改成我们自己的,多余的类别就删掉,剩下的类别名称按照我们自己的顺序修改上去即可,我的数据集因为只有4个类别,所以我们把0-3类别留下,其余的删去,然后再把0-3后面的标签名修改成我数据集对应的标签名即可,修改如下图!(注意:如果你们数据集检测的目标个数以及标签不一样,请按照你们自己的标签数量以及标签名称进行填写哦,具体看你们数据集的classes.txt就行!)
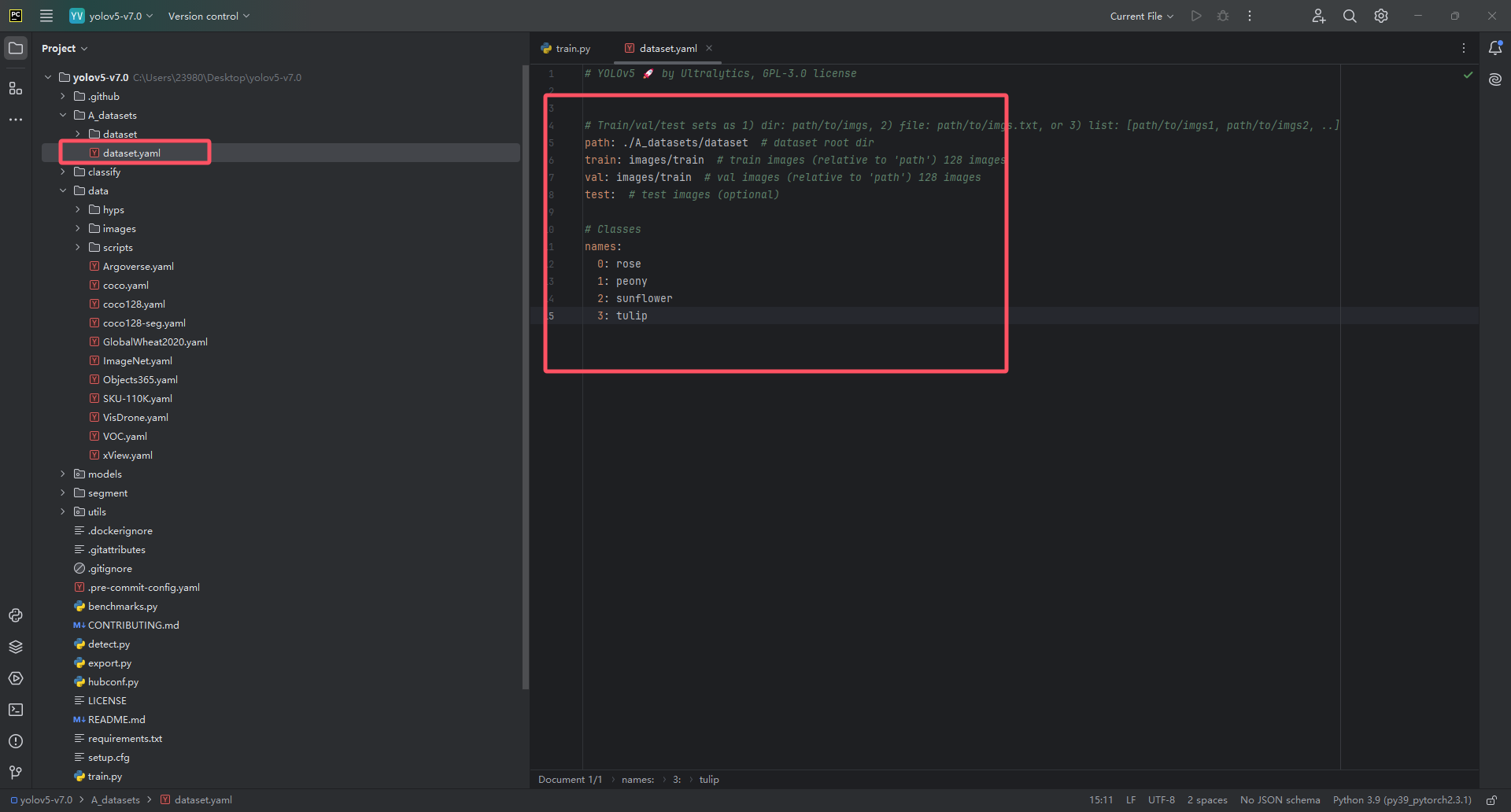
最终我们就配置好了数据集dataset.yaml配置文件!我数据集的配置如下(你们自己的数据集填写的东西可能会和我的不一样,请参考上述文字进行配置,不要直接照抄我下图的!!!)
