









基于Python深度学习手写数字识别系统
– Python / PyTorch / TensorFlow
【数据集】
- 数据集已划分为训练集和测试集,其中训练集和测试集图片各60000张。
【环境配置】
· 使用Anaconda管理环境
· 编程语言使用Python
· 深度学习框架有PyTorch或TensorFlow两种可供选择
· 神经网络结构采用卷积神经网络(CNN)
· 使用PIL和matplotlib库显示和绘制相关图表
· 能够实现高精度的识别分类,在MNIST测试集和QMNIST测试集上准确率达99%
· 可在编译器PyCharm或VsCode或Jupyter Notebook上运行
· 代码文件格式为.py文件,也可转为.ipynb文件
【项目整体流程】
数据预处理和增强 -> 数据加载 ->
超参数设置(epochs、batch_size、lr)-> 模型训练 ->
保存训练记录 -> 绘制损失和准确率曲线图 ->
模型评估 -> 绘制混淆矩阵 ->打印分类报告表 ->
模型应用 -> UI界面实现 -> 可选择导入图片进行预测,也可以手绘数字进行识别
【相关文件】
- 项目文件包括:数据集+源码(包括UI界面代码)+训练好的模型文件+可视化图表
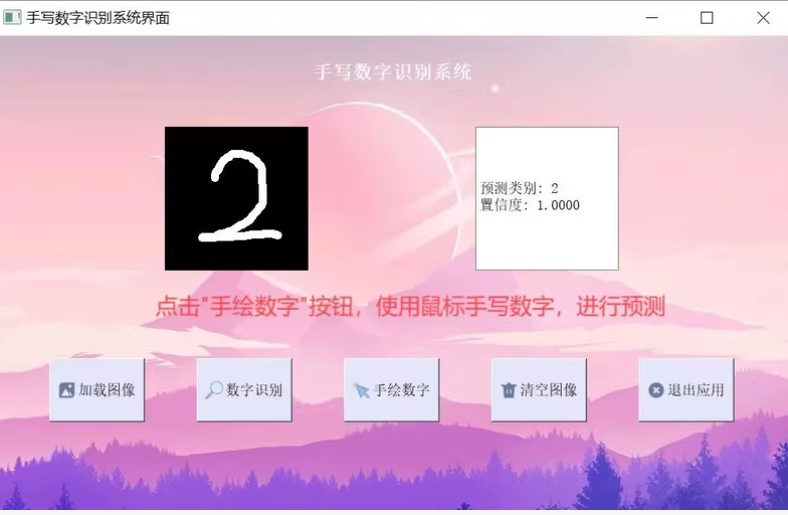
下面提供一个简单的指南来帮助你构建一个手写数字识别系统,使用流行的深度学习框架Keras(TensorFlow的一部分)。
所需库
首先,确保安装了必要的库。我们将使用tensorflow和一些辅助库如numpy和matplotlib用于可视化。
pip install tensorflow numpy matplotlib
数据准备
我们将使用经典的MNIST数据集,它包含70,000张28x28像素的灰度图像,每个图像是从’0’到’9’的手写数字。
from tensorflow.keras.datasets import mnist
import numpy as np
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
x_train = x_train.reshape((x_train.shape[0], 28, 28, 1)).astype('float32') / 255
x_test = x_test.reshape((x_test.shape[0], 28, 28, 1)).astype('float32') / 255
# 将标签转换为one-hot编码
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)

构建模型
接下来,我们定义并编译我们的卷积神经网络(CNN)模型。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential()
# 添加卷积层和池化层
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) # 输出层,10个类别
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
训练模型
现在我们可以训练模型。
model.fit(x_train, y_train, epochs=10, batch_size=64, validation_split=0.2)
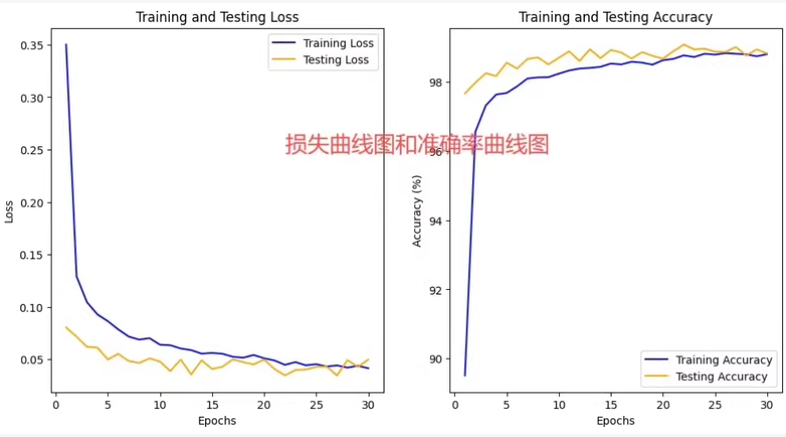
模型评估
最后,我们可以使用测试集评估模型性能。
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)
这个简单的例子应该能帮助你开始着手于手写数字识别的任务。

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