2.3 配置yolov5网络结构配置文件yolov5s.yaml
这里我们就需要配置另一个配置文件,模型网络结构配置!我们打开yolov5代码项目里的models文件夹,可以看见里面有5个yaml文件,其中不一样的就是他们的后缀分别是l m n s x,这其实代表的是yolov5的不同的模型版本,其中他们各有不同,如果像具体了解可以去搜一下相关资料这里就不具体讲解。
反正如果无特殊需求一般我们都是用s级的模型,这个是一个小型版本,通常用于速度优先或资源受限的场景。该模型相对较小,参数较少,适合实时处理!所以我们一样的复制一份yolov5s.yaml文件到A_datasets文件夹下。如下图:
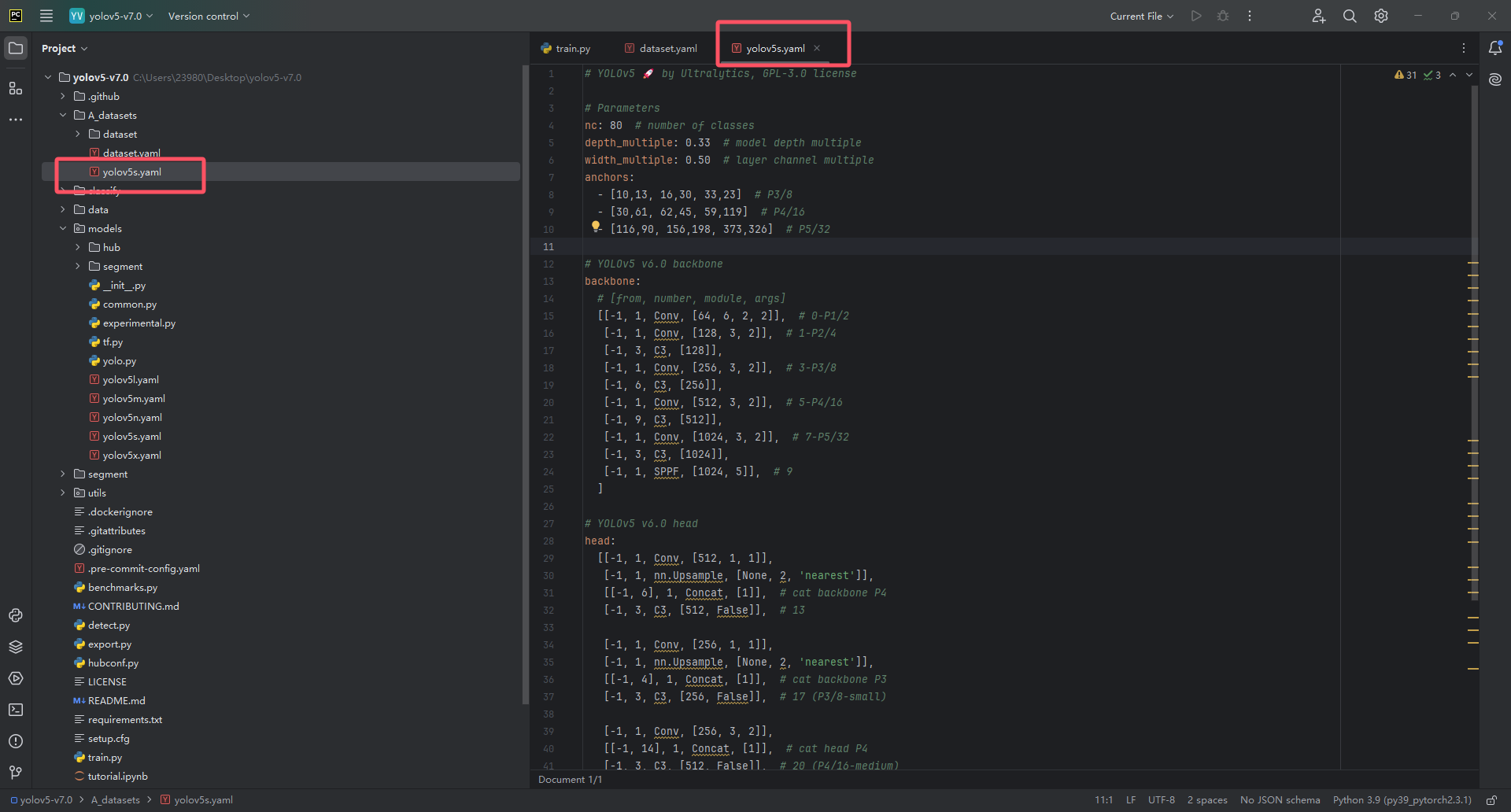
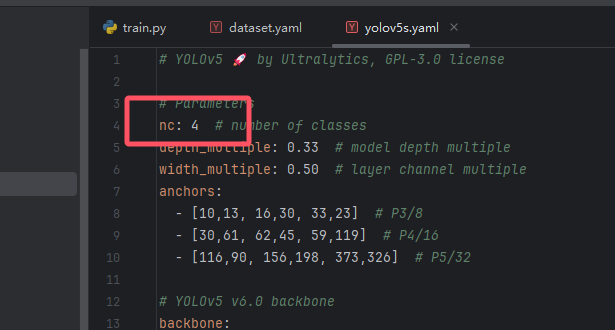
复制完一份之后呢,其实我们只需要改动一处即可,就是里面的nc: ,原始填写的是80,是因为官方的那个coco128数据集一共有80个类别,所以我们这里需要改成我们数据集的类别个数,因为我的数据集一共有4个类,所以我这里改成4即可,如下图。(你们就改成你们自己数据集的类别个数!)
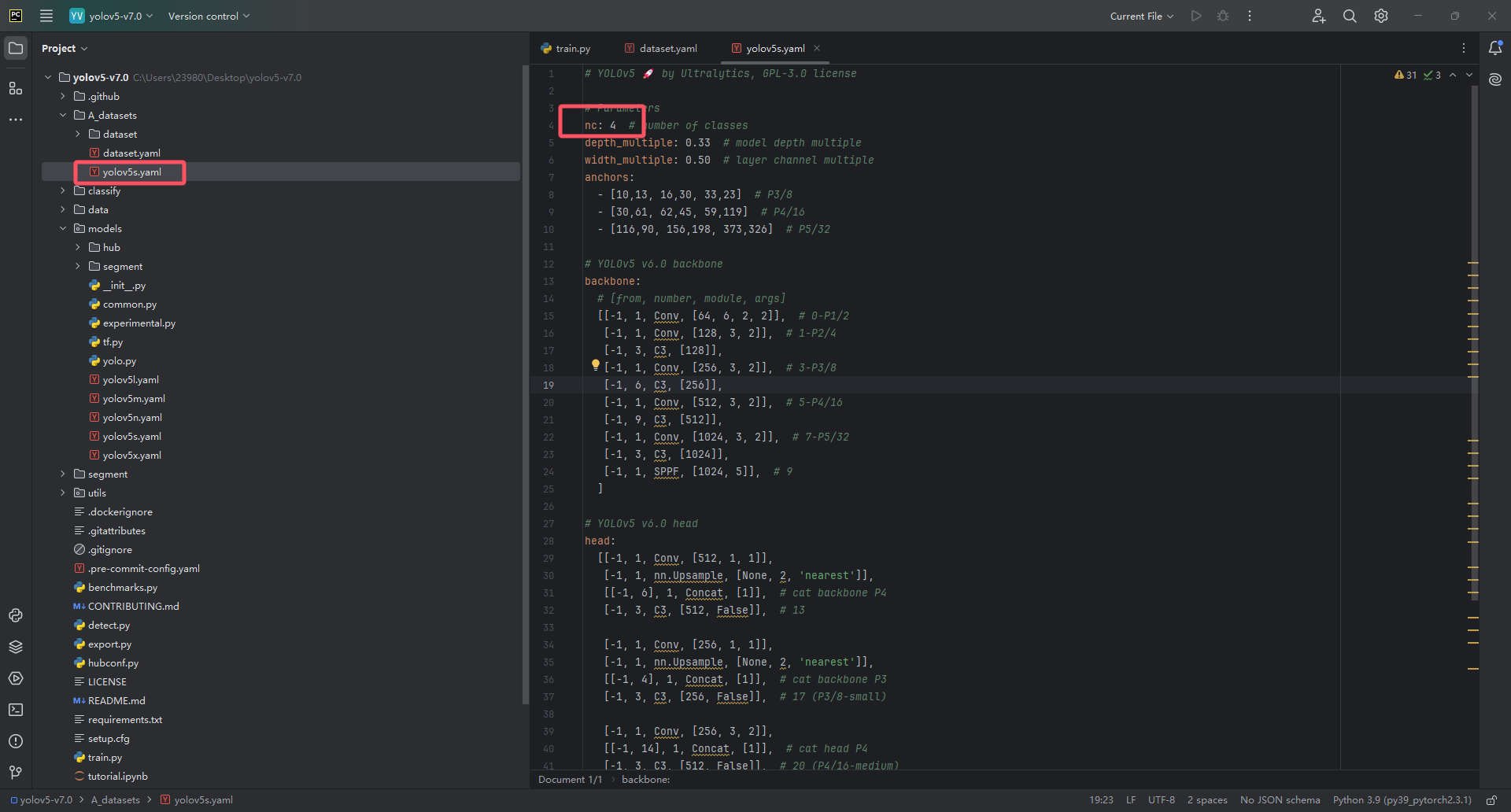
最终我们就配置好了网络结构配置文件yolov5s.yaml!我网络结构配置文件如下(你们自己的数据集填写的那个nc值可能会和我的不一样,请看你们自己的数据集标签个数填写,不要直接照抄我下图的!!!)
3.训练模型
3.1配置参数并训练
到了这里我们就可以开始进行加载数据集用yolov5的代码训练模型了!训练是用yolov5代码项目里的train.py跑的,所以我们先打开train.py,然后我们下滑到第433行左右这里的 parse_opt() 函数这里,这里介绍一下我们一般需要修改的训练参数,如下图:
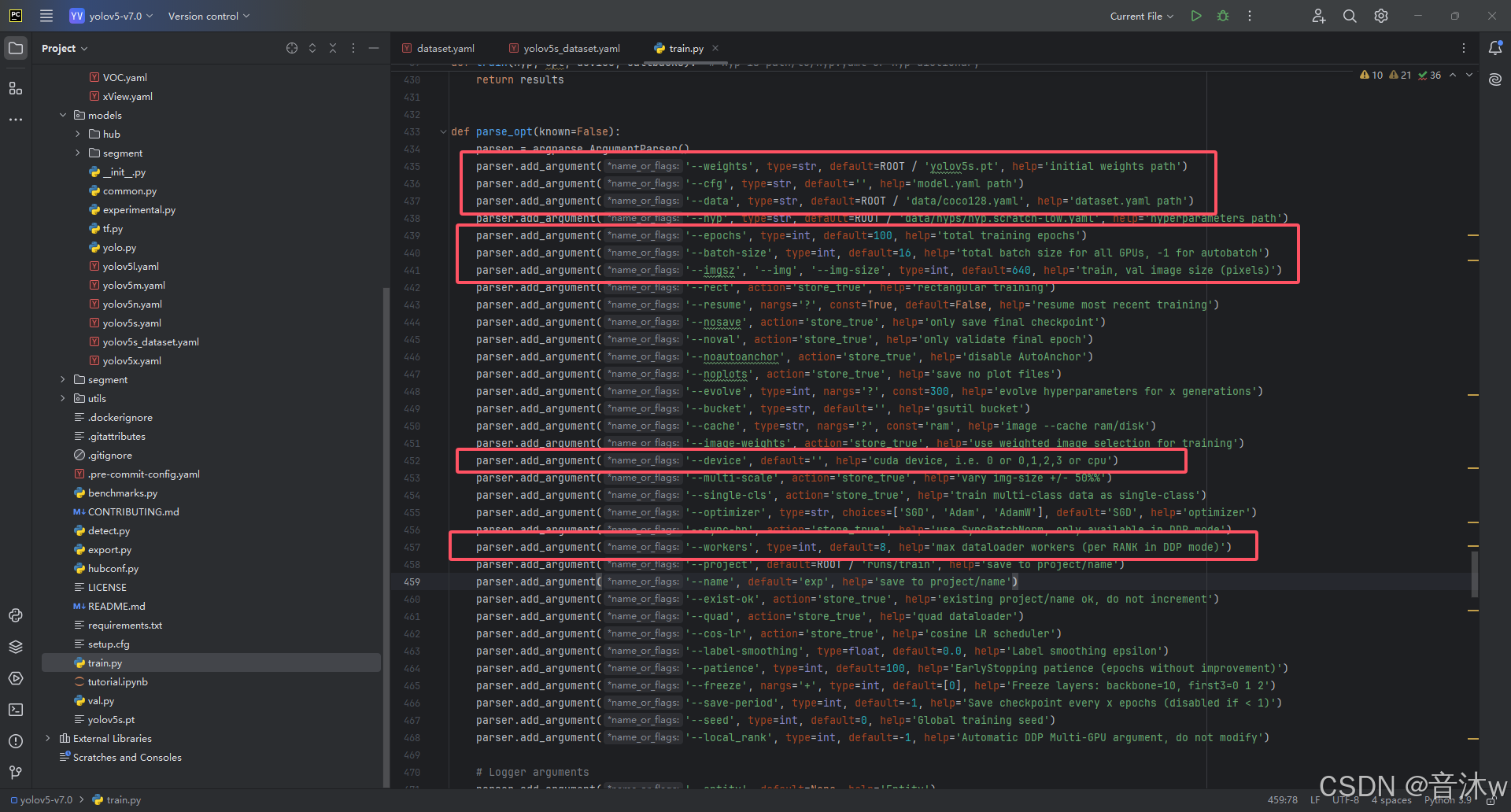
一般训练常要修改的参数大概是这8个,如下表:
| 参数 | 说明 | 修改 |
|---|---|---|
| weights | 填写加载的预训练模型的路径,一般对应你配置的那个上面网络配置文件,默认是yolov5s.pt,代表用官方的s轻量级模型当与预训练模型,如果你在上面那个网络配置选的是其他的,比如选的yolov5n、yolov5m等,这里就需要改成你对应的pt(我在上面提供的v5代码里已经放了yolov5s.pt这个官方模型,如果你是用的yolov5n.pt或是其他的预训练模型在代码运行的时候会自动帮你下载到该项目下,但是有些人连不上外网下载就会出现卡住不动的情况,所以得自行去下载对应的官方pt到项目文件夹里) | 这里我就不用修改,默认用yolov5s.pt就行,因为我上面的网络配置就是用的yolov5s.yaml的网络配置的 |
| cfg | 这里需要填你的网络结构配置文件路径,就是该文2.3处配置的那个yaml的路径 | 所以这里我需要填上A_datasets/yolov5s.yaml |
| data | 这里需要填你的数据集配置文件路径,就是该文2.2处配置的那个yaml的路径 | 所以这里我要改成A_datasets/dataset.yaml |
| epochs | 代表你训练的轮次,也就是训练模型的轮次,理论上轮次越大训练的模型越精准 | 这里就不改默认100即可,代表训练100轮,如果你想训练更多轮次自行改就行 |
| batch-size | 代表你训练时迭代中所使用的样本数量(批次大小),合适的批次大小对训练速度和模型收敛性都有影响,较大的批次大小可能加快训练速度但也可能对硬件资源有更高要求,一般看你自己电脑配置去填16, | 这里就不改默就填16即可,如果电脑带不动跑不起训练提示什么页面文件太小,无法完成操作,就改成8、4、2、1,直到能跑训练为止! |
| imgsz | 代表输入训练、验证阶段图像的尺寸,一般来说不用改 | 这里就不改默认640即可 |
| device | 用于指定训练或推理时所使用的计算设备,可以是 cuda 设备(如 0 表示使用第一个 GPU,0,1,2,3 表示使用多个 GPU),填cpu则指定为 cpu,决定了是利用 GPU 的并行计算能力还是仅依靠 CPU 进行计算。留空待变检测电脑能否跑GPU,能跑则会跑GPU,不能跑则跑CPU | 这里就不改默认不填,让他自己判断用GPU跑还是CPU跑 |
| workers | 用于指定数据加载器(dataloader)中最大的工作线程数量,更多的工作线程可以加快数据加载速度,从而提高整个训练过程的效率。但是很多windows电脑是不支持开这个的,如果开了训练可能就跑不起来一直卡住也不报错 | 这里我们把8改成0,一般windows电脑你就直接改成0就会,如果你电脑配置好可以试着填2、4、8这样往上加,如果不卡住说明没问题,反正越大训练也会越快,如果不行就直接填0就行 |
上述表格就包括了训练基本上需要改的参数了!我这里训练改的如下:
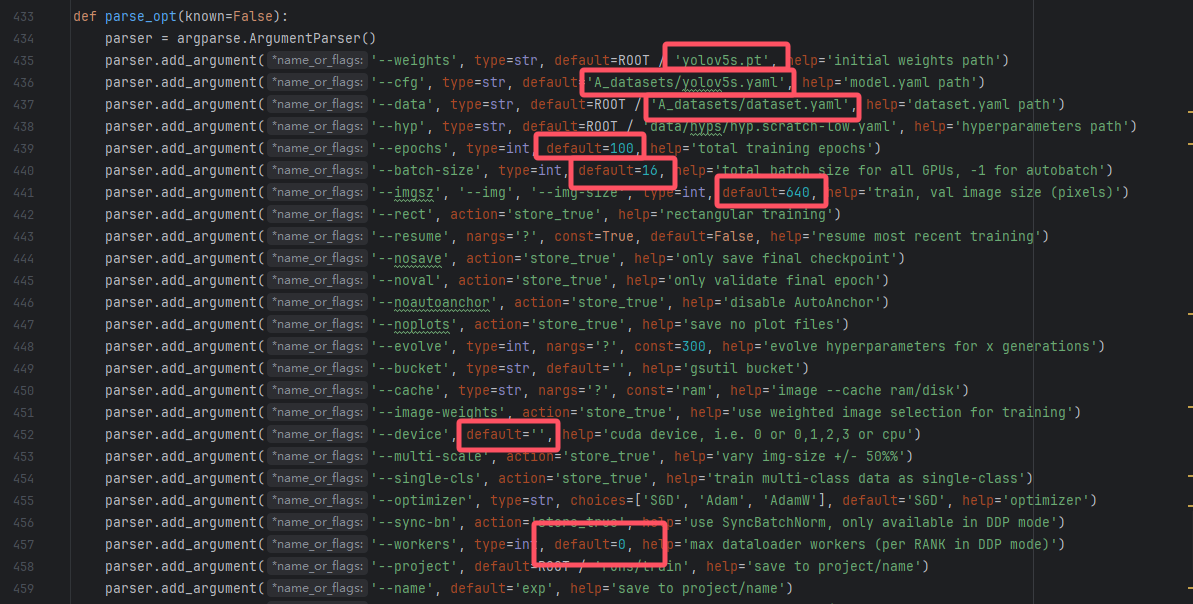
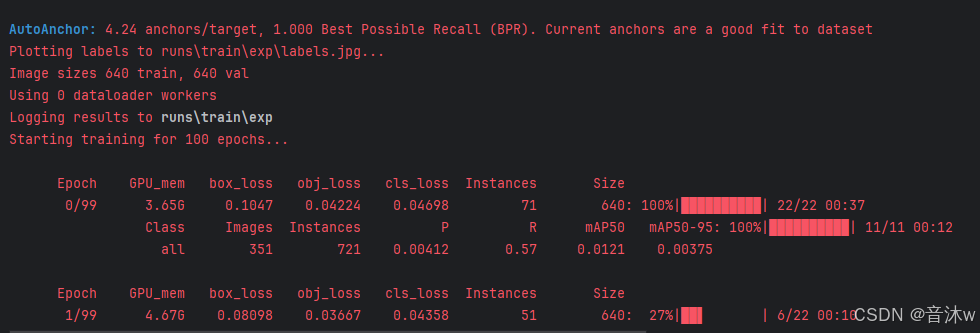
配置完这些我们就可以直接右键train.py然后点run运行代码即可开始训练了!如下为正在训练图:
3.2训练报错解决
如果上述过程运行train.py出现了报错,这里给了大部分报错解决方法,可以看一下!如果成功训练则直接跳至文章3.3处!
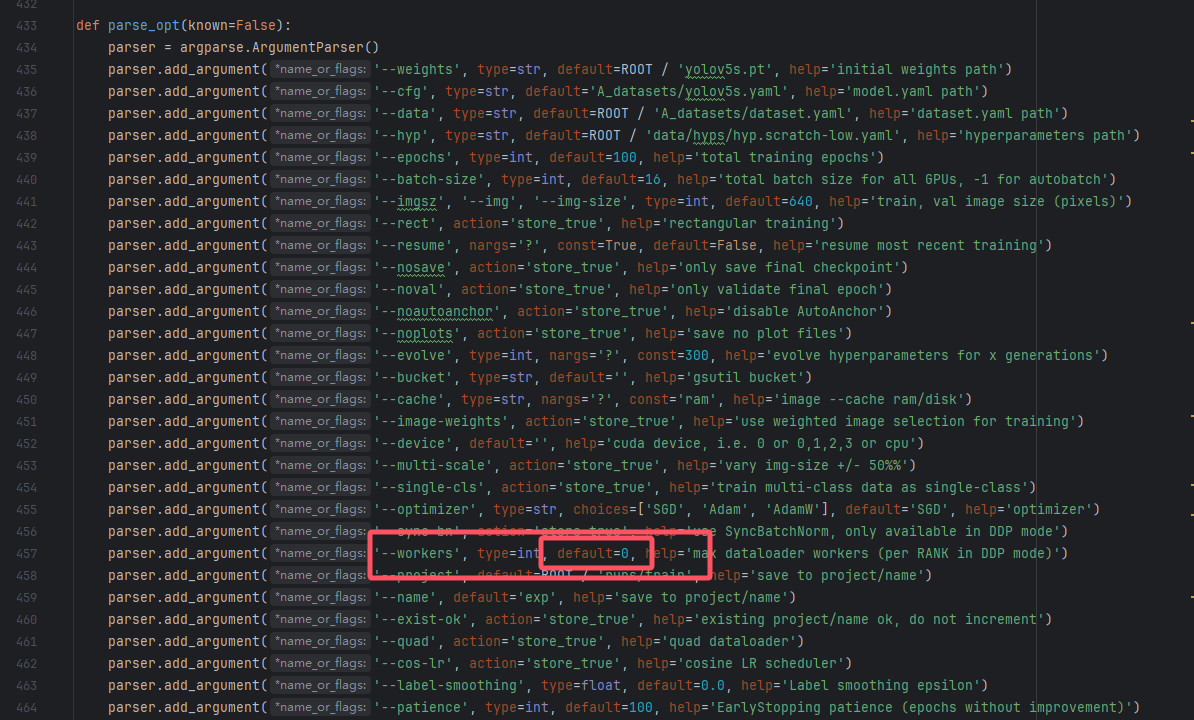
3.2.1 页面文件太小,无法完成操作
原因: windows操作系统不支持python的多进程操作。而神经网络用到了多进程的地方在数据集加载上
解决办法: 在train.py的参数配置那里,把workers改成0!如下图
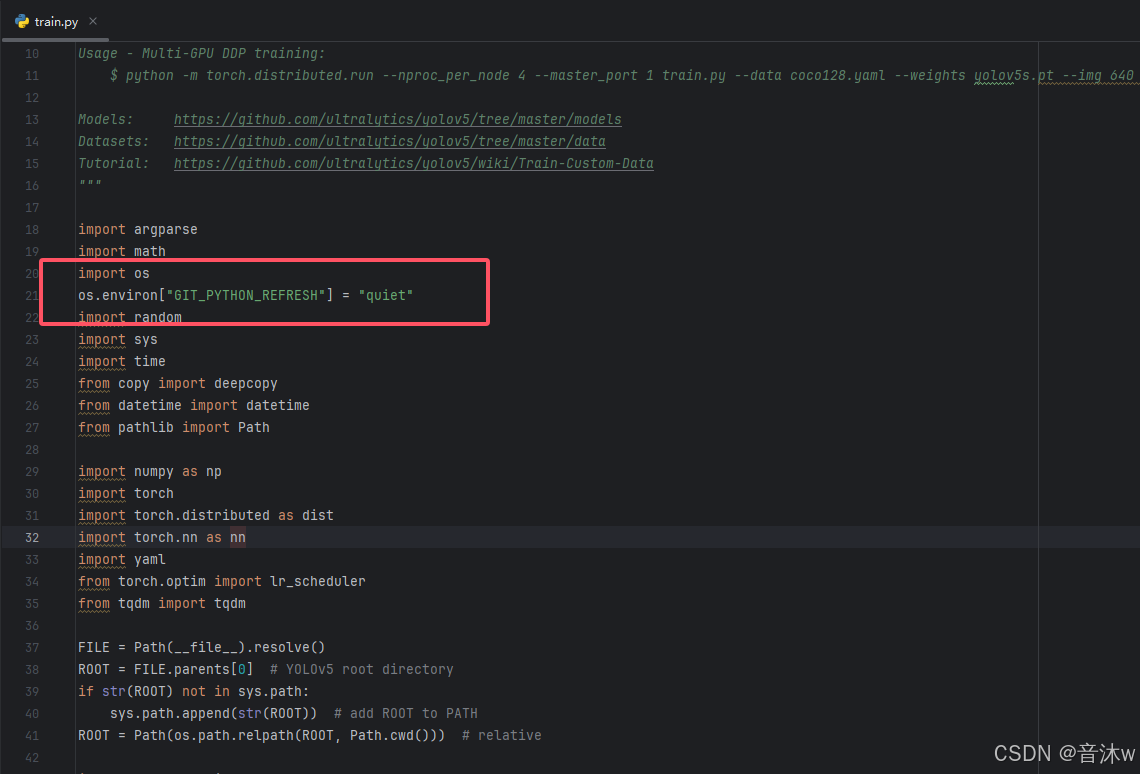
3.2.2 export GIT_PYTHON_REFRESH=quiet
原因: 猜测可能是有墙上不去git
解决办法: 在train.py的最开始加上下面两句代码
import os
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
3.2.3 RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
原因:batch-size过大,调小即可
解决办法:在train.py的参数配置那里,把batch-size改小,例如16、8、4、2、1!一直往下调直到能跑。
3.2.4 attributeerror: ‘FreeTypeFont’ object has no attribute ‘getsize’
原因:这是因为环境里安装了新版本的 Pillow (10)删除了该getsize功能,降级到 Pillow 9.5 解决了该问题
解决办法:在桌面搜索处搜anaconda Prompt,然后双击打开anaconda Prompt然后输入进入你的环境conda activate xxx(xxx为你的虚拟环境名称),然后输入以下代码
pip uninstall pillow
pip install pillow==9.5.0
3.3 训练结果
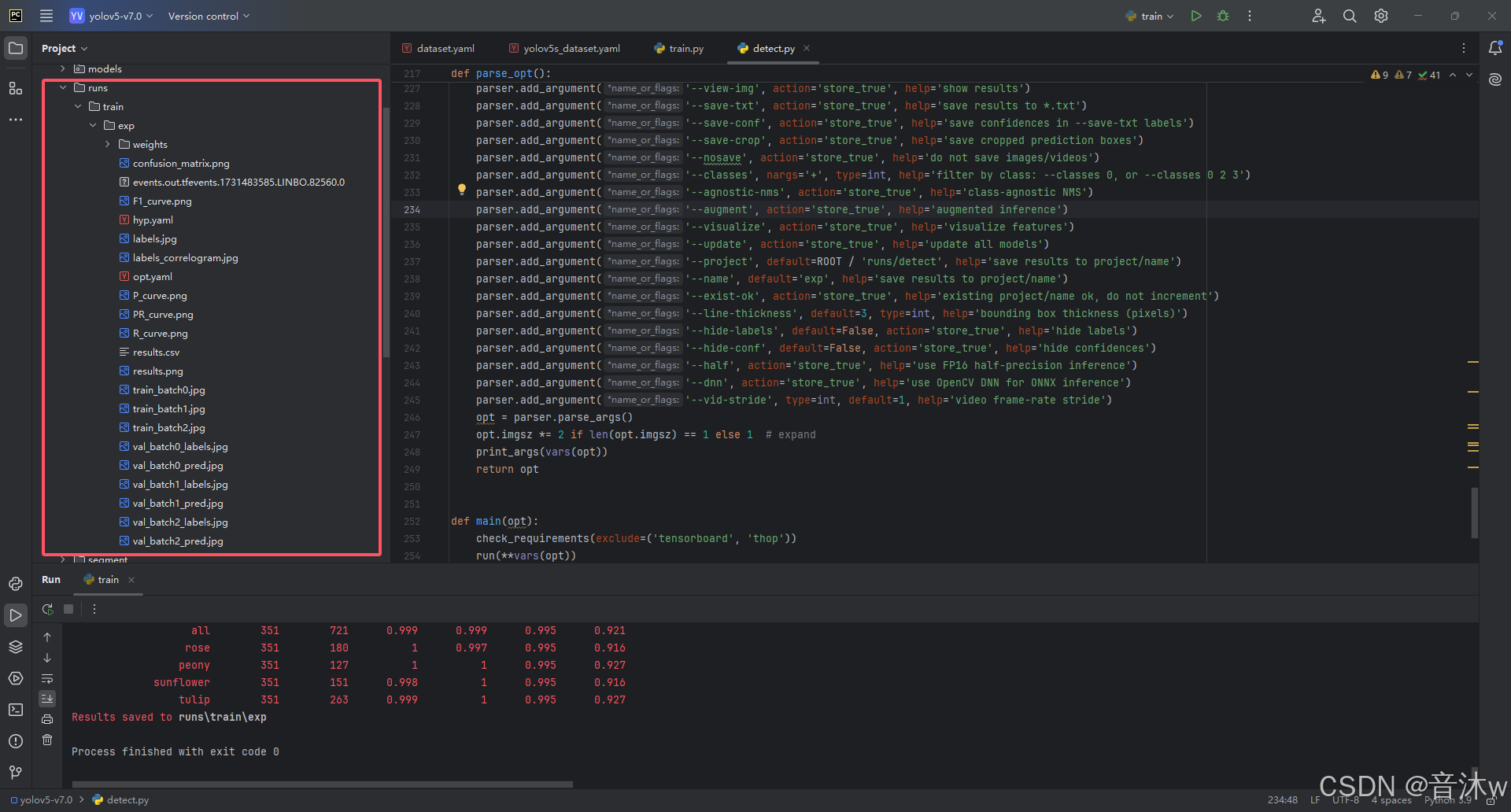
最后如果成功训练完,终端则会显示如下图的一个显示,告诉你训练的结果保存到了那个路径下!这里我们可以看见我的训练结果是保存在了runs/train/exp路径下。

我们去训练结束显示保存到的目录里就能看见我们训练的模型权重以及训练过程图了!(每次运行train.py基本上都会在runs/train目录下生成一个exp?文件夹,就算你中途停止或者报错了什么的都会生成,所以一般你运行过几次train就会有几个exp文件夹在runs/train里,所以具体哪个文件夹时你完全成功训练出来的,还是得看上面训练结束显示的保存目录,我这边显示就是保存在exp中,所以我们在runs/train/exp文件夹里就可以找到我们训练的模型以及训练过程图了!)
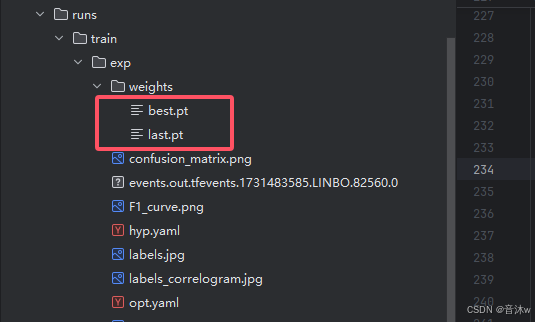
4.模型结果分析
通过上面我们训练完了模型之后,打开exp可以看见我们训练好的所有文件,里面有一个weights文件夹,这个weights文件夹里面就是我们训练出来的最终模型权重了,之后我们就可以去加载这里面的pt模型去检测你想检测的目标。我们打开其实可以看见weights文件夹下有两个pt模型best.pt和last.pt。best.pt代表我们在整个训练过程中训练效果最好的那一次的pt模型,而last.pt代表的是最后一次训练的pt模型,所以我们一般都是直接用best.pt就行了,哪个last.pt是不用的。
然后剩下的那些图表数据什么的其实都是用来帮助你看这个模型的一些指标啊精确度啥的,然后这些模型分析有许多博主都有做介绍了,我这里就不自己去阐述了,我这里给你们放一个我个人认为分析的不错的博主的,你们可以去看看,如下:
https://blog.csdn.net/weixin_54678439/article/details/138392469
四、目标检测
通过上述训练好模型之后呢,这个时候我们就可以进行加载模型进行图像视频检测或者调用摄像头进行检测了!
我们打开detect.py代码,下滑至217行左右这里的 parse_opt() 函数这里,然后我们一般只需要改两个参数即可,如下图:
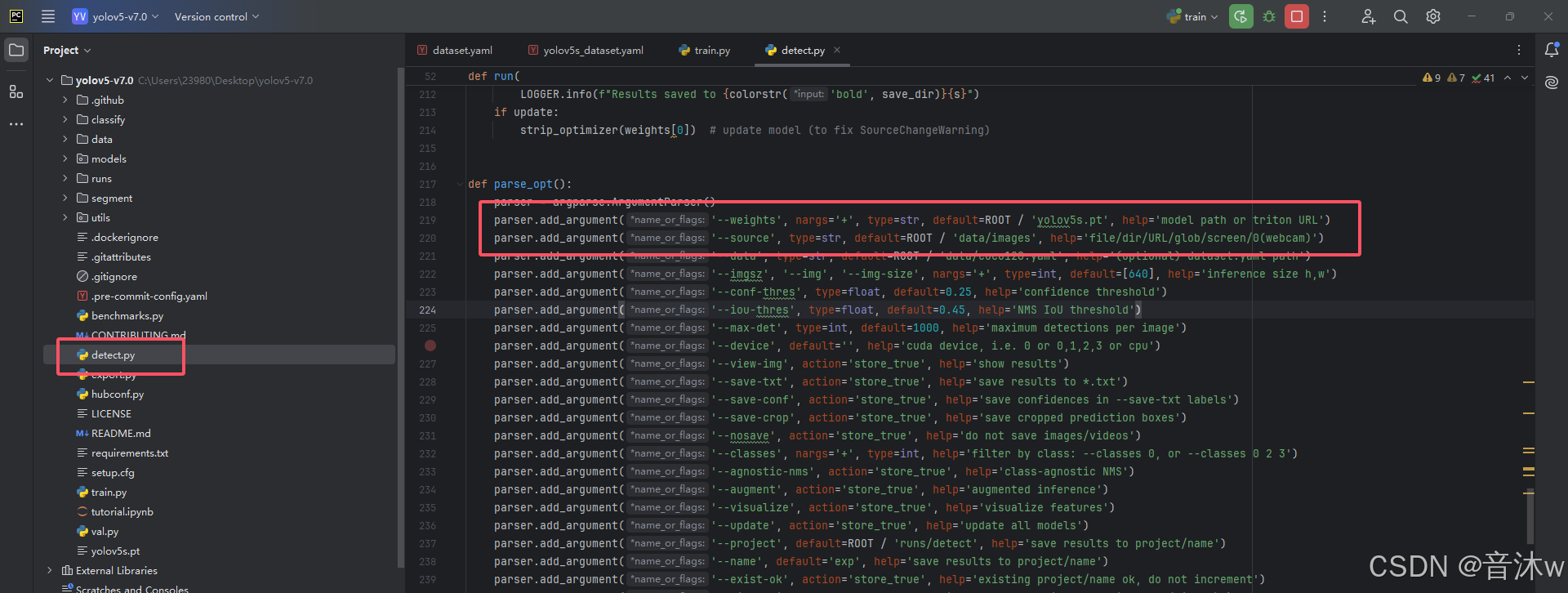
weights 这个参数我们需要改成我们自己训练出来的pt模型路径,从上述我们可以看出,我们训练的模型在当前代码下的runs/train/exp/weights目录下的best.pt,所以这里我们就把路径改上去即可(你们也一样,填你们自己的pt模型的所在路径)
source 这个参数填写的是你需要检测的来源,如下:
- 多图多视频检测:如果你一次性想多个图像和视频一起检测,你可以把你要检测的图像和视频放置在一个文件夹目录,然后在这里填写上那个文件夹的路径即可。
- 单图单视频检测:如果你一次只想检测一个图像或者一次只想检测一个视频,那就在这里填上你想检测的图像的路径或者视频的路径即可
- 调用摄像头检测:如果你是笔记本电脑,你可以填写0为参数,代表调用你自己笔记本电脑摄像头进行实时检测,如果你电脑没有摄像头你可以买一个usb相机插在电脑上也能实现调用摄像头检测,一样也是填0,如果你电脑上有多个usb摄像头,你可以通过填0、1这样调用具体的哪一个摄像头进行检测。
这里我们就以检测一张图像为例子吧,如下图我们将weights的参数改成自己的模型路径,将source的参数改成自己图像的路径。然后一样的右键代码区点run运行detect.py即可!
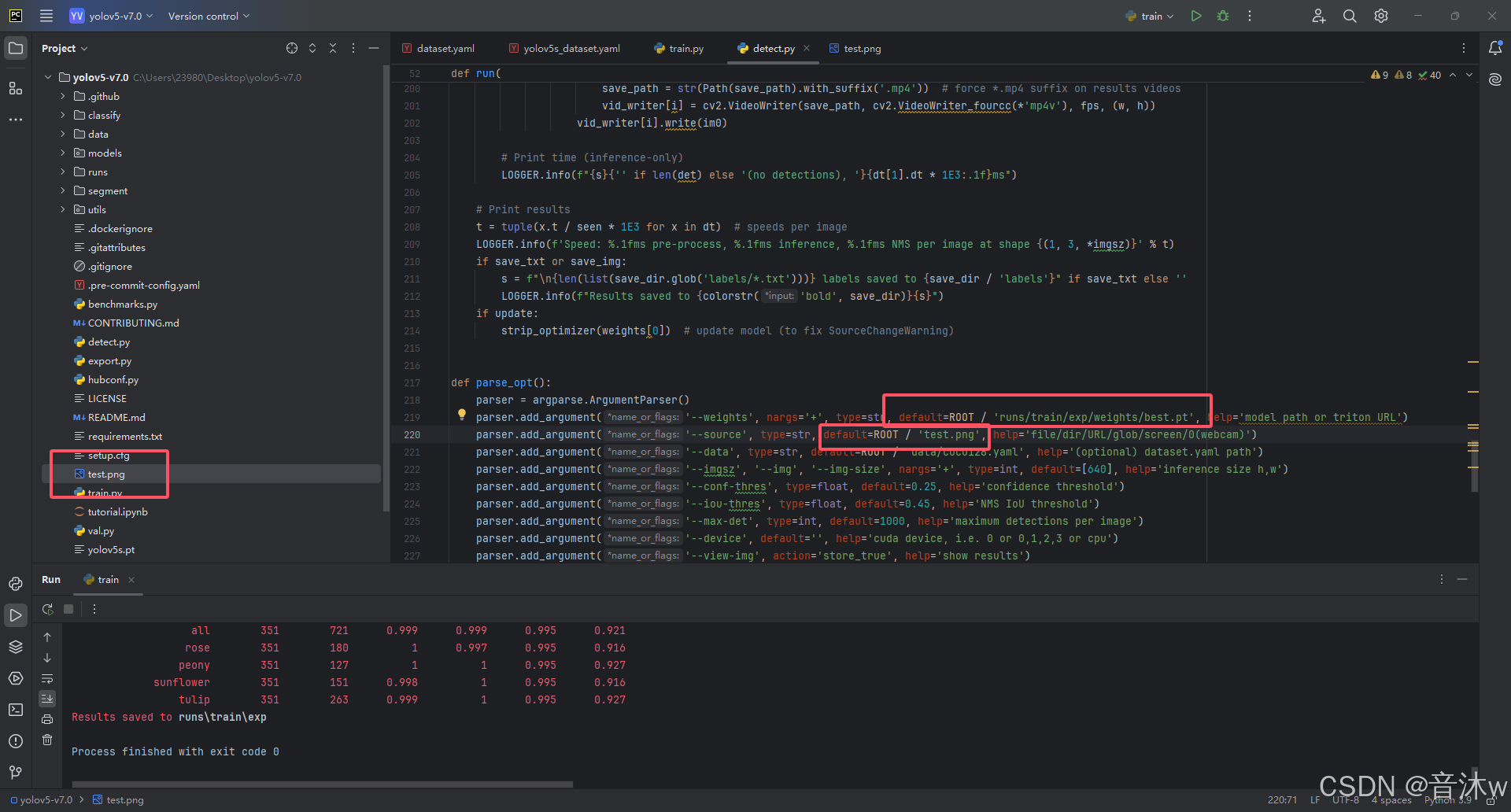
最后运行完会显示检测的结果保存在对应路径下,如下图:
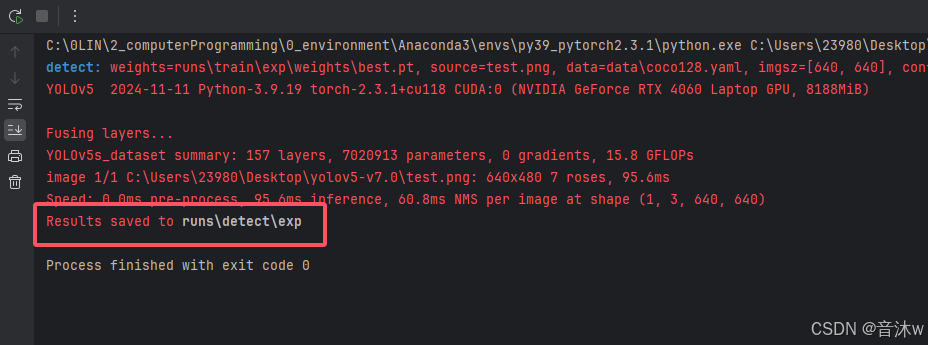
然后我们就可以去他这里现实的保存路径里看见我们的检测结果了!
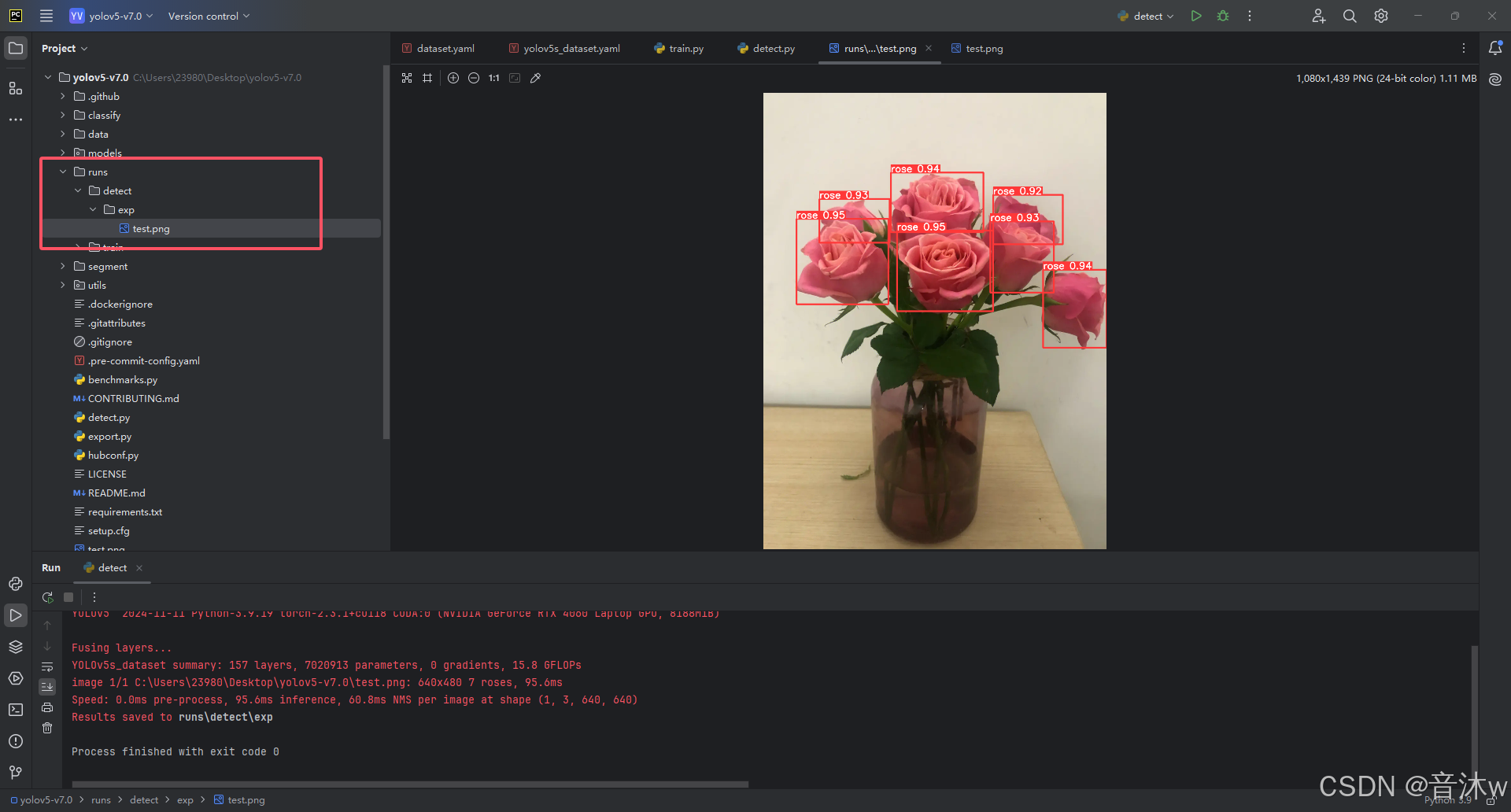
总结
以上就是整个yolov5目标检测的详细教学啦,详细讲解了环境配置、数据集制作、模型训练、加载模型进行目标检测!如果觉得这篇文章对你有所帮助,希望能够给博主一个关注和点赞噢!最后对文章有问题的欢迎在评论区留言询问噢!

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









